本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
SageMaker 智慧篩分的運作方式
SageMaker 智慧篩分的目標是在訓練過程中篩選訓練資料,並僅向模型提供更豐富的範例。使用 的典型訓練期間 PyTorch, . SageMaker smart 篩選會在此資料載入階段實作資料,以批次方式反覆傳送至訓練循環和加速裝置 PyTorch DataLoader
下圖顯示如何設計 SageMaker 智慧篩分演算法的概觀。
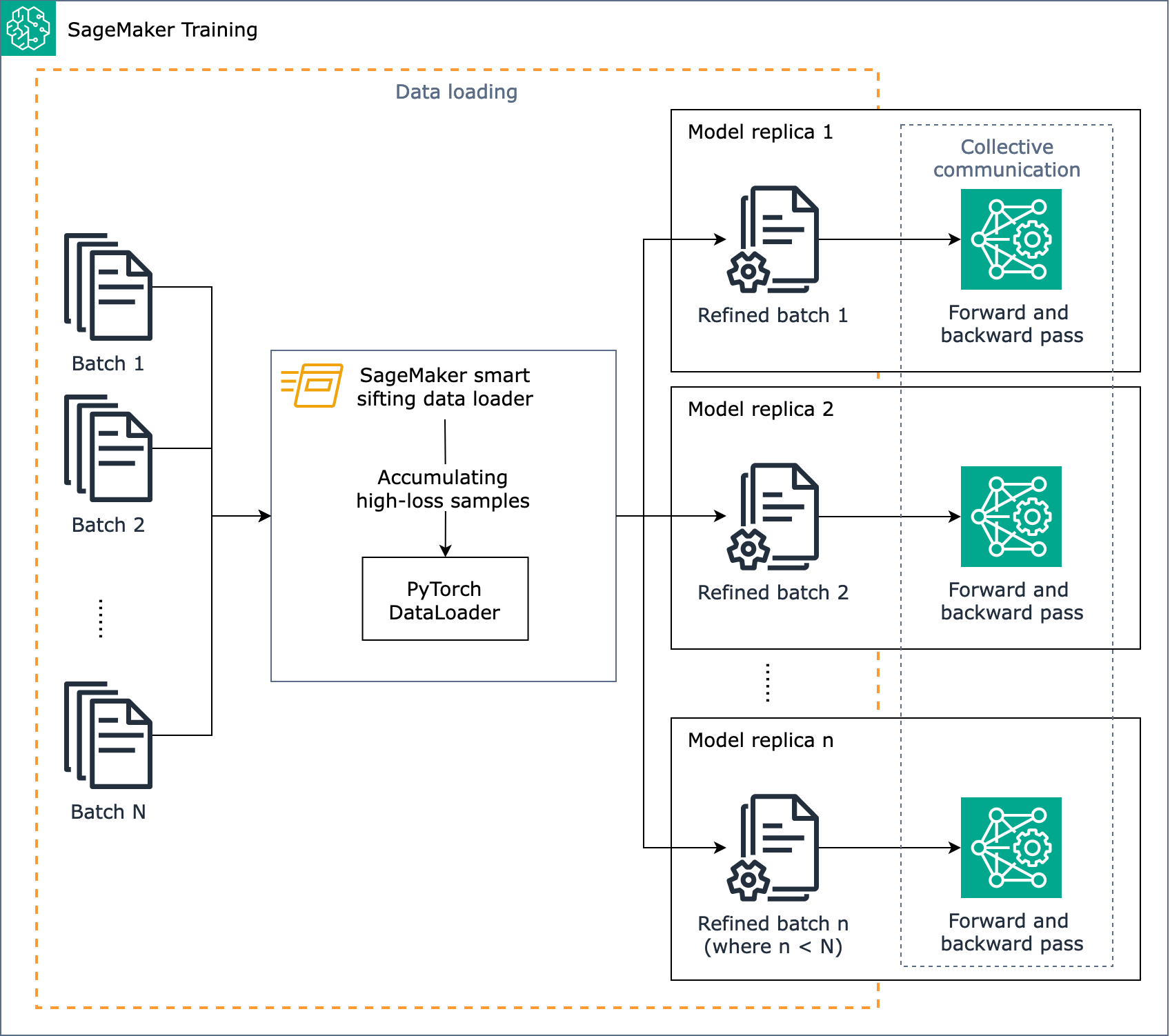
簡而言之, SageMaker 智慧篩分會在載入資料時於訓練期間運作。 SageMaker 智慧篩選演算法會在批次上執行損失計算,並在每次迭代的向前和向後傳遞之前將未改善的資料篩出。然後,系統會將精簡的資料批次用於向前和向後傳遞。
注意
上的資料智慧分割 SageMaker 會使用額外的轉送傳遞來分析和篩選訓練資料。反過來,遞迴次數較少,因為訓練任務中排除了影響較小的資料。因此,具有較長或昂貴反向通過的模型在使用智慧篩分時,可看到最大的效率增益。同時,如果您模型的向前傳遞需要比向後傳遞更長的時間,則額外負荷可能會增加總訓練時間。若要測量每次通過所花費的時間,您可以執行試行訓練任務,並收集記錄程序時間的日誌。也請考慮使用提供分析工具和 UI 應用程式的 SageMaker Profiler。如需進一步了解,請參閱 Amazon SageMaker Profiler。
SageMaker 智慧型篩選適用於具有傳統分散式資料平行處理的 PyTorch型訓練任務,這會為每個GPU工作者建立模型複本,並執行 AllReduce。它適用於 PyTorch DDP 和 SageMaker 分散式資料平行程式庫。
