本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
SageMaker AI 分散式資料平行化程式庫簡介
SageMaker AI 分散式資料平行化 (SMDDP) 程式庫是一種集體通訊程式庫,可改善分散式資料平行訓練的運算效能。SMDDP 程式庫透過提供下列項目來解決關鍵集體通訊操作的通訊額外負荷。
-
程式庫提供
AllReduce最佳化 AWS。AllReduce是一種金鑰操作,用於在分散式資料訓練期間,在每次訓練反覆運算結束時同步 GPUs 的漸層。 -
程式庫提供
AllGather針對 最佳化 AWS。AllGather是碎片資料平行訓練中使用的另一個關鍵操作,這是一種記憶體效率的資料平行處理技術,由熱門程式庫提供,例如 SageMaker AI 模型平行處理 (SMP) 程式庫、DeepSpeed 零冗餘最佳化工具 (ZeRO) 和 PyTorch 完全碎片資料平行處理 (FSDP)。 -
程式庫透過充分利用 AWS 網路基礎設施和 Amazon EC2 執行個體拓撲來執行最佳化node-to-node通訊。
SMDDP 程式庫可以透過近線性擴展效率,在擴展訓練叢集時提供效能提升,進而提高訓練速度。
注意
SageMaker AI 分散式訓練程式庫可透過 SageMaker Training 平台中 PyTorch 和 Hugging Face 的 AWS 深度學習容器取得。若要使用這些程式庫,您必須透過適用於 Python 的 SDK (Boto3) 或 AWS Command Line Interface使用 SageMaker Python SDK 或 SageMaker API。整個文件中,指示和範例著重於如何將分散式訓練程式庫與SageMaker Python SDK 搭配使用。
針對 AWS 運算資源和網路基礎設施最佳化的 SMDDP 集體通訊操作
SMDDP 程式庫提供針對 AWS 運算資源AllReduce和網路基礎設施最佳化的 和 AllGather集體操作實作。
SMDDP AllReduce 集體操作
SMDDP 程式庫可實現 AllReduce 操作與向後傳遞的最佳重疊,大幅提高 GPU 利用率。它透過最佳化 CPU 和 GPU 之間的核心操作,實現了近線性的擴展效率和更快的訓練速度。程式庫在 GPU 運算梯度時平行執行 AllReduce,而不會佔用額外的 GPU 週期,進而使程式庫能夠實現更快的訓練。
-
利用 CPU:程式庫使用 CPU 至
AllReduce梯度,從 GPU 卸載此任務。 -
改善 GPU 使用率:叢集的 GPU 專注於運算漸層,改善整個訓練的使用率。
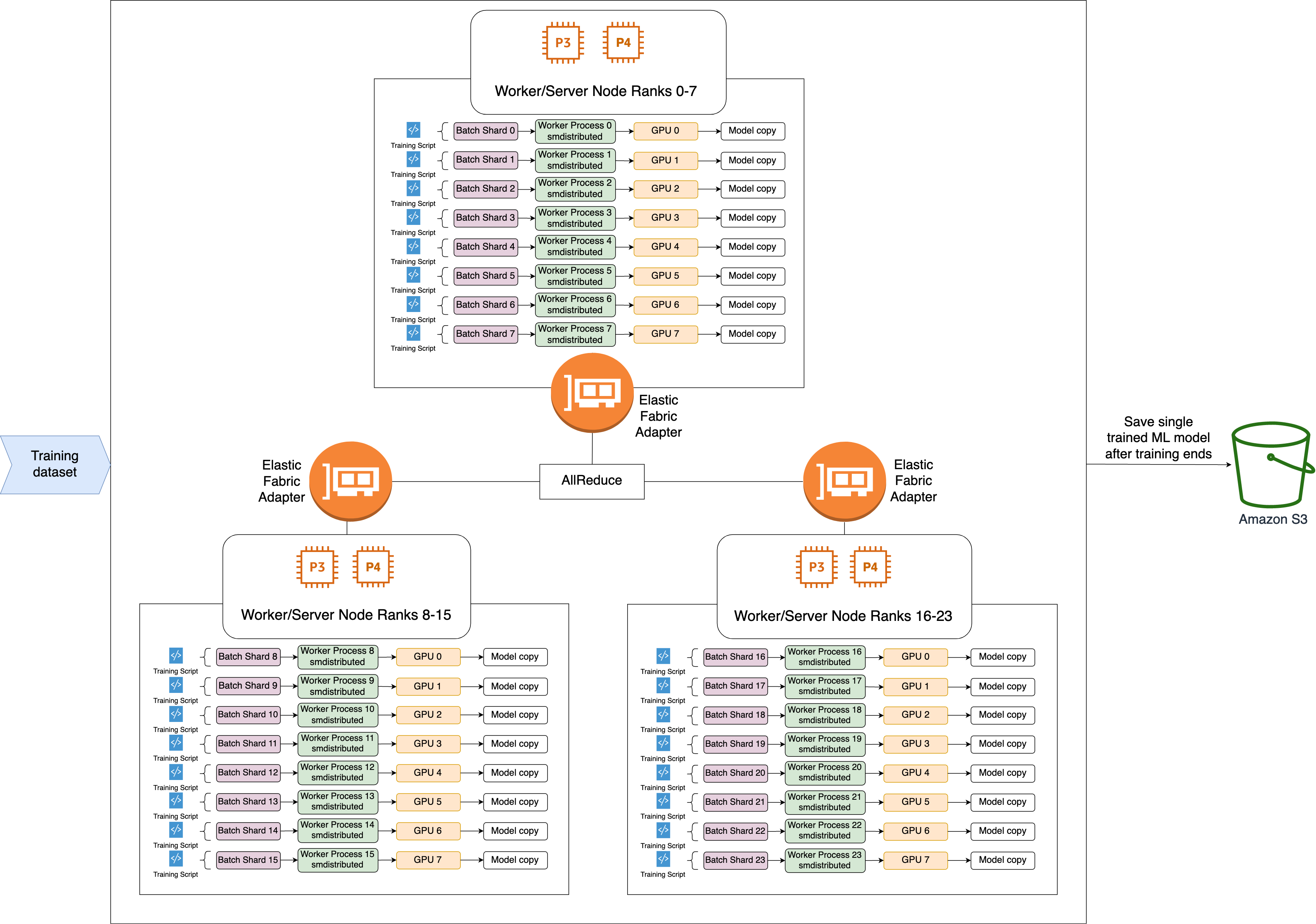
以下是 SMDDP AllReduce 操作的高階工作流程。
-
程式庫指派 GPU 排名 (工作者)。
-
在每次反覆運算時,程式庫會將每個全域批次除以工作者總數 (世界大小),並將小批次 (批次碎片) 指派給工作者。
-
全域批次的大小為
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard)。 -
批次碎片 (小批次) 是每個 GPU (工作者) 每次反覆運算的已指派資料集子集。
-
-
程式庫會在每個工作者上啟動訓練指令碼。
-
程式庫在每次迭代結束時,會管理來自工作者的模型權重和漸層的副本。
-
程式庫會同步處理工作者中的模型權重和漸層,以彙總單一訓練的模型。
下列架構圖顯示程式庫如何為 3 個節點的叢集設定資料平行處理的範例。
SMDDP AllGather 集體操作
AllGather 是一種集體操作,其中每個工作者都從輸入緩衝區開始,然後將所有其他工作者的輸入緩衝區串連或收集到輸出緩衝區。
注意
SMDDP AllGather集體操作可在適用於 PyTorch v2.0.1 和更新版本的 smdistributed-dataparallel>=2.0.1和 AWS 深度學習容器 (DLC) 中使用。
AllGather 大量用於分散式訓練技術,例如碎片資料平行化,其中每個個別工作者都有一部分的模型或碎片層。工作者會在向前和向後傳遞之前呼叫 AllGather,以重建碎片圖層。所有參數都收集完畢後,向前和向後通過會繼續。在向後傳遞期間,每個工作者也會呼叫 ReduceScatter 來收集 (減少) 梯度,並將它們分解 (散射) 為梯度碎片,以更新對應的碎片層。如需這些集體操作在碎片資料平行化中的角色詳細資訊,請參閱 SMP 程式庫在碎片資料平行化上的實作、DeepSpeed 文件中的 ZeRO
由於每次迭代運算都會呼叫 AllGather 等集體操作,因此它們是 GPU 通訊額外負荷的主要因素。這些集體操作的更快速運算會直接轉換為較短的訓練時間,而不會對收斂造成副作用。為了達成此目的,SMDDP 程式庫提供針對 P4d 執行個體AllGather 功能。
SMDDP AllGather 使用以下技術來改善 P4d 執行個體的運算效能。
-
它透過具有網格拓撲的 Elastic Fabric Adapter (EFA)
網路,在執行個體 (節點間) 之間傳輸資料。EFA 是 AWS 低延遲和高輸送量的網路解決方案。節點間網路通訊的網格拓撲更符合 EFA 和 AWS 網路基礎設施的特性。相較於涉及多個封包跳轉的 NCCL 環形或樹狀拓撲,SMDDP 可避免從多個跳轉累積延遲,因為它只需要一個跳轉。SMDDP 實作網路速率控制演算法,在網格拓撲中平衡工作負載與每個通訊對等,並實現更高的全球網路輸送量。 -
它採用以 NVIDIA GPUDirect RDMA 技術 (GDRCopy) 為基礎的低延遲 GPU 記憶體複製程式庫
,來協調本機 NVLink 和 EFA 網路流量。GDRCopy 是由 NVIDIA 提供的低延遲 GPU 記憶體複製程式庫,可在 CPU 程序與 GPU CUDA 核心之間提供低延遲通訊。使用此技術,SMDDP 程式庫能夠將節點內和節點間資料移動管道化。 -
它減少了 GPU 串流多處理器的使用,以提高執行模型核心的運算能力。P4d 和 P4de 執行個體配備 NVIDIA A100 GPU,每個 GPU 具有 108 個串流多處理器。雖然 NCCL 最多需要 24 個串流多處理器來執行集體操作,但 SMDDP 會使用少於 9 個串流多處理器。模型運算核心會挑選儲存的串流多處理器,以加快運算速度。
