本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用資料表建立自訂詞彙
使用表格格式是建立自訂詞彙的首選方式。詞彙表必須由四個欄 (Phrase, SoundsLike, IPA, and DisplayAs) 組成,可依任何順序包含:
| 片語 | SoundsLike | IPA | DisplayAs |
|---|---|---|---|
|
必要。表格中的每一列都必須包含此欄中的項目。 請勿在此欄中使用空格。 如果您輸入的內容包含多個單字,請以連字號 (-) 分隔每個單字。例如 對於縮寫詞,任何發音的字母都必須使用句點分隔。之後的句號也需要發音。如果您有複數個縮寫,您必須在縮寫和「s」間使用連字號。例如,「CLI」是 如果您的片語同時包含一個單字和一個縮寫,則這兩個元件必須用連字號分隔。例如,「DynamoDB」是 請勿在此欄中包含數字;必須拼出數字。例如,「VX02Q」是 |
|
|
選用。此欄中的列可以保留空白。 您可以在此欄中使用空格。 定義您的轉錄輸出中項目的外觀。例如, 如果此欄中的列是空的, Amazon Transcribe 會使用 您可以在此欄中包含數字 ( |
建立表格時要注意的事項:
-
您的表必須包含所有四個列標題(Phrase, SoundsLike, IPA, and DisplayAs)。
Phrase欄必須包含每一列上的項目。通過IPA和提供發音輸入的功能SoundsLike不再受支持,您可以將該列保留空白。這些欄中的任何值都將被忽略。 -
每一欄必須以 TAB 或逗號 (,) 分隔;這適用於自訂詞彙檔案中的每一列。如果列包含空白欄,您仍必須為每個欄納入分隔符號 (TAB 或逗號)。
-
只有
IPA和DisplayAs欄才允許使用空格。請勿使用空格以分隔欄。 -
IPA而SoundsLike且不再支援「自訂字彙」。請將欄留空。這些欄中的任何值都將被忽略。我們將在 future 移除對此專欄的支援。 -
DisplayAs欄支援符號和特殊字元 (例如 C++)。所有其他欄支援您語言的字元集頁面上列出的字元。 -
如果要在
Phrase欄中包含數字,則必須拼出數字。DisplayAs欄僅支援數字 (0-9)。 -
您必須將表格儲存為
LF格式的純文字 (*.txt) 檔案。如果您使用任何其他格式,例如CRLF,將無法處理您的自訂詞彙。 -
您必須將自訂字彙檔案上傳至 Amazon S3 值區並使用處理,
CreateVocabulary然後才能將其納入轉錄請求中。請參閱 建立自訂詞彙表,了解指示。
注意
縮寫或其他字組的字母如須單獨發音,請在單一字母後面輸入句號 (A.B.C.) 。若要輸入縮寫的複數形式,例如「ABCs」,請以連字號 (A.B.C.-s) 分隔縮寫中的「s」。您可以使用大寫或小寫字母以定義縮寫。並非所有語言都支援縮寫;請參閱 支援的語言和特定語言功能。
以下是樣本自訂詞彙表 (其中 [TAB] 代表一個 tab 字元):
Phrase[TAB]SoundsLike[TAB]IPA[TAB]DisplayAs
Los-Angeles[TAB][TAB][TAB]Los Angeles
Eva-Maria[TAB][TAB][TAB]
A.B.C.-s[TAB][TAB][TAB]ABCs
Amazon-dot-com[TAB][TAB][TAB]Amazon.com
C.L.I.[TAB][TAB][TAB]CLI
Andorra-la-Vella[TAB][TAB][TAB]Andorra la Vella
Dynamo-D.B.[TAB][TAB][TAB]DynamoDB
V.X.-zero-two[TAB][TAB][TAB]VX02
V.X.-zero-two-Q.[TAB][TAB][TAB]VX02Q為了釐清,此處是與欄對齊的相同表格。請勿在自訂詞彙表中的欄間加入空格;您的表格看似應該與前面的範例一樣未對齊。
Phrase [TAB]SoundsLike [TAB]IPA [TAB]DisplayAs
Los-Angeles [TAB] [TAB] [TAB]Los Angeles
Eva-Maria [TAB] [TAB] [TAB]
A.B.C.-s [TAB] [TAB] [TAB]ABCs
amazon-dot-com [TAB] [TAB] [TAB]amazon.com
C.L.I. [TAB] [TAB] [TAB]CLI
Andorra-la-Vella[TAB] [TAB] [TAB]Andorra la Vella
Dynamo-D.B. [TAB] [TAB] [TAB]DynamoDB
V.X.-zero-two [TAB] [TAB] [TAB]VX02
V.X.-zero-two-Q.[TAB] [TAB] [TAB]VX02Q建立自訂詞彙表
若要處理自訂字彙表以搭配使用 Amazon Transcribe,請參閱下列範例:
-
在導覽窗格中,選擇自訂詞彙。這會開啟自訂詞彙頁面,您可以在其中檢視現有的詞彙或建立新詞彙。
-
選擇建立詞彙。
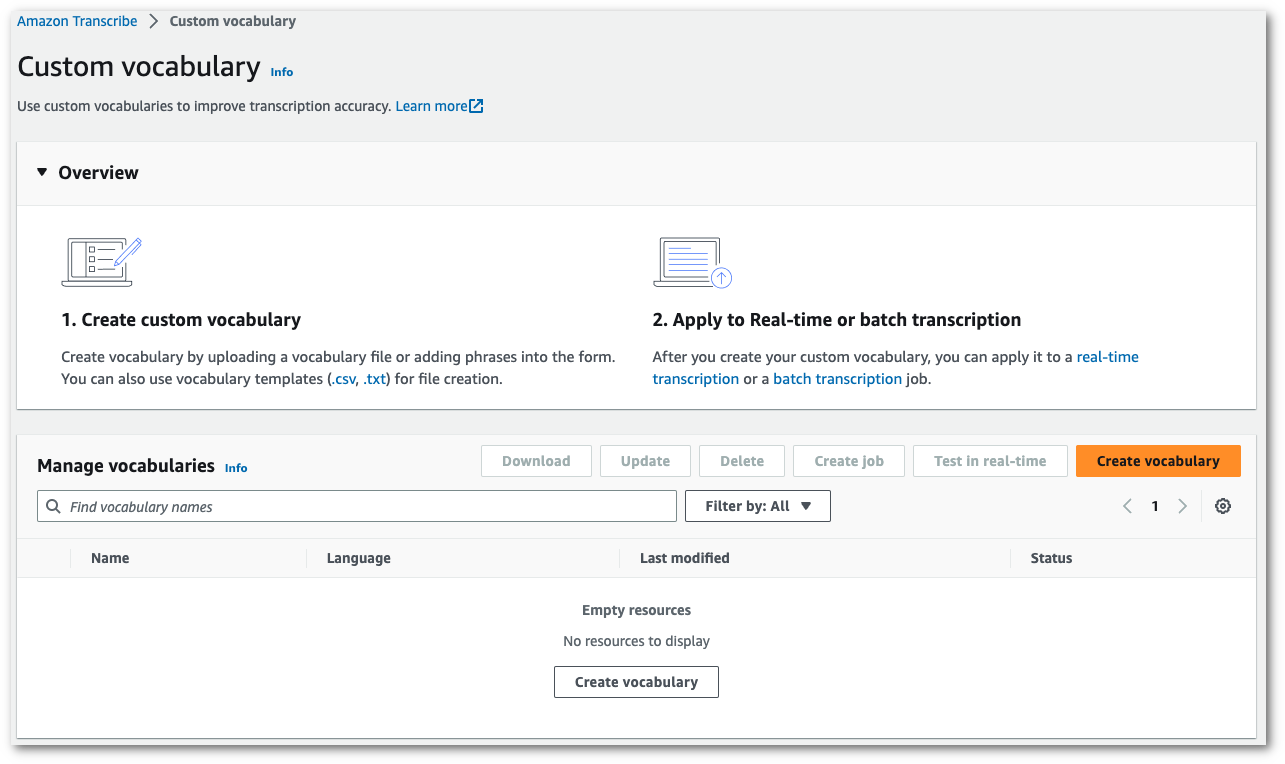
這會引導您前往建立詞彙頁面。輸入新自訂詞彙的名稱。
此處您有三種選擇:
-
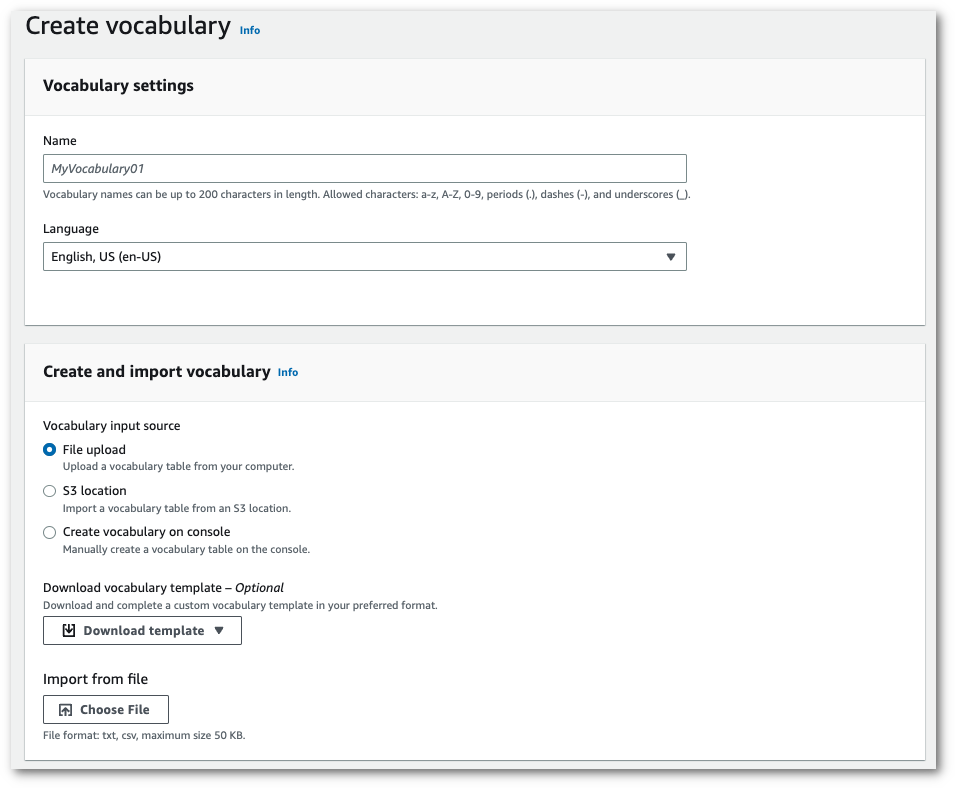
從您的電腦上傳 txt 或 csv 檔案。
您可以從頭開始建立自訂詞彙,也可以下載範本以幫助您開始使用。然後,您的詞彙會自動填入檢視和編輯詞彙窗格中。
-
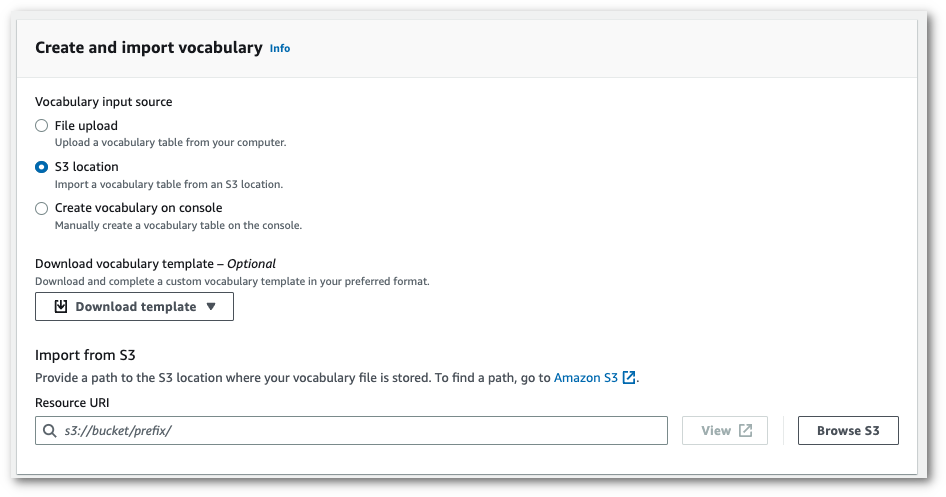
從一個 Amazon S3 位置導入一個 txt 或 csv 文件。
您可以從頭開始建立自訂詞彙,也可以下載範本以幫助您開始使用。將完成的詞彙檔案上傳至 Amazon S3 儲存貯體,並在請求中指定其 URI。然後,您的詞彙會自動填入檢視和編輯詞彙窗格中。
-
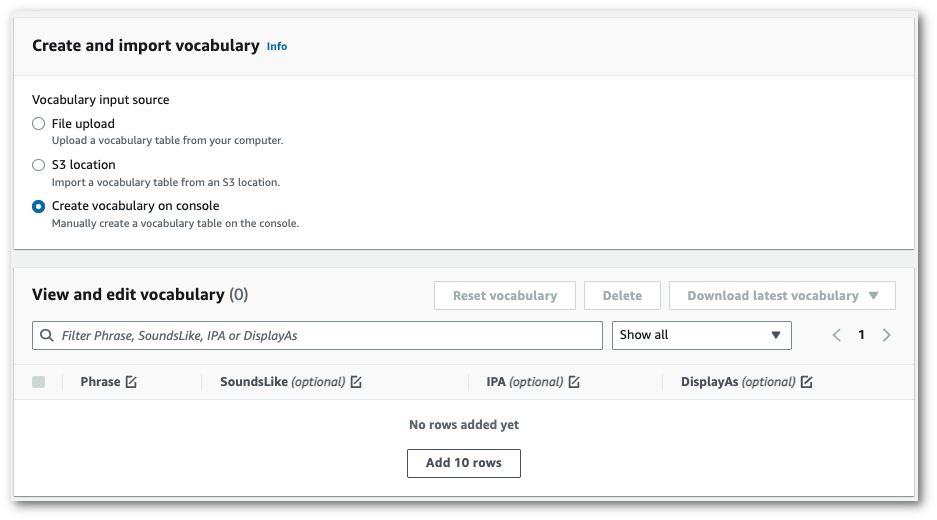
在主控台中手動建立詞彙。
捲動至檢視和編輯詞彙窗格,然後選擇新增 10 列。您現在可以手動輸入術語。
-
-
您可以在檢視和編輯詞彙窗格中編輯詞彙。按一下您想要修改的項目,進行變更。
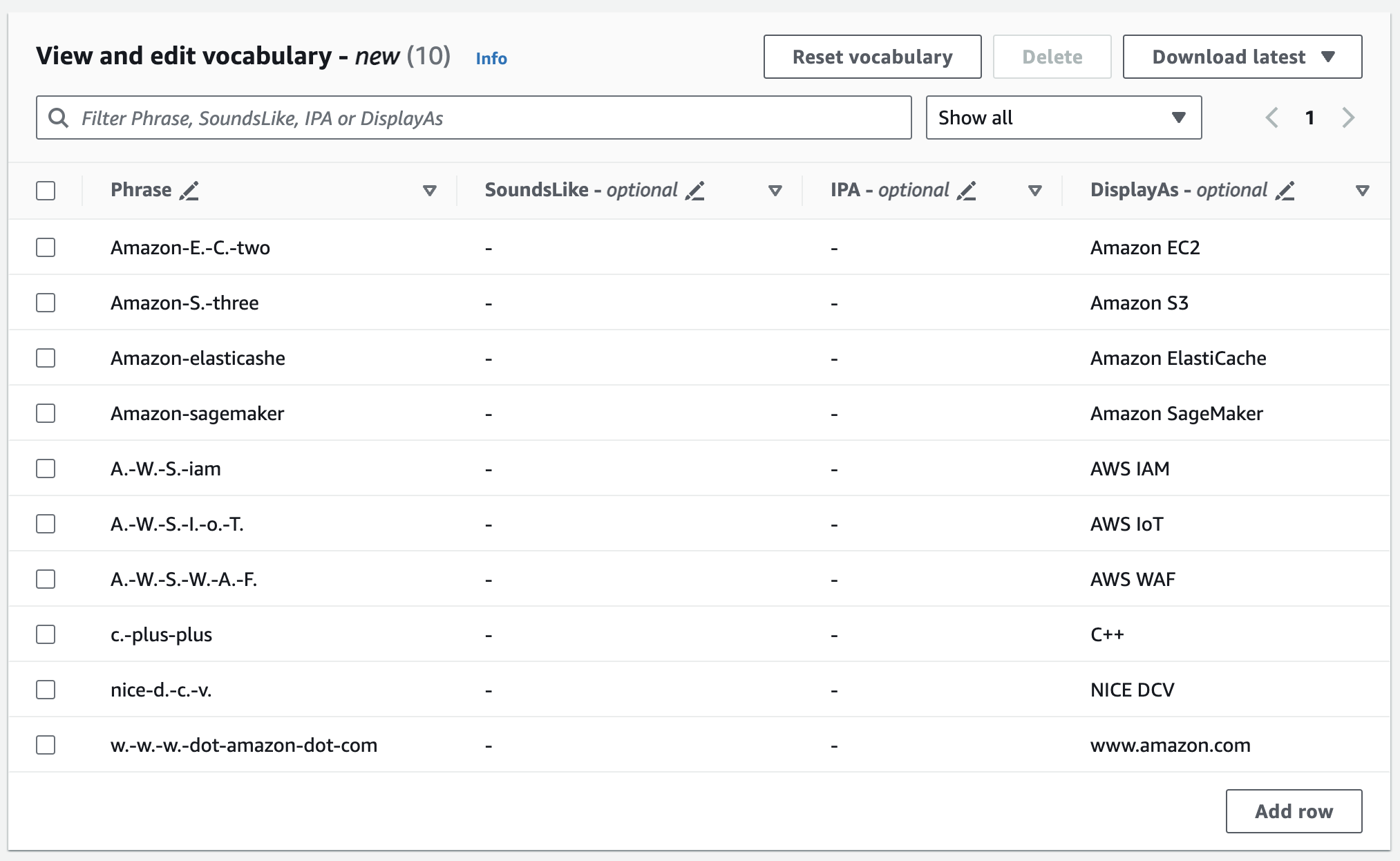
如果您執行時發生錯誤,您會收到詳細的錯誤訊息,以在處理詞彙前修正任何問題。請注意,如果您選擇建立詞彙前未更正所有錯誤,詞彙請求就會失敗。
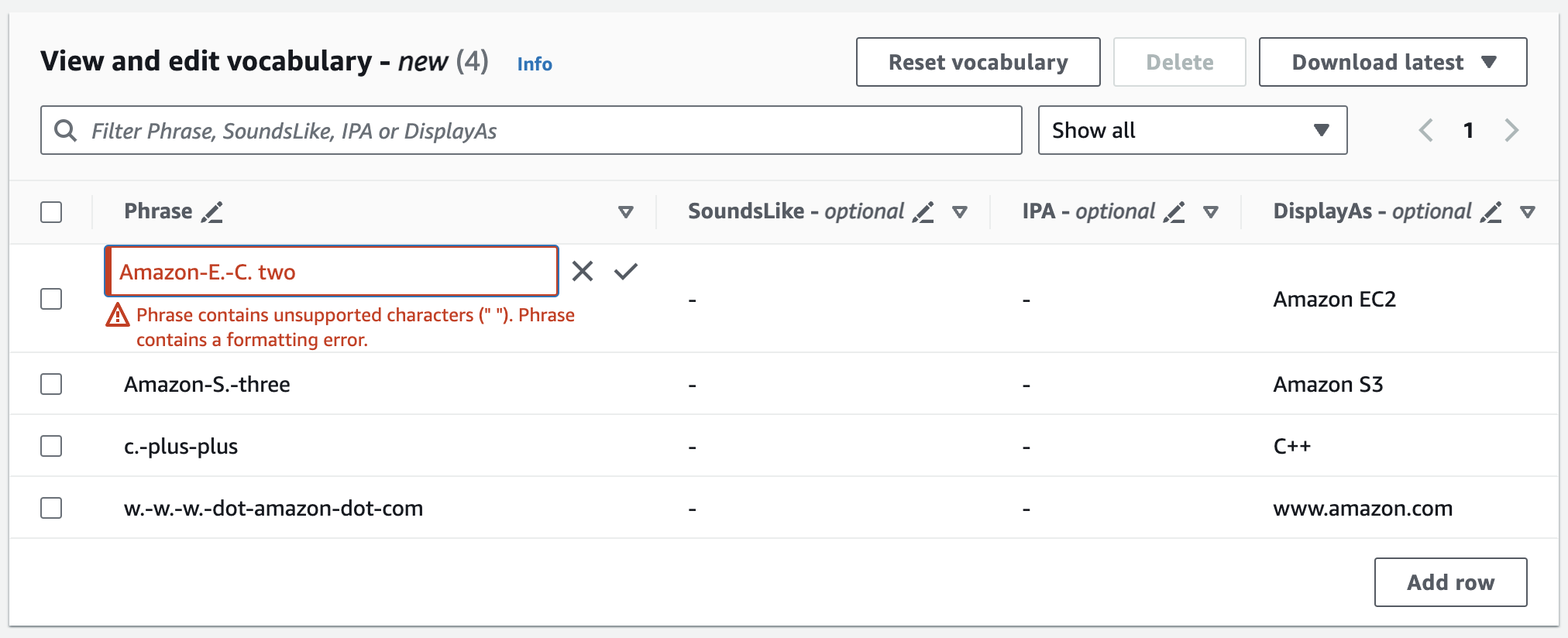
選擇核取記號 (✓) 以儲存變更,或選擇「X」以捨棄變更。
-
或者,將標籤新增至您的自訂詞彙。完成所有欄位並滿意您的詞彙後,選擇頁面底部的建立詞彙。這會引導您返回自訂詞彙頁面,您可以在此檢視自訂詞彙的狀態。狀態從「待處理」變更為「就緒」時,您的自訂詞彙可以與轉錄搭配使用。

-
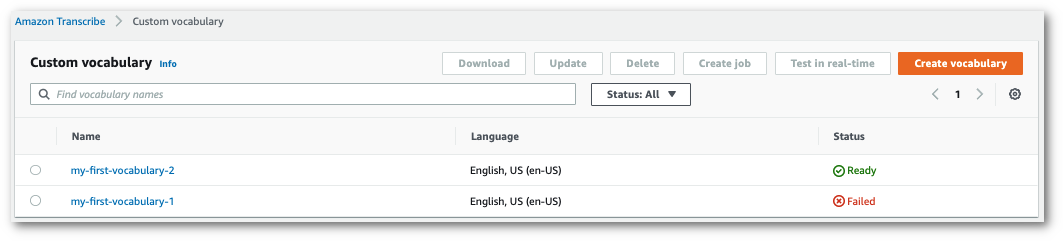
如果狀態變更為「失敗」,選擇自訂詞彙的名稱以前往其資訊頁面。
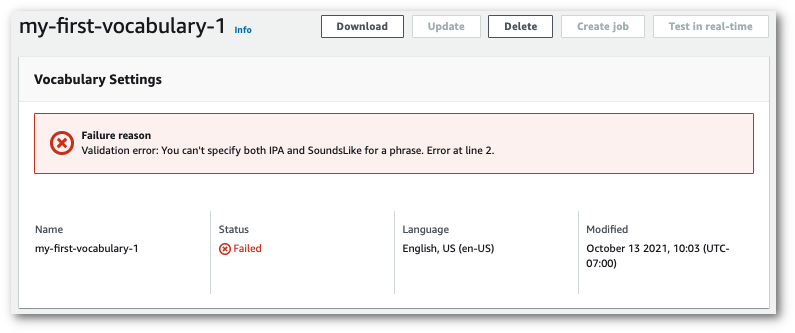
此頁面頂端有失敗原因橫幅,提供自訂詞彙失敗原因的相關資訊。請更正文字檔案中的錯誤,然後再試一次。
此範例使用 create-vocabulary 指令,搭配表格式的詞彙檔案。如需詳細資訊,請參閱 CreateVocabulary。
若要在轉錄工作中使用現有的自訂字彙,請VocabularyName在呼叫StartTranscriptionJob作業時在Settings欄位中設定,或從下 AWS Management Console拉式清單中選擇自訂字彙。
aws transcribe create-vocabulary \ --vocabulary-namemy-first-vocabulary\ --vocabulary-file-uri s3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-file.txt \ --language-codeen-US
這是使用 create-vocabulary 指令的另一個範例,以及建立自訂詞彙的請求內文。
aws transcribe create-vocabulary \ --cli-input-json file://filepath/my-first-vocab-table.json
該文件 my-first-vocab-table.json 包含以下請求主體。
{ "VocabularyName": "my-first-vocabulary", "VocabularyFileUri": "s3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-table.txt", "LanguageCode": "en-US" }
VocabularyState 從 PENDING 變更為READY 後,您的自訂詞彙即可與轉錄搭配使用。執行下列指令可檢視自訂詞彙的目前狀態:
aws transcribe get-vocabulary \ --vocabulary-namemy-first-vocabulary
此範例使用, AWS SDK for Python (Boto3) 使用 create_CreateVocabulary。
若要在轉錄工作中使用現有的自訂字彙,請VocabularyName在呼叫StartTranscriptionJob作業時在Settings欄位中設定,或從下 AWS Management Console拉式清單中選擇自訂字彙。
如需使用 AWS SDK 的其他範例,包括特定功能、案例和跨服務範例,請參閱本章。使用 的 Amazon Transcribe 程式碼範例 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary" response = transcribe.create_vocabulary( LanguageCode = 'en-US', VocabularyName = vocab_name, VocabularyFileUri = 's3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-table.txt' ) while True: status = transcribe.get_vocabulary(VocabularyName = vocab_name) if status['VocabularyState'] in ['READY', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
注意
如果您為自訂字彙檔案建立新 Amazon S3 值區,請確定提出CreateVocabulary請求的 IAM 角色具有存取此值區的權限。如果角色沒有正確的授權,您的請求將失敗。您可以選擇性地在請求中加入DataAccessRoleArn參數來指定 IAM 角色。如需中 IAM 角色和原則的詳細資訊 Amazon Transcribe,請參閱Amazon Transcribe 身分型政策範例。
