本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
偵錯工具進階示範和視覺化
下列示範將逐步引導您使用偵錯工具完成進階使用案例和視覺化指令碼。
主題
使用 Amazon SageMaker Experiments 和 Debugger 訓練和刪減模型
Nathalie Rauschmayr 醫生, AWS 應用科學家 | 長度:49 分鐘 26 秒
深入了解 Amazon SageMaker Experiments 和偵錯工具如何簡化訓練任務的管理。Amazon SageMaker Debugger 提供有關訓練任務的透明可見度,並將訓練指標儲存到 Amazon S3 儲存貯體中。SageMaker 實驗可讓您透過 SageMaker Studio 呼叫訓練資訊做為試驗,並支援訓練任務視覺化。這可協助您維持模型的高品質,同時根據重要性排名減少較不重要的參數。
這部影片示範了模型刪減技術,讓預先訓練的 ResNet50 和 AlexNet 模型更輕量化且經濟實惠,同時保留模型準確度的高標準。
SageMaker AI 估算器會在具有 PyTorch 架構的 AWS 深度學習容器中訓練 PyTorch 模型庫所提供的演算法,而偵錯工具會從訓練程序中擷取訓練指標。
影片也會示範如何設定偵錯工具自訂規則,以監看已剔除模型的準確度、在準確度達到閾值時觸發 Amazon CloudWatch 事件和 AWS Lambda 函數,以及自動停止剔除程序以避免備援反覆運算。
學習目標如下:
-
了解如何使用 SageMaker AI 加速 ML 模型訓練並改善模型品質。
-
了解如何自動擷取輸入參數、組態和結果,以使用 SageMaker Experiments 管理訓練反覆運算。
-
探索偵錯工具如何從加權、批度和卷積神經網路的啟用輸出等指標自動擷取即時張量資料,以讓訓練程序透明化。
-
當 Debugger 擷取問題時,使用 CloudWatch 觸發 Lambda。
-
使用 SageMaker Experiments 和偵錯工具精通 SageMaker 訓練程序。
若要尋找這部影片所使用的筆記本和訓練指令碼,請參閱 SageMaker Debugger PyTorch 反覆運算模型刪減
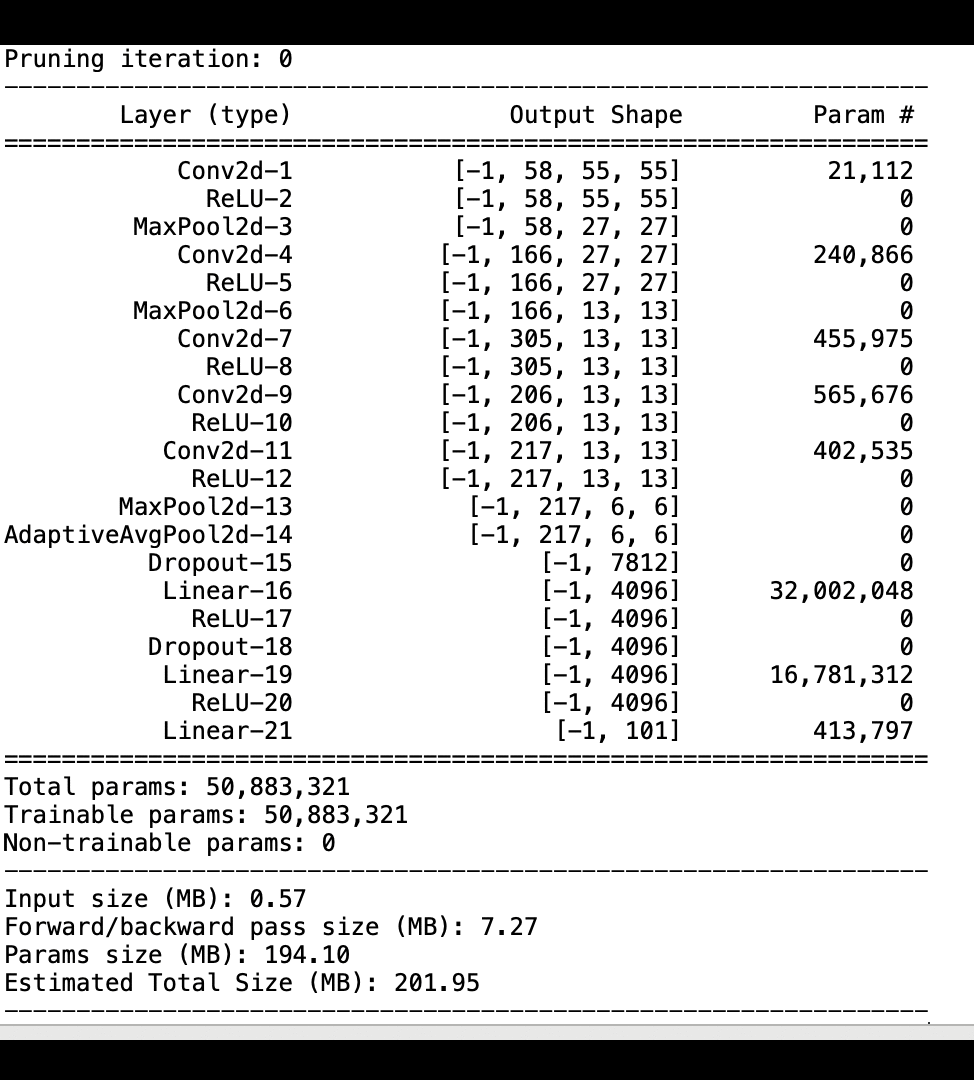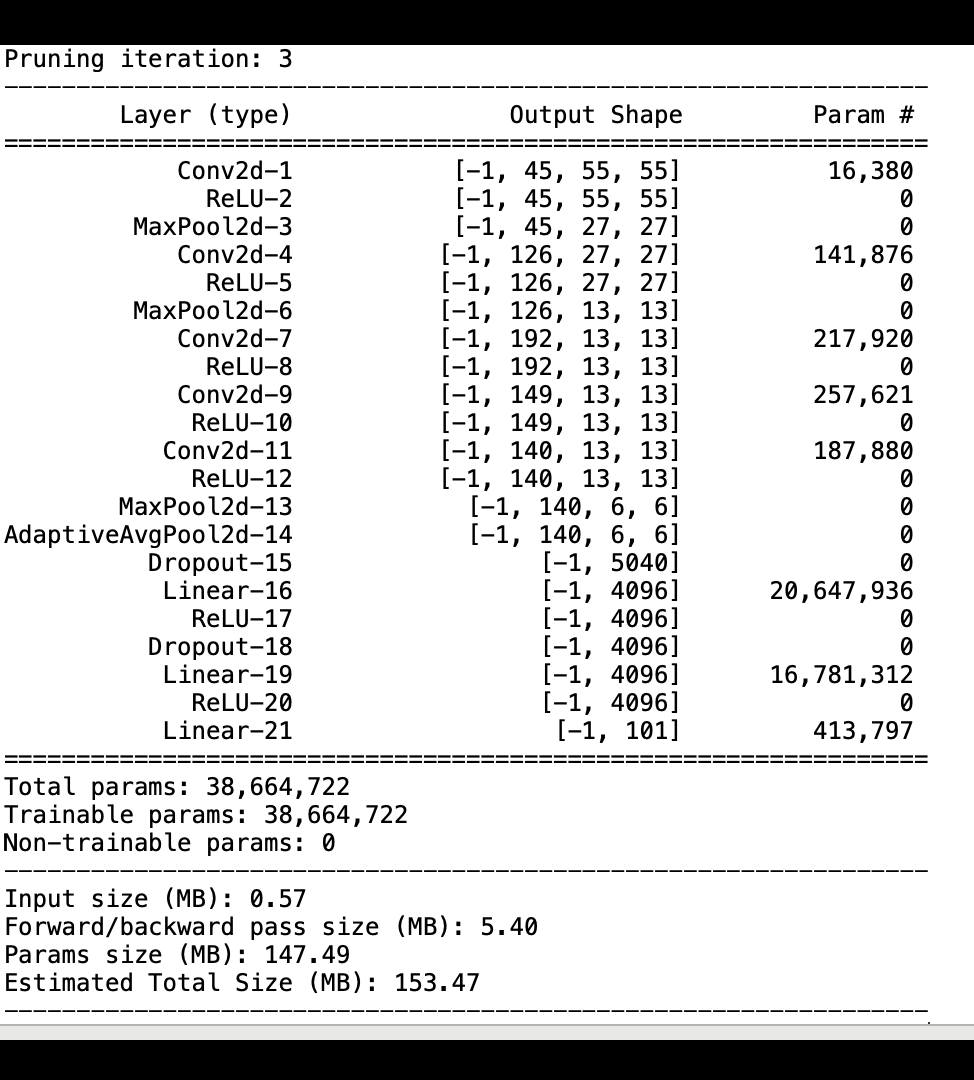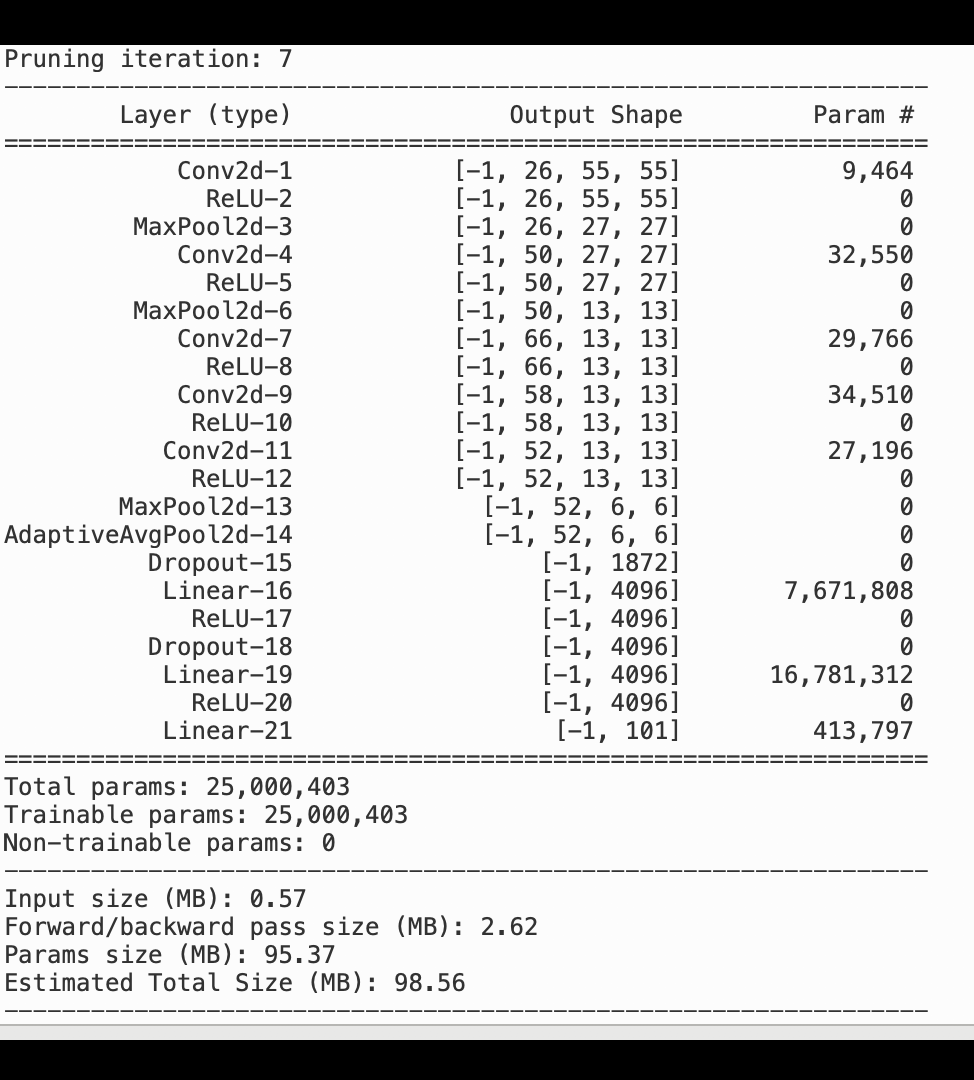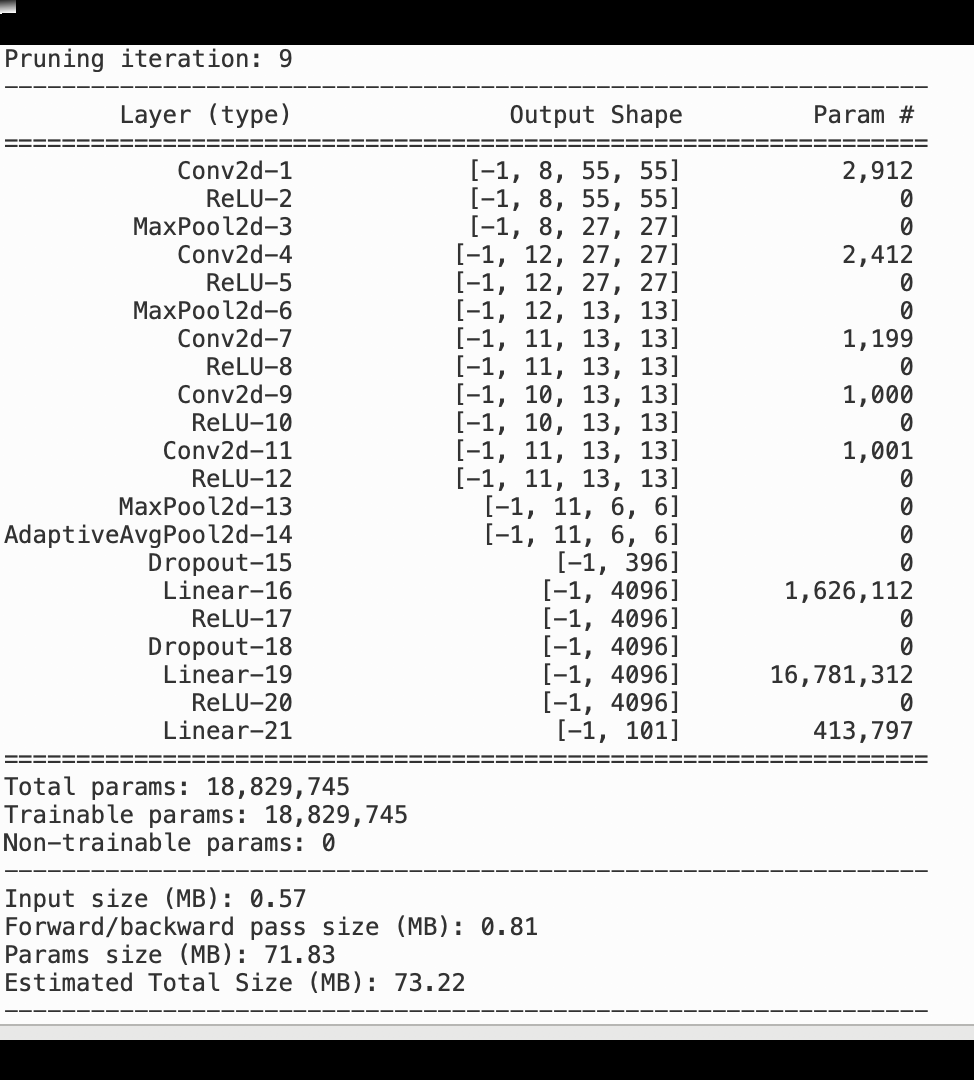
下列影像顯示反覆運算模型刪減程序如何根據啟用輸出和坡度所評估的重要性排名,刪去 100 個最不重要的篩選條件,以縮減 AlexNet 的大小。
刪減程序已將最初的 5000 萬個參數縮減為 1800 萬個參數。它也已將預估模型大小從 201 MB 縮減為 73 MB。
您也需要追蹤模型準確度,而下列影像顯示您可如何繪製模型刪減程序,以根據 SageMaker Studio 中的參數數量視覺化模型準確度的變更。
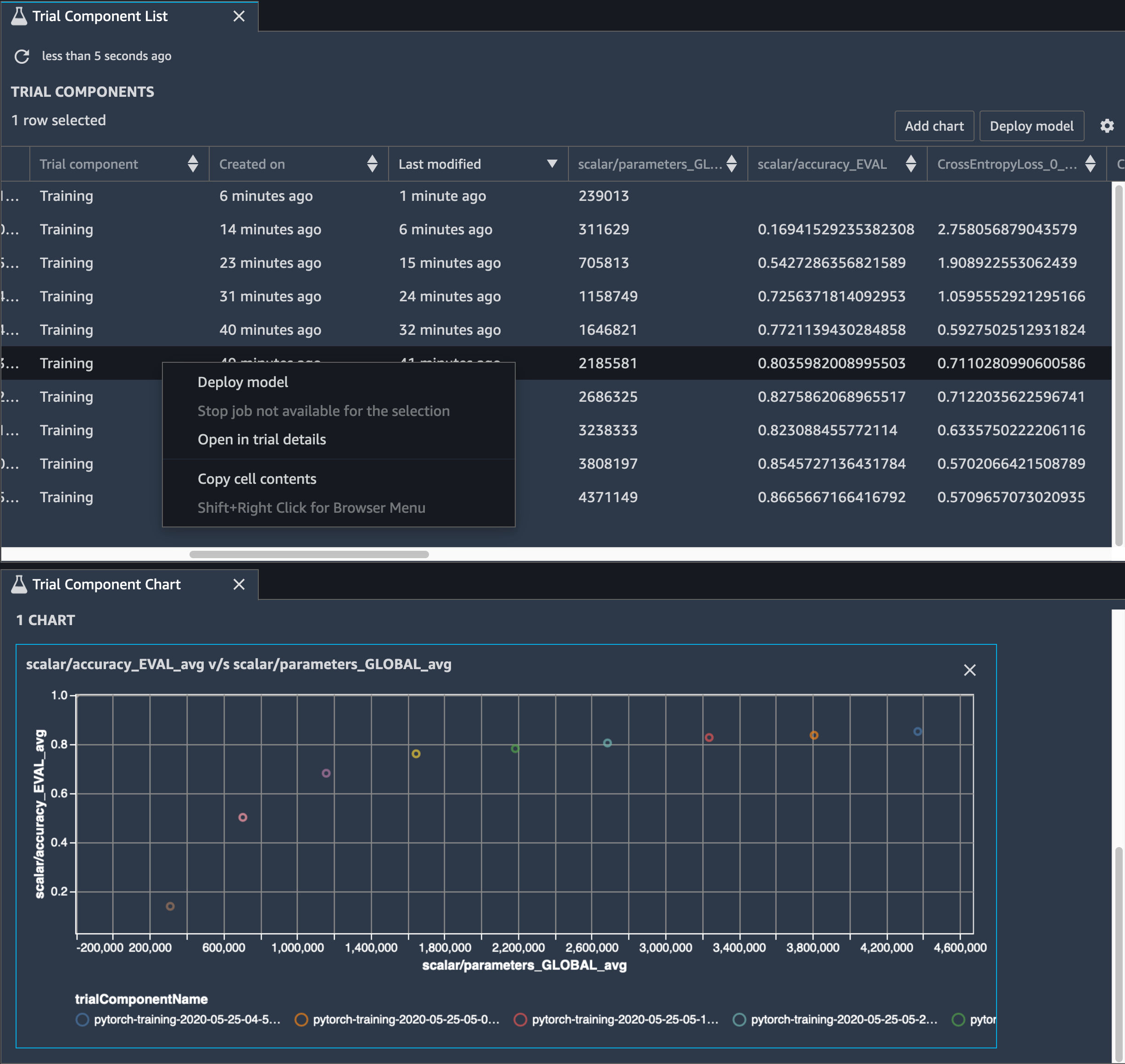
在 SageMaker Studio 中,選擇實驗索引標籤,從刪減程序中選取由偵錯程式儲存的張量清單,然後構成試驗元件清單面板。將十個反覆運算全選,然後選擇新增圖表,以建立試驗元件圖表。決定要部署的模型之後,請選擇試驗元件和要執行動作的功能表,或選擇部署模型。
注意
若要使用下列筆記本範例透過 SageMaker Studio 部署模型,請在 train.py 指令碼中的 train 函式結尾處新增一行程式碼。
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
使用 SageMaker Debugger 監控卷積自動編碼器模型訓練
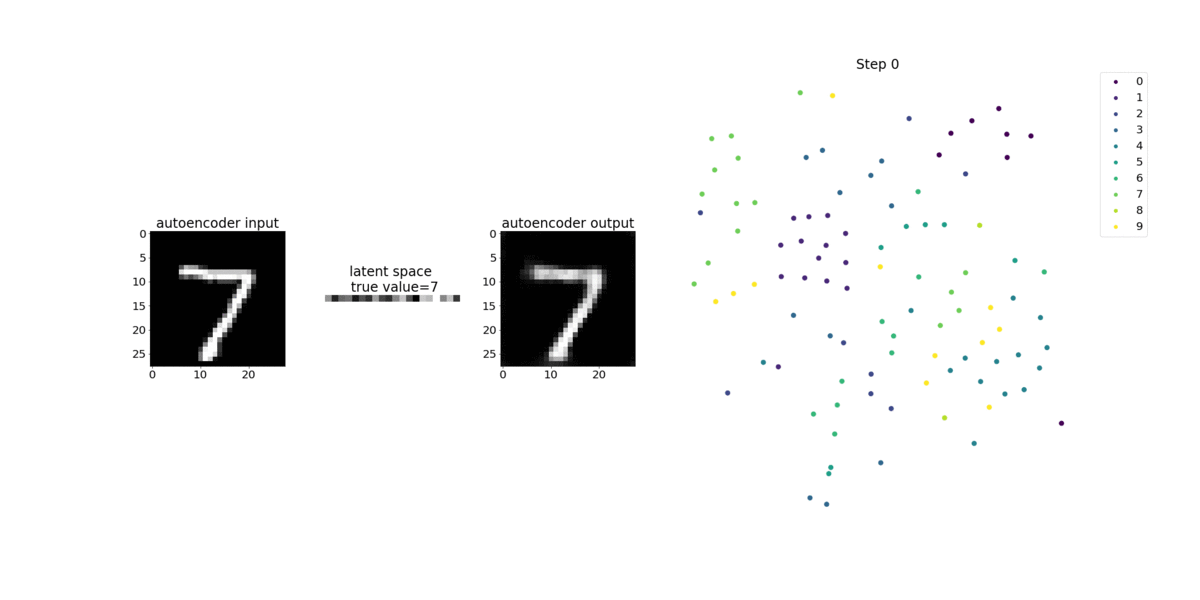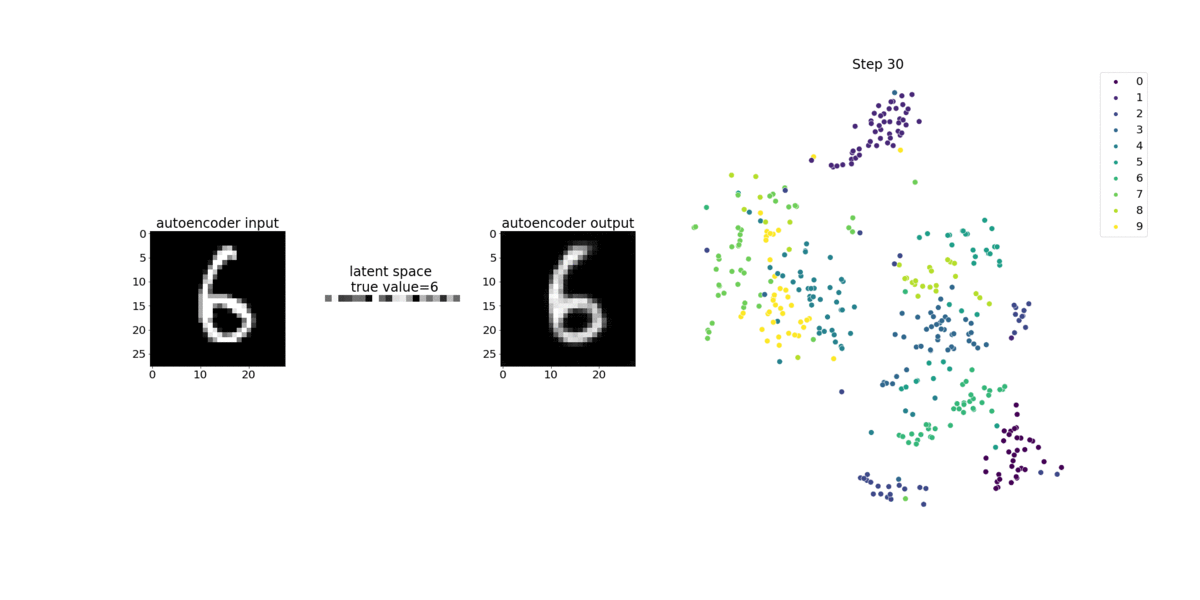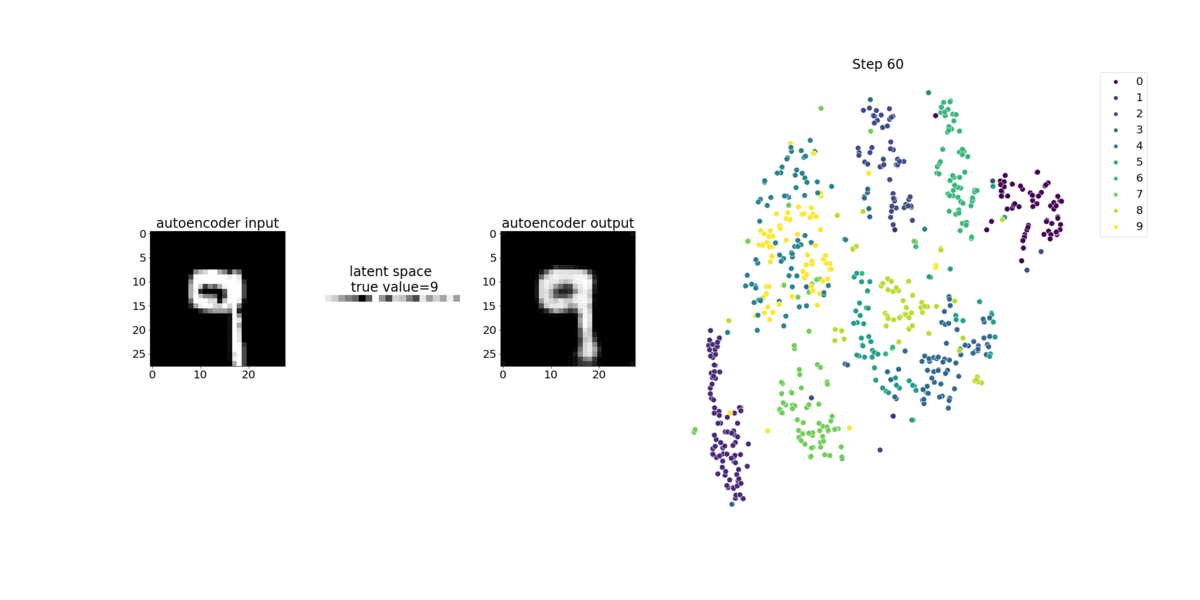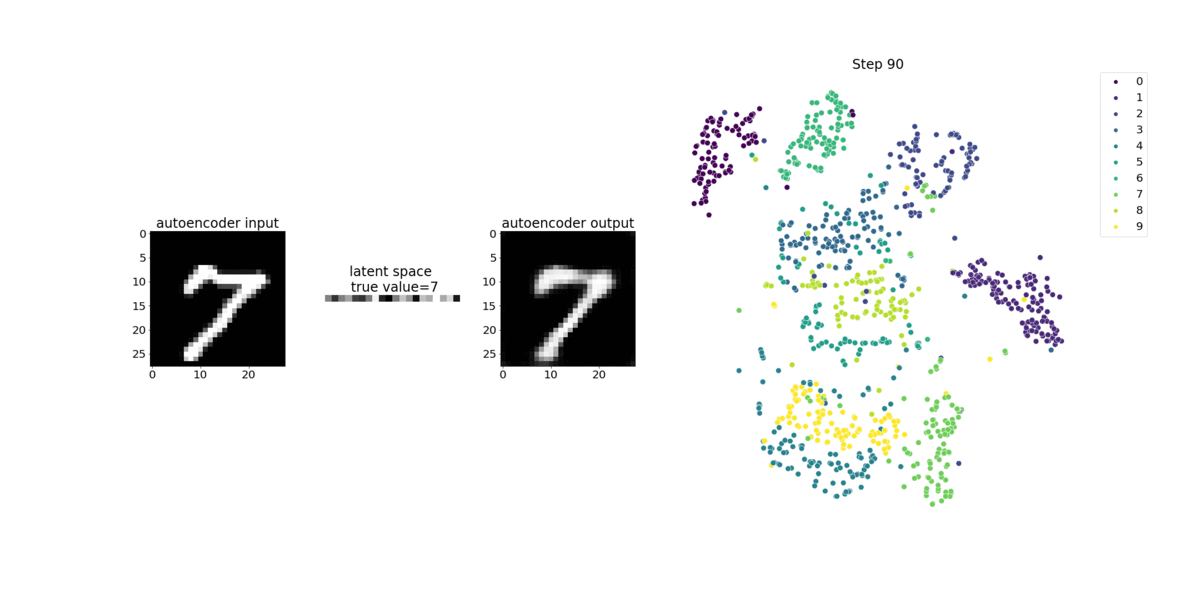
此筆記本示範 SageMaker Debugger 如何視覺化來自手寫數字 MNIST 影像資料集上非監督式 (或自我監督式) 學習程序的張量。
此筆記本中的訓練模型是具有 MXNet 架構的卷積自動編碼器。此卷積自動編碼器具有瓶頸成形的卷積神經網路,其中包含一個編碼器部分和一個解碼器部分。
此範例中的編碼器有兩個卷積層,可產生輸入影像的壓縮表示法 (隱含變數)。在此案例中,編碼器會從大小 (28、28) 的原始輸入影像產生大小 (1、20) 的隱含變數,並大幅縮減訓練的資料大小 (高達 40 次)。
解碼器具有兩個非卷積層,而且可以重新建構輸出影像,以確保隱含變數保留重要資訊。
卷積編碼器可透過較小的輸入資料大小為叢集演算法提供技術,以及提供 K 平均數、k-NN 和 t-Distributed Stochastic Neighbor Embedding (t-SNE) 等叢集演算法的效能。
此筆記本範例示範如何使用偵錯工具視覺化隱含變數,如下列動畫所示。它也示範 t-SNE 演算法如何將隱含變數分類為十個叢集,並將它們投影到 2D 空間中。影像右側的散佈圖色彩結構呈現真正的值,說明 BERT 模型和 t-SNE 演算法將隱含變數整理為叢集的情況是否良好。
使用 SageMaker Debugger 監控 BERT 模型訓練中的注意力
來自轉換器的雙向編碼表示法 (BERT) 是一種語言表示法模型。正如此模型的名稱所示,BERT 模型建置於適用於自然語言處理 (NLP) 的轉換學習和轉換器模型。
BERT 模型會在非監督式任務上預先訓練,例如預測句子中的遺失單字或預測自然接著上一句的下一個句子。訓練資料包含 33 億個英文文字的單字 (權杖),來源為 Wikipedia 和電子書等。若為簡單範例,BERT 模型可將高注意力提供給來自主詞權杖的適當動詞權杖或代名詞權杖。
預先訓練的 BERT 模型可使用額外的輸出層進行微調,在問題回應自動化、文字分類等 NLP 任務中達到最先進的模型訓練成果。
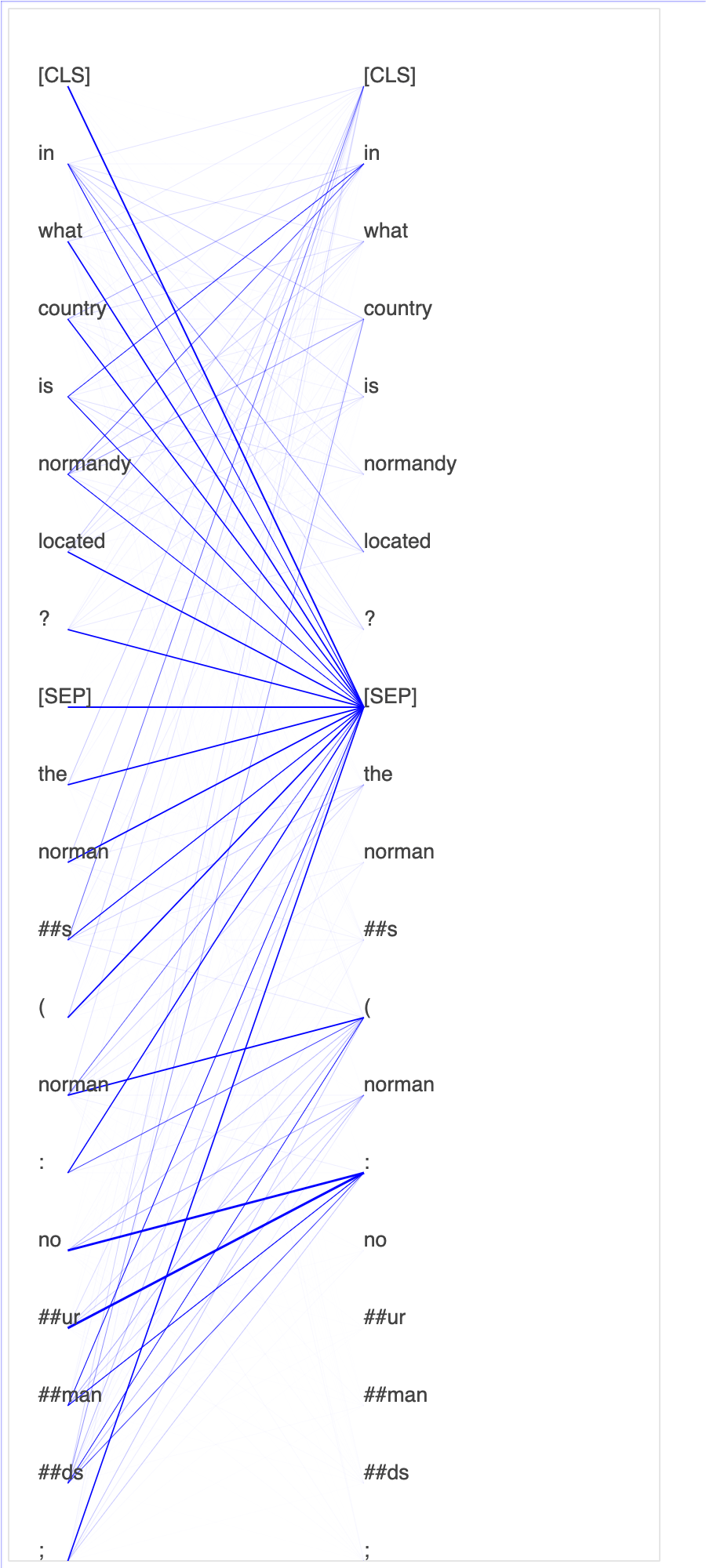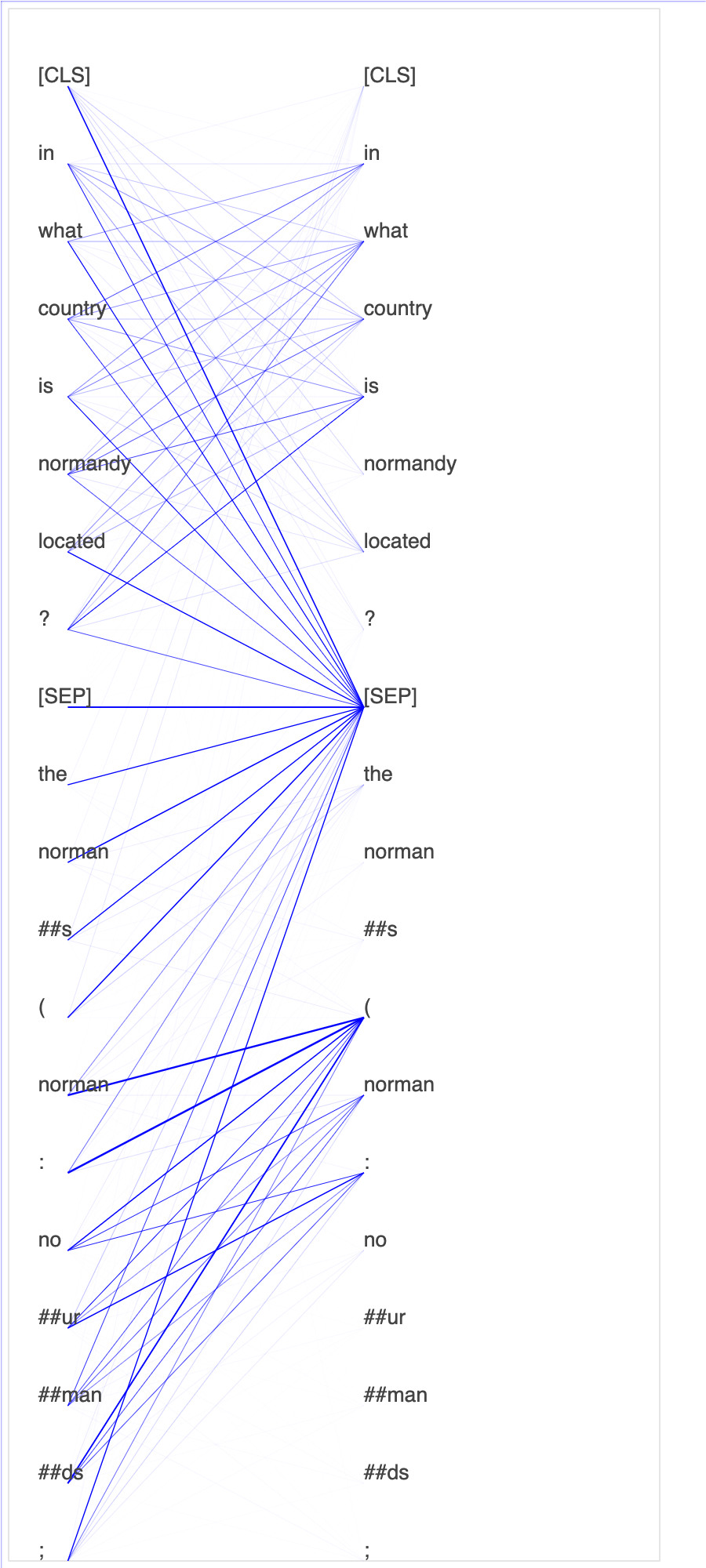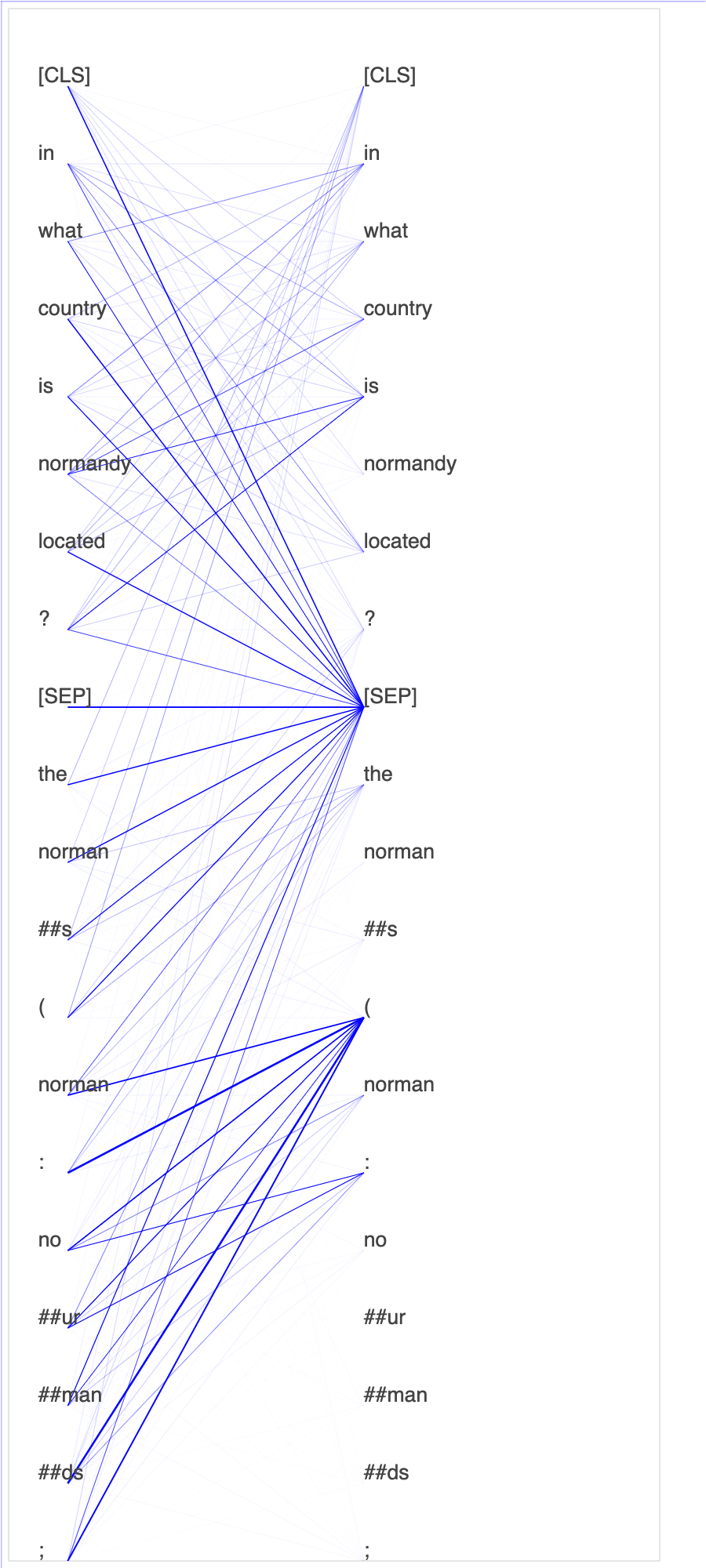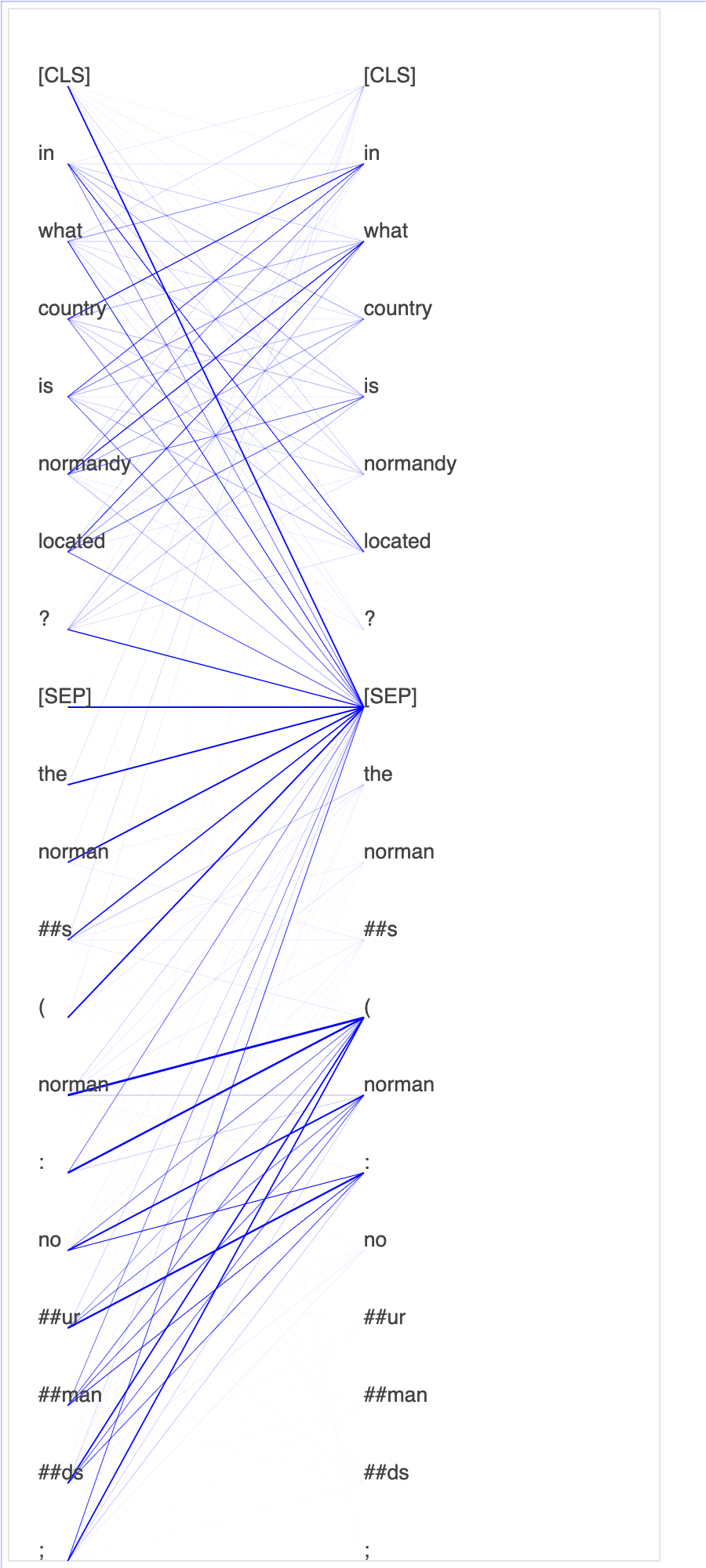
偵錯工具從微調程序收集張量。在 NLP 的內容中,神經元的權重稱為注意力。
此筆記本示範如何在 Stanford 問題和回答資料集上使用來自 GluonNLP 模型庫的預先訓練 BERT 模型
在查詢和關鍵向量中繪製注意力分數 和個別神經元,可協助您識別不正確模型預測的原因。透過 SageMaker AI Debugger,您可以在訓練進行並了解模型學習內容的同時,擷取張量並即時繪製注意力頭檢視畫面。
下列動畫顯示筆記本範例提供的訓練任務中,十個反覆運算的前 20 個輸入權杖的注意力分數。
使用 SageMaker Debugger 在卷積神經網路 (CNNs) 中視覺化類別啟用映射
此筆記本示範如何使用 SageMaker Debugger 來繪製類別啟用地圖,以供卷積神經網路 (CNN) 內的影像偵測和分類使用。在深度學習中,卷積神經網路 (CNN 或 ConVNet) 屬於深度神經網路類別,最常用於分析視覺影像。自動駕駛車輛是採用分類啟用地圖的其中一個應用程式,這需要影像的立即偵測和分類,例如交通號誌、道路和障礙物。
在此筆記本中,PyTorch ResNet 模型是在德國交通號誌資料集
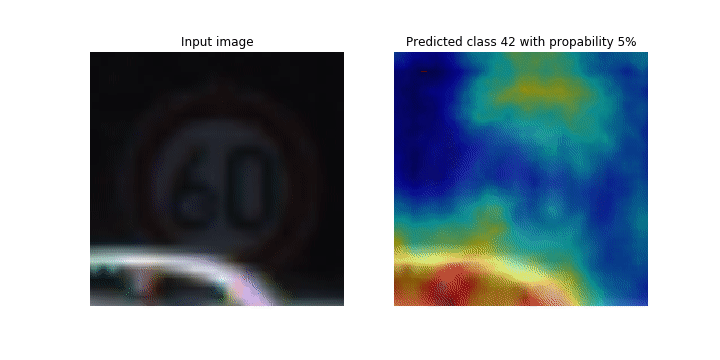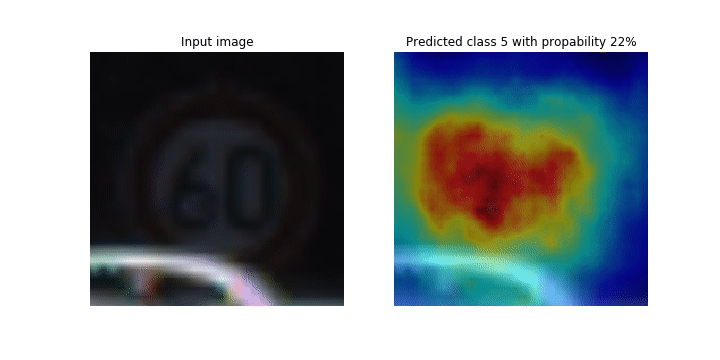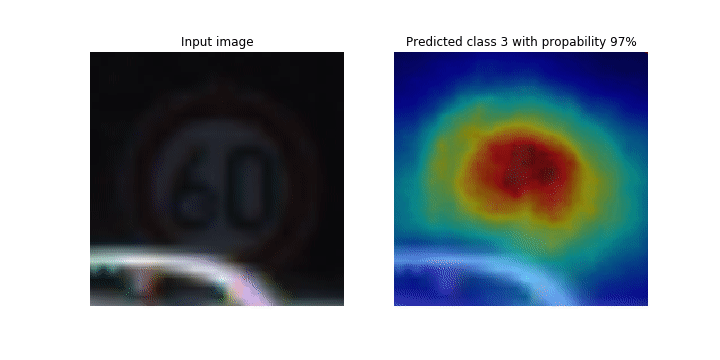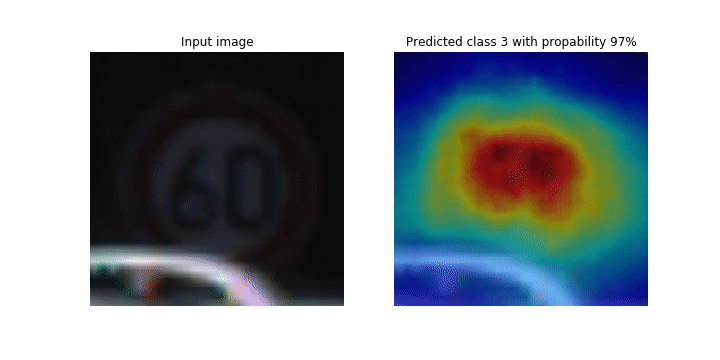
在訓練程序期間,SageMaker Debugger 會收集張量,以即時繪製類別啟用地圖。如此動畫影像所示,類別啟用地圖 (也稱為顯著性地圖) 會以紅色突顯高度啟用的區域。
您可以使用偵錯工具擷取的張量,視覺化啟用地圖如何在模型訓練期間進化。首先,模型會在訓練任務開始時偵測左下角的邊緣。在訓練繼續進行的同時,焦點會移動到中央並偵測速度限制號誌,而模型成功地將輸入影像預測為類別 3,這是速度限制 60km/h 號誌的類別,具有 97% 的信賴度。
