本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Debugger 分析報告解析
本節將引導您一個區段一個區段完成 Debugger 分析報告。本分析報告是由監視和效能分析的內建規則所產生。本報告僅顯示發現問題之規則的結果圖表。
重要
報告中的圖表和建議僅用於提供資訊,並非絕對。由您負責對資訊進行您自己獨立的評估。
訓練工作總結
在報告的開頭,Debugger 會提供訓練工作的摘要。在本節中,您可以概觀不同訓練階段的持續時間和時間戳記。
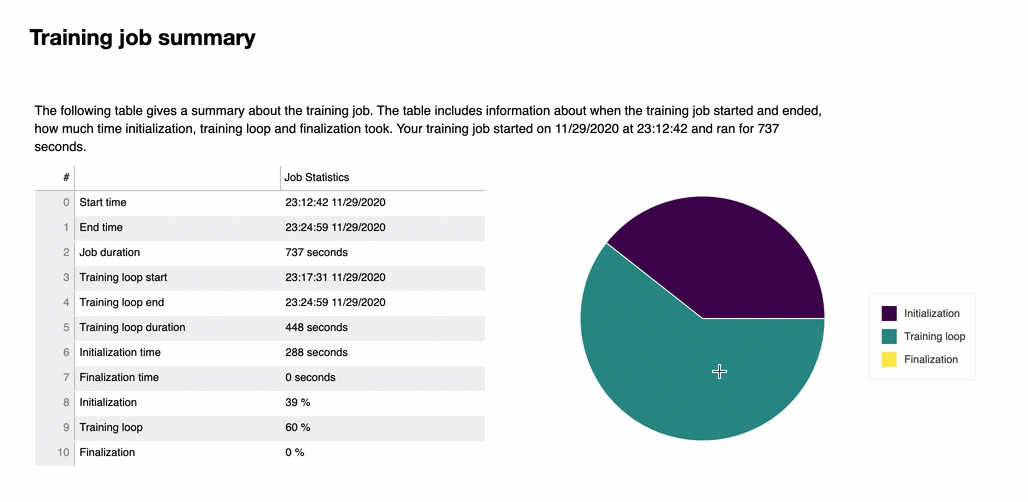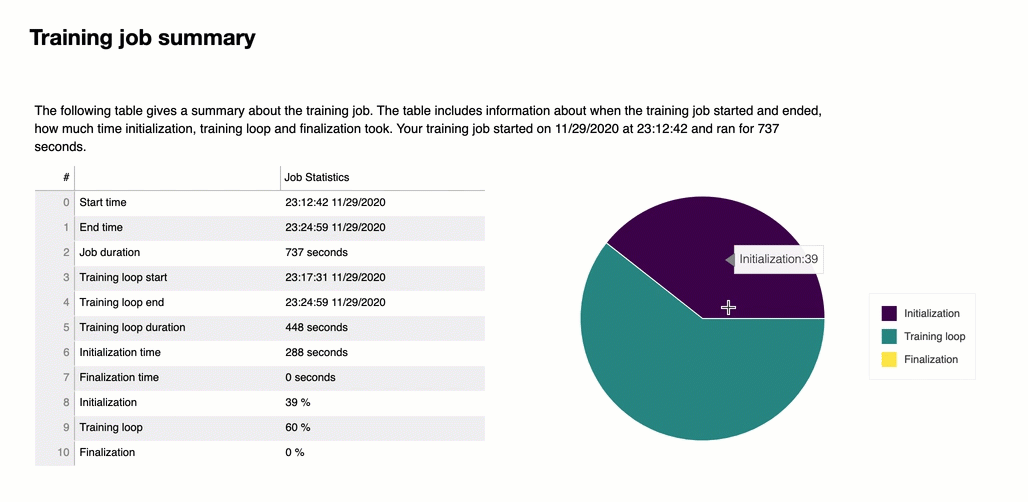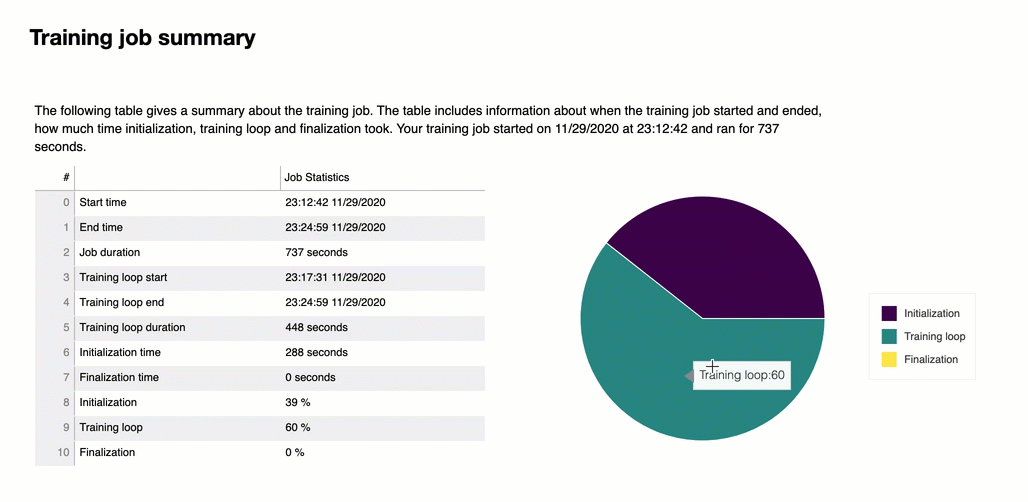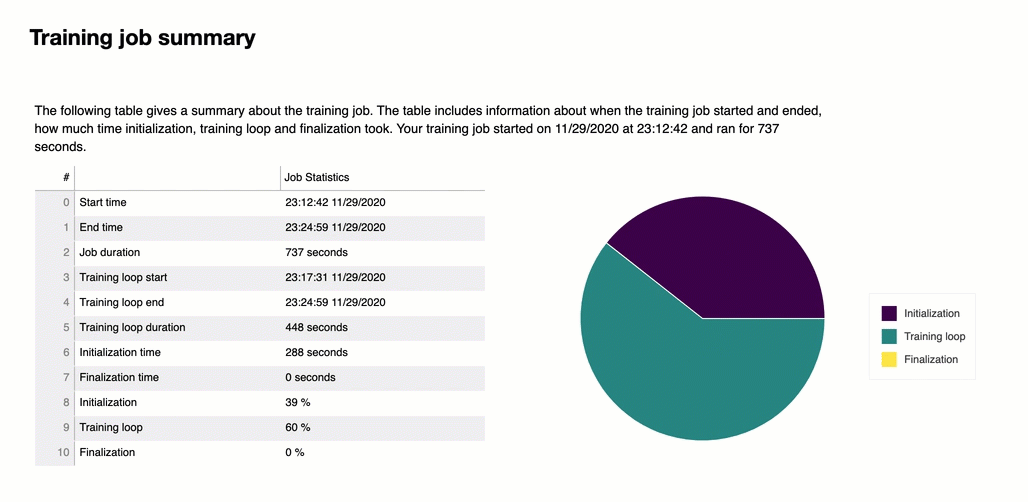
總結表包含以下資訊:
-
start_time — 訓練工作開始的確切時間。
-
end_time — 訓練工作完成的確切時間。
-
job_duration_in_seconds — 從start_time到end_time的總工作時間。
-
training_loop_start - 第一個 epoch 的第一步開始的確切時間。
-
training_loop_end - 最後一個 epoch 的最後一步完成的確切時間。
-
training_loop_duration_in_seconds - 訓練循環開始至訓練循環結束的總時間。
-
initialization_in_seconds - 將工作初始化所花費的時間。初始化階段涵蓋從 start_time 至 training_loop_start 的時間。初始化時間用於編譯訓練指令碼、啟動訓練指令碼、建立和初始化模型、啟動EC2執行個體和下載訓練資料。
-
finalization_in_seconds – 完成訓練任務所花費的時間,例如完成模型訓練、更新模型成品,以及關閉EC2執行個體。完成階段涵蓋從 training_loop_end 至 end_time 的時間。
-
initialization (%)— 初始化的時間佔總 job_duration_in_seconds 的百分比。
-
training loop (%)— 訓練循環所花費的時間佔總 job_duration_in_seconds 的百分比。
-
finalization (%) — 完成的時間佔總 job_duration_in_seconds 的百分比。
系統使用率統計
在本區段中,您可以查看系統使用率統計資料的概觀。
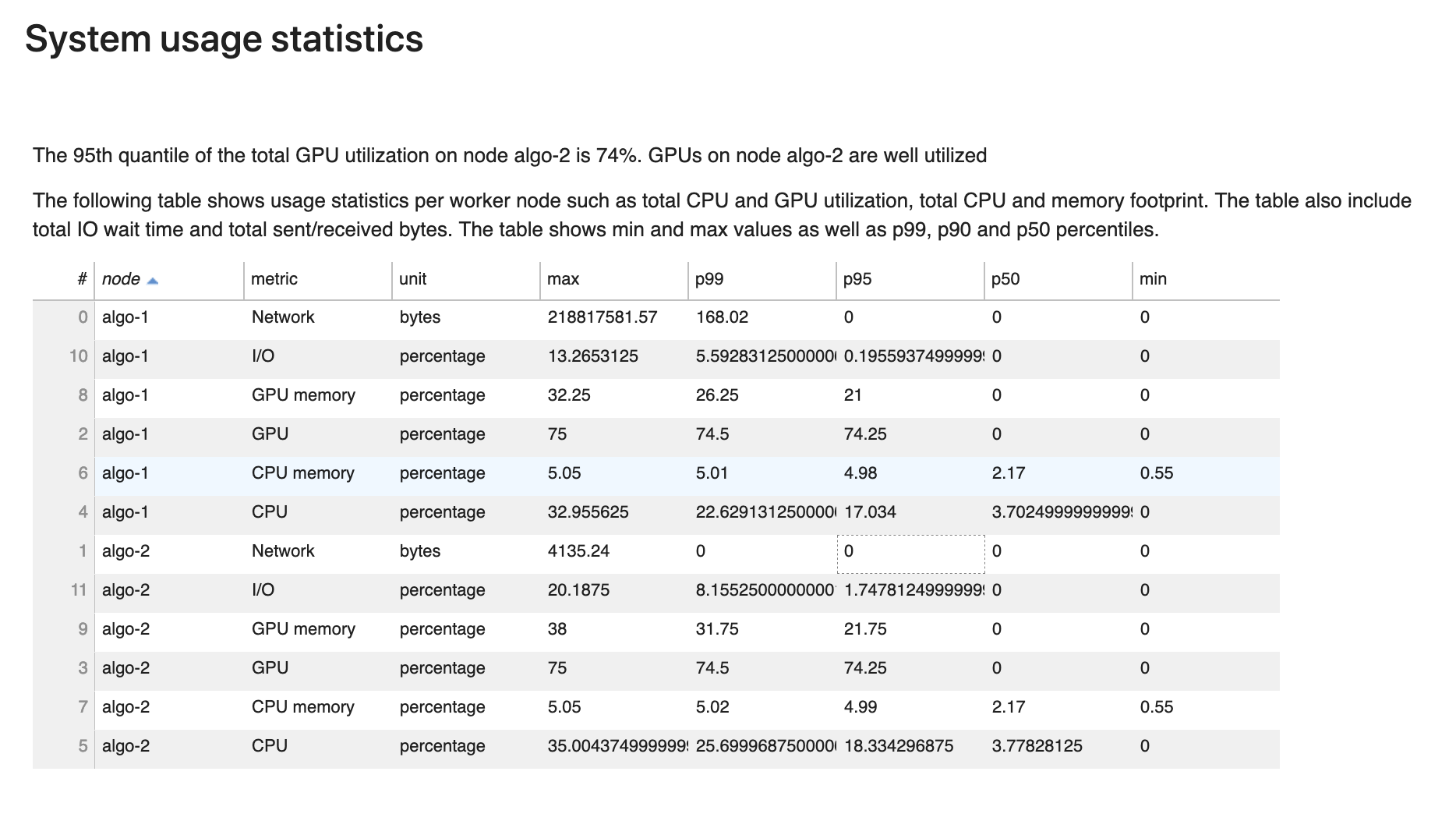
Debugger 分析報告包含下列資訊:
-
node — 列出節點的名稱。如果在多節點 (多個EC2執行個體) 上使用分散式訓練,則節點名稱的格式為
algo-n。 -
指標 – Debugger 收集的系統指標:CPU、GPU、CPU記憶體、GPU記憶體、I/O 和 Network 指標。
-
Unit — 指標的單位。
-
max — 每個系統指標的最大值。
-
p99 — 每個系統使用率的第 99 個百分位數。
-
p95 — 每個系統使用率的第 95 個百分位數。
-
p50 — 每個系統利用率的第 50 個百分位數 (中位數)。
-
min — 每個系統指標的最小值。
框架度量摘要
在本節中,下列圓餅圖顯示 CPUs和 上的架構操作明細GPUs。
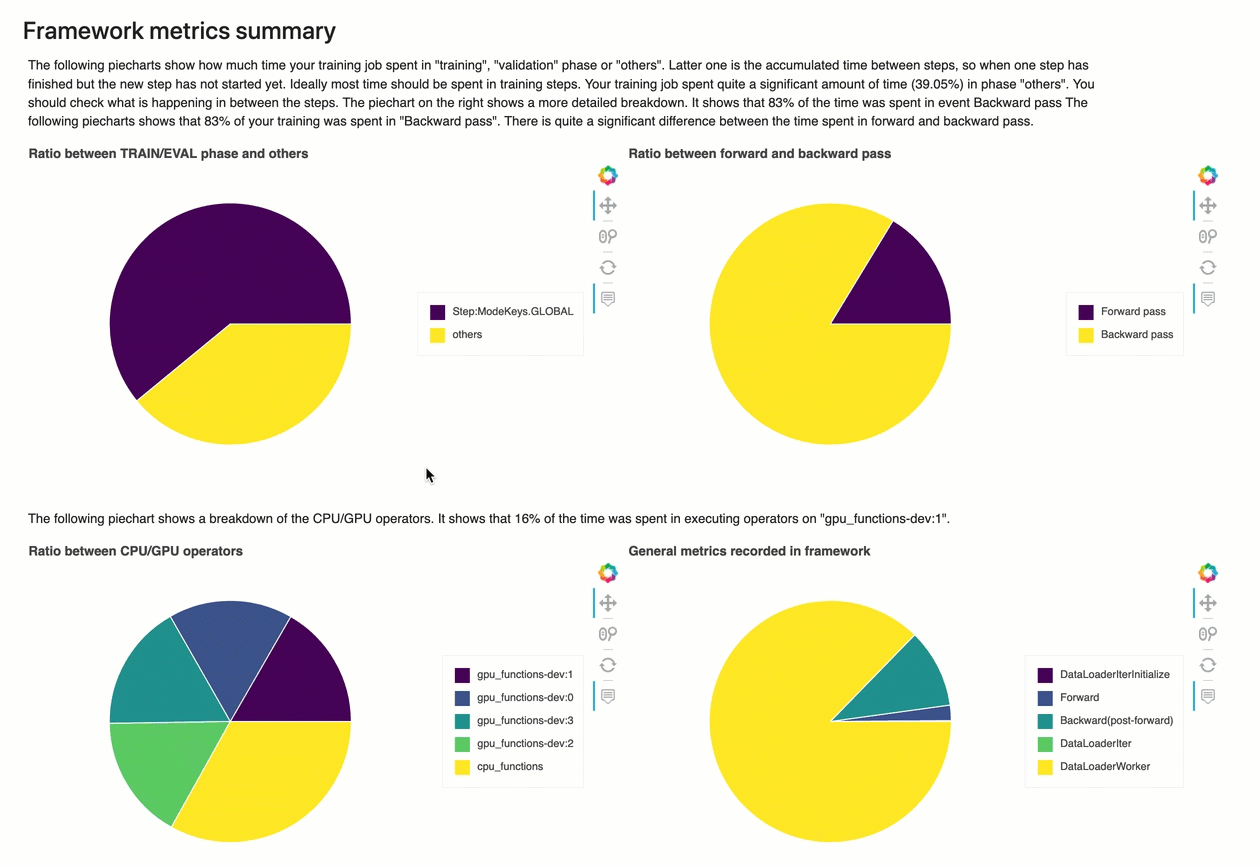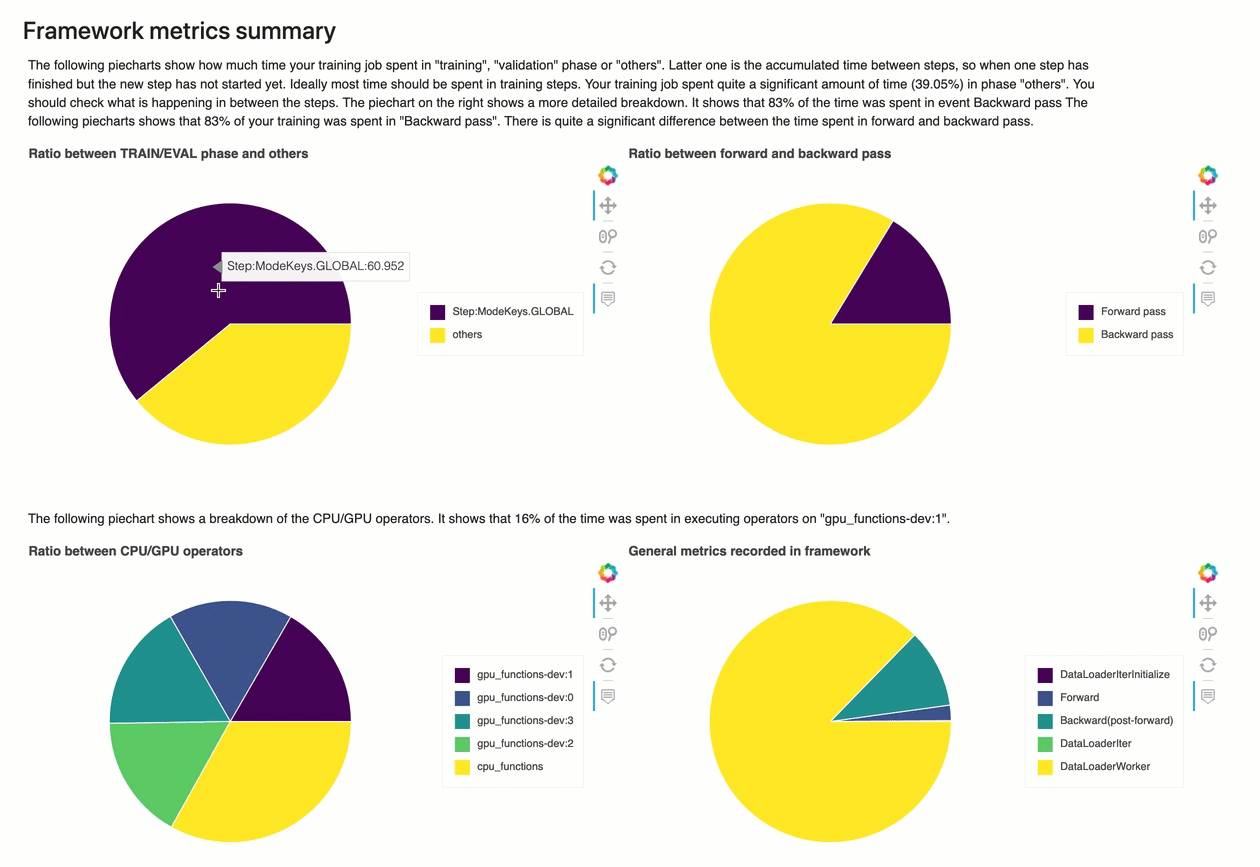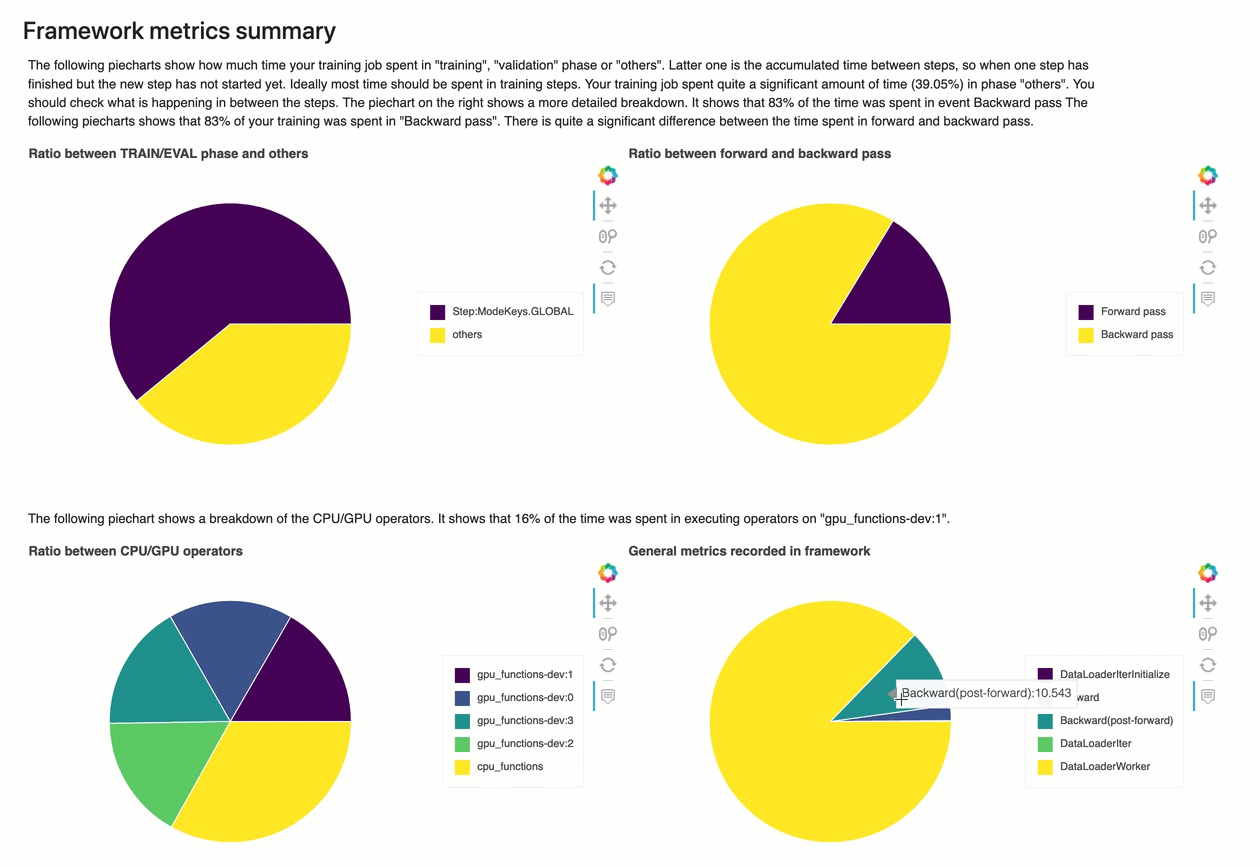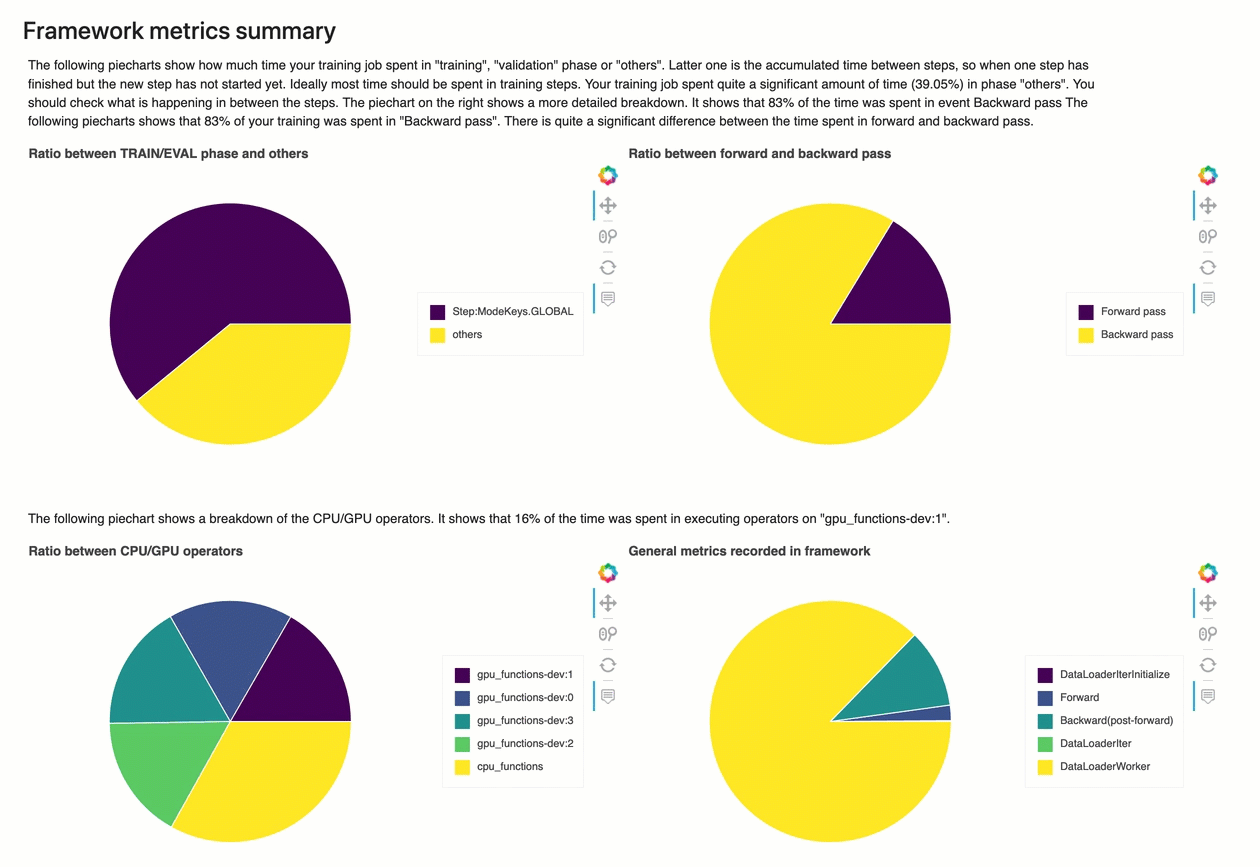
每個圓餅圖分析從以下各方面收集的框架度量:
-
TRAIN/EVAL 階段與其他階段的比率 – 顯示不同訓練階段所花費時間的比率。
-
向前和向後傳遞的比率 — 顯示訓練循環中向前和向後傳遞的持續時間比率。
-
CPU/GPU 運算子之間的比率 – 顯示在 CPU或 上執行的運算子上花費的時間比率GPU,例如卷積運算子。
-
架構內記錄的一般指標 — 顯示花費在主要架構指標 (例如資料載入、向前和向後傳遞) 的時間比率。
概觀:CPU運算子
本節詳細提供CPU運算子的資訊。資料表顯示時間的百分比,以及最常呼叫運算CPU子所花費的絕對累積時間。
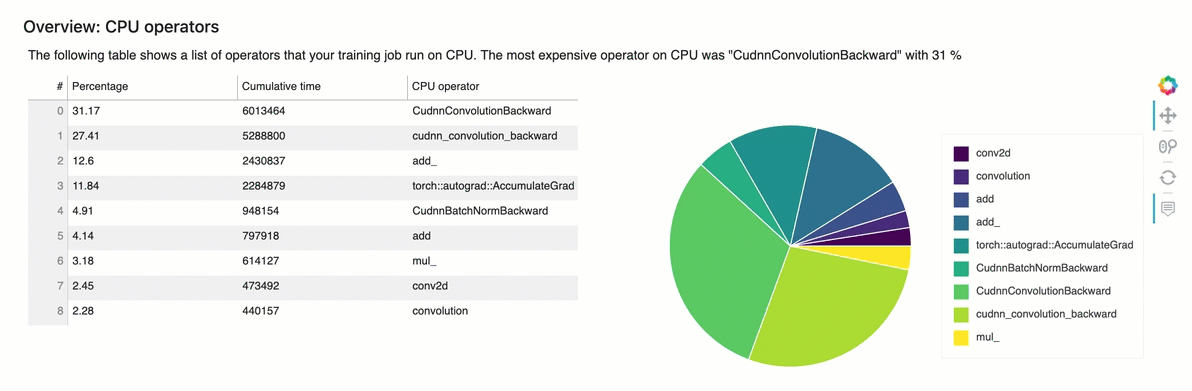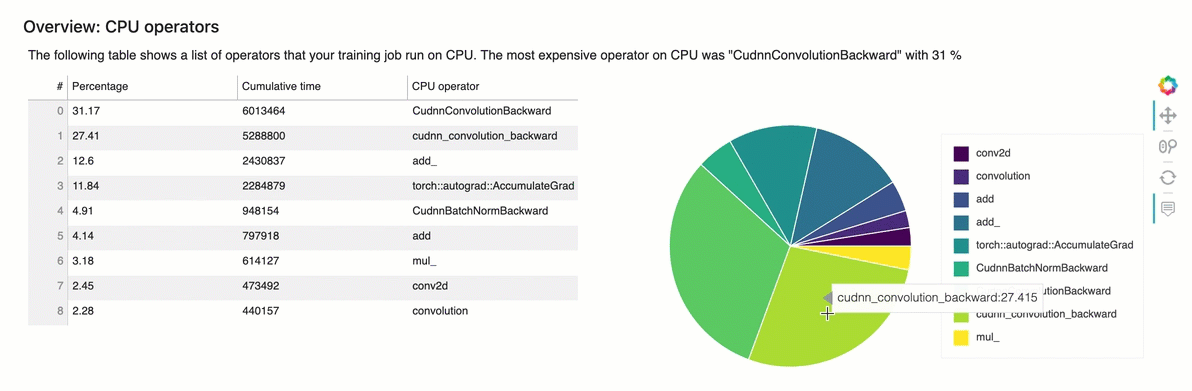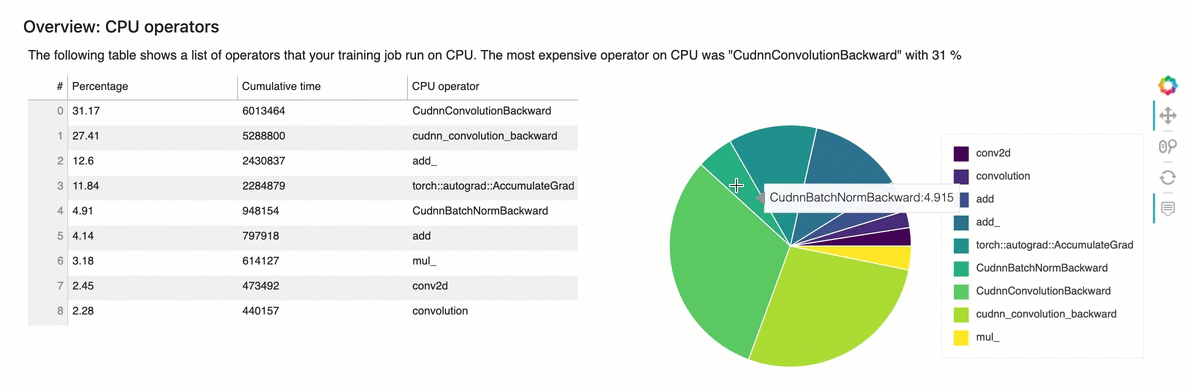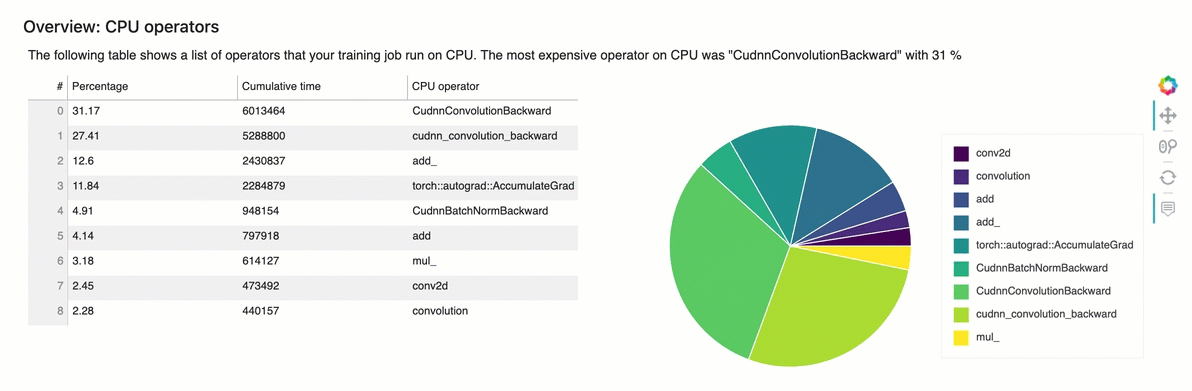
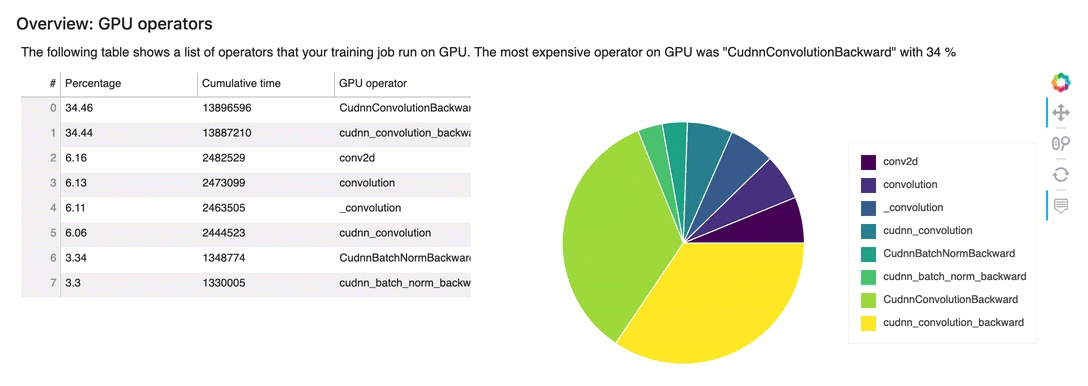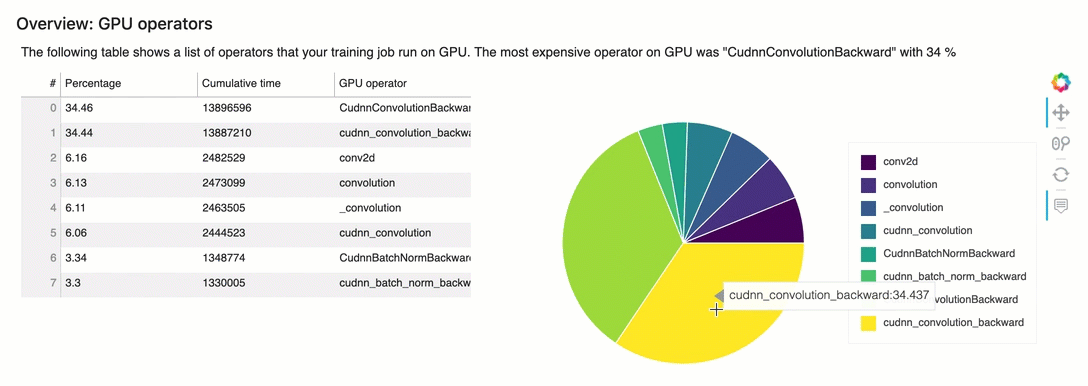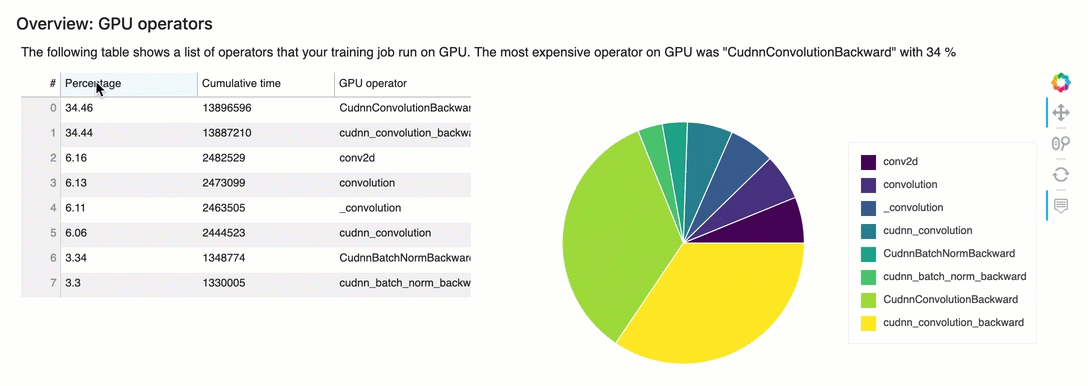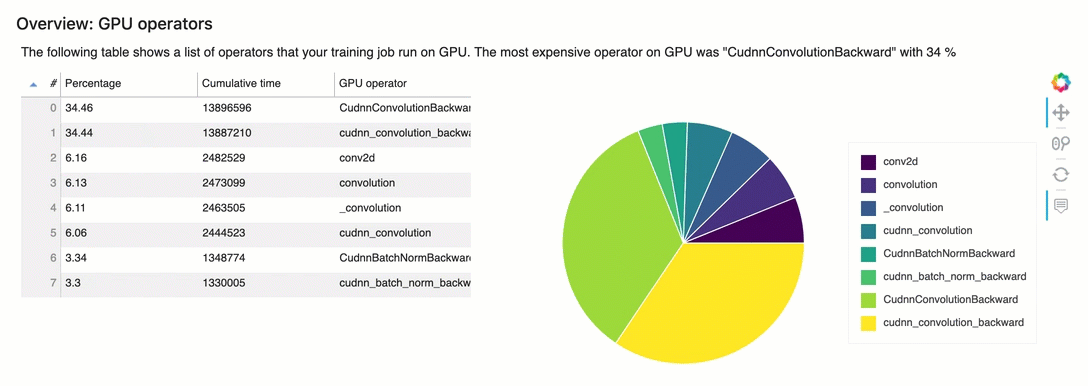
概觀:GPU運算子
本節詳細提供GPU運算子的資訊。此表格顯示時間的百分比,以及最常呼叫運算GPU子所花費的絕對累積時間。
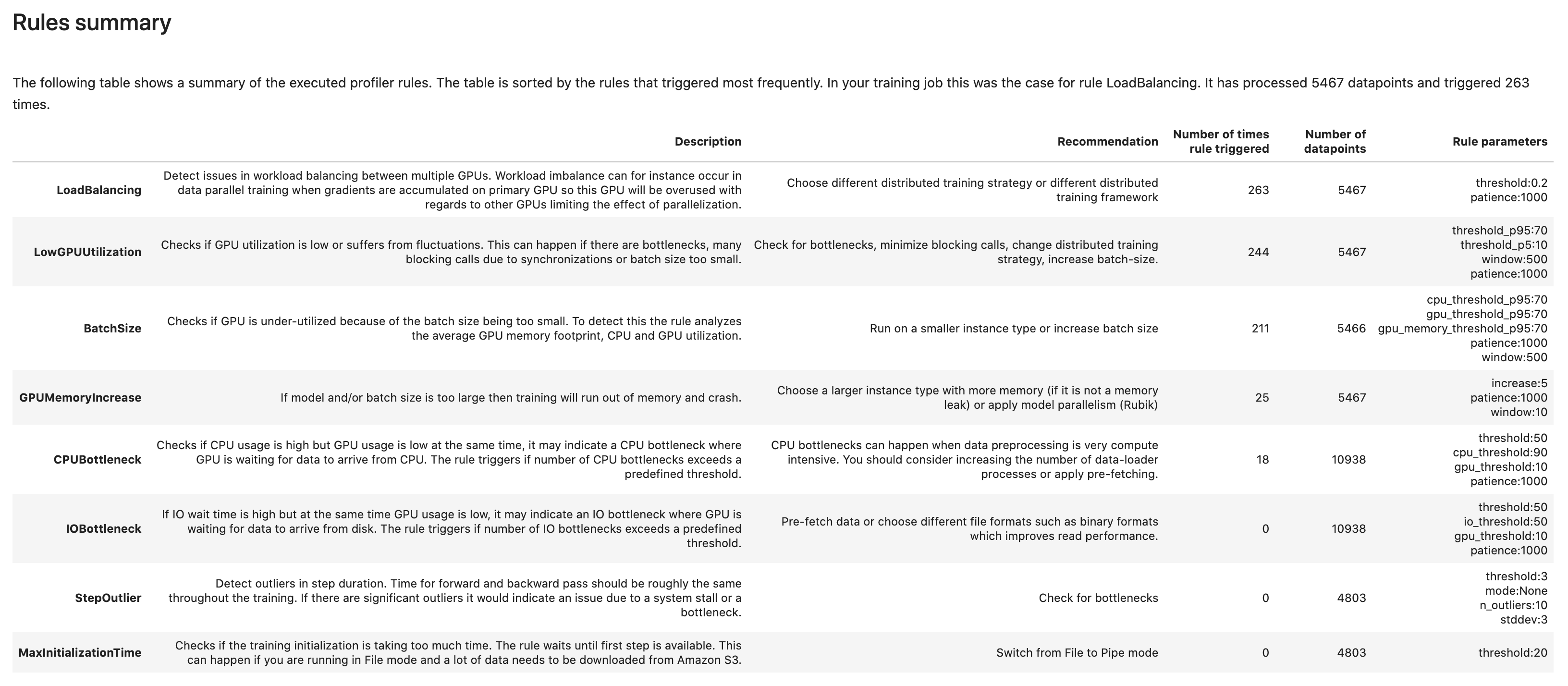
規則摘要
在本區段中,Debugger 會彙總所有規則評估結果、分析、規則說明和建議。
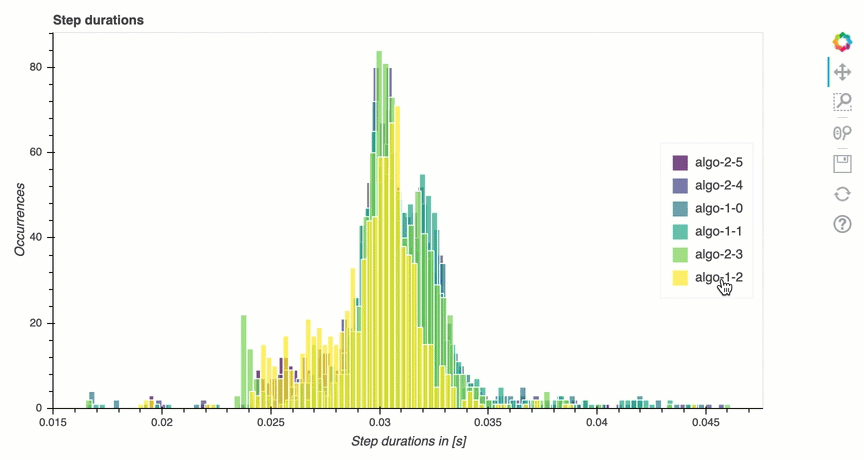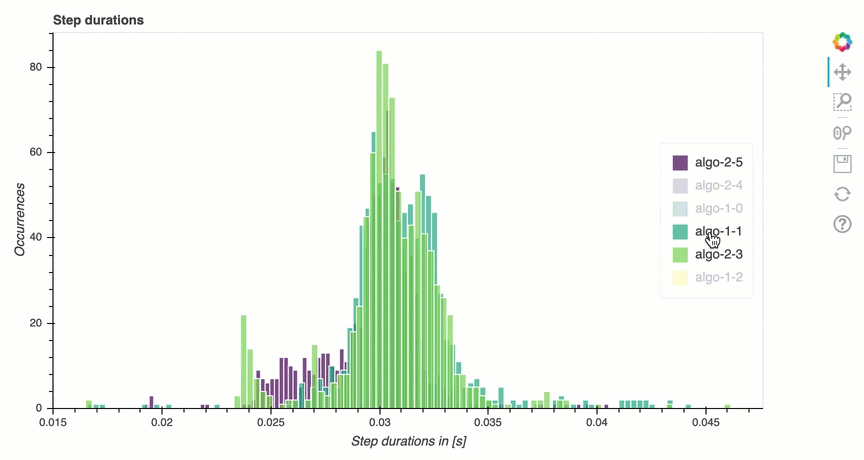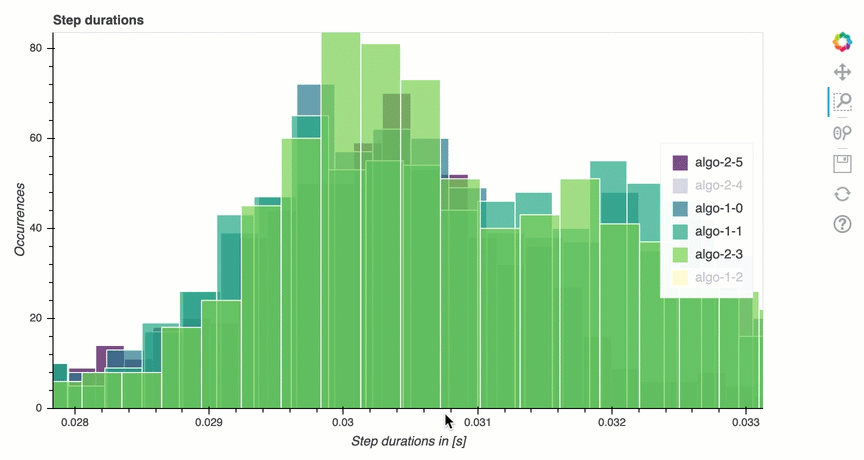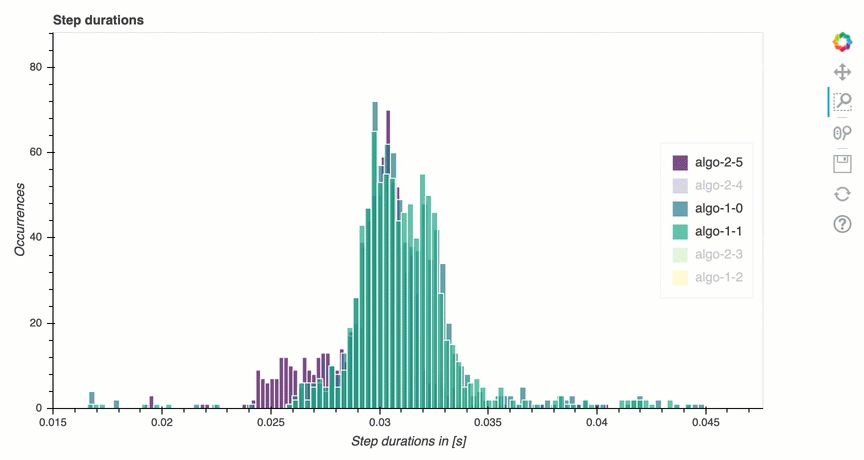
分析訓練循環 — 步驟持續時間
在本節中,您可以找到每個節點每個GPU核心上步驟持續時間的詳細統計資料。Debugger 評估平均值、最大值、P99、p95、p50 和步驟持續時間的最小值,並評估步驟異常值。下列長條圖顯示在不同工作者節點 和 上擷取的步驟持續時間GPUs。您可以透過選擇右側的圖例來啟用或禁用每個工作者的長條圖。您可以檢查是否有特定 GPU 導致步驟持續時間異常值。
GPU 使用率分析
本節顯示以 L owGPUUtilization 規則為基礎的GPU核心使用率詳細統計資料。它也會摘要GPU使用率統計資料,平均值、p95 和 p5,以判斷訓練任務是否未充分利用 GPUs。
批次大小
本節顯示總CPU使用率、個別GPU使用率和GPU記憶體佔用空間的詳細統計資料。此 BatchSize 規則會決定您是否需要變更批次大小,以更好地利用 GPUs。您可以檢查批次大小是否太小,導致使用率不足或過大,造成過度使用和記憶體不足的問題。在圖表中,方塊顯示 p25 和 p75 百分位數與中位數的距離範圍 (分別填滿深紫色和亮黃色),誤差列顯示下限的第 5 個百分位數和上限的第 95 個百分位數。

CPU 瓶頸
在本節中,您可以深入探討從訓練任務偵測到的CPUBottleneck規則CPU瓶頸。規則會檢查CPU使用率是否高於 cpu_threshold(預設為 90%),以及GPU使用率是否低於 gpu_threshold(預設為 10%)。
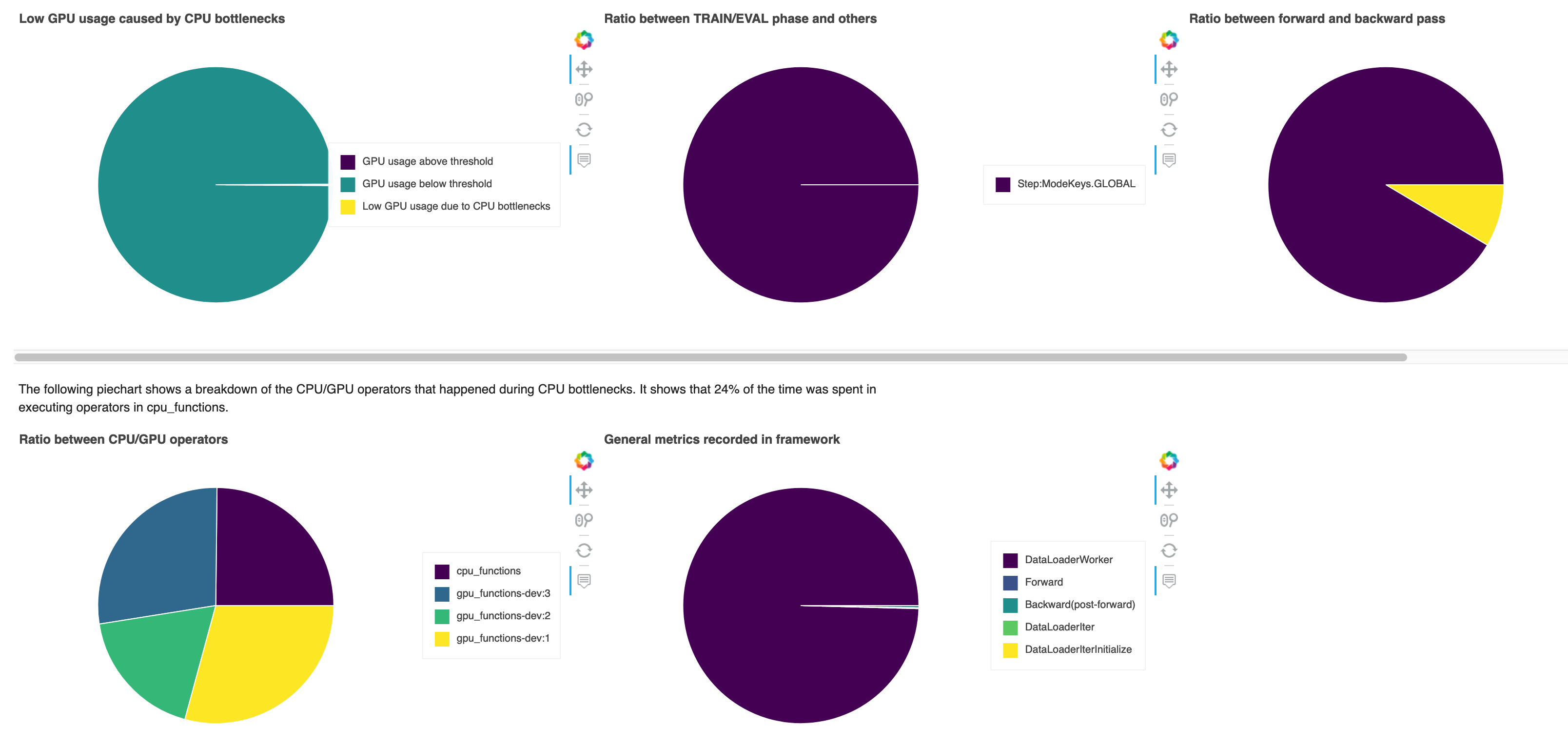
圓餅圖會顯示下列資訊:
-
CPU 瓶頸造成的低GPU用量 – 顯示GPU使用率高於和低於閾值的資料點與符合CPU瓶頸條件的資料點比率。
-
TRAIN/EVAL 階段與其他階段的比率 – 顯示不同訓練階段所花費時間的比率。
-
向前和向後傳遞的比率 — 顯示訓練循環中向前和向後傳遞的持續時間比率。
-
CPU/GPU 運算子之間的比率 – 顯示 Python 運算子在 GPUs 和 CPUs 上花費的時間長度之間的比率,例如資料載入器程序以及向前和向後傳遞運算子。
-
框架中記錄的一般指標 — 顯示主要框架指標,以及在指標上所花費的時間的比率。
I/O 瓶頸
在本區段中,您可以找到 I/O 瓶頸的摘要。此規則會評估 I/O 等待時間和GPU使用率,並監控花費在 I/O 請求上的時間是否超過總訓練時間的閾值百分比。這可能表示GPUs等待資料從儲存體到達的 I/O 瓶頸。
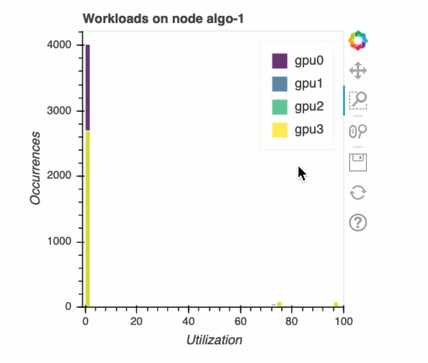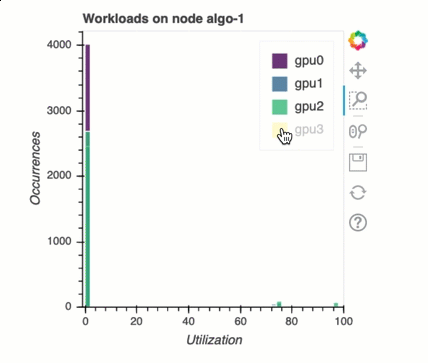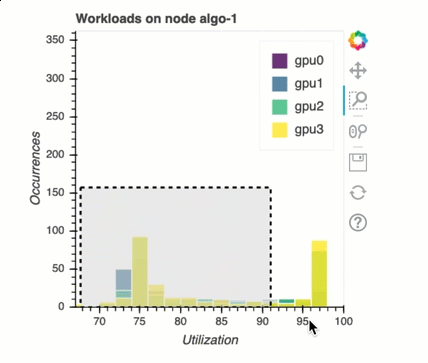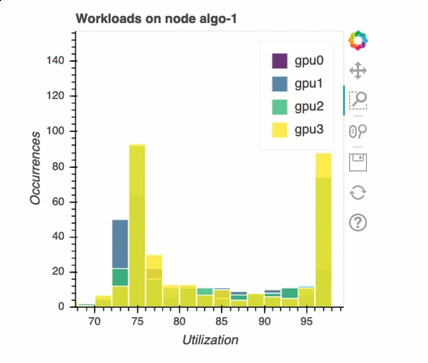
多GPU訓練中的負載平衡
我在此區段中,您可以識別跨 的工作負載平衡問題GPUs。
GPU 記憶體分析
在本節中,您可以分析GPUMemoryIncrease規則收集的GPU記憶體使用率。在圖表中,方塊顯示 p25 和 p75 百分位數與中位數的距離範圍 (分別填滿深紫色和亮黃色),誤差列顯示下限的第 5 個百分位數和上限的第 95 個百分位數。

