本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon SageMaker AI 中使用異質叢集設定訓練任務
本節提供如何使用包含多個執行個體類型的異質叢集來執行訓練任務之說明。
開始之前,請注意下列事項。
-
所有執行個體群組都共用相同的 Docker 映像和訓練指令碼。因此,您應該修改訓練指令碼,以偵測它所屬的執行個體群組,並相應地進行 fork 執行。
-
異質叢集功能與 SageMaker AI 本機模式不相容。
-
異質叢集訓練任務的 Amazon CloudWatch 日誌串流不會依執行個體群組分組。您需要從日誌中找出哪些節點在哪個群組中。
選項 1:使用 SageMaker Python SDK
遵循如何使用 SageMaker Python 為異質叢集設定執行個體群組的指示SDK。
-
若要針對訓練任務配置異質叢集的執行個體群組,請使用
sagemaker.instance_group.InstanceGroup類別。您可以為每個執行個體群組指定自訂名稱、執行個體類型,以及每個執行個體群組的執行個體數目。如需詳細資訊,請參閱 SageMaker AI Python SDK 文件中的 sagemaker.instance_group.InstanceGroup。 注意
如需可用執行個體類型的詳細資訊,以及您可以在異質叢集中設定的執行個體群組數量上限,請參閱 InstanceGroupAPI參考。
下列程式碼範例示範如何設定兩個執行個體群組,其中包含兩個CPU僅限
ml.c5.18xlarge的執行個體,instance_group_1以及一個名為 的ml.p3dn.24xlargeGPU執行個體instance_group_2,如下圖所示。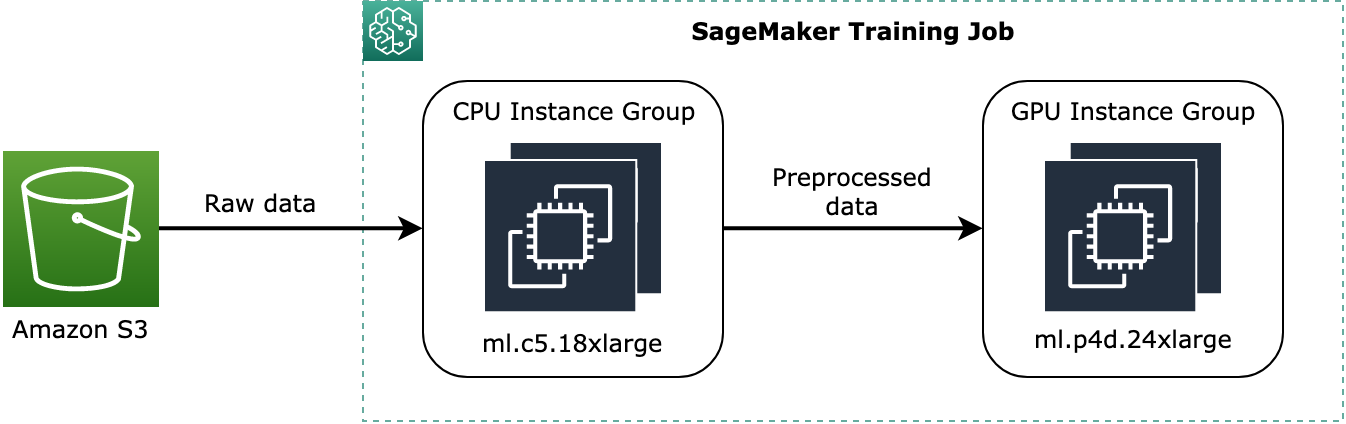
上圖顯示預先訓練程序的概念範例,例如資料預先處理,如何指派給CPU執行個體群組,並將預先處理的資料串流至GPU執行個體群組。
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
使用執行個體群組物件,設定訓練輸入通道,並透過 sagemaker.inputs.TrainingInput
類別的 instance_group_names引數將執行個體群組指派給通道。instance_group_names引數會接受執行個體群組名稱的字串清單。下列範例顯示如何設定兩個訓練輸入頻道,並指派在上一個步驟範例中建立的執行個體群組。您也可以指定 Amazon S3 儲存貯體的
s3_data引數路徑,讓執行個體群組為您的使用目的處理資料。from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )如需
TrainingInput引數的詳細資訊,請參閱以下連結。-
SageMaker Python SDK 文件中的 sagemaker.inputs.TrainingInput
類別 -
SageMaker AI API參考API中的 S3DataSource
-
-
使用
instance_groups引數設定 SageMaker AI 估算器,如下列程式碼範例所示。instance_groups引數接受InstanceGroup物件的清單。注意
異質叢集功能可透過 SageMaker AI PyTorch
和TensorFlow 架構估算器類別取得。支援的架構是 PyTorch v1.10 或更新版本,以及 TensorFlow v2.6 或更新版本。若要尋找可用架構容器、架構版本和 Python 版本的完整清單,請參閱 AWS 深度學習容器 GitHub 儲存庫中的 SageMaker AI Framework Containers 。 注意
AI SageMaker 估算器類別的
instance_type和instance_count引數對和instance_groups引數是互斥的。對於同質叢集訓練,請使用instance_type和instance_count引數對。若要進行異質叢集訓練,請使用instance_groups。注意
若要尋找可用架構容器、架構版本和 Python 版本的完整清單,請參閱 AWS 深度學習容器 GitHub 儲存庫中的 SageMaker AI Framework Containers
。 -
使用執行個體群組配置的訓練輸入頻道來設定
estimator.fit方法,然後開始訓練任務。estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
選項 2:使用低階 SageMaker APIs
如果您使用 AWS Command Line Interface 或 AWS SDK for Python (Boto3) 並想要使用低階 SageMaker APIs 來提交具有異質叢集的訓練任務請求,請參閱下列API參考。
