本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立自訂語言模型
建立自訂語言模型前,您必須:
-
準備您的資料。資料必須以純文字格式儲存,且不能包含任何特殊字元。
-
將資料上傳至 Amazon S3 儲存貯體。建議為訓練和調整資料建立個別的資料夾。
-
請確定 Amazon Transcribe 可存取您的 Amazon S3 儲存貯體。您必須指定具有存取許可 IAM 的角色,才能使用您的資料。
準備您的資料
您可以將所有資料編譯在一個檔案中,也可以另存為多個檔案。請注意,如果您選擇包括調整資料,則必須將其儲存在與訓練資料不同的檔案中。
無論您進行培訓或調整資料所使用的文字檔案數量。上傳一個包含 100,000 個單字的檔案會產生與上傳 10 個檔案 (含 10,000 個單字) 相同的結果。以最方便的方式準備文字資料。
請確定您的所有資料檔案都符合以下條件:
-
它們都使用與您要建立的模型相同的語言。例如,如果您想要建立以美式英文 (
en-US) 轉錄音訊的自訂語言模型,則所有文字資料都必須使用美式英文。 -
它們採用 UTF-8 編碼的純文字格式。
-
它們不包含任何特殊字元或格式,例如 HTML 標記。
-
訓練資料的合併大小上限為 2 GB,調整資料的大小上限為 200 MB。
如果不符合這些條件,您的模型會失敗。
上傳資料
上傳資料前,請先為訓練資料建立新資料夾。如果使用調整資料,請建立獨立的資料夾
您的儲存貯體的 URI 可能如下所示:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
將您的訓練和調整資料上傳至適當的儲存貯體。
您可以稍後將更多資料新增至這些儲存貯體。但是,如果這樣做,則需要使用新資料重新建立模型。現有模型無法使用新資料更新。
允許存取您的資料
若要建立自訂語言模型,您必須指定具有存取儲存 Amazon S3 貯體許可 IAM 的角色。如果您還沒有可存取您放置訓練資料的儲存 Amazon S3 貯體的角色,則必須建立一個。建立角色後,您可以連接政策以授與該角色權限。請勿將政策連接至使用者
如需範例政策,請參閱 Amazon Transcribe 身分型政策範例。
若要了解如何建立新的 IAM 身分,請參閱IAM 身分 (使用者、使用者群組和角色)。
若要了解政策的詳細資訊,請參閱:
建立您的自訂語言模型
建立自訂語言模型時,您必須選擇基礎模型。有兩種基本模型選項:
-
NarrowBand:取樣率小於 16,000 Hz 的音訊,使用此選項。此模型類型通常用於以 8,000 Hz 記錄的電話對話。 -
WideBand:取樣率大於或等於 16,000 Hz 的音訊,使用此選項。
您可以使用 AWS Management Console AWS CLI、 AWS SDKs.;請參閱下列範例:
-
在導覽窗格中,選擇自訂語言模型。這會開啟 自訂語言模型 頁面,您可以在其中檢視現有的自訂語言模型或訓練新的自訂語言模型。
-
若要訓練新模型,選擇 訓練模型。

此會引導您前往 訓練模型 頁面。新增名稱、指定語言,然後選擇您要用於模型的基礎模型。然後,將路徑新增至訓練,並選擇性新增調整資料。您必須包含具有存取資料許可 IAM 的角色。
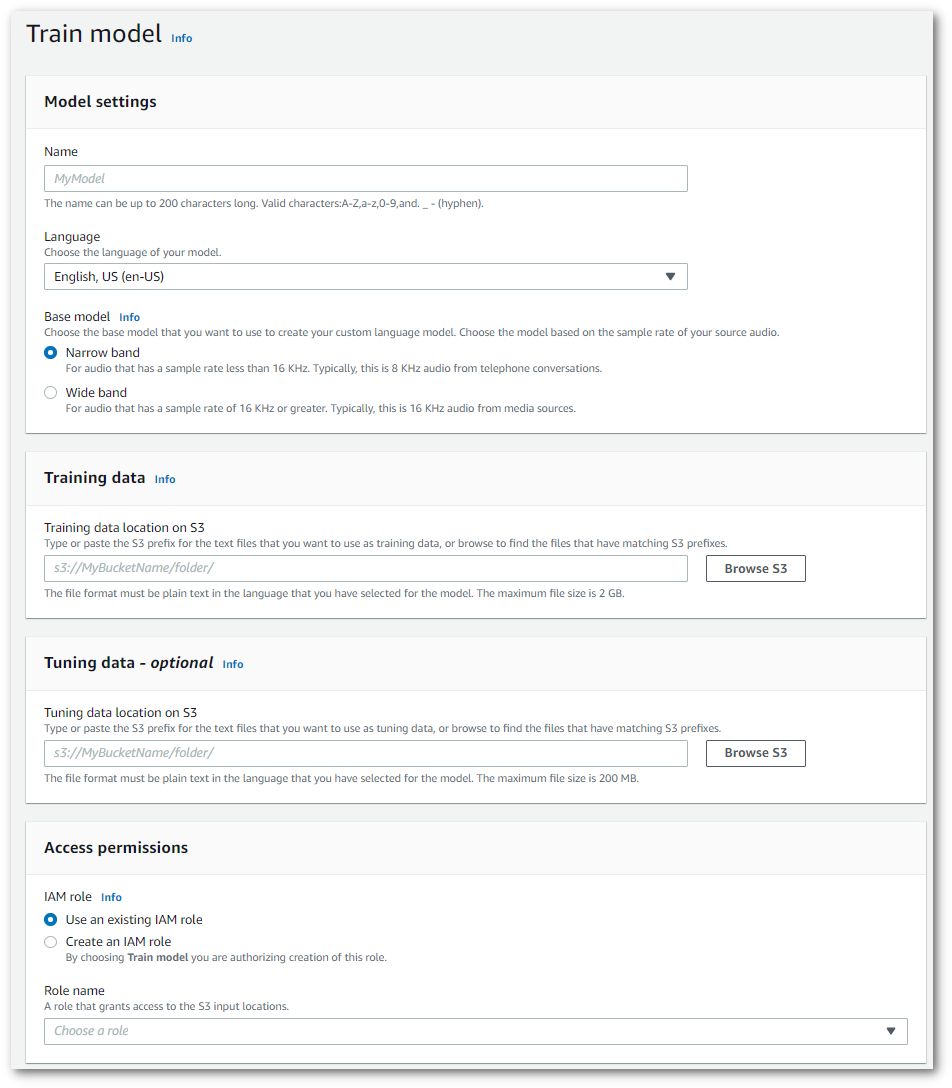
-
完成所有欄位後,選擇頁面底部的 訓練模型。
此範例使用 create-language-modelCreateLanguageModel 和 LanguageModel。
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
這是使用 create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
檔案 my-first-language-model.json 包含以下請求主文。
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
此範例使用 AWS SDK for Python (Boto3) 來使用 create_language_modelCreateLanguageModel 和 LanguageModel。
如需使用 AWS SDKs 的其他範例,包括功能特定、案例和跨服務範例,請參閱 使用 AWS SDKs Amazon Transcribe 程式碼範例章節。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
更新您的自訂語言模型
Amazon Transcribe 會持續更新可用於自訂語言模型的基本模型。為了從這些更新中受益,我們建議每 6 到 12 個月訓練新的自訂語言模型一次。
若要查看您的自訂語言模型是否使用最新的基礎模型,請使用 AWS CLI 或 AWS SDK 執行DescribeLanguageModel請求,然後在回應中尋找 UpgradeAvailability 欄位。
如果 UpgradeAvailability 是 true,則表示您的模型未執行最新版本的基礎模型。若要在自訂語言模型中使用最新的基礎模型,您必須建立新的自訂語言模型。自訂語言模型無法升級。
