本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Quickstart:建立 SageMaker AI 沙盒網域,以在 Studio 中啟動 Amazon EMR 叢集
本節會逐步引導您快速設定 Amazon SageMaker Studio 中的完整測試環境。您將建立新的 Studio 網域,讓使用者直接從 Studio 啟動新的 Amazon EMR 叢集。這些步驟提供範例筆記本,您可以連線至 Amazon EMR 叢集以開始執行Spark工作負載。使用此筆記本,您將使用 Amazon EMR Spark 分散式處理和 OpenSearch 向量資料庫來建置擷取增強產生系統 (RAG)。
注意
若要開始使用,請使用具有管理員許可的 AWS Identity and Access Management (IAM) 使用者帳戶登入 AWS 管理主控台。如需如何註冊 AWS 帳戶並建立具有管理存取權的使用者的詳細資訊,請參閱 完成 Amazon SageMaker AI 先決條件。
若要設定 Studio 測試環境並開始執行Spark任務:
步驟 1:建立 SageMaker AI 網域以在 Studio 中啟動 Amazon EMR 叢集
在下列步驟中,您會套用 AWS CloudFormation 堆疊來自動建立新的 SageMaker AI 網域。堆疊也會建立使用者設定檔,並設定所需的環境和許可。SageMaker AI 網域設定為讓您直接從 Studio 啟動 Amazon EMR 叢集。在此範例中,Amazon EMR 叢集是在與 SageMaker AI 相同的 AWS 帳戶中建立,無需身分驗證。您可以在 get_started
注意
SageMaker AI 預設允許每個 AWS 帳戶 5 個 Studio 網域 AWS 區域 。在建立堆疊之前,請確定您的帳戶在您的區域中不超過 4 個網域。
請依照下列步驟設定 SageMaker AI 網域,以從 Studio 啟動 Amazon EMR 叢集。
-
從
sagemaker-studio-emrGitHub 儲存庫下載此AWS CloudFormation 範本的原始檔案。 -
前往 AWS CloudFormation 主控台:https://https://console.aws.amazon.com/cloudformation
-
選擇建立堆疊,然後從下拉式選單中選擇使用新資源 (標準)。
-
在步驟 1 中:
-
在準備範本區段中,選取選擇現有範本。
-
在 Specify template (指定範本) 區段中,選擇 Upload a template file (上傳範本檔案)。
-
上傳下載的 AWS CloudFormation 範本,然後選擇下一步。
-
-
在步驟 2 中,輸入 Stack 名稱和 SageMakerDomainName,然後選擇下一步。
-
在步驟 3 中,保留所有預設值,然後選擇下一步。
-
在步驟 4 中,勾選方塊以確認資源建立,然後選擇建立堆疊。這會在您的帳戶和區域中建立 Studio 網域。
步驟 2:從 Studio UI 啟動新的 Amazon EMR 叢集
在下列步驟中,您可以從 Studio UI 建立新的 Amazon EMR 叢集。
-
前往位於 https://https://console.aws.amazon.com/sagemaker/
的 SageMaker AI 主控台,然後在左側選單中選擇網域。 -
按一下您的網域名稱 GenerativeAIDomain 以開啟網域詳細資訊頁面。
-
從使用者設定檔 啟動 Studio
genai-user。 -
在左側導覽窗格中,前往資料,然後 Amazon EMR 叢集。
-
在 Amazon EMR 叢集頁面上,選擇建立。選取由 AWS CloudFormation 堆疊建立的範本 SageMaker Studio Domain No Auth EMR,然後選擇下一步。
-
輸入新 Amazon EMR 叢集的名稱。選擇性地更新其他參數,例如核心節點和主節點的執行個體類型、閒置逾時或核心節點數量。
-
選擇建立資源以啟動新的 Amazon EMR 叢集。
建立 Amazon EMR 叢集後,請遵循 EMR 叢集頁面上的狀態。當狀態變更為 時
Running/Waiting,Amazon EMR 叢集即可在 Studio 中使用。
步驟 3:將 JupyterLab 筆記本連接至 Amazon EMR 叢集
在下列步驟中,您將 JupyterLab 中的筆記本連接至執行中的 Amazon EMR 叢集。在此範例中,您可以匯入筆記本,讓您使用 Amazon EMR Spark 分散式處理和 OpenSearch 向量資料庫來建置擷取增強型產生 (RAG) 系統。
-
啟動 JupyterLab
從 Studio 啟動 JupyterLab 應用程式。
-
建立私有空間
如果您尚未為 JupyterLab 應用程式建立空間,請選擇建立 JupyterLab 空間。輸入空間的名稱,並將空間保留為私有。將所有其他設定保留為預設值,然後選擇建立空間。
否則,請執行您的 JupyterLab 空間以啟動 JupyterLab 應用程式。
-
部署 LLM 和內嵌模型以進行推論
-
從頂端功能表中,選擇檔案、新增,然後選擇終端機。
-
在終端機中,執行下列命令。
wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb mkdir AWSGuides cd AWSGuides wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/AmazonSageMakerDeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/EC2DeveloperGuide.pdf wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/AWSGuides/S3DeveloperGuide.pdf這會將
Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb筆記本擷取到本機目錄,並將三個 PDF 檔案下載到本機AWSGuides資料夾。 -
開啟
lab-00-setup/Lab_0_Warm_Up_Deploy_EmbeddingModel_Llama2_on_Nvidia.ipynb,保留Python 3 (ipykernel)核心,然後執行每個儲存格。警告
在 Llama 2 授權合約區段中,請務必先接受 Llama2 EULA,再繼續。
筆記本在 上部署兩個模型
all-MiniLM-L6-v2 ModelsLlama 2和ml.g5.2xlarge以進行推論。模型的部署和端點的建立可能需要一些時間。
-
-
開啟您的主要筆記本
在 JupyterLab 中,開啟終端機並執行下列命令。
cd .. wget --no-check-certificate https://raw.githubusercontent.com/aws-samples/sagemaker-studio-foundation-models/main/lab-03-rag/Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb您應該會在 JupyterLab 的左側面板中看到額外的
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb筆記本。 -
選擇
PySpark核心開啟您的
Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb筆記本,並確保您使用SparkMagic PySpark核心。您可以在筆記本的右上角切換核心。選擇目前的核心名稱以開啟核心選取模式,然後選擇SparkMagic PySpark。 -
將筆記本連接至叢集
-
在筆記本的右上角,選擇叢集。此動作會開啟一個模態視窗,列出您有權存取的所有執行中叢集。
-
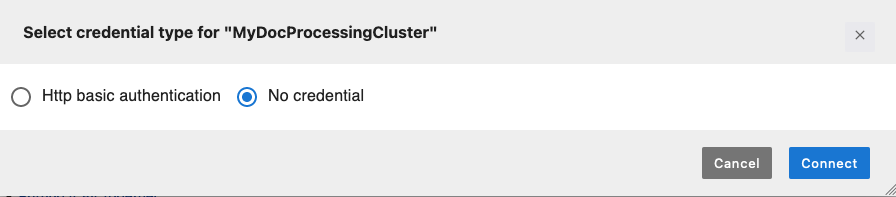
選取您的叢集,然後選擇連線。新的登入資料類型選取模式視窗隨即開啟。
-
選擇無登入資料,然後選擇連線。
-
筆記本儲存格會自動填入並執行。筆記本儲存格會載入
sagemaker_studio_analytics_extension.magics延伸模組,提供連線至 Amazon EMR 叢集的功能。然後,它會使用%sm_analytics魔術命令來啟動與 Amazon EMR 叢集和 Spark 應用程式的連線。注意
確定 Amazon EMR 叢集的連線字串具有設為 的身分驗證類型
None。--auth-type None下列範例中的值會說明此項目。您可以視需要修改 欄位。%load_ext sagemaker_studio_analytics_extension.magics %sm_analytics emr connect --verify-certificate False --cluster-idyour-cluster-id--auth-typeNone--language python -
成功建立連線後,您的連線儲存格輸出訊息應會顯示您的
SparkSession詳細資訊,包括叢集 ID、YARN應用程式 ID 和 UI Spark 連結,以監控您的Spark任務。
-
您已準備好使用Lab_3_RAG_on_SageMaker_Studio_using_EMR.ipynb筆記本。此範例筆記本會執行分散式 PySpark 工作負載,以使用 LangChain 和 OpenSearch 建置 RAG 系統。
步驟 4:清除 AWS CloudFormation 堆疊
完成後,請務必終止兩個端點並刪除 AWS CloudFormation 堆疊,以避免繼續收費。刪除堆疊會清除堆疊佈建的所有資源。
在完成時刪除您的 AWS CloudFormation 堆疊
-
前往 AWS CloudFormation 主控台:https://https://console.aws.amazon.com/cloudformation
-
選取您要刪除的堆疊。您可以依名稱進行搜尋,或在堆疊清單中找到。
-
按一下刪除按鈕以完成刪除堆疊,然後再次刪除以確認這會刪除堆疊建立的所有資源。
等待堆疊刪除完成。這可能需要幾分鐘的時間。 AWS CloudFormation 會自動清除堆疊範本中定義的所有資源。
-
確認堆疊建立的所有資源都已刪除。例如,檢查是否有任何剩餘的 Amazon EMR 叢集。
移除模型的 API 端點
-
前往 SageMaker AI 主控台:https://https://console.aws.amazon.com/sagemaker/
。 -
在左側導覽窗格中,選擇推論,然後選擇端點。
-
選取端點,
hf-allminil6v2-embedding-ep然後在動作下拉式清單中選擇刪除。針對端點 重複 步驟meta-llama2-7b-chat-tg-ep。
