本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Object2Vec 的運作方式
使用 Amazon SageMaker AI Object2Vec 演算法時,請依照標準工作流程:處理資料、訓練模型,然後產生推論。
步驟 1:處理資料
在預先處理期間,將資料轉換為中適用於 Object2Vec 訓練的資料格式指定的 JSON 行np.random.shuffle;若為 Unix,則可以使用 shuf。
步驟 2:訓練模型
SageMaker AI Object2Vec 演算法具有以下主要元件:
-
兩個輸入管道 — 輸入管道會採用相同或不同類型的一對物件做為輸入,並將它們傳遞到獨立和可自訂的編碼器。
-
兩個編碼器 — 兩個編碼器 (enc0 和 enc1) 可將每個物件轉換為固定長度的內嵌向量。成對物件的編碼內嵌接著會傳遞到比較程式。
-
比較程式 — 比較程式會以不同方式比較內嵌,並輸出分數以指出成對物件間的關係強度。在句子對的輸出分數中。例如,1 指出句子對之間的強式關係,而 0 代表弱式關係。
在訓練期間,演算法會接受物件組和其關係標籤或分數做為輸入。每一對中的物件可以屬於不同類型,如前所述。如果這兩個編碼器的輸入是由相同權杖層級單位組成,則您可以使用共用的權杖內嵌層,方法為在建立訓練任務時,將 tied_token_embedding_weight 超參數設為 True。這是可行的,例如,當比較同時具有字組權杖層級單位的句子時。若要以指定的比率產生負面範例,請將 negative_sampling_rate 超參數設為所需的負面與正面範例比。此超參數可加速學習如何區分訓練資料中觀察到的正面範例和不可能觀察到的負面範例。
物件對是透過獨立的、可自訂的編碼器來傳遞,而這些編碼器相容於對應物件的輸入類型。編碼器可將一對中的每個物件轉換為等長的固定長度內嵌向量。向量對會傳遞給比較程式運算子,以使用 comparator_list 超參數中指定的值,將這些向量組合成單一向量。然後,組合向量會通過多層感知器 (MLP) 層,這會產生一個輸出,而損失函式會將其與提供的標籤進行比較。這個比較會評估成對物件之間的關係強度,是否如模型預測一般。下圖顯示此工作流程。
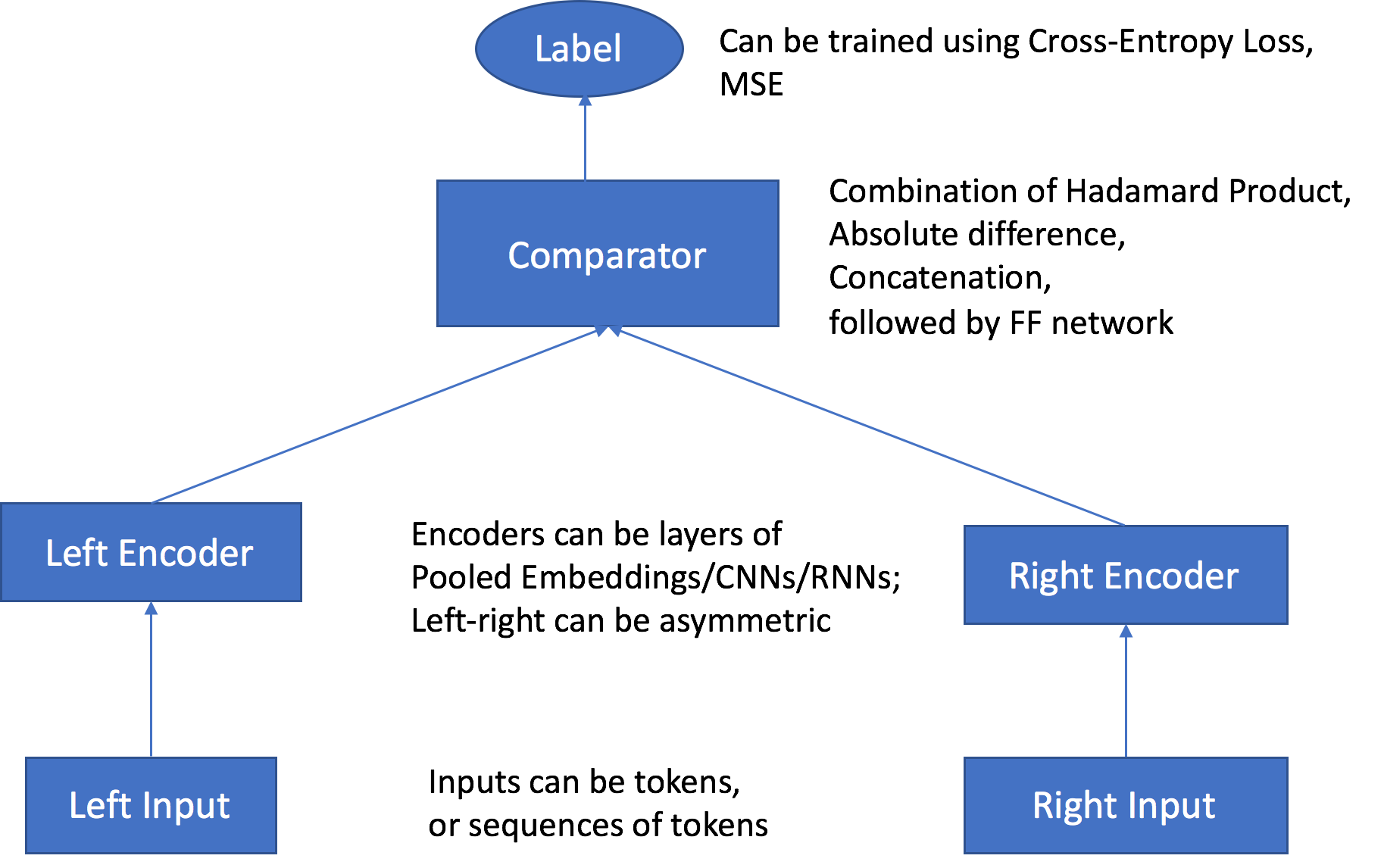
從資料輸入到分數的 Object2Vec 演算法架構
步驟 3:產生推論
訓練模型後,您可以使用已訓練的編碼器,來預先處理輸入物件或執行兩種類型的推論:
-
使用對應的編碼器,將單一輸入物件轉換為固定長度內嵌
-
預測成對輸入物件之間的關係標籤或分數
推論伺服器會根據輸入資料自動判斷請求類型。若要取得內嵌做為輸出,請只提供一個輸入。若要預測關係標籤或分數,請提供該對中的兩個輸入。
