本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Neptune ML 中的 Gremlin 推論查詢
如 Neptune ML 功能 中所述,Neptune ML 支援可以執行下列各種推論任務的訓練模型:
節點分類 – 預測頂點屬性的類別特徵。
節點迴歸 – 預測頂點的數值屬性。
邊緣分類 – 預測邊緣屬性的類別特徵。
邊緣迴歸 – 預測邊緣的數值屬性。
連結預測 – 鑑於來源節點和傳出邊緣預測目的地節點,或鑑於目的地節點和傳入邊緣指定來源節點。
我們可以使用 GroupLens Research
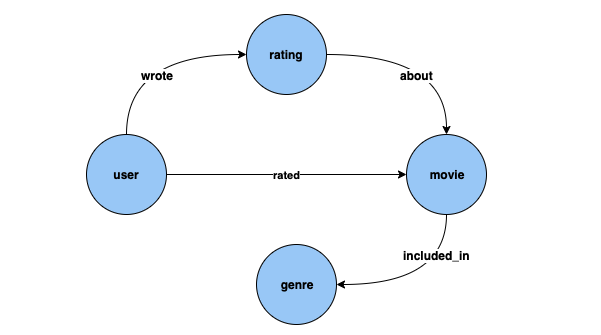
節點分類:在上述資料集中,Genre 是由邊緣 included_in 連線至頂點類型 Movie 的頂點類型。但是,如果我們調整資料集,使 Genre 成為頂點類型 Movie 的類別Genre 的問題可以使用節點分類模型來解決。
節點迴歸:如果我們考慮頂點類型 Rating,它具有 timestamp 和 score 等屬性,則為 Rating 推斷數值 Score 的問題可以使用節點迴歸模型來解決。
邊緣分類:同樣地,對於 Rated 邊緣,如果我們有一個屬性 Scale 可以具有 Love、Like、Dislike、Neutral、Hate 其中一個值,則為新電影/評分的 Rated 邊緣推斷 Scale 的問題可以使用邊緣分類模型來解決。
邊緣迴歸:同樣地,對於相同的 Rated 邊緣,如果我們有一個屬性 Score 保留評分的數值,則這可以從邊緣迴歸模型推斷出來。
連結預測:尋找最有可能對給定電影評分的前十名使用者,或尋找給定使用者最有可能評分的前十部電影之類的問題屬於連結預測。
注意
對於 Neptune ML 使用案例,我們有一組非常豐富的筆記本,旨在讓您實際了解每個使用案例。當您使用 Neptune ML AWS CloudFormation 範本建立 Neptune ML 叢集時,您可以建立這些筆記本和 Neptune 叢集。這些筆記本也可以在 github
主題
