本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
設定偵錯工具勾點的範例筆記本和程式碼範例
下列各節提供如何使用 Debugger 勾點儲存、存取和視覺化輸出張量的筆記本和程式碼範例。
Tensor 視覺化範例筆記本
以下兩個筆記本範例顯示用於視覺化張量的 Amazon SageMaker Debugger 進階用法。Debugger 提供訓練深度學習模型的透明檢視。
-
使用 MXNet 在 SageMaker Studio 筆記本進行互動張量分析
此筆記本範例示範如何使用 Amazon SageMaker Debugger 視覺化已儲存的張量。透過將張量視覺化,訓練深度學習演算法的同時,您可以查看張量值的變化方式。此筆記本包含訓練任務和設定不良的神經網路,並使用 Amazon SageMaker 偵錯器來彙總和分析張量,包括梯度、啟用輸出和權重。例如,下圖顯示了受消失坡度問題影響之卷積圖層的坡度分佈。
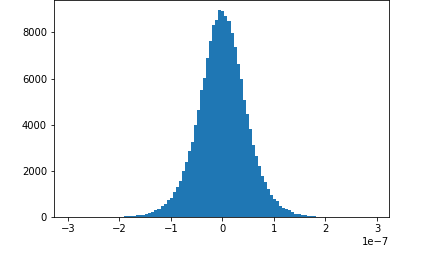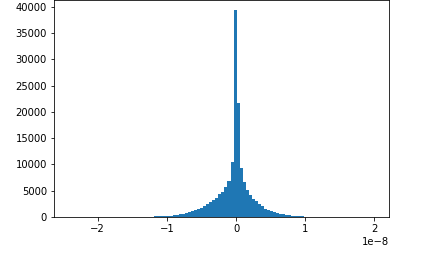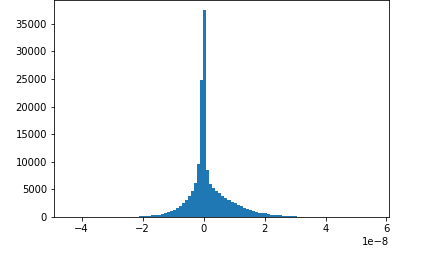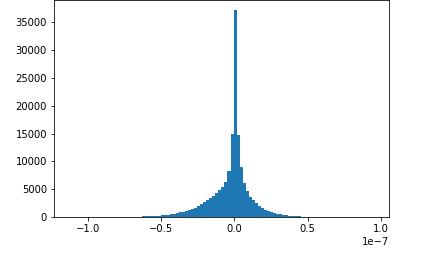
此筆記本也說明良好的初始超參數設定可產生相同的張量分佈圖,從而改善訓練程序。
-
此筆記本範例示範如何使用 Amazon SageMaker Debugger,從 MXNet Gluon 模型訓練任務儲存和視覺化張量。其中說明 Debugger 設為將所有張量儲存到 Amazon S3 儲存貯體,並擷取 ReLu 啟用輸出來進行視覺化。下圖顯示 ReLu 啟用輸出的三維視覺化。色彩方案設為藍色表示接近 0 的值,設為黃色表示接近 1 的值。

在此筆記本中,從
tensor_plot.py匯入的TensorPlot類別,旨在繪製以二維影像作為輸入的卷積神經網路 (CNN)。筆記本隨附的tensor_plot.py指令碼使用 Debugger 擷取張量,並將卷積神經網路視覺化。您可以在 SageMaker Studio 上執行此筆記本,重現張量視覺化,並實作您自己的卷積神經網路模型。 -
使用 MXNet 在 SageMaker 筆記本中進行即時張量分析
本範例逐步引導您安裝必要的元件,在 Amazon SageMaker 訓練任務中發出張量,以及在訓練執行期間,使用 Debugger API 作業存取這些張量。gluon CNN 模型在 Fashion MNIST 資料集訓練。任務執行時,您會看到 Debugger 如何從每 100 個批次的第一個卷積層擷取啟用輸出,並將它們視覺化。此外,這將向您顯示如何在任務完成後視覺化權重。
使用 Debugger 內建集合儲存張量
使用 CollectionConfig API 即可使用內建張量集合,使用 DebuggerHookConfig API 即可儲存它們。下列範例示範如何使用 Debugger hook 組態的預設設定來建構 SageMaker AI TensorFlow 估算器。您也可以將其用於 MXNet,PyTorch 和 XGBoost 估算器。
注意
在下列範例程式碼中,DebuggerHookConfig 的 s3_output_path 參數是選用的。如果您未指定該參數,Debugger 會將張量儲存在 s3://<output_path>/debug-output/,其中 <output_path> 是 SageMaker 訓練任務的預設輸出路徑。例如:
"s3://sagemaker-us-east-1-111122223333/sagemaker-debugger-training-YYYY-MM-DD-HH-MM-SS-123/debug-output"
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call built-in collections collection_configs=[ CollectionConfig(name="weights"), CollectionConfig(name="gradients"), CollectionConfig(name="losses"), CollectionConfig(name="biases") ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-built-in-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
若要查看 Debugger 內建集合的清單,請參閱 Debugger 內建集合
透過修改 Debugger 內建集合來儲存張量
您可以使用 CollectionConfig API 作業修改 Debugger 內建集合。下列範例示範如何調整內建losses集合,並建構 SageMaker AI TensorFlow 估算器。您也可以將其用於 MXNet,PyTorch 和 XGBoost 估算器。
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to call and modify built-in collections collection_configs=[ CollectionConfig( name="losses", parameters={"save_interval": "50"})] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-modified-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
如需 CollectionConfig 參數完整清單,請參閱 Debugger CollectionConfig API
使用 Debugger 自訂集合儲存張量
您也可以儲存較少的張量而不是整組張量 (例如,如果您想減少 Amazon S3 儲存貯體中儲存的資料量)。下列範例顯示如何自訂 Debugger 勾點組態,指定您想儲存的目標張量。您可以將其用於 TensorFlow、MXNet、PyTorch 和 XGBoost 估算器。
import sagemaker from sagemaker.tensorflow import TensorFlow from sagemaker.debugger import DebuggerHookConfig, CollectionConfig # use Debugger CollectionConfig to create a custom collection collection_configs=[ CollectionConfig( name="custom_activations_collection", parameters={ "include_regex": "relu|tanh", # Required "reductions": "mean,variance,max,abs_mean,abs_variance,abs_max" }) ] # configure Debugger hook # set a target S3 bucket as you want sagemaker_session=sagemaker.Session() BUCKET_NAME=sagemaker_session.default_bucket() LOCATION_IN_BUCKET='debugger-custom-collections-hook' hook_config=DebuggerHookConfig( s3_output_path='s3://{BUCKET_NAME}/{LOCATION_IN_BUCKET}'. format(BUCKET_NAME=BUCKET_NAME, LOCATION_IN_BUCKET=LOCATION_IN_BUCKET), collection_configs=collection_configs ) # construct a SageMaker TensorFlow estimator sagemaker_estimator=TensorFlow( entry_point='directory/to/your_training_script.py', role=sm.get_execution_role(), base_job_name='debugger-demo-job', instance_count=1, instance_type="ml.p3.2xlarge", framework_version="2.9.0", py_version="py39", # debugger-specific hook argument below debugger_hook_config=hook_config ) sagemaker_estimator.fit()
如需 CollectionConfig 參數的完整清單,請參閱 Debugger CollectionConfig
