本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
平行化工作
若要最佳化效能,請務必平行處理資料載入和轉換的工作。正如我們在 Apache Spark 的關鍵主題中所討論的那樣,彈性分散式資料集 (RDD) 磁碟分割的數目很重要,因為它會決定平行處理原則的程度。Spark 創建的每個任務都對應於 1:1 的基礎上的RDD分區。為了獲得最佳性能,您需要了解如何確定分RDD區數量以及如何優化該數量。
如果您沒有足夠的平行性,則以下症狀將記錄在CloudWatch度量和 Spark UI 中。
CloudWatch 度量
檢查負CPU載和記憶體使用率。如果某些執行者在工作的某個階段沒有處理,那麼改善平行性是適當的。在這種情況下,在可視化的時間範圍內,執行者 1 正在執行任務,但其餘的執行者(2,3 和 4)不是。你可以推斷這些執行者沒有被 Spark 驅動程序分配任務。
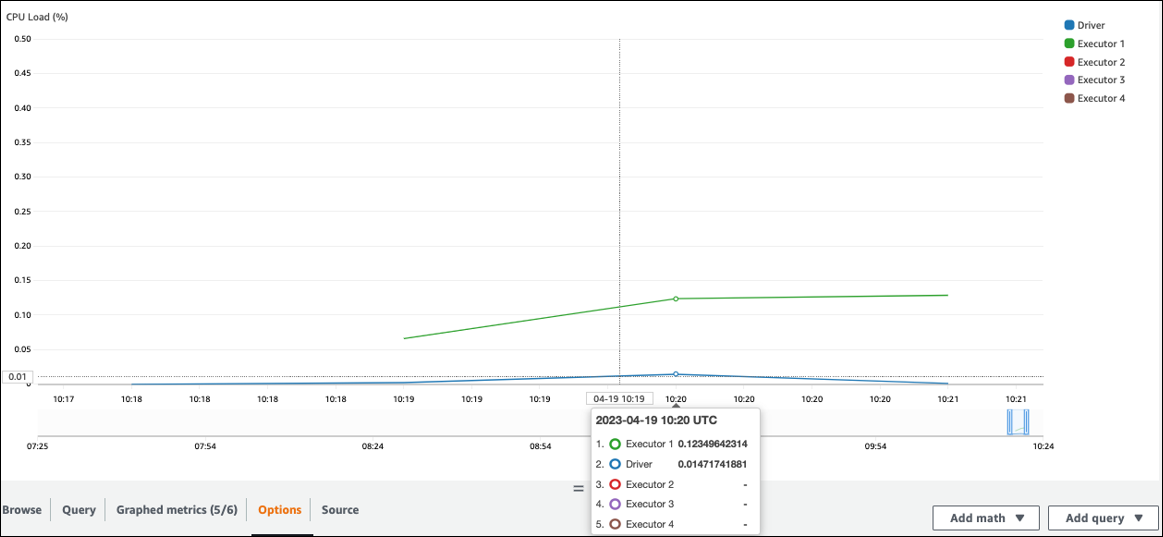
Spark UI
在 Spark UI 的「階段」索引標籤上,您可以看到階段中的工作數目。在這種情況下,Spark 只執行了一項任務。

此外,事件時間表顯示執行者 1 正在處理一項任務。這意味著在這個階段的工作完全是在一個執行者上執行的,而其他執行者則處於閒置狀態。

如果您發現這些徵狀,請針對每個資料來源嘗試下列解決方案。
並行處理來自 Amazon S3 的資料載入
若要平行處理來自 Amazon S3 的資料載入,請先檢查預設的分割區數量。然後,您可以手動確定分割區的目標數量,但請務必避免分割區過多。
確定分區的默認數量
對於 Amazon S3,Spark RDD 分割區的初始數量 (每個分割區都對應於 Spark 任務) 是由 Amazon S3 資料集的功能 (例如,格式、壓縮和大小) 決定。當您 DataFrame 從 Amazon S3 中存放的CSV物件建立 AWS Glue DynamicFrame或 Spark 時,初始RDD分割區數 (NumPartitions) 可大約計算如下:
-
物件大小等於 64 MB:
NumPartitions = Number of Objects -
物件大小 > 64 MB:
NumPartitions = Total Object Size / 64 MB -
不可分割 (壓縮):
NumPartitions = Number of Objects
如「減少資料掃描量」一節中所述,Spark 會將大型 S3 物件分割成可 parallel 處理的分割。當物件大於分割大小時,Spark 會分割物件,並為每次RDD分割建立一個分割區 (和工作)。Spark 的拆分大小基於您的數據格式和運行時環境,但這是一個合理的起始近似值。某些物件會使用不可分割的壓縮格式 (例如 gzip) 進行壓縮,因此 Spark 無法分割它們。
該NumPartitions值可能會因您的資料格式、壓縮、 AWS Glue 版本、 AWS Glue Worker 數量和 Spark 組態而有所不同。
例如,當您使用 Spark 載入單一 10 GB 的csv.gz物件時 DataFrame,Spark 驅動程式只會建立一個RDD磁碟分割 (NumPartitions=1),因為 gzip 是不可分割的。這會導致一個特定的 Spark 執行程序負載沉重,並且沒有任務分配給剩餘的執行者,如下圖所述。
在 Spark Web UI 階段索引標籤上檢查階段的實際工作數 (NumPartitions),或在程式碼df.rdd.getNumPartitions()中執行以檢查平行處理原則。
遇到 10 GB gzip 檔案時,請檢查產生該檔案的系統是否可以以可分割的格式產生檔案。如果這不是一個選項,您可能需要擴展叢集容量來處理檔案。若要對載入的資料有效率地執行轉換,您RDD需要使用 repartition 來重新平衡叢集中的 Worker。
手動確定分區的目標數
根據數據的屬性和 Spark 對某些功能的實現,即使基礎工作仍然可以並行化,您也可能會得到較低的NumPartitions價值。如果NumPartitions太小,請運行以增df.repartition(N)加分區的數量,以便處理可以分配到多個 Spark 執行程序。
在這種情況下,運行df.repartition(100)將NumPartitions從 1 增加到 100,創建 100 個數據分區,每個分區都有一個可以分配給其他執行者的任務。
此作業會平等repartition(N)地分割整個資料 (10 GB /100 個分割區 = 100 MB/ 分割區),避免資料偏移到特定分割區。
注意
執行隨機操作 (例如join) 時,會根據或的值動態增加或減少分割區的spark.sql.shuffle.partitions數目。spark.default.parallelism這有助於 Spark 執行程序之間更有效的數據交換。如需詳細資訊,請參閱 S park 文件
決定分割區的目標數目時,您的目標是最大限度地使用佈建的 AWS Glue Worker。 AWS Glue 工作人員的數量和 Spark 任務的數量是通過數量相關的vCPUs。星火為每個 v CPU 核心支持一個任務。在 3.0 AWS Glue 版或更新版本中,您可以使用以下公式計算分區的目標數量。
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
在此範例中,每個 G.1X 工作者會為 Spark 執行程式 () spark.executor.cores = 4 提供四個 v CPU 核心。Spark 支援每個 v CPU 核心一項工作,因此 G.1X Spark 執行程式可以同時執行四項工作 () numSlotPerExecutor。如果工作花費相等的時間,則此數目的分割區會充分利用叢集。但是,某些任務需要比其他任務更長的時間,從而創建閒置內核。如果發生這種情況,請考慮numPartitions乘以 2 或 3 來分解並有效地安排瓶頸任務。
分割區太多
過多的分區會創建過多的任務。這會導致 Spark 驅動程序的負載沉重,因為與分佈式處理相關的開銷,例如管理任務和 Spark 執行程序之間的數據交換。
如果工作中的分割區數量大於目標分割區數目,請考慮減少分割區數目。您可以使用下列選項來減少分割區:
-
如果您的文件大小非常小,請使用 AWS Glue groupFiles。您可以減少因啟動 Apache Spark 工作而產生的過多平行處理原則,以處理每個檔案。
-
用
coalesce(N)於將分割區合併在一起。這是一個低成本的過程。減少分區的數量時,優先coalesce(N)於repartition(N),因為repartition(N)執行洗牌以平均分配每個分區中的記錄數量。這會增加成本和管理開銷。 -
使用星火 3.x 自適應查詢執行。如 Apache Spark 中關鍵主題中所討論的,調適性查詢執行提供了自動合併分割區數目的函數。當您在執行之前無法知道分區數量時,可以使用此方法。
平行化資料載入 JDBC
Spark RDD 分區的數量由配置決定。請注意,預設情況下,只會執行單一工作,以透過SELECT查詢掃描整個來源資料集。
AWS Glue DynamicFrames 和 Spark 都 DataFrames 支援跨多個工作並行處理JDBC資料載入。這是通過使用where謂詞將一個查詢拆分為多個SELECT查詢來完成的。若要平行化讀取JDBC,請設定下列選項:
-
對於 AWS Glue DynamicFrame,設定
hashfield(或hashexpression)和hashpartition。若要深入瞭解,請參閱從JDBC表格 parallel 讀取。connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
對於星火 DataFrame,設定
numPartitionspartitionColumn、lowerBound、、和upperBound。若要深入瞭解,請參閱JDBC至其他資料庫。 df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
使用連接器時,將來自 DynamoDB 的資料載入平行化 ETL
星火RDD分區的數量由dynamodb.splits參數確定。若要平行化讀取來自 Amazon DynamoDB 作,請設定下列選項:
-
增加的值
dynamodb.splits。 -
遵循 Spark 中的連線類型和選項中所述的公式,將參數最佳化。ETL AWS Glue
從 Kinesis 資料串流平行化資料載入
Spark RDD 分割區的數量取決於來源 Amazon Kinesis Data Streams 中的碎片數量。如果您的資料串流中只有少數碎片,則只會有少數 Spark 工作。這可能會導致下游處理程序的平行度低。若要平行化從 Kinesis Data Streams 讀取,請設定下列選項:
-
從 Kinesis 資料串流載入資料時,增加碎片數量以獲得更多的平行處理。
-
如果您在微批次中的邏輯足夠複雜,請考慮在刪除不需要的資料欄之後,在批次開頭重新分割資料。
如需詳細資訊,請參閱最佳化 AWS Glue 串流ETL工作成本和效能的
資料載入後平行化工作
若要在資料載入後平行化工作,請使用下列選項增加RDD分割區數目:
-
重新分區數據以生成更多數量的分區,尤其是在負載本身無法並行化的情況下,尤其是在初始加載之後立即。
呼叫
repartition()DynamicFrame 或 DataFrame,指定分割區數目。一個好的經驗法則是可用內核數的兩到三倍。但是,在寫入分區資料表時,這可能會導致檔案爆炸(每個分割區都可能會在每個資料表分割區中產生一個檔案)。為了避免這種情況,您可以 DataFrame按列重新分區。這使用表分區列,以便在寫入之前組織數據。您可以指定較高數量的分區,而不會在表格分區上獲取較小的文件。但是,請小心避免資料偏差,在此情況下,某些分割區值最終會出現大部分資料,並延遲工作的完成。
-
當有洗牌時,增加
spark.sql.shuffle.partitions值。這也可以幫助在洗牌時解決任何內存問題。當您有超過 2,001 個隨機播放分割區時,Spark 會使用壓縮的記憶體格式。如果您的數字接近該值,您可能想要將
spark.sql.shuffle.paritions值設定為超過該限制,以取得更有效率的表示方式。
