本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
管道模型
模型平行程式庫的核心功能之一是管線平行處理原則,可決定進行計算的順序,以及在模型訓練期間跨裝置處理資料的順序。 SageMakerPipelining 是一種在模型平行處理原則中實現真正平行化的技術,方法是在不同的資料樣本上同時GPUs運算,並克服因循序計算而導致的效能損失。當您使用管線平行處理原則時,訓練工作會以管線方式透過微批次執行,以最大化使用率。GPU
注意
管線平行處理原則 (也稱為模型分割) 可用於 PyTorch 和 TensorFlow。如需架構的支援版本清單,請參閱支援的架構與 AWS 區域。
管道執行排程
管線是基於將迷你批次拆分為微批次,這些微批次被饋入培訓管道, one-by-one 並遵循庫運行時定義的執行時間表。微批次是指定訓練迷你批次的較小子集。管道排程決定每個時段由哪個裝置執行哪個微批次。
例如,根據管線排程和模型分區的不同,GPUi可能會對微批次執行(向前或向後)計算,同b時對微批次GPUi+1執行計算b+1,從而同時保持兩者處於GPUs活動狀態。在單次向前或向後傳遞期間,單一微批次的執行流程可能多次造訪相同裝置,具體取決於分割決定。例如,模型開頭的作業可能與模型結束時間的作業位於同一裝置,而介於兩者之間的作業則位於不同裝置,這代表造訪該裝置兩次。
該庫提供了兩種不同的管道計劃,簡單和交錯,可以使用 Python 中的pipeline參數進行配置。 SageMaker SDK在大多數情況下,交錯管道可以通過更有效地利用來實現GPUs更好的性能。
INTERLEAVED 管道
在 INTERLEAVED 管道,盡可能優先考量微批次的向後執行。這樣可更快釋放用於啟用的記憶體,以便更以有效的方式使用記憶體。它還允許更高的縮放微粒的數量, 減少的空閒時間. GPUs 在穩定狀態,每個裝置在向前與向後傳遞之間進行交替。這代表可能會先執行單一微批次的向後傳遞,即使另一微批次的向前傳遞尚未完成。

上圖說明交錯配管的範例執行排程超過 2。GPUs在圖中,F0 代表微批次 0 的向前傳遞,B1 代表微批次 1 的向後傳遞。更新代表參數的最佳化工具更新。GPU0 總是在可能的情況下優先順序向後傳遞(例如,在 F2 之前執行 B0),這允許清除之前用於激活的內存。
簡便管道
相比之下,簡便管道會先完成執行每個微批次的向前傳遞,然後再開始向後傳遞。這代表其只在其管道內傳輸向前傳遞及向後傳遞階段。下圖說明了這是如何工作的一個例子,超過 2 GPUs。

在特定架構執行管道傳輸
請參閱下列各節,瞭解框架特定管線排程決策 SageMaker的模型平行程度程式庫所做的和。 TensorFlow PyTorch
管道執行 TensorFlow
下列影像是使用自動化模型分割的模型平行程式庫分割的 TensorFlow 圖形範例。當分割圖表時,每個生成的子圖表會複寫 B 倍 (變數除外),其中 B 是微批次數量。在此圖,每個子圖表均複寫 2 次 (B=2)。在子圖表的每個輸入處插入 SMPInput 作業,並在每個輸出處插入 SMPOutput 作業。這些作業會與程式庫後端進行通訊,以便彼此傳輸張量。

下列映像範例說明 2 個子圖表以 B=2 分割並新增漸層作業。SMPInput 作業的漸層是 SMPOutput 作業,反之亦然。這可讓漸層在反向傳播期間向後流動。
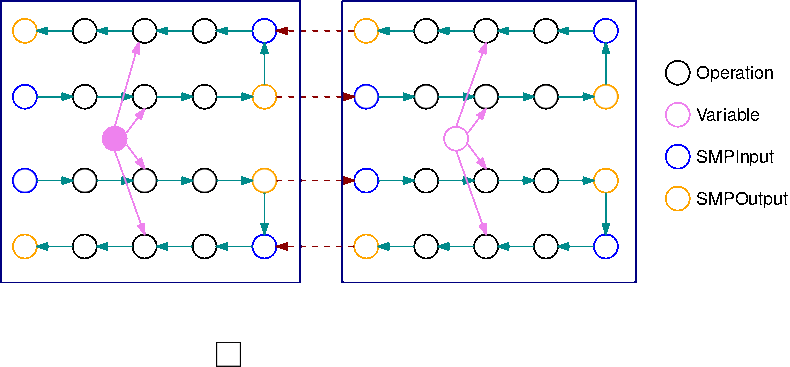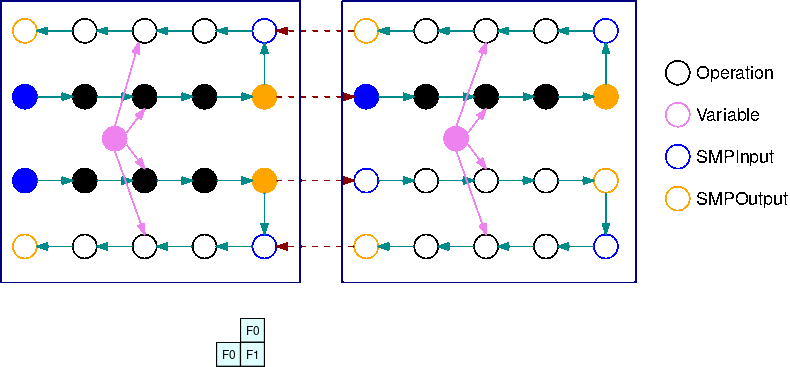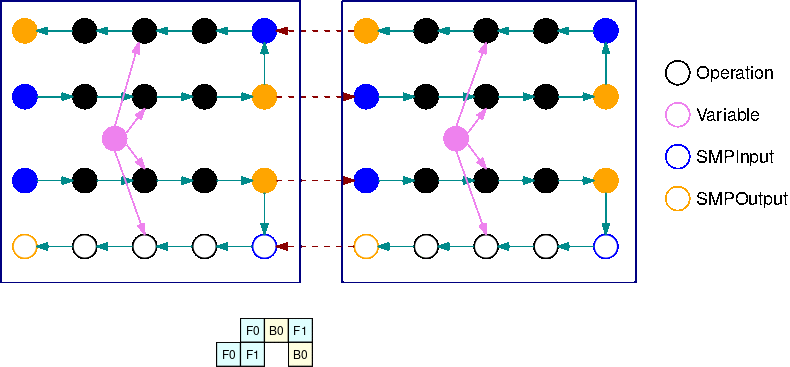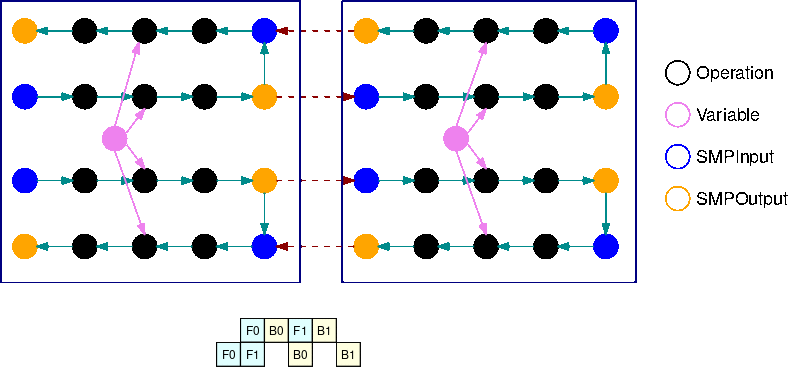
這GIF演示了一個例子交錯管道執行計劃與 B = 2 微批和 2 個子圖。每個設備按順序執行其中一個子圖副本以提高使用率。GPU隨著 B 變大,閒置時間時段的小部分會變為零。無論何時在特定子圖形複本執行 (向前或向後) 運算時,管道層都會向相應藍色 SMPInput 作業發出訊號以開始執行。
一旦運算單一最小批次所有微批次的漸層,程式庫會跨微批次結合漸層,然後可將其套用至參數。
管道執行 PyTorch
從概念上講,流水線遵循. PyTorch 但是,由於 PyTorch 不涉及靜態圖形,因此模型平行程式庫的 PyTorch 功能使用更加動態的管線範例。
如在 TensorFlow, 每個批次被分成多個微粒, 這是在每個設備上的時間執行一個. 不過,執行排程是透過啟動於每個裝置的執行伺服器來處理。每當目前裝置需要放置在另一裝置的子模組輸出時,執行請求將與子模組的輸入張量一起傳送至遠端裝置的執行伺服器。然後,伺服器使用指定輸入來執行此模組,並將回應傳回目前裝置。
由於目前裝置在遠端子模組執行期間處於閒置狀態,因此目前微批次的本機執行會暫停,且程式庫執行期將切換為執行目前裝置可有效處理的另一微批次。微批次的優先順序由所選擇的管道排程決定。對於 INTERLEAVED 管道排程,處於運算向後階段的微批次會盡可能優先考量。
