本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
擴展叢集容量
如果您的任務花費太多時間,但執行器耗用足夠的資源,且 Spark 正在建立相對於可用核心的大量任務,請考慮擴展叢集容量。若要評估這是否適當,請使用下列指標。
CloudWatch 指標
-
檢查 CPU 負載和記憶體使用率,以判斷執行器是否耗用足夠的資源。
-
檢查任務執行的時間長度,以評估處理時間是否太長而無法達成您的效能目標。
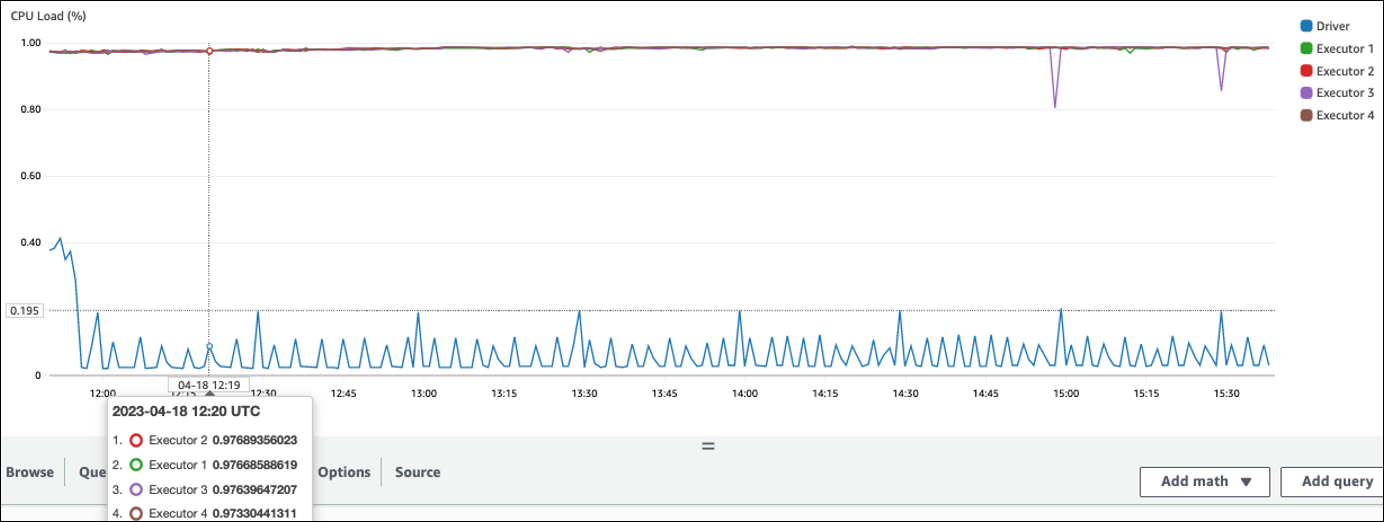
在下列範例中,四個執行器以超過 97% 的 CPU 負載執行,但在大約三個小時後仍未完成處理。
注意
如果 CPU 負載低,您可能無法受益於擴展叢集容量。
Spark UI
在任務索引標籤或階段索引標籤上,您可以看到每個任務或階段的任務數量。在下列範例中,Spark 已建立58100任務。

在執行器索引標籤上,您可以看到執行器和任務的總數。在下列螢幕擷取畫面中,每個 Spark 執行器都有四個核心,可以同時執行四個任務。
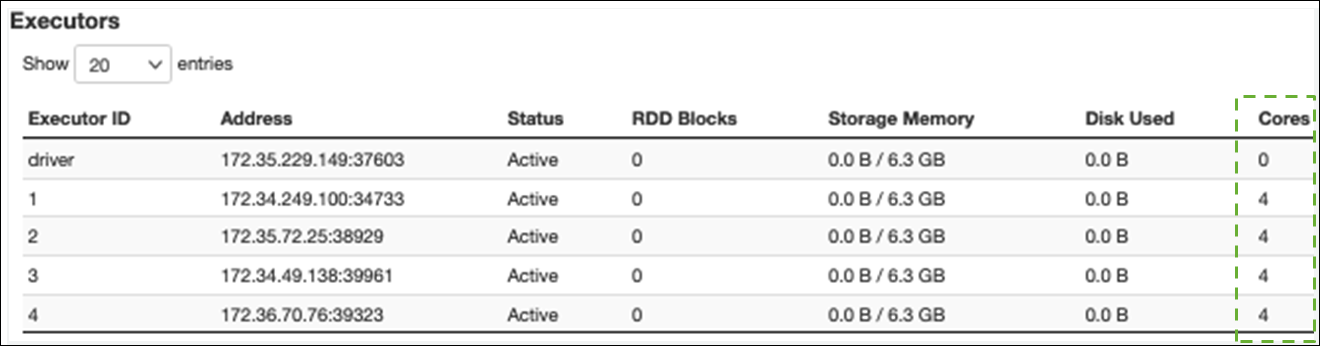
在此範例中,Spark 任務的數量 (58100) 遠大於執行器可同時處理的 16 個任務 (4 個執行器 × 4 個核心)。
如果您觀察到這些症狀,請考慮擴展叢集。您可以使用下列選項來擴展叢集容量:
-
Enable AWS Glue Auto Scaling – Auto Scaling 適用於 3.0 AWS Glue 版或更新版本的 AWS Glue 擷取、轉換和載入 (ETL) 和串流任務。自動新增 AWS Glue 和移除叢集中的工作者,取決於每個階段的分割區數量,或任務執行時產生微批次的速率。
如果您觀察到即使啟用 Auto Scaling 仍無法增加工作者數量的情況,請考慮手動新增工作者。不過,請注意,手動擴展一個階段可能會導致許多工作者在稍後階段閒置,因此成本更高,效能零增加。
啟用 Auto Scaling 之後,您可以在 CloudWatch 執行器指標中查看執行器的數量。使用下列指標來監控 Spark 應用程式中執行器的需求:
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors -
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
如需指標的詳細資訊,請參閱AWS Glue 使用 Amazon CloudWatch 指標進行監控。
-
-
向外擴展:增加工作者數量 AWS Glue – 您可以手動增加工作者數量 AWS Glue 。只有在您觀察到閒置工作者之前,才新增工作者。此時,新增更多工作者將增加成本,而不會改善結果。如需詳細資訊,請參閱平行處理任務。
-
擴展:使用較大的工作者類型 – 您可以手動變更 AWS Glue 工作者的執行個體類型,以使用具有更多核心、記憶體和儲存體的工作者。較大的工作者類型可讓您垂直擴展和執行密集型資料整合任務,例如記憶體密集型資料轉換、偏斜彙總,以及涉及 PB 資料的實體偵測檢查。
向上擴展也有助於 Spark 驅動程式需要更大容量的情況,例如,因為任務查詢計畫相當大。如需工作者類型和效能的詳細資訊,請參閱 AWS 大數據部落格文章使用新的大型工作者類型 G.4X 和 G.8X 擴展 AWS Glue Apache Spark 任務的規模
。 使用較大的工作者也可以減少所需的工作者總數,這可透過減少密集操作中的隨機播放來提高效能,例如聯結。
