本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用 在 Amazon SageMaker AI 中建立模型 ModelBuilder
在 SageMaker AI 端點上準備部署模型需要多個步驟,包括選擇模型映像、設定端點組態、編碼序列化和還原序列化函數,以往返伺服器和用戶端傳輸資料、識別模型相依性,以及上傳到 Amazon S3。 ModelBuilder可以降低初始設定和部署的複雜性,協助您在單一步驟中建立可部署模型。
ModelBuilder 會為您執行下列任務:
只需一個步驟,即可將使用 XGBoost或 等各種架構訓練的機器學習模型 PyTorch 轉換為可部署模型。
根據模型架構執行自動容器選擇,因此您不需要手動指定容器。您仍然可以透過將自己的容器傳遞URI至 來攜帶自己的容器
ModelBuilder。先處理用戶端上的資料序列化,再將其傳送至伺服器,以推論和還原序列化伺服器傳回的結果。資料格式正確,無需手動處理。
啟用相依性自動擷取,並根據模型伺服器預期封裝模型。
ModelBuilder的相依性自動擷取是動態載入相依性的最佳方法。(我們建議您在本機測試自動擷取,並更新相依性以符合您的需求。)對於大型語言模型 (LLM) 使用案例, 選擇性地對可在 SageMaker AI 端點上託管時部署的 服務屬性執行本機參數調校,以獲得更好的效能。
支援大多數熱門模型伺服器和容器 TorchServe,例如 Triton DJLServing和TGI容器。
使用 建置模型 ModelBuilder
ModelBuilder 是一種 Python 類別XGBoost PyTorch,採用架構模型,例如 或使用者指定的推論規格,並將其轉換為可部署的模型。 ModelBuilder提供建置函數,可產生部署成品。產生的模型成品是模型伺服器特有的,您也可以指定 做為其中一個輸入。如需 ModelBuilder類別的詳細資訊,請參閱 ModelBuilder
下圖說明使用 時的整體模型建立工作流程ModelBuilder。 ModelBuilder接受模型或推論規格以及您的結構描述,以建立可在部署之前在本機測試的可部署模型。
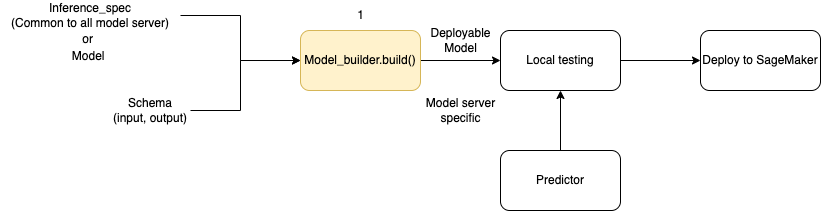
ModelBuilder 可以處理您想要套用的任何自訂。不過,若要部署架構模型,模型建置器至少需要模型、範例輸入和輸出,以及角色。在下列程式碼範例中, ModelBuilder 會使用架構模型呼叫 ,並使用SchemaBuilder最小引數呼叫 執行個體 (以推斷對應的 函數來序列化和還原序列化端點輸入和輸出)。未指定容器,也不會傳遞封裝相依性 - SageMaker AI 會在您建置模型時自動推斷這些資源。
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
下列程式碼範例ModelBuilder會使用推論規格 (做為InferenceSpec執行個體) 叫用,而非使用模型,並搭配額外的自訂。在此情況下,呼叫模型建置器包含儲存模型成品的路徑,並開啟所有可用相依性的自動擷取。如需 的其他詳細資訊InferenceSpec,請參閱 自訂模型載入和處理請求。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
定義序列化和還原序列化方法
叫用 SageMaker AI 端點時,資料會透過MIME不同類型的HTTP承載傳送。例如,傳送至端點以進行推論的影像需要轉換為用戶端的位元組,並透過HTTP承載傳送至端點。當端點收到承載時,它需要將位元組字串還原序列化回模型預期的資料類型 (也稱為伺服器端還原序列化)。模型完成預測後,結果也需要序列化為位元組,可透過HTTP承載傳回給使用者或用戶端。一旦用戶端收到回應位元組資料,就需要執行用戶端還原序列化,將位元組資料轉換回預期的資料格式,例如 JSON。您至少需要轉換下列任務的資料:
推論請求序列化 (由用戶端處理)
推論請求還原序列化 (由伺服器或演算法處理)
針對承載叫用模型,並將回應承載傳回
推論回應序列化 (由伺服器或演算法處理)
推論回應還原序列化 (由用戶端處理)
下圖顯示您叫用端點時所發生的序列化和還原序列化程序。
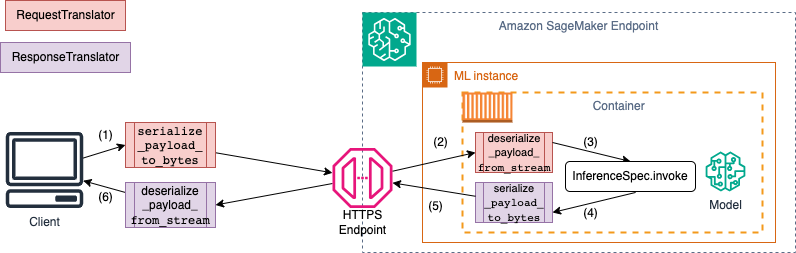
當您提供範例輸入和輸出給 時SchemaBuilder,結構描述建置器會產生對應的串列函數,以序列化和還原序列化輸入和輸出。您可以使用 進一步自訂序列化函數CustomPayloadTranslator。但是,在大多數情況下,簡單的序列化器,例如以下,將有效:
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
如需 的詳細資訊SchemaBuilder,請參閱 SchemaBuilder
下列程式碼片段概述了範例,您想要在用戶端和伺服器端自訂序列化和還原序列化函數。您可以使用 定義自己的請求和回應譯者CustomPayloadTranslator,並將這些譯者傳遞給 SchemaBuilder。
透過將輸入和輸出與轉換器結合,模型建置器可以擷取模型預期的資料格式。例如,假設範例輸入是原始映像,而您的自訂轉譯器會裁切映像,並將裁切映像以張量形式傳送至伺服器。 ModelBuilder需要原始輸入和任何自訂預先處理或後置處理程式碼,才能衍生方法,來轉換用戶端和伺服器端的資料。
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
建立SchemaBuilder物件時,您會將範例輸入和輸出與先前定義的自訂譯者一起傳遞,如下列範例所示:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
然後,您將輸入和輸出範例,以及先前定義的自訂譯者傳遞至SchemaBuilder物件。
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
以下各節詳細說明如何使用 建置模型ModelBuilder,並使用其支援類別來自訂使用案例的體驗。
自訂模型載入和處理請求
透過 提供您自己的推論程式碼,InferenceSpec提供額外的自訂層。使用 InferenceSpec,您可以自訂模型的載入方式,以及模型處理傳入推論請求的方式,略過其預設載入和推論處理機制。使用非標準模型或自訂推論管道時,這種彈性特別有用。您可以自訂 invoke方法,以控制模型如何預先處理和後處理傳入的請求。此invoke方法可確保模型正確處理推論請求。下列範例使用 InferenceSpec來產生具有 HuggingFace 管道的模型。如需 的更多詳細資訊InferenceSpec,請參閱 InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
下列範例說明先前範例的自訂變化。模型的定義為具有相依性的推論規格。在這種情況下,推論規格中的程式碼取決於 lang-segment 套件。的 引數dependencies包含 陳述式,指示建置器使用 Git 安裝 lang-segment。由於模型建置器是由使用者引導來自訂安裝相依性,因此auto金鑰是False關閉相依性的自動擷取。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
建置模型並部署
呼叫 build函數來建立可部署的模型。此步驟會在您的工作目錄中使用建立結構描述、執行輸入和輸出的序列化和還原序列化,以及執行其他使用者指定的自訂邏輯所需的程式碼來建立推論程式碼 (做為 inference.py)。
做為完整性檢查, SageMaker AI 會封裝和挑選必要的檔案,以做為ModelBuilder建置函數的一部分進行部署。在此過程中, SageMaker AI 也會為 pickle 檔案建立HMAC簽署,並在 (deploy或 create) 期間將秘密金鑰新增至CreateModelAPI環境變數。端點啟動使用環境變數來驗證 pickle 檔案的完整性。
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
使用模型的現有deploy方法部署模型。在此步驟中, SageMaker AI 會設定端點來託管模型,並開始對傳入請求進行預測。雖然 ModelBuilder 推斷部署模型所需的端點資源,但您可以使用自己的參數值覆寫這些估算值。下列範例指示 SageMaker AI 在單一ml.c6i.xlarge執行個體上部署模型。由 建構的模型可在部署期間ModelBuilder啟用即時記錄,做為新增功能。
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
如果您想要對指派給模型的端點資源進行更精細的控制,您可以使用 ResourceRequirements 物件。使用 ResourceRequirements 物件,您可以請求您想要部署的模型的最小數量 CPUs、 加速器和副本。您也可以請求記憶體下限和上限 (以 MB 為單位)。若要使用此功能,您需要將端點類型指定為 EndpointType.INFERENCE_COMPONENT_BASED。下列範例會請求四個加速器,最低記憶體大小為 1024 MB,以及要部署到 類型端點的模型複本EndpointType.INFERENCE_COMPONENT_BASED。
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
攜帶您自己的容器 (BYOC)
如果您想要攜帶自己的容器 (從 SageMaker AI 容器延伸),您也可以指定映像URI,如下列範例所示。您也需要識別與 映像對應的模型伺服器,ModelBuilder以產生模型伺服器特有的成品。
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
ModelBuilder 在本機模式中使用
您可以使用 mode引數在本機測試和部署之間切換到端點,以在本機部署模型。您需要將模型成品存放在工作目錄中,如下列程式碼片段所示:
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
傳遞模型物件、SchemaBuilder執行個體,並將模式設定為 Mode.LOCAL_CONTAINER。當您呼叫 build函數時, ModelBuilder會自動識別支援的架構容器,並掃描相依性。下列範例示範在本機模式下使用 模型建立XGBoost模型。
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
呼叫 deploy函數以在本機部署,如下列程式碼片段所示。如果您為執行個體類型或計數指定參數,則會忽略這些引數。
predictor_local = xgb_local_builder.deploy()
本機模式疑難排解
視個別本機設定而定,您可能會在環境中ModelBuilder遇到順暢執行的困難。請參閱下列清單,了解您可能面臨的一些問題,以及如何解決這些問題。
已在使用中:您可能會遇到
Address already in use錯誤。在這種情況下,Docker 容器可能在該連接埠上執行,或另一個程序正在使用它。您可以遵循 Linux 文件中概述的方法,識別程序,並正常地將本機程序從連接埠 8080 重新導向至另一個連接埠或清除 Docker 執行個體。 IAM 許可問題:嘗試提取 Amazon ECR映像或存取 Amazon S3 時,您可能會遇到許可問題。在此情況下,導覽至筆記本或 Studio Classic 執行個體的執行角色,以驗證 的政策
SageMakerFullAccess或個別API許可。EBS 磁碟區容量問題:如果您部署大型語言模型 (LLM),則在本機模式下執行 Docker 時可能會用盡空間,或遇到 Docker 快取的空間限制。在這種情況下,您可以嘗試將 Docker 磁碟區移至空間足夠的檔案系統。若要移動 Docker 磁碟區,請完成下列步驟:
開啟終端機並執行
df以顯示磁碟用量,如下列輸出所示:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000將預設 Docker 目錄從 移至
/dev/nvme0n1p1/dev/nvme2n1,以便您可以充分利用 256 GB SageMaker AI 磁碟區。如需詳細資訊,請參閱如何移動 Docker 目錄的文件。 使用下列命令停止 Docker:
sudo service docker stop將
daemon.json新增至/etc/docker或將下列 JSON Blob 附加至現有 Blob。{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }/var/lib/docker/home/ec2-user/SageMaker AI使用下列命令將 Docker 目錄移入 :sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}使用以下命令啟動 Docker:
sudo service docker start使用下列命令清除垃圾桶:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *如果您使用的是 SageMaker 筆記本執行個體,您可以遵循 Docker 準備檔案中
的步驟,為本機模式準備 Docker。
ModelBuilder 範例
如需使用 ModelBuilder建置模型的更多範例,請參閱ModelBuilder範例筆記本
