本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon 的 RL 環境 SageMaker
Amazon SageMaker RL 使用環境來模擬真實世界案例。指定環境的目前狀態及代理程式所採取的動作,模擬器便會處理動作的影響,並傳回下一個狀態及獎勵。當在真實世界中訓練代理程式不安全時 (例如操控一台無人機),或是當 RL 演算法花費太多時間進行收斂時 (例如下西洋棋時),模擬器便會很有用。
下圖顯示與一個賽車遊戲模擬器互動的範例。
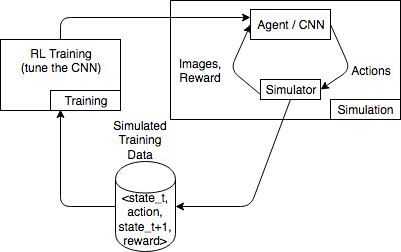
模擬環境由代理程式及模擬器組成。在這裡,卷積神經網絡(CNN)從模擬器中消耗圖像並生成控制遊戲控制器的操作。透過多次模擬,此環境會產生形式為 state_t、action、state_t+1 及 reward_t+1 的訓練資料。定義獎勵並不容易,且會影響 RL 模型的品質。我們希望提供幾個獎勵函式的範例,但也想要讓使用者能夠進行設定。
在 RL 環境中 SageMaker 使用 OpenAI 健身房介面
若要在 SageMaker RL 中使用 OpenAI 健身房環境,請使用下列API元素。如需有關 OpenAI Gym 的詳細資訊,請參閱 Gym 文件
-
env.action_space—定義代理程式能採取的動作,指定每個動作是否連續或離散,並在動作為連續動作時,指定最小值及最大值。 -
env.observation_space—定義代理程式從環境接收到的觀察,以及連續觀察的最小值及最大值。 -
env.reset()—初始化訓練集。reset()函式會傳回環境的初始狀態,而代理程式則會使用初始狀態來採取第一個動作。動作接著會重複傳送到step(),直到集到達最終狀態為止。當step()傳回done = True時,集便會結束。RL 工具組會呼叫reset()來重新初始化環境。 -
step()—將代理動作做為輸入,並輸出環境的下一個狀態、獎勵、集是否已終止,以及一個info字典來通訊除錯資訊。環境需要負責驗證輸入。 -
env.render()—用於具備視覺化的環境。RL 工具組會在每一次呼叫step()函式後,呼叫此函式來擷取環境的視覺化。
使用開放原始碼環境
您可以建置自己的容器 RoboSchool,在 SageMaker RL 中使用開放原始碼環境,例如 EnergyPlus 和。如需有關的詳細資訊 EnergyPlus,請參閱 https://energyplus.net/
使用商業環境
您可以通過構建自己的容器在 SageMaker RL 中使用商業環境,例如MATLAB和 Simulink。您需要管理您自己的授權。
