本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon SageMaker 自動駕駛儀資料探索報告
Amazon SageMaker 自動輔助駕駛會自動清理和預先處理您的資料集。高品質資料可提升機器學習效率,並產生可進行更準確預測的模型。
由客戶提供的資料集存在一些問題,這些問題需要部份專業領域知識才能著手進行修復,無法自動解決。例如,迴歸問題的目標欄中,較大的極端值可能會導致出現非極端值的次最佳預測。根據建模目標,極端值可能需要被移除。如果目標欄被意外包含為輸入特徵之一,最終模型雖能在驗證時有良好表現,但對於未來的預測毫無價值。
為了協助客戶發現這類問題,Autopilot 提供資料探勘報告,其中包含資料潛在問題的深入分析。該報告還建議如何處理這些問題。
針對每項 Autopilot 任務,系統會產生包含報告的資料探勘筆記本。報告儲存在 Amazon S3 儲存貯體,可從輸出路徑存取。資料探勘報告的路徑通常遵循以下模式。
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMakerAutopilotDataExplorationNotebook.ipynb
資料探索筆記本的位置可以使用儲存在中DataExplorationNotebookLocation的DescribeAutoMLJob作業回應,從 Autopilot API 取得。
從 SageMaker Studio 經典版執行自動輔助駕駛時,您可以使用下列步驟開啟資料探索報告:
-
從左側導覽窗格
 中選擇「首頁」圖示,以檢視頂層的 Amazon SageMaker Studio 傳統版導覽功能表。
中選擇「首頁」圖示,以檢視頂層的 Amazon SageMaker Studio 傳統版導覽功能表。 -
從主要工作區域中,選取 AutoML 卡片。這會開啟新的 Autopilot 索引標籤。
-
在 名稱欄位中,選擇您想要檢閱之資料探勘筆記本的 Autopilot 任務。這將開啟新的 Autopilot 任務索引標籤。
-
在 Autopilot 任務索引標籤的右上角,選取開啟資料探勘筆記本。
資料探勘報告會在訓練程序開始之前,從您的資料產生。這能讓您停止可能導致無意義結果的 Autopilot 任務。同樣地,在重新執行 Autopilot 之前,您可以提出對您的資料集的任何問題或改進。如此一來,您可以使用領域專業知識,手動進行改善資料品質,再於規劃較佳的資料集上訓練模型。
資料報告僅包含靜態 Markdown,可以在任何 Jupyter 環境中開啟。包含報告的筆記本可以轉換為其他格式,例如作為 PDF 格式匯出或轉換為 HTML 檔案。如需有關轉換的更多資訊,請參閱使用 nbconvert 指令碼將 Jupyter 筆記本轉換為其他格式。
資料集摘要
此資料集摘要提供您的資料集關鍵統計資料,包含資料列數量、資料欄數、重複的資料列百分比和遺失目標值。它的目的是在 Amazon SageMaker Autopilot 偵測到的資料集發生問題且可能需要您介入時,提供快速提醒。這些深入分析產生之後,會被分類為高嚴重性或低嚴重性的警告。分類取決於問題會對模型效能的信賴度造成不利影響。
高嚴重性和低嚴重性洞察,會以快顯視窗的形式顯示在摘要中。我們對大多數的洞察結果提供了建議,讓您了解如何確認資料集中可能存在需要您注意的問題。我們還提供如何解決這些問題的相關提案。
Autopilot 提供有關資料集中遺失或無效目標值的額外統計資料,協助您偵測高嚴重性洞察可能沒有掌握到的其他問題。如果出現一部分特定類型的非預期資料欄,可能表示您要使用的某些資料欄可能會從資料集中遺失。這也可能表示資料的準備或儲存方式發生問題。修正 Autopilot 引起您注意的這些資料問題,可以改善資料訓練之機器學習模型的效能。
高嚴重性洞察會顯示在摘要和報告的其他相關章節中。通常根據資料報告的區段,來提供高嚴重性和低嚴重性洞察的範例。
目標分析
本章節中,顯示與目標欄中值分佈所相關的各種高嚴重性和低嚴重性洞察。檢查目標欄是否包含正確的值。目標欄中的值不正確,可能會導致機器學習模型無法滿足預期的業務目的。本章節介紹高嚴重性和低嚴重性的資料洞察。以下是數個範例。
-
極端目標值 - 偏態或不尋常的迴歸目標發佈,例如重尾目標。
-
高或低目標基數 - 指分類問題中,不常見的類別標籤的數量,或大量且唯一的類別。
對於迴歸和分類問題類型,會顯示目標欄中的無效值,例如數值無限大、NaN或目標欄中出現空格。視問題類型而定,會顯示不同的資料集統計資料。迴歸問題的目標欄值的發佈,可讓您驗證發佈是否符合您的預期。
下列螢幕擷取畫面顯示 Autopilot 資料報告,其中包含資料集中平均值、中位數、最小值、最大值、極端值百分比等統計資料。螢幕擷取畫面包含一個長條圖,顯示目標欄中標籤的發佈。長條圖顯示水平軸上的目標欄值,而計數在垂直軸上。螢幕擷取畫面的極端值百分比區段會出現一個方塊,重點標示出此統計資料的顯示位置。
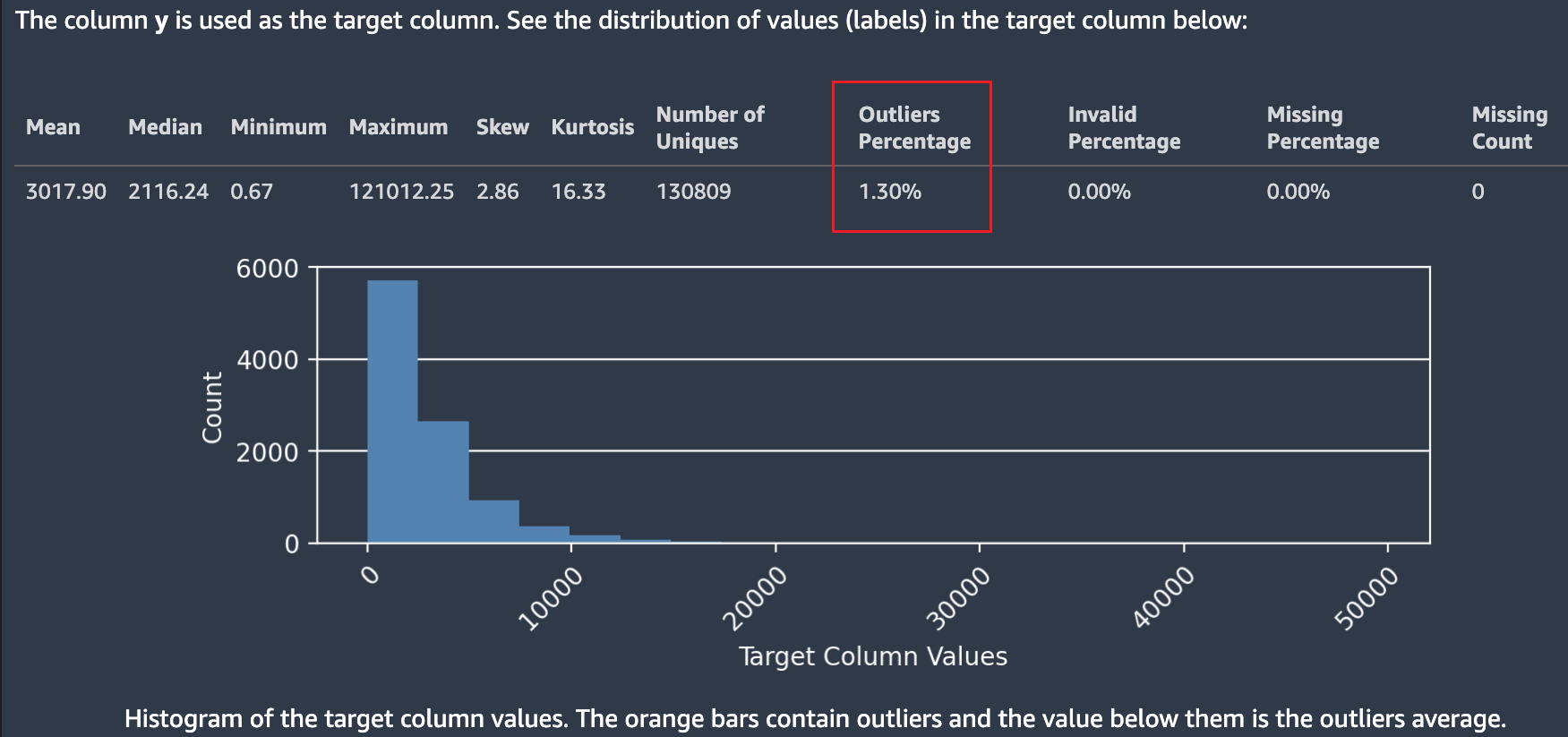
顯示有關目標值及其發佈的多個統計資料。如果有任何極端值、無效值或缺少的百分比大於零,這些值將背呈現,以便您可以調查資料包含無法使用的目標值的原因。某些未使用目標值會重點標示為低嚴重性洞察警告。
在下面的螢幕擷取畫面中,目標欄不慎加入了一個 ` 符號,這導致無法解析目標數值。低嚴重性洞察:出現無效的目標值 警告。範例中的警告指出,目標欄中標籤的 0.14% 無法轉換為數值。最常見的非數字值是:["-3.8e-05","-9-05","-4.7e-05","-1.4999999999999999e-05","-4.3e-05"]。這通常表示資料收集或處理方面存在問題。Amazon SageMaker 自動駕駛儀會忽略帶有無效目標標籤的所有觀測結果。」

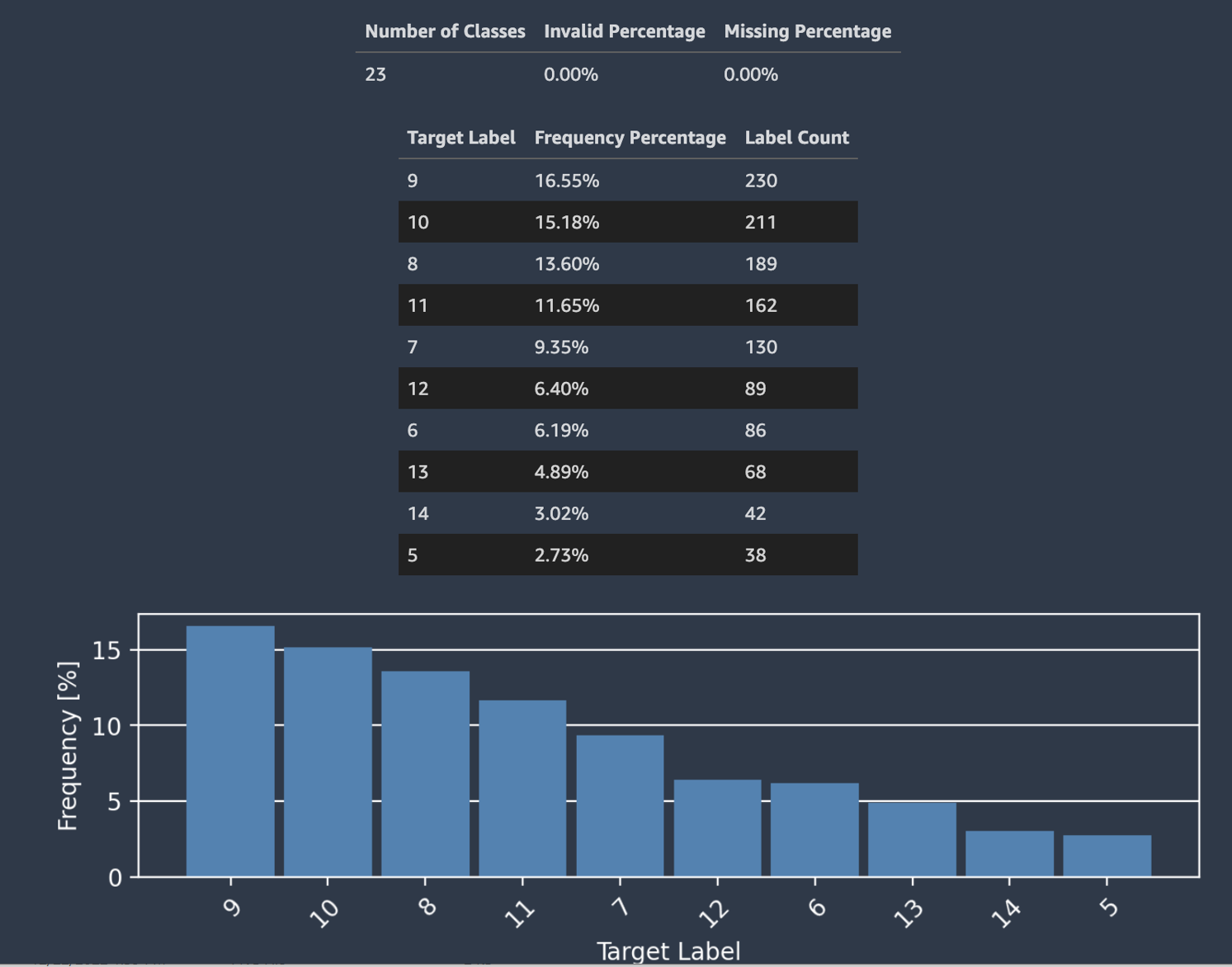
Autopilot 還提供一個長條圖,顯示分類標籤的發佈。
下面的螢幕擷取畫面顯示與您的目標欄的統計資訊的相關範例,包含類別數量、缺少或無效的值。一件長條圖,其水平軸上有目標標籤,垂直軸上有頻率顯示每個標籤類別的發佈。
注意
您可以在報告筆記本底部的定義章節中,找到本章節及其他章節中,所顯示的所有術語的定義。
資料範例
Autopilot 提供資料的實際範例,協助您發現資料集的問題。範例表格會水平捲動。檢查範例資料,確認資料集中是否存在所有必要的資料欄。
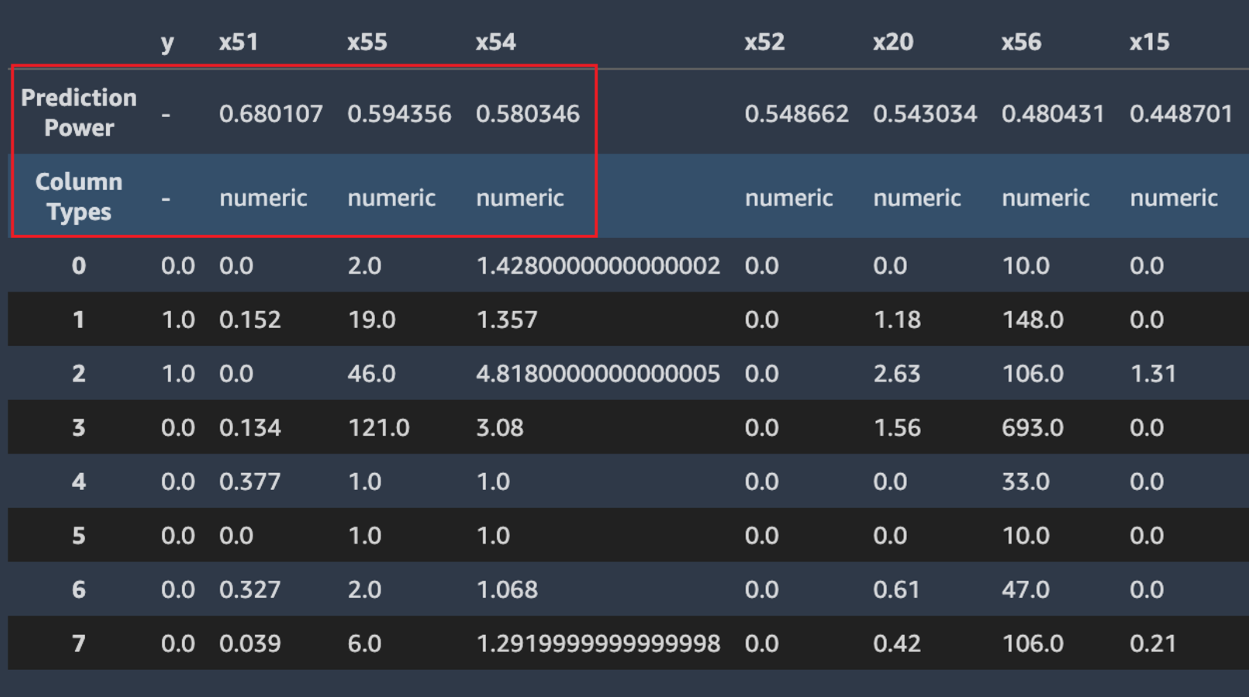
Autopilot 亦會計算預測力的量值,可用來識別特徵與目標變數之間的線性或非線性關係。0的的值表示此功能在預測目標變數時沒有預測值。1的值表示目標變數的最高預測力。有關預測能力的更多資訊,請參閱定義區段區段。
注意
不推薦使用預測力來替代特徵重要性。只有在確定預測力是適合您使用案例的方法時,才使用此特徵。
以下螢幕擷取畫面顯示了一個資料範例範本。第一列包含資料集中每個資料欄的預測力。第二列包含欄位資料類型。後續列包含標籤。這些資料欄包括目標欄,後面是每個特徵欄。每個特徵欄都有相關的預測力,在此螢幕擷取畫面以方塊重點標示。在此範例中,包含特徵x51的資料欄具有目標變數y的預測力0.68。特徵x55的預測力略低於0.59。
重複的資料列
如果資料集中存在重複的資料列,Amazon SageMaker Autopilot 會顯示這些資料列的範例。
注意
在將資料集提供給 Autopilot 之前,不建議先透過向上取樣來平衡資料集。這可能會導致 Autopilot 訓練模型的驗證分數不正確,並且生成的模型可能無法使用。
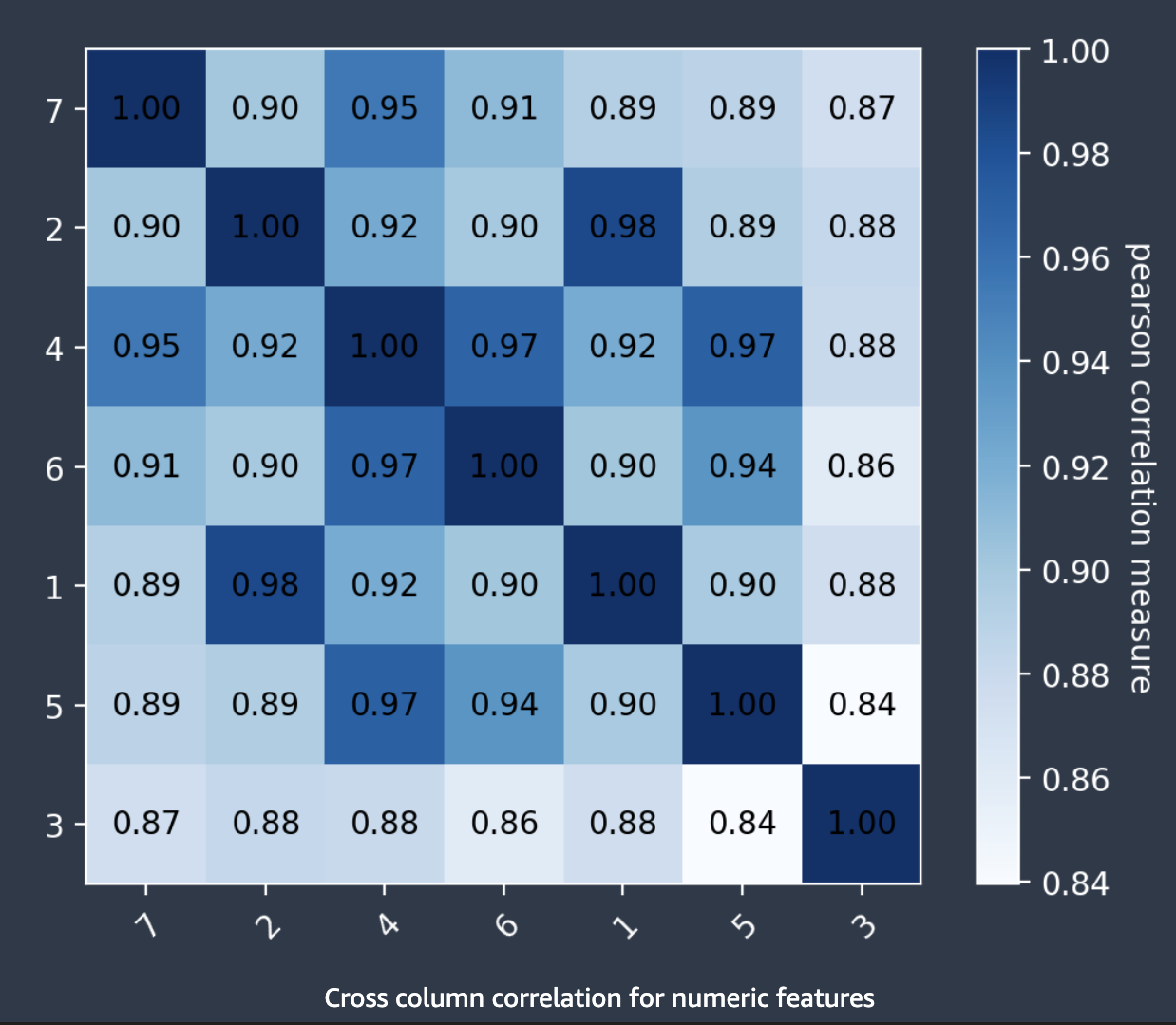
跨欄相互關聯
Autopilot 使用 Pearsons 相互關聯係數,這是兩個特徵之間線性相關性的測量方法,以生成相互關聯矩陣。在相互關聯矩陣中,數值特徵繪製在水平軸和垂直軸上,並在其交集繪製 Pearsons 相互關聯。兩個特徵之間的相互關聯越高,係數越高,最大值為|1|。
-
數值為
-1時,表示這些特徵之間存在完全的負向相關。 -
當一個特徵與自身相關時,數值為
1,表示完全正向相關。
您可以透過相互關聯矩陣中的資訊,來移除高度相關的特徵。較少的特徵數量可降低模型過度擬合的機會,並且可以透過兩種方式降低生產成本。它減少了所需的 Autopilot 執行期,並且對於某些應用程式,可以降低資料收集的成本。
以下螢幕擷取畫面顯示了7特徵之間相互關聯矩陣的範例。每個特徵都會以矩陣顯示在水平軸和垂直軸上。Pearsons 相互關聯顯示在兩個特徵之間的交集處。每個特徵交集都有一個與其關聯對象的顏色。相互關聯性越高,色調越暗。最暗的色調佔據矩陣的對角線,其中每個特徵都與自身相關,代表完全的相互關聯性。
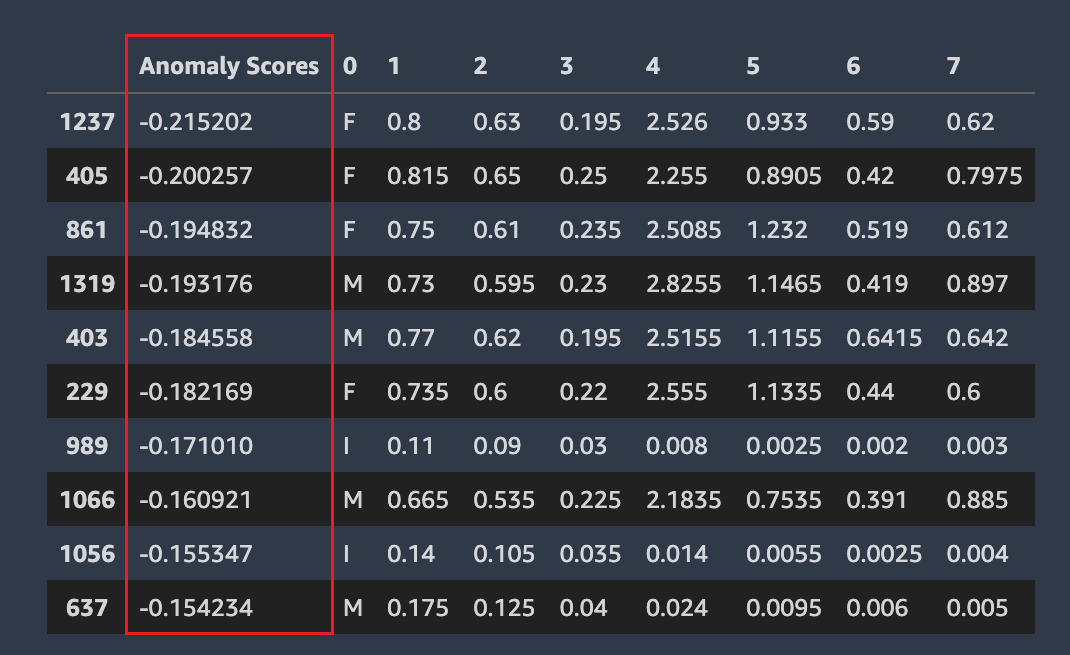
異常列
Amazon SageMaker 自動輔助駕駛會偵測資料集中的哪些資料列可能是異常的。然後,它會為每一列指派異常狀況分數。具有負面異常狀況分數的列被視為異常。
下列螢幕擷取畫面顯示 Autopilot 分析中,包含異常值的資料列之輸出。包含異常分數的資料欄會顯示在每個資料列的資料集欄位旁。
缺少值、基數和描述性統計
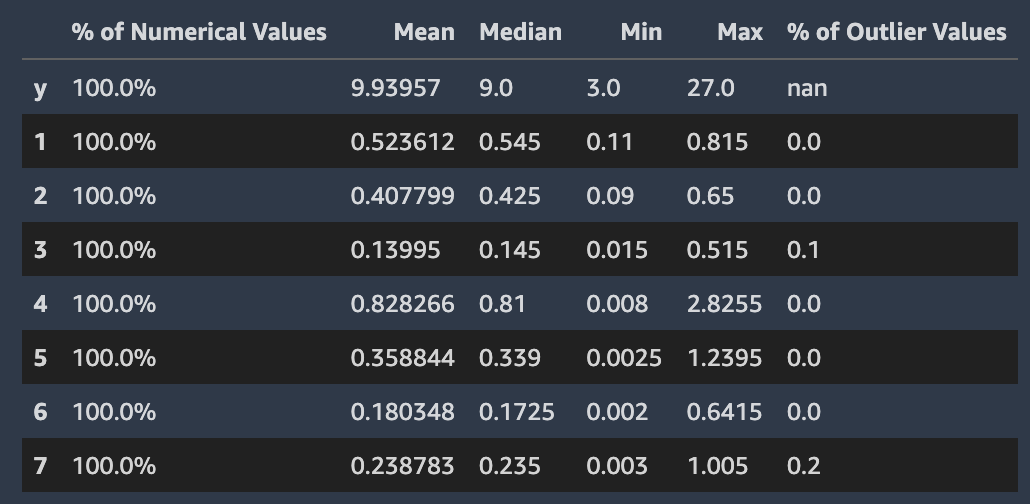
Amazon SageMaker Autopilot 會檢查資料集中個別資料欄的屬性並進行報告。在呈現此分析的資料報告的每個區段中,內容會依序排列。這樣您就可以先檢查最 “可疑” 的值。使用這些統計資料,您可以改善個別欄位的內容,並改善 Autopilot 所產生的模型品質。
Autopilot 計算包含它們的列中的分類值的幾個統計資訊。其中包含唯一項目的數量,以及用於文字的唯一字數。
Autopilot 計算包含它們的列中的數值的幾個標準統計資訊。下列映像說明這些統計資料,包含平均值、中間值、下限和最大值,以及數值類型和極端值的百分比。