本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Debugger XGBoost 訓練報告演練
本節將逐步引導您完成 Debugger XGBoost 訓練報告。報告會根據輸出張量 regex 自動彙總,以識別二進制分類、多類別分類和迴歸中的訓練任務類型。
重要
在報告中,系統會提供資訊圖表和相關建議,其中的內容並非絕對。您有責任對當中的資訊進行自己的獨立評估。
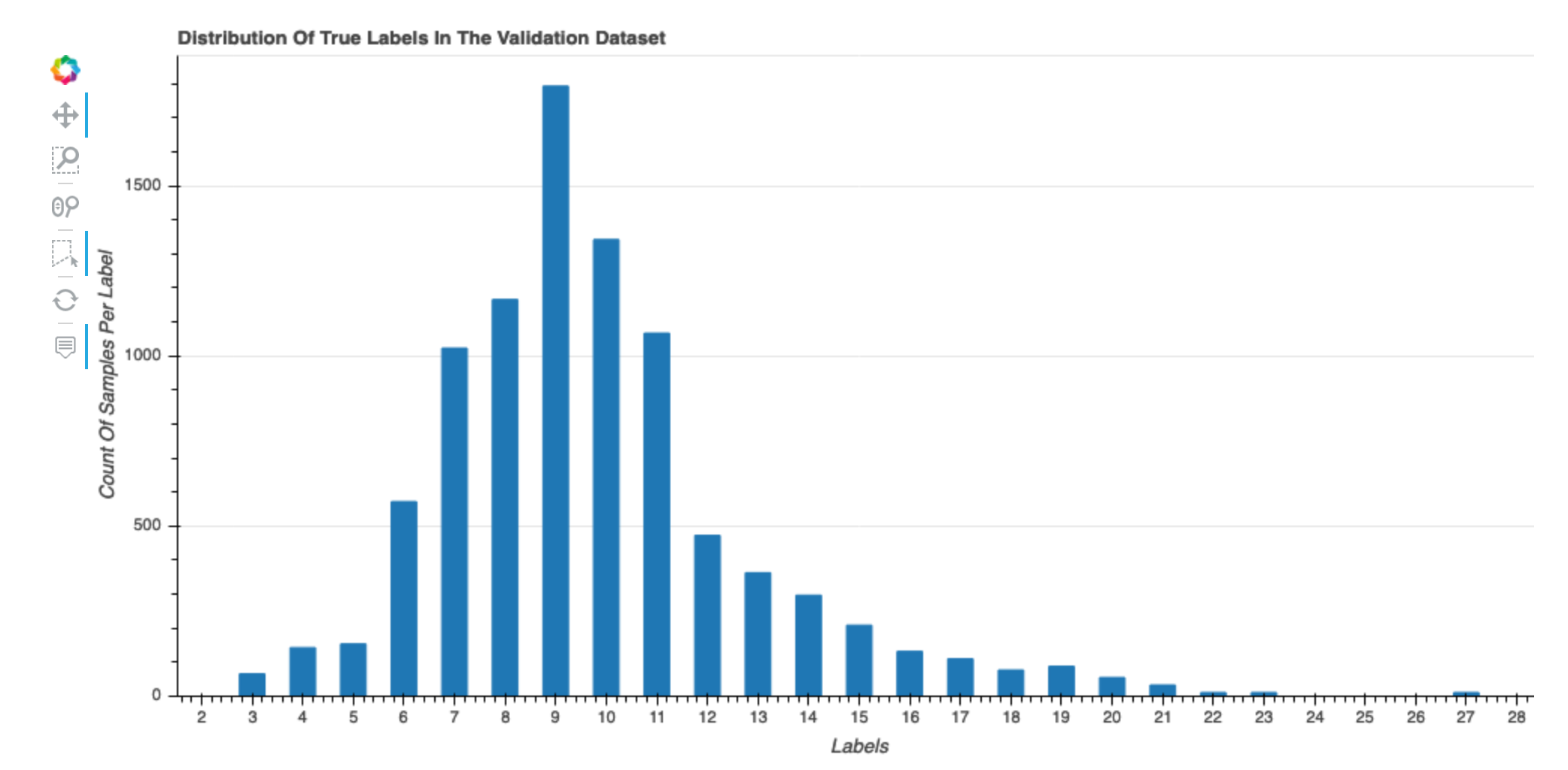
資料集真實標籤的分佈
此長條圖會顯示原始資料集中標籤類別 (用於分類) 或值 (用於迴歸) 的分佈。資料集中的偏態可能會導致不準確。此視覺化內容適用於下列模型類型:二進制分類、多重分類和迴歸。
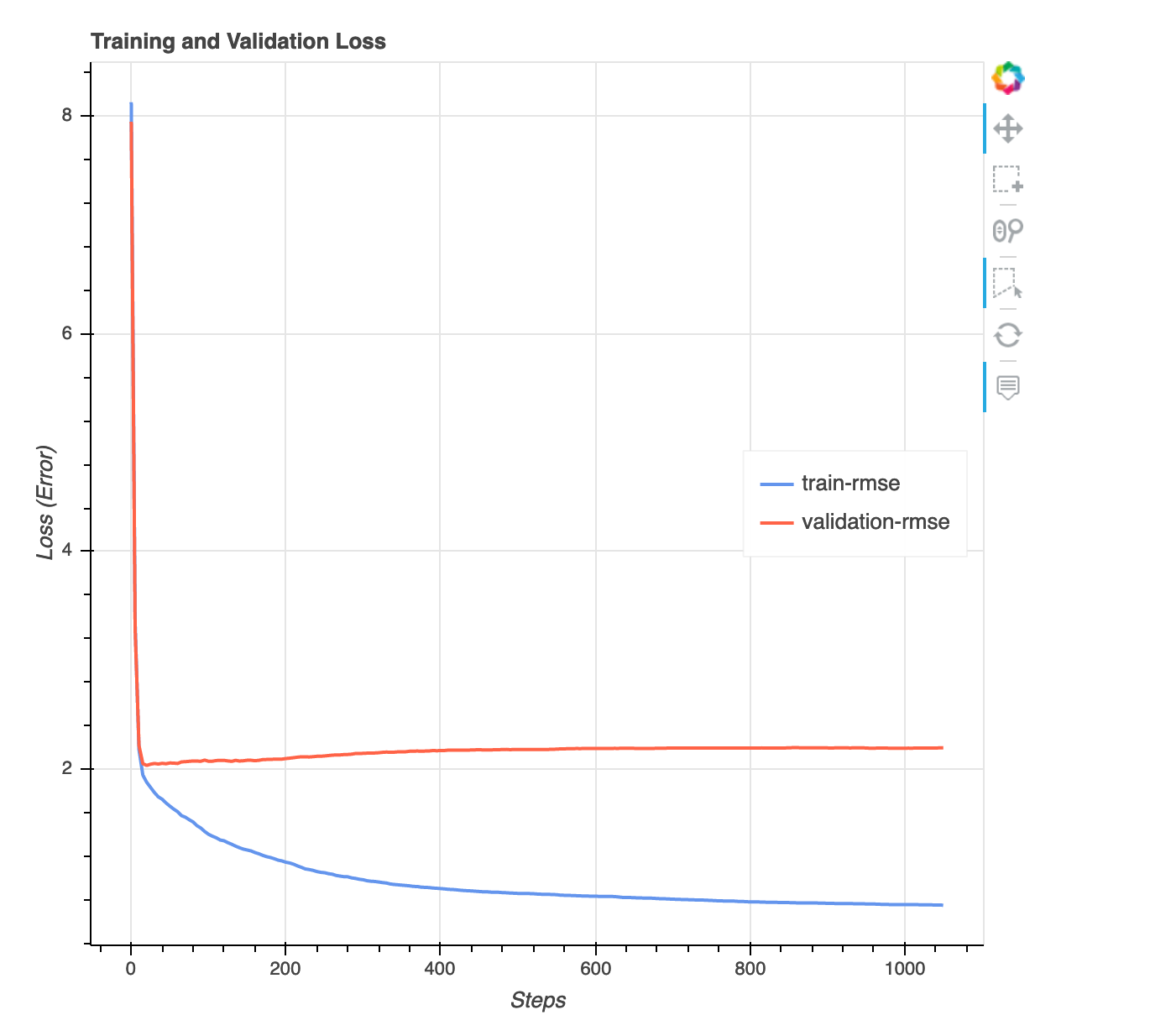
遺失與步驟圖表的比較
這是一個折線圖,顯示在整個訓練步驟中訓練資料和驗證資料損失的演進方式。損失是您在目標函式中定義的內容,例如平均值平方錯誤。您可以從此繪圖中測量模型是過度擬合或低度擬合。本節還提供了您可以用來釐清如何解決過度擬合和低度擬合問題的洞察。此視覺化內容適用於下列模型類型:二進制分類、多重分類和迴歸。
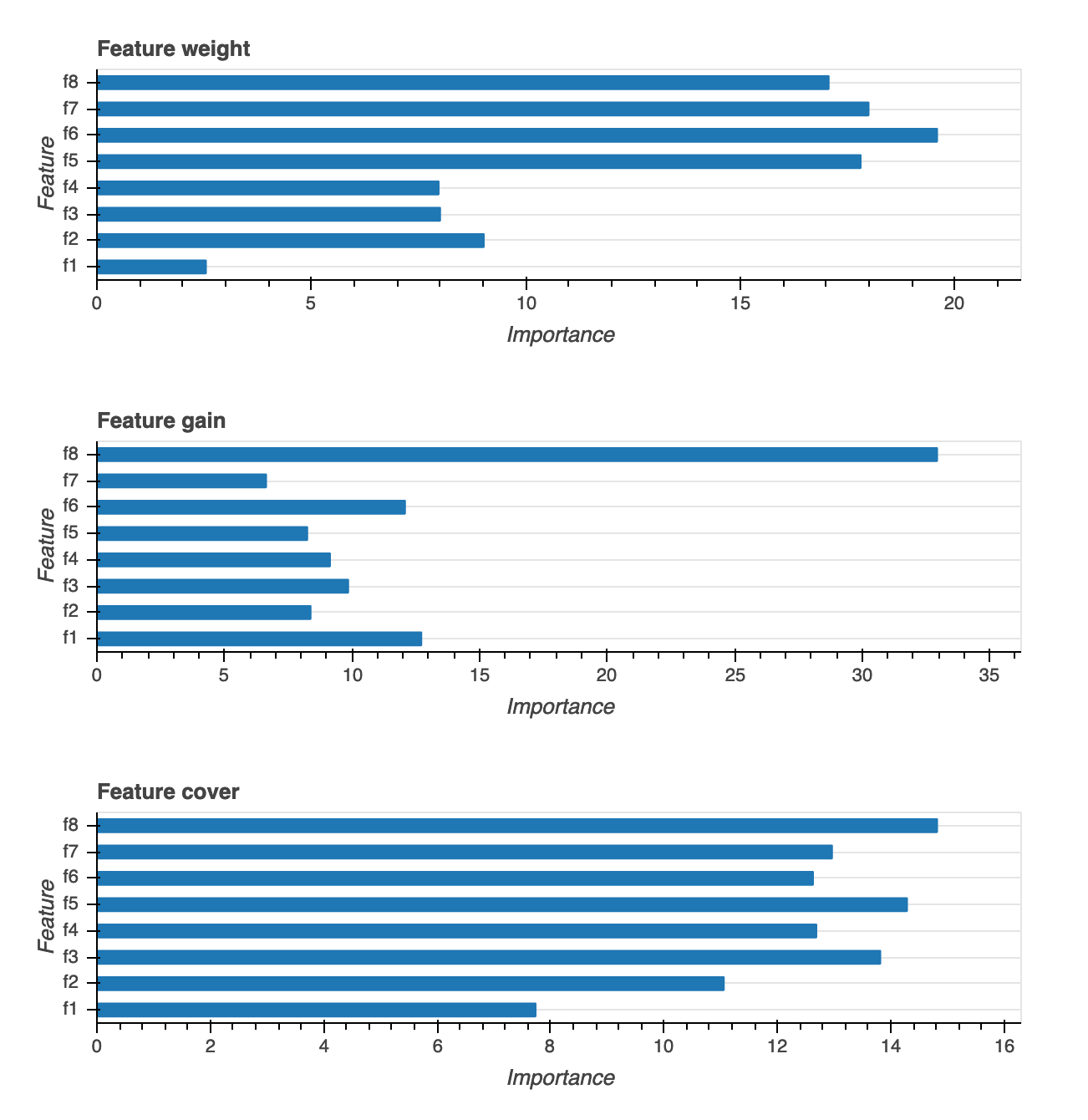
功能重要性
提供三種不同類型的功能重要性視覺效果:權重、增加和覆蓋範圍。我們針對報告中三者中的每一項目提供詳細定義。功能重要性視覺化可協助您了解訓練資料集中的哪些功能對預測有何貢獻。功能重要性視覺化適用於下列模型類型:二進制分類、多重分類和迴歸。
混淆矩陣
此視覺化內容僅適用於二進位和多類別分類模型。單憑準確度可能不足以評估模型效能。對於某些使用案例,例如醫療保健和詐騙偵測,了解假陽性率和假陰性率也很重要。混淆矩陣為您提供用於評估模型效能的其他維度。

混淆矩陣的評估
本節為您提供有關模型精確度、重新呼叫和 F1 分數的微型、巨集和加權指標之更多洞察。
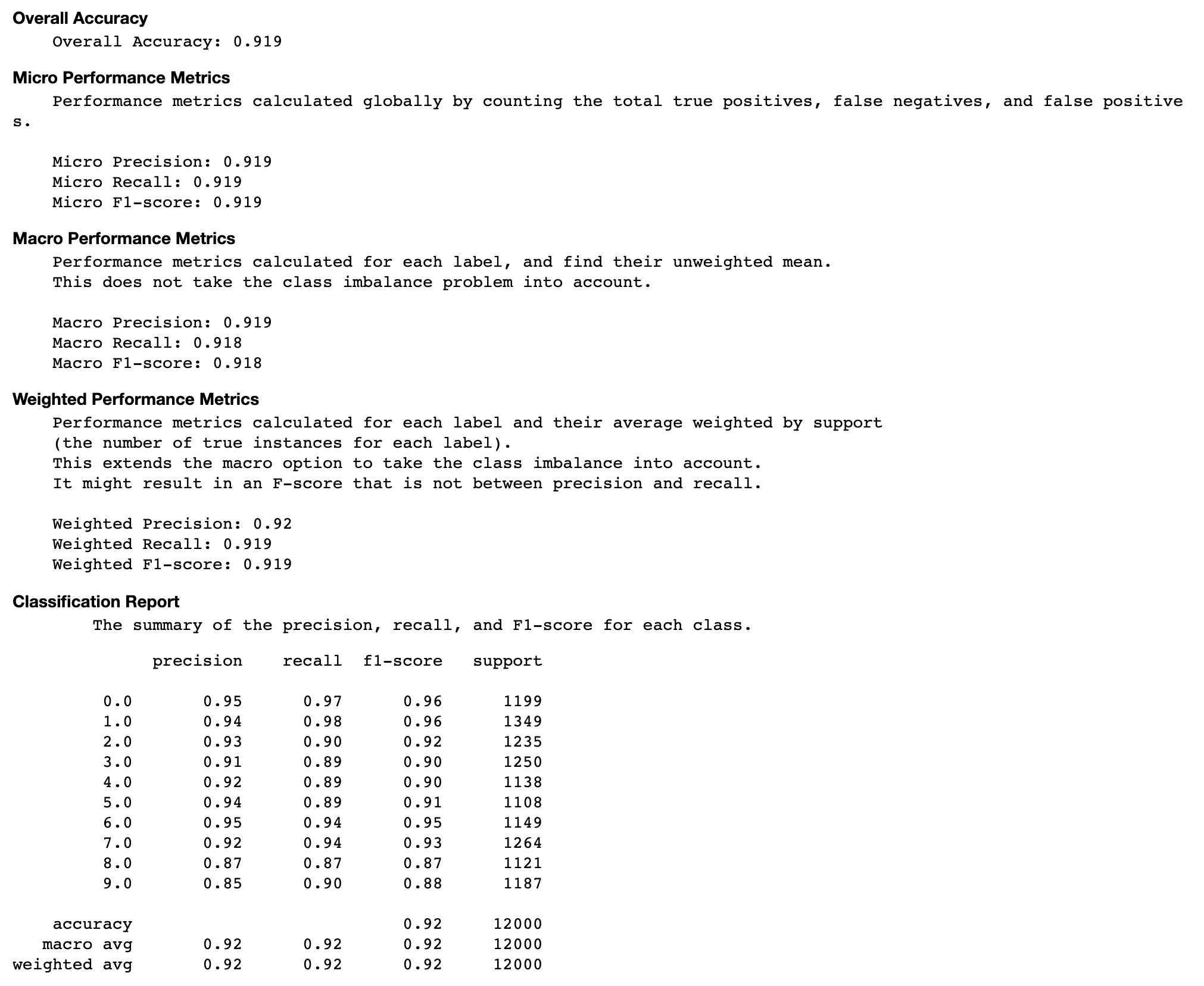
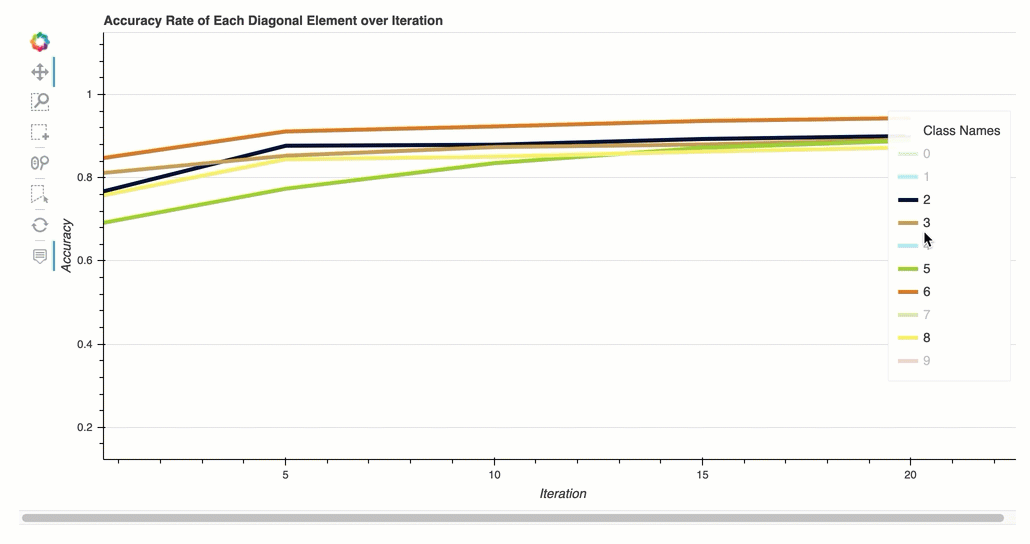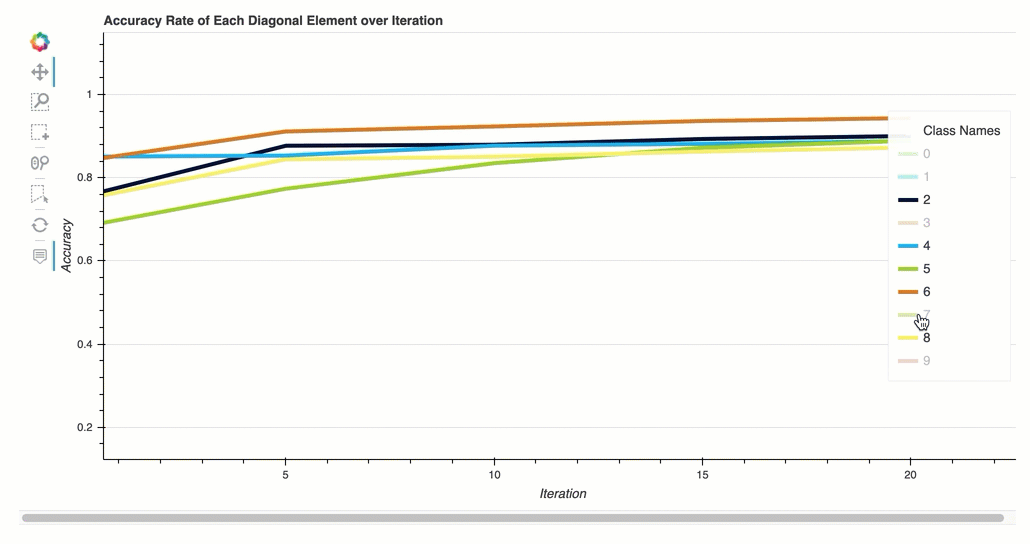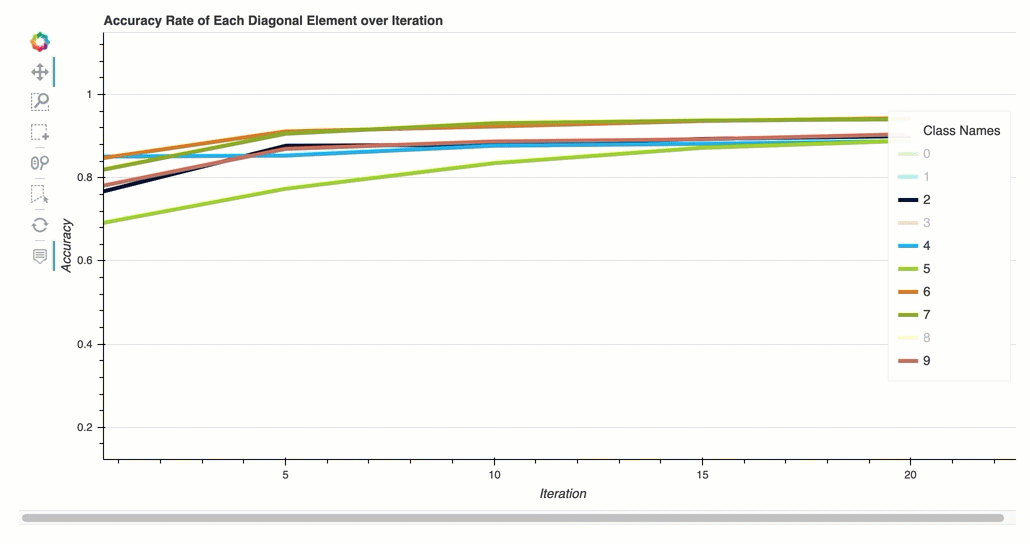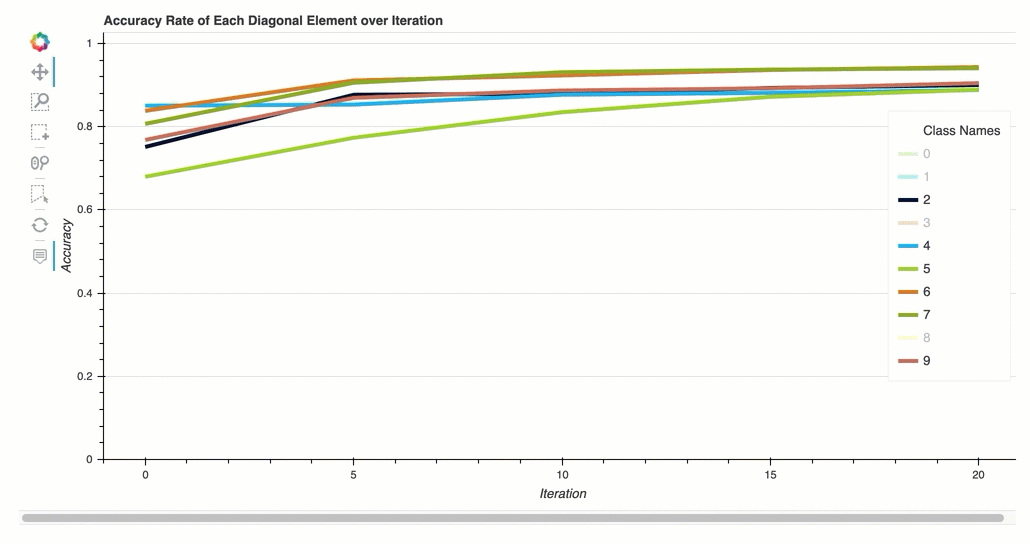
反覆運算中每個對角元素的準確度
此視覺化內容僅適用於二進制分類和多類別分類模型。這是一個折線圖,用於在每個類別訓練步驟中繪製混淆矩陣中的對角值。此圖顯示了每個類別在整個訓練步驟中的準確性如何進展。您可以從此圖中識別表現不佳的類別。
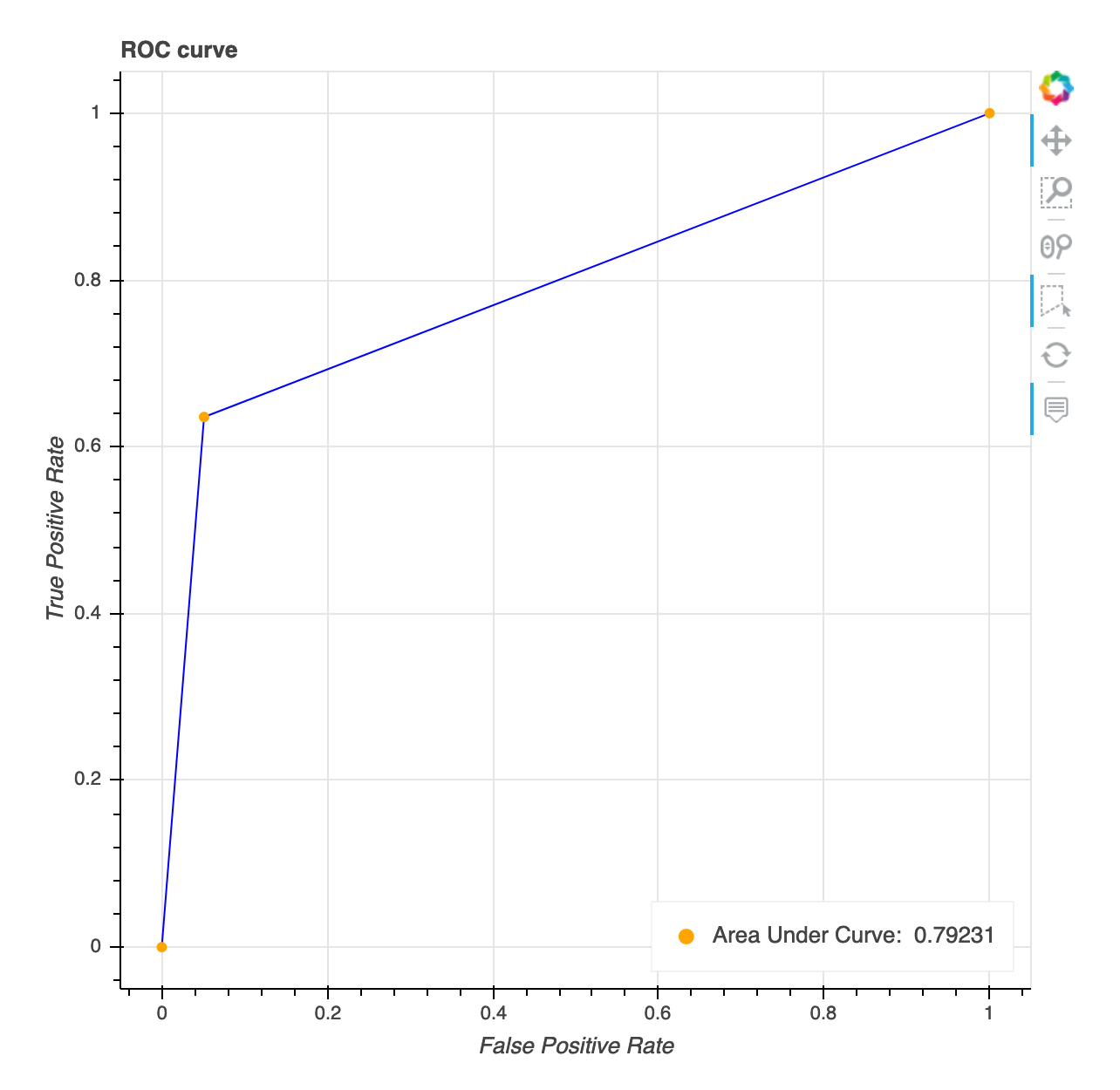
接收器操作特性曲線
此視覺化內容僅適用於二進制分類模型。接收器操作特性曲線通常用於評估二進制分類模型效能。曲線的 Y 軸為相符率 (TPF),X 軸為假陽性率 (FPR)。該圖也會顯示曲線下面積 (AUC) 的值。AUC 值越高,您的分類器就越具預測性。您也可以使用 ROC 曲線來了解 TPR 和 FPR 之間的取捨,並識別適合您使用案例的最佳分類閾值。可以調整分類閾值以微調模型的行為,以減少一種或另一種類型的錯誤 (FP/FN)。
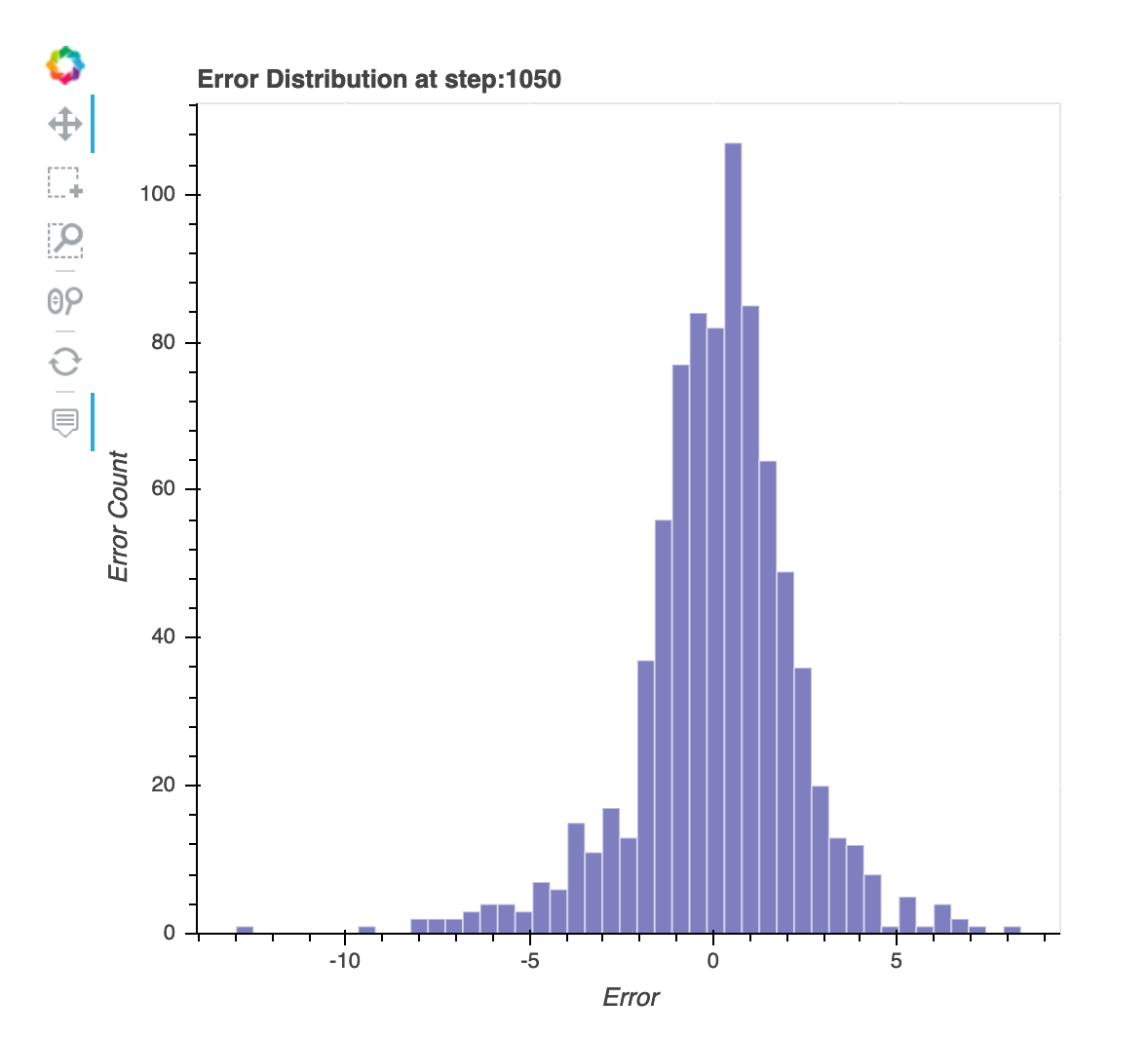
最後一個儲存步驟的殘差分佈
此視覺化內容是一個欄位圖,顯示在最後一個步驟 Debugger 擷取的殘差分佈。在此視覺化內容中,您可以檢查殘差分佈是否接近以零為中心的常態分佈。如果殘差有偏態,則您的功能可能不足以預測標籤。
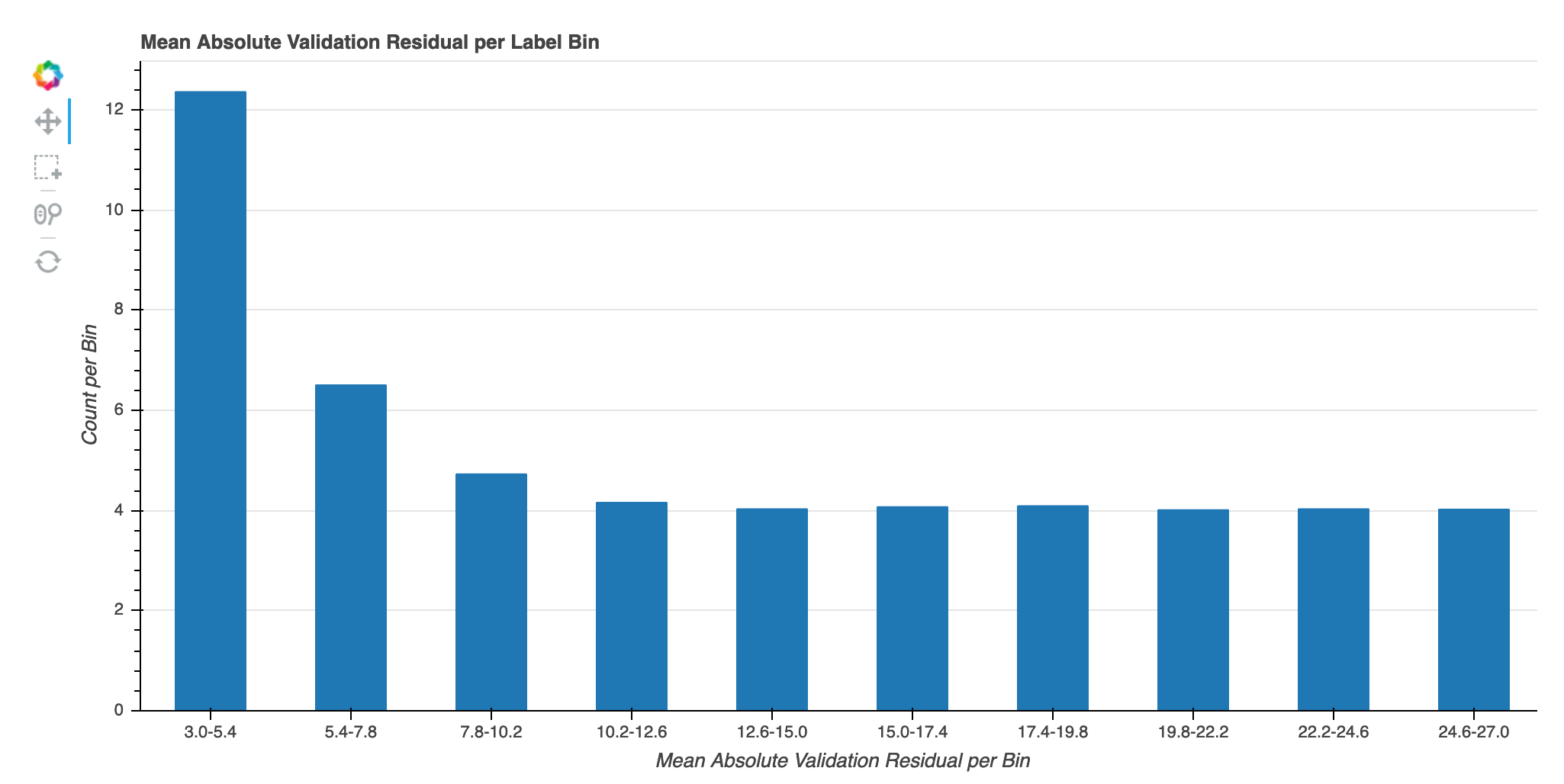
反覆運算時每個標籤儲存貯體的絕對驗證錯誤
此視覺化內容僅適用於迴歸模型。實際的目標值會分割為 10 個間隔。此視覺化內容顯示直線圖中訓練步驟中每個間隔的驗證錯誤如何進展。絕對驗證錯誤是驗證期間預測和實際差異的絕對值。您可以從此視覺化內容中識別效能不佳的間隔。