本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
選擇輸入模式和儲存單位
訓練工作的最佳資料來源取決於工作負載特性,例如資料集的大小、檔案格式、檔案平均大小、訓練持續時間、資料載入器讀取模式為循序或隨機,以及模型可以取用訓練資料的速度。下列最佳實務提供準則,讓您開始使用最適合使用案例的輸入模式和資料儲存服務。
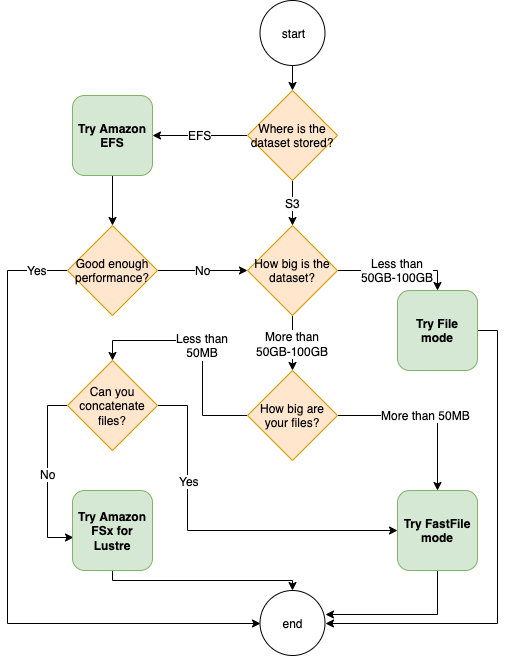
何時使用 Amazon EFS
如果您的資料集儲存在 Amazon Elastic File System 中,您可能有使用 Amazon EFS 儲存的預處理或註釋應用程式。您可以執行訓練任務,設定指向 Amazon EFS 檔案系統的資料通道。如需詳細資訊,請參閱使用 Amazon FSx for Lustre 和 Amazon EFS 檔案系統加速 Amazon SageMaker AI 的訓練 FSx EFS
針對小型資料集使用檔案模式
如果資料集儲存在 Amazon Simple Storage Service 內,且資料集的總體磁碟區相對較小 (例如小於 50-100 GB),請嘗試使用檔案模式。下載 50 GB 資料集的額外負荷,會因檔案的數量而有所不同。例如,如果將資料集分成 100 MB 的碎片,則大約需要 5 分鐘。這樣的啟動額外負荷是否可接受,主要取決於訓練工作的整體持續時間,因為較長的訓練階段意味著下載階段的佔比較低。
序列化許多小型檔案
如果您的資料集很小 (小於 50-100 GB),但由許多小型檔案 (每個檔案少於 50 MB) 組成,則檔案模式下載額外負荷會增加,因為每個檔案都需要從 Amazon Simple Storage Service 分別下載到訓練執行個體磁碟區。若要減少這種額外負荷和資料周遊的整體時間,請考慮使用檔案格式,例如 TensorFlow 的 TefRecord
何時使用快速檔案模式
對於檔案較大 (每個檔案大於 50 MB) 的大型資料集,第一個選項是試用快速檔案模式,這比 FSx for Lustre 更容易使用,因為它不需要建立檔案系統或連線至 VPC。快速檔案模式非常適合大型檔案容器 (大於 150 MB),並且對於大於 50 MB 的檔案也很適合。由於快速檔案模式提供 POSIX 介面,因此它支援隨機讀取 (讀取非循序位元範圍)。但是,這不是理想的使用案例,您的輸送量可能會低於循序讀取。不過,如果您有相對較大且運算強度高的機器學習 (ML) 模型,則快速檔案模式仍然可以使訓練管道的有效頻寬飽和,而不會造成 IO 瓶頸。您需要實驗看看。若要從檔案模式切換到快速檔案模式 (或回復),只需在使用 SageMaker Python SDK 定義輸入通道時新增 (或移除) input_mode='FastFile' 參數即可:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
何時使用 Amazon FSx for Lustre
如果您的資料集對於檔案模式而言太大、有許多您無法輕易序列化的小型檔案,或者使用隨機讀取存取權模式,FSx for Lustre 是一個不錯的選項。它的檔案系統可擴展至每秒數百 GB (GB/s) 的輸送量和數百萬 IOPS,這在您有許多小型檔案時非常理想。但是請注意,由於延遲載入以及設定、初始化 FSx for Lustre 檔案系統的額外負荷,可能會有冷啟動問題。
提示
如需進一步了解,請參閱為您的 Amazon SageMaker 訓練工作選擇最佳資料來源
