本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
執行 Amazon Redshift 的概念驗證 (POC)
Amazon Redshift 是熱門的雲端資料倉儲,提供全受管的雲端服務,可與組織的 Amazon Simple Storage Service 資料湖、即時串流、機器學習 (ML) 工作流程、交易工作流程等整合。以下各節會引導您完成在 Amazon Redshift 上執行概念驗證 (POC) 的程序。此處的資訊可協助您設定 POC 的目標,並利用可自動化 POC 服務佈建和組態的工具。
注意
如需此資訊的 PDF 副本,請選擇 Amazon
執行 Amazon Redshift 的 POC 時,您會測試、證明和採用best-in-class安全功能、彈性擴展、輕鬆整合和擷取,以及靈活的分散式資料架構選項等功能。

請依照下列步驟執行成功的 POC。
步驟 1:範圍您的 POC

執行 POC 時,您可以選擇使用自己的資料,也可以選擇使用基準資料集。當您選擇自己的資料時,您可以對資料執行自己的查詢。使用基準資料時,範例查詢會與基準一起提供。如果您尚未準備好使用自己的資料執行 POC,請參閱使用範例資料集以取得更多詳細資訊。
一般而言,我們建議對 Amazon Redshift POC 使用兩週的資料。
首先執行下列動作:
識別您的業務和功能需求,然後向後工作。常見範例包括:更快速的效能、降低成本、測試新的工作負載或功能,或 Amazon Redshift 與其他資料倉儲之間的比較。
設定成為 POC 成功條件的特定目標。例如,從更快的效能,想出您要加速的前五個程序清單,並包含目前的執行時間以及所需的執行時間。這些可以是報告、查詢、ETL 程序、資料擷取,或任何您目前的痛點。
識別執行測試所需的特定範圍和成品。您需要遷移或持續擷取至 Amazon Redshift 的哪些資料集,以及執行測試以根據成功條件進行測量所需的查詢和程序為何? 有兩種方式可以進行:
攜帶您自己的資料
若要測試您自己的資料,請想出測試成功條件所需的最低可行資料成品清單。例如,如果您目前的資料倉儲有 200 個資料表,但您想要測試的報告只需要 20 個,則只能使用較小的資料表子集,以更快的速度執行 POC。
使用範例資料集
如果您尚未準備好自己的資料集,您仍然可以使用 TPC-DS
或 TPC-H 等產業標準基準資料集,在 Amazon Redshift 上開始執行 POC,並執行範例基準查詢以利用 Amazon Redshift 的強大功能。資料集建立後,可以從 Amazon Redshift 資料倉儲內存取。如需如何存取這些資料集和範例查詢的詳細說明,請參閱 步驟 2:啟動 Amazon Redshift。
步驟 2:啟動 Amazon Redshift

Amazon Redshift 透過快速、簡單且安全的大規模雲端資料倉儲,加速您獲得洞見的時間。您可以在 Redshift Serverless 主控台
設定 Amazon Redshift Serverless
第一次使用 Redshift Serverless 時,主控台會引導您完成啟動倉儲所需的步驟。您可能也符合帳戶中 Redshift Serverless 用量的額度資格。如需選擇免費試用的詳細資訊,請參閱 Amazon Redshift 免費試用版
如果您先前已在帳戶中啟動 Redshift Serverless,請遵循 Amazon Redshift 管理指南中的使用命名空間建立工作群組中的步驟。倉儲可用後,您可以選擇載入 Amazon Redshift 中可用的範例資料。如需有關使用 Amazon Redshift 查詢編輯器 v2 載入資料的資訊,請參閱《Amazon Redshift 管理指南》中的載入範例資料。
如果您要攜帶自己的資料,而不是載入範例資料集,請參閱 步驟 3:載入您的資料。
步驟 3:載入您的資料

啟動 Redshift Serverless 後,下一步是載入 POC 的資料。無論您是上傳簡單的 CSV 檔案、從 S3 擷取半結構化資料,還是直接串流資料,Amazon Redshift 都能提供快速且輕鬆地將資料從來源移入 Amazon Redshift 資料表的彈性。
選擇下列其中一種方法來載入您的資料。
上傳本機檔案
若要快速擷取和分析,您可以使用 Amazon Redshift 查詢編輯器 v2,輕鬆從本機桌面載入資料檔案。它能夠處理 CSV、JSON、AVRO、PARQUET、ORC 等各種格式的檔案。若要讓身為管理員的使用者能夠使用查詢編輯器 v2 從本機桌面載入資料,您必須指定常見的 Amazon S3 儲存貯體,而且使用者帳戶必須設定適當的許可。您可以使用查詢編輯器 V2 來遵循在 Amazon Redshift 中輕鬆且安全的資料載入
載入 Amazon S3 檔案
若要將資料從 Amazon S3 儲存貯體載入 Amazon Redshift,請先使用 COPY 命令,指定來源 Amazon S3 位置和目標 Amazon Redshift 資料表。確保 IAM 角色和許可已正確設定,以允許 Amazon Redshift 存取指定的 Amazon S3 儲存貯體。遵循教學課程:從 Amazon S3 載入資料以取得step-by-step指導。您也可以在查詢編輯器 v2 中選擇載入資料選項,以直接從 S3 儲存貯體載入資料。
持續擷取資料
Autocopy (預覽) 是 COPY 命令的延伸,可自動從 Amazon S3 儲存貯體載入連續資料。當您建立複製任務時,Amazon Redshift 會偵測何時在指定的路徑中建立新的 Amazon S3 檔案,然後自動載入這些檔案,而無需您的介入。Amazon Redshift 會追蹤載入的檔案,以確認檔案只載入一次。如需如何建立複製任務的說明,請參閱 複製工作
注意
自動複製目前處於預覽狀態,並且僅在特定佈建叢集中受支援 AWS 區域。若要建立預覽叢集以進行自動複製,請參閱建立 S3 事件整合,以自動從 Amazon S3 儲存貯體複製檔案。
載入串流資料
串流擷取提供從 Amazon Kinesis Data Streams
步驟 4:分析您的資料

建立 Redshift Serverless 工作群組和命名空間,並載入您的資料後,您可以從 Redshift Serverless 主控台
使用 Amazon Redshift 查詢編輯器 v2 的查詢
您可以從 Amazon Redshift 主控台存取查詢編輯器 v2。如需如何使用查詢編輯器 v2 設定、連線和執行查詢的完整指南,請參閱使用 Amazon Redshift 查詢編輯器 v2 簡化資料分析
或者,如果您想要在 POC 中執行負載測試,您可以透過以下步驟安裝和執行 Apache JMeter。
使用 Apache JMeter 執行負載測試
若要執行負載測試以模擬「N」使用者同時提交查詢至 Amazon Redshift,您可以使用 Apache JMeter
若要安裝並設定 Apache JMeter 以針對 Redshift Serverless 工作群組執行,請遵循使用 AWS Analytics Automation Toolkit 自動化 Amazon Redshift 負載測試
完成自訂 SQL 陳述式並完成測試計畫後,請儲存並針對 Redshift Serverless 工作群組執行測試計畫。若要監控測試進度,請開啟 Redshift Serverless 主控台
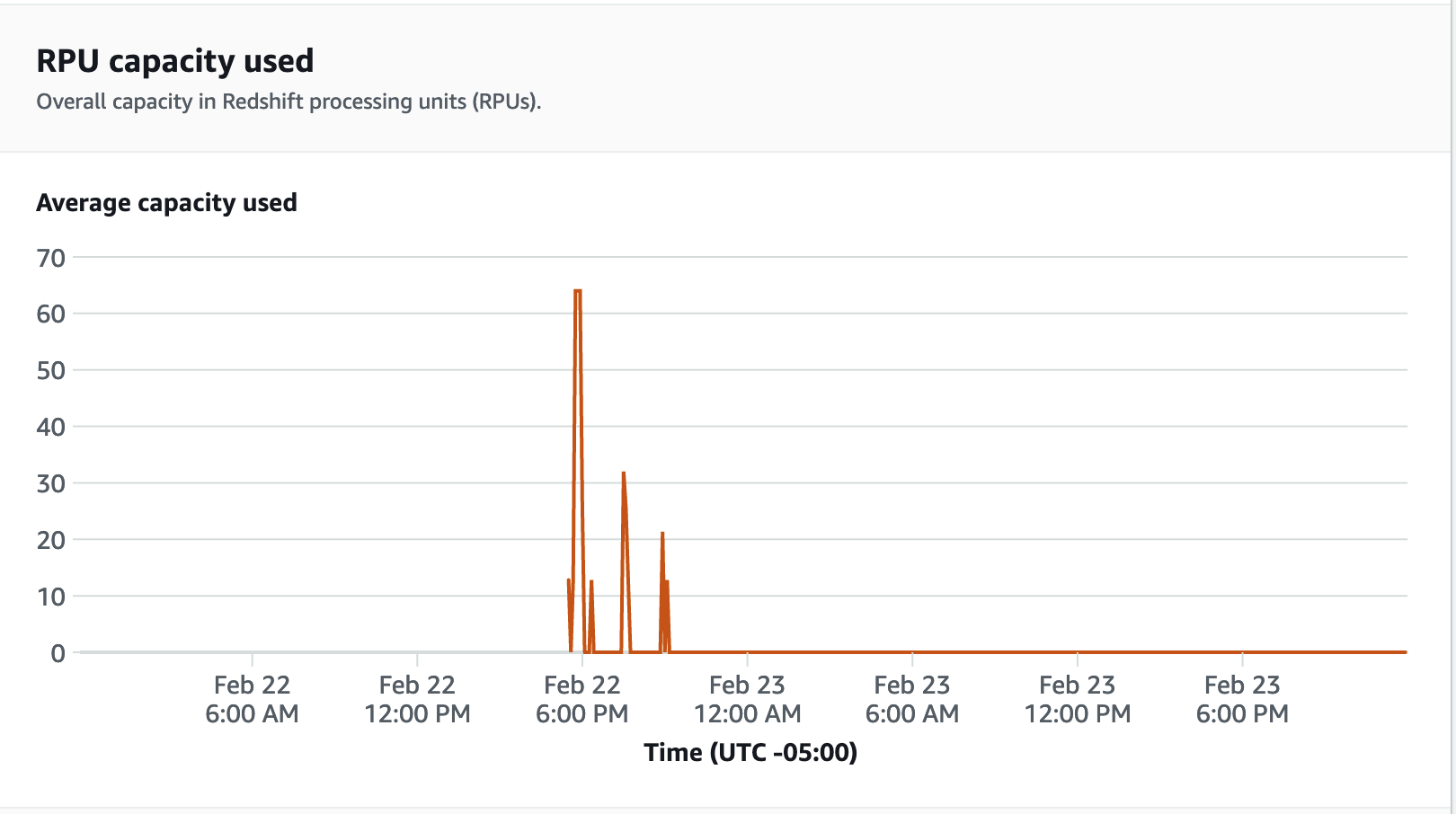
針對效能指標,請選擇 Redshift Serverless 主控台上的資料庫效能索引標籤,以監控資料庫連線和 CPU 使用率等指標。在這裡,您可以檢視圖形來監控使用的 RPU 容量,並觀察 Redshift Serverless 如何在工作群組上執行負載測試時自動擴展以滿足並行工作負載需求。
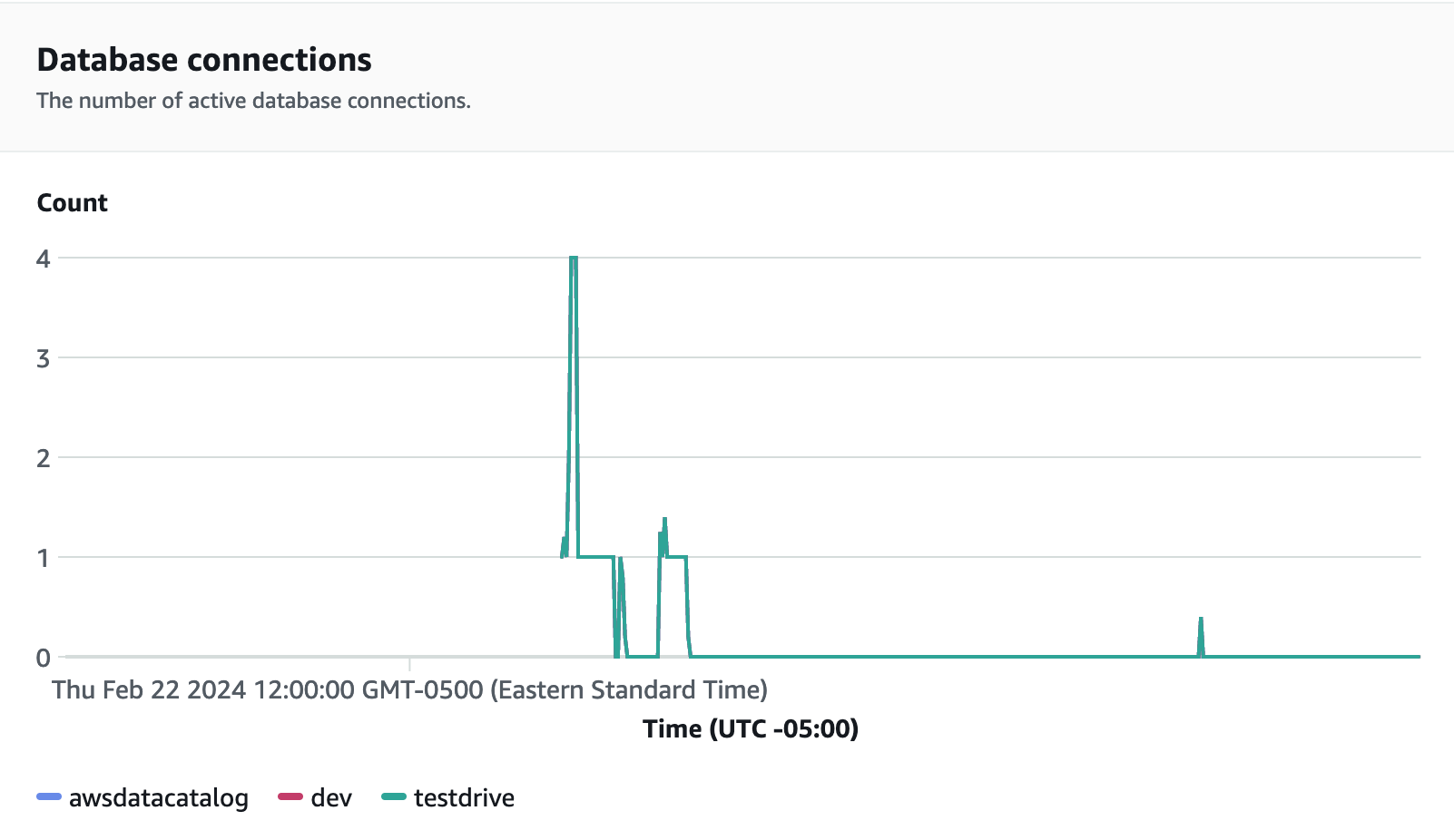
資料庫連線是在執行負載測試時監控的另一個實用指標,以了解您的工作群組在特定時間處理多個並行連線的方式,以滿足不斷增加的工作負載需求。
步驟 5:最佳化

Amazon Redshift 提供各種組態和功能以支援個別使用案例,讓數萬使用者每天處理數十位元組的資料,並為分析工作負載提供支援。在選擇這些選項時,客戶正在尋找工具,協助他們判斷最佳的資料倉儲組態,以支援其 Amazon Redshift 工作負載。
試駕
您可以使用 Test Drive
