本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
設定並啟動超參數調校任務
重要
允許 Amazon SageMaker Studio 或 Amazon SageMaker Studio Classic 建立 Amazon SageMaker 資源的自訂 IAM 政策也必須授予許可,才能將標籤新增至這些資源。需要將標籤新增至資源的許可,因為 Studio 和 Studio Classic 會自動標記他們建立的任何資源。如果 IAM 政策允許 Studio 和 Studio Classic 建立資源,但不允許標記,則嘗試建立資源時可能會發生「AccessDenied」錯誤。如需詳細資訊,請參閱提供標記 SageMaker AI 資源的許可。
AWS Amazon SageMaker AI 的 受管政策 提供建立 SageMaker 資源的許可,已包含建立這些資源時新增標籤的許可。
超參數是高階參數,會在模型訓練期間影響學習程序。如要取得最佳的模型預測,您可以最佳化超參數組態或設定超參數值。尋找最佳組態的程序稱為超參數調校。若要設定並啟動超參數調校任務,請完成這些指南中的步驟。
超參數調校任務的設定
若要指定超參數調校任務的設定,請在建立調校任務時定義一個 JSON 物件。將此 JSON 物件作為 HyperParameterTuningJobConfig 參數的值傳遞給 CreateHyperParameterTuningJob API。
在此 JSON 物件中,指定下列項目:
在這個 JSON 物件中,請指定:
-
HyperParameterTuningJobObjective— 用來評估超參數調校任務所啟動之訓練任務效能的目標指標。 -
ParameterRanges— 調校式超參數在最佳化期間可使用的值範圍。如需更多資訊,請參閱定義超參數範圍 -
RandomSeed— 用來初始化虛擬亂數產生器的值。設定隨機種子可讓超參數調校搜尋策略為相同的調校任務產生更一致的組態 (選用)。 -
ResourceLimits— 超參數調校任務可使用的訓練與平行訓練任務的數量上限。
下列程式碼範例會示範如何使用內建的 XGBoost 演算法來設定超參數調校任務。此程式碼範例說明如何定義 eta、alpha、min_child_weight 和 max_depth 超參數的範圍。如需有關這些和其他超參數的詳細資訊,請參閱 XGBoost 參數
在此程式碼範例中,超參數調校任務的目標指標會尋找可最大化 validation:auc 的超參數組態。SageMaker AI 內建演算法會自動將目標指標寫入 CloudWatch Logs。下列程式碼範例也示範了如何設定 RandomSeed。
tuning_job_config = { "ParameterRanges": { "CategoricalParameterRanges": [], "ContinuousParameterRanges": [ { "MaxValue": "1", "MinValue": "0", "Name": "eta" }, { "MaxValue": "2", "MinValue": "0", "Name": "alpha" }, { "MaxValue": "10", "MinValue": "1", "Name": "min_child_weight" } ], "IntegerParameterRanges": [ { "MaxValue": "10", "MinValue": "1", "Name": "max_depth" } ] }, "ResourceLimits": { "MaxNumberOfTrainingJobs": 20, "MaxParallelTrainingJobs": 3 }, "Strategy": "Bayesian", "HyperParameterTuningJobObjective": { "MetricName": "validation:auc", "Type": "Maximize" }, "RandomSeed" : 123 }
設定訓練任務
超參數調校任務將啟動訓練任務,以尋找超參數的最佳組態。這些訓練任務應使用 SageMaker AI CreateHyperParameterTuningJob API 設定。
若要設定訓練任務,請定義 JSON 物件,並將其傳遞為 TrainingJobDefinition 內的 CreateHyperParameterTuningJob 參數值。
在此 JSON 物件中,您可以指定下列項目:
-
AlgorithmSpecification— 包含訓練演算法和相關中繼資料的 Docker 映像檔登錄檔路徑。若要指定演算法,您可以在 Docker容器或 SageMaker AI 內建演算法 (必要) 內使用自己的自訂內建演算法。 SageMaker -
InputDataConfig— 輸入配置,包括訓練和測試資料 (必要) 的ChannelName、ContentType和資料來源。 -
InputDataConfig— 輸入配置,包括訓練和測試資料 (必要) 的ChannelName、ContentType和資料來源。 -
演算法輸出的儲存位置。指定您要用來存放訓練任務輸出的 S3 儲存貯體。
-
RoleArn– SageMaker AI 用來執行任務的 AWS Identity and Access Management (IAM) 角色的 Amazon Resource Name (ARN)。任務包括讀取輸入資料、下載 Docker 映像檔、將模型成品寫入 S3 儲存貯體、將日誌寫入 Amazon CloudWatch Logs,以及將指標寫入 Amazon CloudWatch (必要)。 -
StoppingCondition— 訓練任務在停止之前可執行的最大執行期 (以秒為單位)。此值應大於訓練模型所需的時間 (必要)。 -
MetricDefinitions— 定義訓練任務發出之任何指標的名稱和常規表達式。只有當您使用自訂訓練演算法時,才定義指標。下列程式碼中的範例使用內建演算法,該演算法已定義指標。如需定義指標 (選用) 的詳細資訊,請參閱定義指標。 -
TrainingImage— 指定訓練演算法的 Docker容器映像檔 (選用)。 -
StaticHyperParameters— 超參數在調校任務中不調校的超參數名稱和值 (選用)。
在下列程式碼範例中,系統會設定 搭配 Amazon SageMaker AI 的 XGBoost 演算法 內建演算法的 eval_metric、num_round、objective、rate_drop 和 tweedie_variance_power 參數的靜態值。
命名並啟動超參數調校任務
設定超參數調校任務後,您可以透過呼叫 CreateHyperParameterTuningJob API 來啟動它。下列程式碼範例使用了 tuning_job_config 和 training_job_definition。這些是在前兩個程式碼範例中所定義的,以建立超參數調校任務。
tuning_job_name = "MyTuningJob" smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name, HyperParameterTuningJobConfig = tuning_job_config, TrainingJobDefinition = training_job_definition)
檢視訓練任務的狀態
檢視超參數調校任務啟動的訓練任務狀態
-
在超參數調校任務清單中,選擇您已啟動的任務。
-
選擇 Training jobs (訓練任務)。
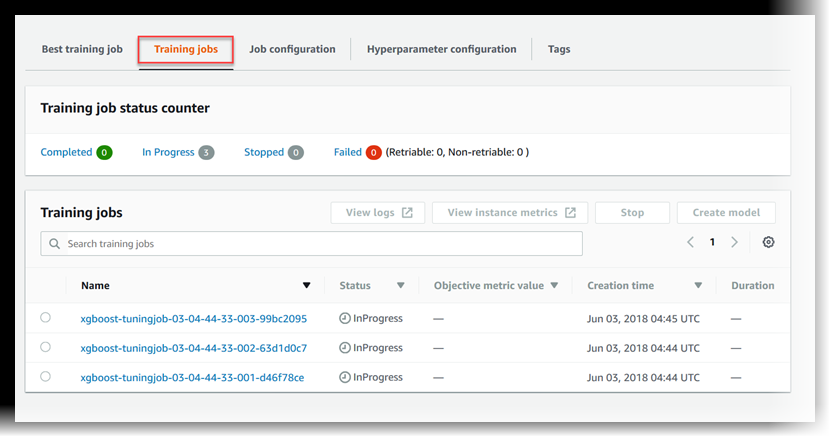
-
檢視每個訓練任務的狀態。若要查看任務的詳細資訊,請選擇訓練任務清單中的某個任務。若要查看超參數調校任務啟動之所有訓練任務的狀態摘要,請參閱訓練任務狀態計數器。
訓練任務可以是:
-
Completed— 訓練任務已成功完成。 -
InProgress— 訓練任務進行中。 -
Stopped— 訓練任務在完成前已手動停止。 -
Failed (Retryable)— 訓練任務失敗,但可以重試。只有當訓練任務是因內部服務發生錯誤而失敗時,才可以重試失敗的任務。 -
Failed (Non-retryable)— 訓練任務失敗,且無法重試。用戶端發生錯誤時,即無法重試失敗的訓練任務。
注意
您可以停止超參數調校任務並刪除基礎資源,但任務本身無法刪除。
-
檢視最佳訓練任務
超參數調校任務會使用每個訓練任務傳回的目標指標,來評估訓練任務。當超參數調校任務正在進行時,最佳訓練任務就是目前傳回最佳目標指標的任務。當超參數調校任務完成之後,最佳訓練任務就是傳回最佳目標指標的任務。
若要查看最佳的訓練任務,請選擇最佳訓練任務。

若要將最佳訓練任務部署為您可以在 SageMaker AI 端點託管的模型,請選擇建立模型。
後續步驟
