本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Apache Spark 中的關鍵主題
本節說明 Apache Spark 的基本概念和關鍵主題 AWS Glue ,以調校 Apache Spark 效能。在討論真實世界調校策略之前,請務必了解這些概念和主題。
架構
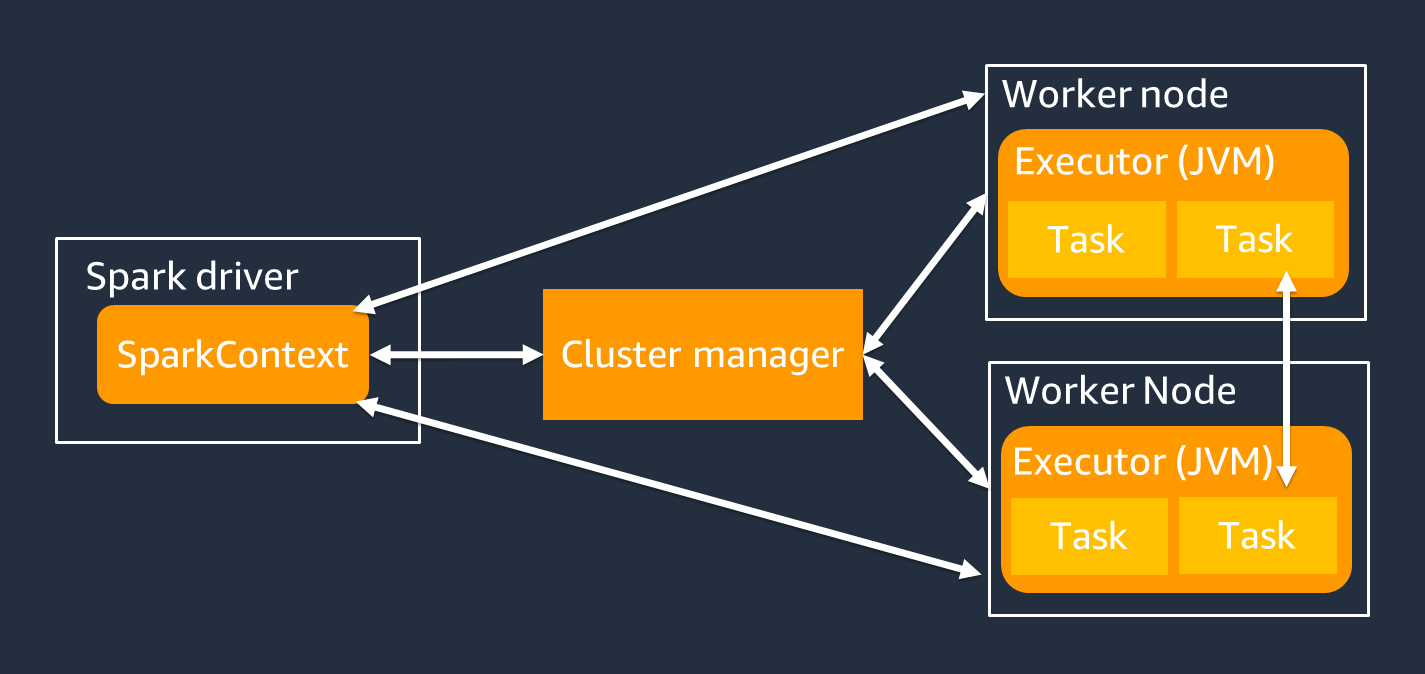
Spark 驅動程式主要負責將您的 Spark 應用程式分割為可在個別工作者上完成的任務。Spark 驅動程式有下列責任:
-
在程式碼
main()中執行 -
產生執行計畫
-
搭配叢集管理員佈建 Spark 執行器,以管理叢集上的資源
-
排程任務並請求 Spark 執行器的任務
-
管理任務進度和復原
您可以使用 SparkContext 物件來與 Spark 驅動程式進行任務執行互動。
Spark 執行器是一種工作者,用於保存從 Spark 驅動程式傳遞的資料和執行中的任務。Spark 執行器的數量會隨著叢集的大小而增加和減少。
注意
Spark 執行器具有多個插槽,以便平行處理多個任務。Spark 預設支援每個虛擬 CPU (vCPU) 核心的一個任務。例如,如果執行器有四個 CPU 核心,則可以執行四個並行任務。
彈性分散式資料集
Spark 會執行複雜任務,以跨 Spark 執行器存放和追蹤大型資料集。當您編寫 Spark 任務的程式碼時,不需要考慮儲存體的詳細資訊。Spark 提供彈性分散式資料集 (RDD) 抽象,這是可以平行操作的一組元素,並可分割叢集的 Spark 執行器。
下圖顯示 Python 指令碼在一般環境中執行時,以及在 Spark 架構 (PySpark) 中執行時,如何在記憶體中存放資料的差異。
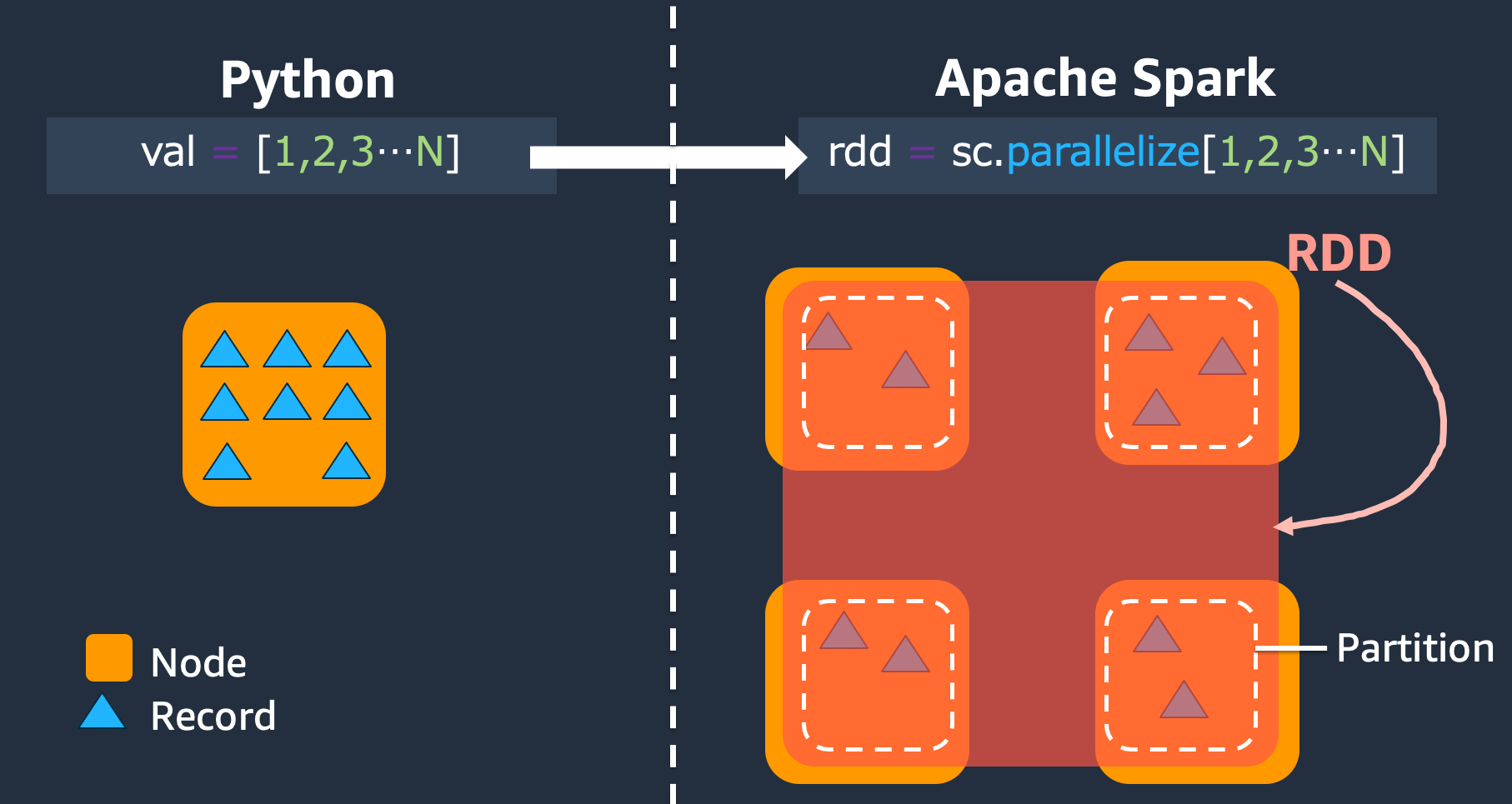
-
Python – 在 Python 指令碼
val = [1,2,3...N]中寫入 會將資料保留在執行程式碼的單一電腦上的記憶體中。 -
PySpark – Spark 提供 RDD 資料結構,以載入和處理分散在多個 Spark 執行器上記憶體的資料。您可以使用 等程式碼產生 RDD
rdd = sc.parallelize[1,2,3...N],Spark 可以在多個 Spark 執行器之間自動分配和保留記憶體中的資料。在許多 AWS Glue 任務中,您可以透過 DynamicFrames 和 Spark DataFrames 使用 RDDs AWS Glue 。這些摘要可讓您定義 RDD 中資料的結構描述,並使用該額外資訊執行更高階的任務。由於它們在內部使用 RDDs,因此資料會以透明的方式分佈並載入到下列程式碼中的多個節點:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
RDD 具有下列功能:
-
RDDs由分成多個部分的資料組成,稱為分割區。每個 Spark 執行器都會在記憶體中存放一或多個分割區,資料會分散到多個執行器。
-
RDDs 是不可變的,這表示在建立後就無法變更。若要變更 DataFrame,您可以使用轉換,如下節所定義。
-
RDDs會跨可用節點複寫資料,以便從節點故障中自動復原。
延遲評估
RDDs支援兩種類型的操作:轉換,從現有資料集建立新資料集,以及動作,在資料集上執行運算後將值傳回給驅動程式。
-
轉換 – 由於 RDDs 不可變,因此您只能使用轉換來變更它們。
例如,
map是一種轉換,透過函數傳遞每個資料集元素,並傳回代表結果的新 RDD。請注意,map方法不會傳回輸出。Spark 會存放未來的抽象轉換,而不是讓您與結果互動。在您呼叫 動作之前,Spark 不會對轉換採取行動。 -
動作 – 使用轉換,您可以建立邏輯轉換計畫。若要啟動運算,請執行
write、、countshow或 等動作collect。Spark 中的所有轉換都很緩慢,因為它們不會立即運算結果。反之,Spark 會記住套用至某些基本資料集的一系列轉換,例如 Amazon Simple Storage Service (Amazon S3) 物件。只有在動作需要將結果傳回給驅動程式時,才會計算轉換。此設計可讓 Spark 更有效率地執行。例如,考慮透過
map轉換建立的資料集僅由大幅減少資料列數量的轉換耗用的情況,例如reduce。然後,您可以將經過兩個轉換的較小資料集傳遞給驅動程式,而不是傳遞較大的映射資料集。
Spark 應用程式術語
本節涵蓋 Spark 應用程式術語。Spark 驅動程式會建立執行計畫,並控制應用程式在數個抽象中的行為。下列術語對於使用 Spark UI 進行開發、偵錯和效能調校非常重要。
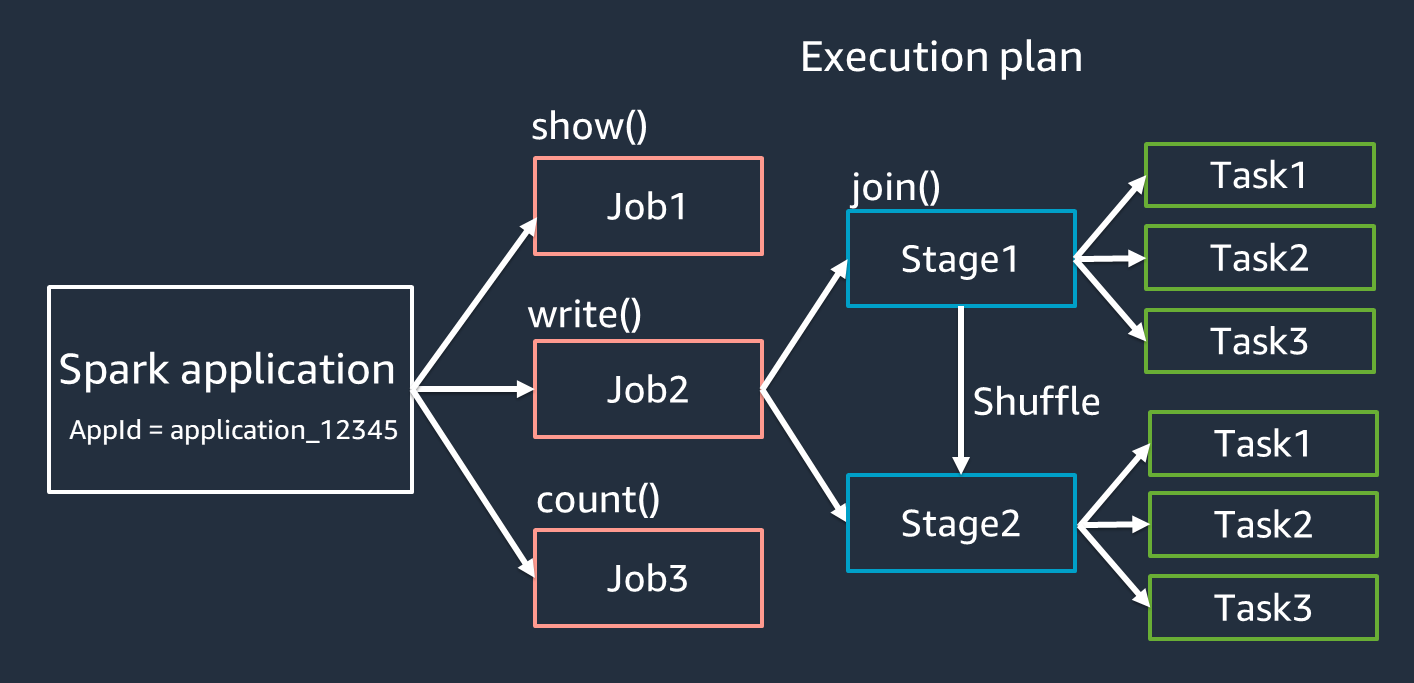
-
應用程式 – 根據 Spark 工作階段 (Spark 內容)。由唯一 ID 識別,例如
<application_XXX>。 -
任務 – 根據 為 RDD 建立的動作。任務包含一或多個階段。
-
階段 – 根據 為 RDD 建立的隨機播放 。階段包含一或多個任務。隨機播放是 Spark 重新分配資料的機制,因此在 RDD 分割區之間會以不同的方式分組。某些轉換,例如
join(),需要隨機播放。最佳化隨機播放調校實務中會更詳細地討論隨機播放。 -
任務 – 任務是 Spark 排定的最小處理單位。為每個 RDD 分割區建立任務,任務數量是階段中同時執行的最大數量。
注意
最佳化平行處理時,任務是最重要的考量事項。任務數量會隨 RDD 數量而擴展
平行處理
Spark 會平行處理載入和轉換資料的任務。
請考慮您在 Amazon S3 上執行存取日誌檔案 (名為 accesslog1 ... accesslogN) 分散式處理的範例。下圖顯示分散式處理流程。
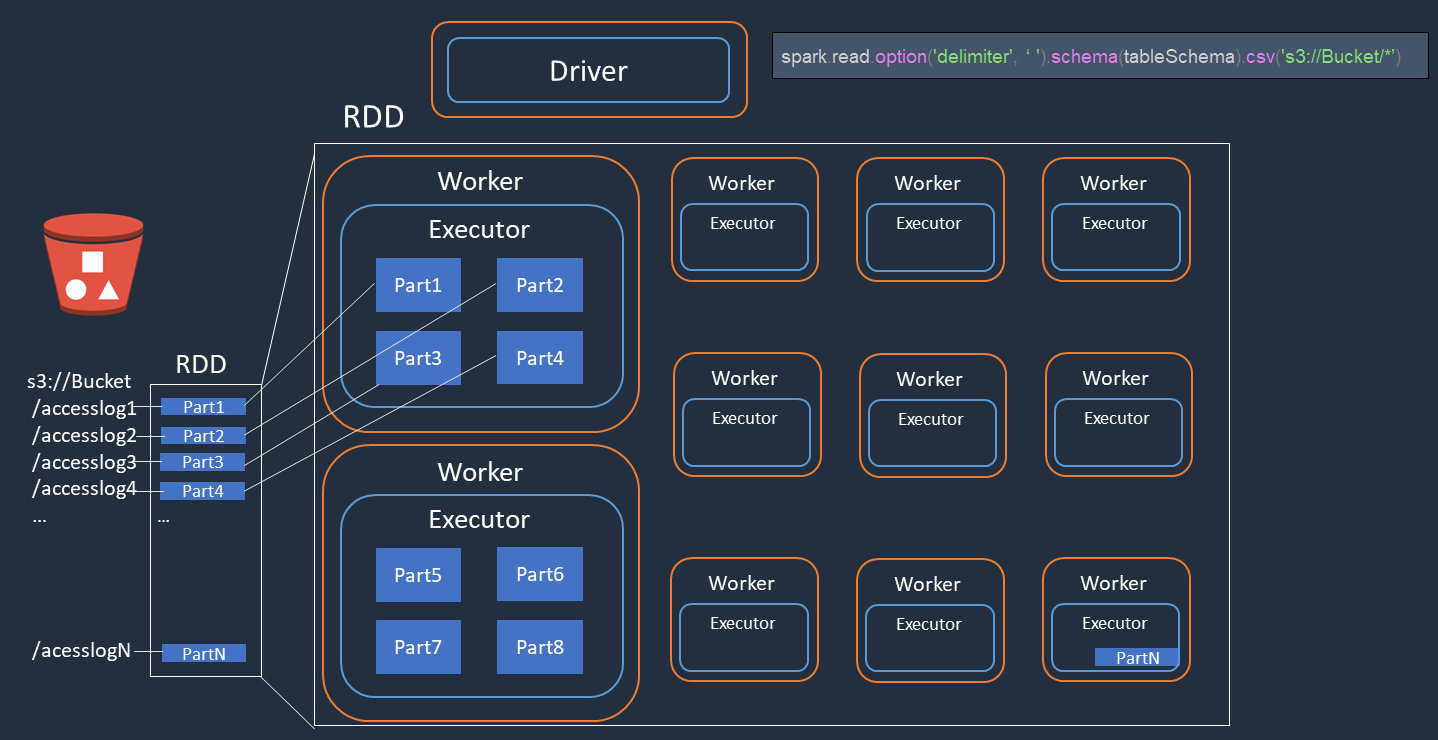
-
Spark 驅動程式會建立執行計劃,以分散處理多個 Spark 執行器。
-
Spark 驅動程式會根據執行計畫指派每個執行器的任務。根據預設,Spark 驅動程式會為每個 S3 物件 () 建立 RDD 分割區 (每個分割區對應於 Spark 任務)
Part1 ... N。然後,Spark 驅動程式會將任務指派給每個執行器。 -
每個 Spark 任務都會下載其指派的 S3 物件,並將其存放在 RDD 分割區的記憶體中。如此一來,多個 Spark 執行器會平行下載和處理其指派的任務。
如需初始分割區數量和最佳化的詳細資訊,請參閱平行處理任務一節。
Catalyst 最佳化工具
在內部,Spark 會使用名為 Catalyst 最佳化工具
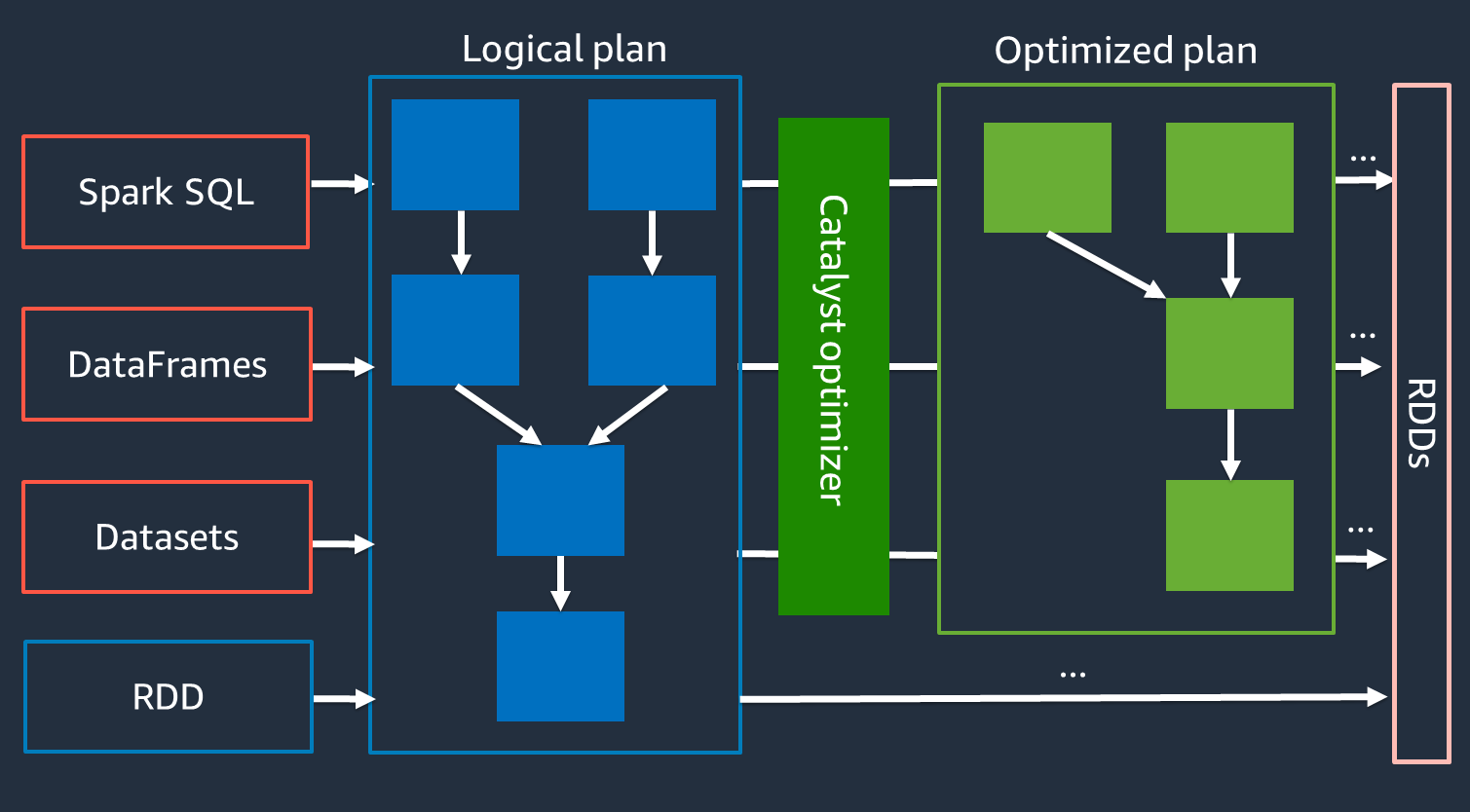
由於 Catalyst 最佳化工具無法直接與 RDD API 搭配使用,因此高階 APIs 通常比低階 RDD API 更快。對於複雜的聯結,Catalyst 最佳化工具可以透過最佳化任務執行計劃來大幅改善效能。您可以在 Spark UI 的 SQL 索引標籤上查看 Spark 任務的最佳化計劃。
自適應查詢執行
Catalyst 最佳化工具會透過稱為適應性查詢執行的程序來執行執行期最佳化。自適應查詢執行會使用執行時間統計資料,在任務執行時重新最佳化查詢的執行計畫。自適應查詢執行提供數種效能挑戰的解決方案,包括合併隨機分割、將排序合併聯結轉換為廣播聯結,以及扭曲聯結最佳化,如以下各節所述。
自適應查詢執行可在 AWS Glue 3.0 和更新版本中使用,且預設會在 AWS Glue 4.0 (Spark 3.3.0) 和更新版本中啟用。在您的程式碼spark.conf.set("spark.sql.adaptive.enabled", "true")中使用 可以開啟和關閉自適應查詢執行。
Coalescing 隨機播放後分割區
此功能會根據map輸出統計資料,在每個隨機播放之後減少 RDD 分割區 (餘量)。其可簡化執行查詢時隨機分割編號的調校。您不需要設定隨機分割號碼以符合資料集。在您擁有足夠多的隨機播放分割區初始數量之後,Spark 可以在執行時間選擇適當的隨機播放分割區編號。
當 spark.sql.adaptive.enabled和 都設為 true 時spark.sql.adaptive.coalescePartitions.enabled,會啟用並行隨機播放後分割區。如需詳細資訊,請參閱 Apache Spark 文件
將排序合併聯結轉換為廣播聯結
此功能會辨識您何時聯結大小大不相同的兩個資料集,並根據該資訊採用更有效率的聯結演算法。如需詳細資訊,請參閱 Apache Spark 文件
偏移聯結最佳化
資料扭曲是 Spark 任務最常見的瓶頸之一。其中描述了資料偏向特定 RDD 分割區 (因此是特定任務) 的情況,這會延遲應用程式的整體處理時間。這通常會降低聯結操作的效能。偏移聯結最佳化功能會動態處理排序合併聯結中的偏移,方法是將偏移任務分割 (並視需要複寫) 為大致均勻大小的任務。
當 spark.sql.adaptive.skewJoin.enabled 設為 true 時,此功能會啟用。如需詳細資訊,請參閱 Apache Spark 文件
