Release notes
Describes Amazon Athena features, improvements, and bug fixes by release date.
Athena release notes for 2026
July 06, 2026
Amazon Athena releases ODBC driver version 2.2.0.1. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the ODBC 2.x driver, see ODBC 2.x driver download.
July 1, 2026
Published on July 1, 2026
Amazon Athena fixed an issue where querying a table through a managed connector returned zero results when the table was shared from an Amazon SageMaker Unified Studio producer project to a consumer project within the same AWS account. Managed connectors now resolve shared table and schema references through the correct underlying data source.
June 03, 2026
Amazon Athena releases JDBC driver version 3.8.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
May 29, 2026
Amazon Athena releases ODBC driver version 2.2.0.0. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the ODBC 2.x driver, see ODBC 2.x driver download.
May 12, 2026
Published on 2026-05-12
Updates and security improvements
We've updated the third party library versions as following.
-
Updated
logback-corefrom 1.3.15 to 1.3.16 -
Updated
logback-classicfrom 1.3.15 to 1.3.16 -
Updated
jackson-annotationsfrom 2.16.0 to 2.21.2 -
Updated
jackson-corefrom 2.16.0 to 2.21.2 -
Updated
jackson-databindfrom 2.16.0 to 2.21.2 -
Replaced hardcoded
NTLMauthentication with theNegotiateprotocol in the ADFS SAML authentication flow, enabling Kerberos support with automaticNTLMv2fallback
For more information, and to download the JDBC 2.x driver, release notes, and documentation, see Athena JDBC 2.x driver.
April 21, 2026
Published on 2026-04-21
Amazon Athena now offers managed connectors for 12 data sources, including Amazon DynamoDB, PostgreSQL, MySQL, and Snowflake. Managed connectors are AWS Glue Data Catalog federated connectors that Athena creates and manages on your behalf, so you can query data outside Amazon S3 without deploying or maintaining connector resources in your AWS account. These connectors are registered as federated catalogs in AWS Glue Data Catalog, and you can optionally set up fine-grained access controls through AWS Lake Formation. For more information, see Use Amazon Athena Federated Query.
March 27, 2026
Published on 2026-03-27
Amazon Athena now supports Capacity Reservations in the following commercial AWS Regions: US West (N. California), Africa (Cape Town), Asia Pacific (Hong Kong), Asia Pacific (Hyderabad), Asia Pacific (Jakarta), Asia Pacific (Malaysia), Asia Pacific (Melbourne), Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Thailand), Asia Pacific (Taipei), Canada (Central), Canada West (Calgary), Europe (Frankfurt), Europe (London), Europe (Milan), Europe (Paris), Europe (Zurich), and Mexico (Central).
To learn more, see Manage query processing capacity and
Amazon Athena pricing
March 20, 2026
Published on 2026-03-20
Athena releases ODBC driver version 2.1.0.0. This release includes security improvements to authentication flows, query processing, and transport security. We recommend upgrading to this version as soon as possible. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the ODBC 2.x driver, see ODBC 2.x driver download.
March 17, 2026
Published on 2026-03-17
Athena now supports AWS IAM-based authorization for Amazon S3 Tables and Apache Iceberg materialized views. With IAM-based authorization, you can define all necessary permissions across storage, catalog, and query engines in a single IAM policy.
February 10, 2026
Published on 2026-02-10
Athena announces the following features and improvements.
Amazon Athena now supports 1-minute Capacity Reservations and 4 Data Processing Unit (DPU) minimum capacity. Capacity Reservations provide dedicated serverless compute for interactive SQL workloads requiring query prioritization and concurrency controls. With this release, you can now get started with less capacity and adjust capacity more frequently to closely match variable workload patterns. Learn more in the Athena User Guide.
January 12, 2026
Published on 2026-01-12
Amazon Athena announces the availability of Athena SQL in the Asia Pacific (New Zealand) Region.
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
Athena release notes for 2025
November 30, 2025
Published on 2025-11-30
Athena announces the following features and improvements.
Amazon Athena now supports AWS Glue Data Catalog materialized views, a new type of pre-computed query result table that automatically updates as your data changes. Glue Data Catalog materialized views are stored as Apache Iceberg tables and can be queried with Athena SQL SELECT statements and Apache Spark version 3.5. To learn more, see Query AWS Glue Data Catalog materialized views and Using materialized views.
November 21, 2025
Published on 2025-11-21
Athena announces the following features and improvements.
-
Amazon Athena for Apache Spark is now available in notebooks – Provides data engineers, analysts, and data scientists with a unified workspace to query data, develop jobs, train models, and work with AI. Athena for Apache Spark runs on Spark 3.5.6 and has new debugging features, real-time monitoring through Spark UI, Spark Connect for secure cluster interaction, and AWS Lake Formation table-level access controls. Learn more at the SageMaker user guide.
-
Capacity Reservations cost and performance controls – You can now set Data Processing Unit (DPU) usage limits at the workgroup or query level and get DPU usage details for queries that you run on Capacity Reservations. These controls help you fine-tune query performance and manage costs by controlling resource usage for your most important SQL workloads. To learn more, see Control capacity usage.
-
Capacity Reservations auto-scaling solution – You can now automatically adjust Capacity Reservations based on utilization. Athena's solution uses CloudFormation and Step Functions to remove the need for manual capacity adjustments, helping you balance performance requirements with cost optimization, and is customizable for different needs. To learn more, see Automatically adjust capacity.
-
Optimization with Iceberg statistics – Athena has enhanced how it uses Iceberg statistics to make intelligent decisions about join ordering, filters, and aggregation behavior that can improve query performance and reduce costs. To learn more, see Use Iceberg table statistics.
-
Iceberg Parquet column indexing – Athena now supports Parquet column indexing on Iceberg tables for precise data pruning during query execution. It leverages page-level min/max statistics to reduce the amount of data scanned, improving query performance and lowering costs, particularly for queries with selective filter predicates on sorted columns. To learn more, see Use Parquet column indexing.
-
Iceberg performance enhancements with Lake Formation – Athena has added new partition pruning behaviors for Iceberg tables that have Lake Formation row filters and column masks, and additional predicate pushdown behaviors for all other table types that have Lake Formation row filters and column masks. This update enhances query performance while maintaining security protections.
-
Query result reuse – Athena has improved query result reuse to enable more queries to benefit from cached results. Athena now treats semantically equivalent queries as identical regardless of formatting differences. Customers who use query result reuse will automatically benefit from increased cache hit rates, resulting in faster query execution and reduced costs, with no action needed. To learn more, see Reuse query results in Athena.
-
Upgraded data lake file SerDes – Athena has upgraded its SerDes for Parquet, JSON, CSV, and text files. This improves query performance and reliability while correcting for scenarios where previous SerDes returned non-deterministic or incorrect results. Customers will automatically benefit from these improvements without any action needed as they are upgraded based on compatibility checks performed by Athena.
-
Hudi 0.15.0 upgrade – You can now use Athena to query Hudi 0.15.0 tables. For more information, see Query Apache Hudi datasets.
-
Browser trusted identity propagation integration – Athena added a new authentication plugin to support JWT trusted identity propagation integration with JDBC and ODBC drivers. This authentication type allows you to fetch a JSON web token (JWT) from an external identity provider and authenticates with Athena. For more information, see Use Trusted identity propagation with Amazon Athena drivers.
-
JDBC 3.7.0 driver – Athena releases JDBC driver version 3.7.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
-
ODBC 2.0.6.0 driver – Athena releases ODBC driver version 2.0.6.0. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the latest JDBC driver, see ODBC 2.x driver download.
October 13, 2025
Published on 2025-10-13
Athena releases ODBC driver version 2.0.5.1. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the ODBC 2.x driver, see ODBC 2.x driver download.
September 19, 2025
Published on 2025-09-19
Amazon Athena adds key-pair and OAuth authentication methods for Amazon Athena Snowflake connector. These authentication methods replace the username and password authentication method that Snowflake plans to disable by November 2025. For information about how to configure the new authentication methods, see Authenticate with Snowflake.
September 10, 2025
Published on 2025-09-10
Athena announces the following features and improvements.
JWT trusted identity propagation integration
Athena added a new authentication plugin to support JWT trusted identity propagation integration with JDBC and ODBC drivers. This authentication type allows you to use a JSON web token (JWT) obtained from an external identity provider as a connection parameter to authenticate with Athena. For more information , see Use Trusted identity propagation with Amazon Athena drivers.
ODBC 2.0.5.0 driver
Athena releases ODBC driver version 2.0.5.0. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the latest JDBC driver, see ODBC 2.x driver download.
JDBC 3.6.0 driver
Athena releases JDBC driver version 3.6.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
September 05, 2025
Published on 2025-09-05
Athena announces the following features and improvements.
JDBC 2.2.2 driver
JDBC 2.2.2 driver release for Athena.
Updates and bug fixes
We've updated the third party library versions as following.
-
Updated
commons-codecfrom 1.15 to 1.18.0 -
Updated
commons-csvfrom 1.8 to 1.14.0 -
Updated
commons-loggingfrom 1.2 to 1.3.5 -
Updated the Log4j component to 2.24.3.
Bug fixes
-
Fixed an error that occurred in connector when a null value is passed to the
loginToRpparameter during ADFS authentication.
For more information, and to download the JDBC 2.x driver, release notes, and documentation, see Athena JDBC 2.x driver.
August 15, 2025
Published on 2025-08-15
Athena announces the following features and improvements.
CREATE TABLE AS SELECT (CTAS) queries for S3 Tables – Athena now supports CREATE TABLE AS SELECT (CTAS) queries for S3 Tables. For more information, see Create S3 Tables in Athena.
Removal of legacy Iceberg table statistics support – We've removed support for tracking legacy Iceberg table statistics in Athena. If you have tables that were written before May 7, 2023, you must re-analyze them.
August 11, 2025
Published on 2025-08-11
Athena announces the following fixes and improvements:
-
We've changed the behavior of
lead()andlag()with respect to handling ofNULLoffsets. Prior to this change, passing inNULLoffset tolead()andlag()would produceNULLas output. Now, Athena returns the error Offset must not be null.This is done to make the behavior compliant with SQL standards and to prevent unexpected
NULLin the output by proactively preventing them in the input. With this, you are advised to not passNULLas offset tolead()andlag(). While it's not recommended, you can preserve the old behavior by rewriting as shown in the following example:Original query pattern
lead(column1, column_containing_nulls) OVER (...) as transformedUpdated query pattern
CASE WHEN column_containing_nulls IS NULL THEN NULL ELSE (lead(column1, coalesce(column_containing_nulls, 1)) OVER (...)) END as transformed
July 17, 2025
Published on 2025-07-17
Athena releases JDBC driver version 3.5.1. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
June 30, 2025
Published on 2025-06-30
Amazon Athena announces the availability of Athena SQL in the Asia Pacific (Taipei) Region.
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
June 17, 2025
Published on 2024-06-17
Athena releases ODBC driver version 2.0.4.0. For more information about this version of the driver, see Amazon Athena ODBC 2.x release notes. To download the ODBC 2.x driver, see ODBC 2.x driver download.
June 03, 2025
Published on 2025-06-03
Athena introduces managed query results, a new feature that automatically stores,
secures, and manages query result data for you at no cost. Managed query results helps
you get started in fewer steps by removing the need for Amazon S3 buckets to store query
results and clean up processes to delete query results you no longer need. Managed query
results is generally available in all regions where Athena is available
When you use managed query results, you can continue to access query results through the same interfaces as with traditional S3 bucket storage. To get started, use the AWS Management Console, AWS SDK, or AWS CLI to configure your new or existing workgroups to use managed query results. For more information, see Managed query results.
May 27, 2025
Published on 2025-05-27
Athena announces the following fixes and improvements:
Enhanced Error Messaging for Delta Lake Metadata Tables – We've improved error messaging for Delta Lake metadata tables, now providing clearer feedback when you attempt to query these unsupported tables.
May 14, 2025
Published on 2025-05-14
Athena announces the following fixes and improvements:
We've resolved an issue that could cause ORC files to be created with larger than intended file sizes.
-
Improved performance of scans on Delta Lake tables that use v2 checkpoints.
April 18, 2025
Published on 2025-04-18
Athena announces the following fixes and improvements:
Capacity Reservation tracking – We have resolved an issue in our capacity reservation tracking system where reservations were not being properly released during query cancellation scenarios, specifically after query was planned and before workers are acquired by Athena for query execution. The fix allows Athena query engine to explicitly release capacity reservation when the above scenario is encountered.
April 16, 2025
Published on 2025-04-16
Amazon Athena announces the availability of Athena SQL in the Asia Pacific (Thailand) and Mexico (Central) Regions.
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
April 09, 2025
Published on 2025-04-09
Athena announces the following features and improvements.
JDBC 2.2.1 driver
JDBC 2.2.1 driver release for Athena.
Updates and enhancements:
-
Updated Logback libraries to use version 1.3.15.
For more information, and to download the JDBC 2.x driver, release notes, and documentation, see Athena JDBC 2.x driver.
March 18, 2025
Published on 2025-03-18
Athena releases JDBC driver version 3.5.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
March 14, 2025
Published on March 14, 2025
Amazon Athena releases capabilities to create and query table operations directly from the S3 console.
For more information, see Register S3 table bucket catalogs and query Tables from Athena.
March 07, 2025
Published on March 07, 2025
Provisioned capacity is now generally available in the Asia Pacific (Mumbai) Region. Provisioned capacity allows you to run SQL queries on fully-managed compute capacity and provides workload management capabilities that help you prioritize, control, and scale your most important interactive workloads. You can add capacity at any time to increase the number of queries that you run concurrently, control which workloads use the capacity, and share capacity among workloads.
For more information, see Manage query processing capacity. For pricing information, visit the Amazon Athena pricing
February 18, 2025
Published on 2025-02-18
Athena releases JDBC driver version 3.4.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the latest JDBC driver, see JDBC 3.x driver download.
January 22, 2025
Published on 2025-01-22
Athena now supports federated queries through Lambda and encryption of query results using KMS on TIP enabled workgroups. For more information, see Use IAM Identity Center enabled Athena workgroups.
Athena release notes for 2024
December 17, 2024
Published on 2024-12-17
Amazon Athena announces the availability of Athena SQL in the Asia Pacific (Malaysia).
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
December 16, 2024
Published on 2024-12-16
Deletion vectors fix – Fixed an issue with deletion vectors where partitioned tables returned incorrect results in the Delta Lake connector.
December 3, 2024
Published on 2024-12-03
Athena announces the following features and improvements.
-
Data source connections– Amazon Athena announces a streamlined console and API workflow for creating data source connections. You can now create and manage Athena data connections entirely within the Athena console, and the properties for your connections are now centrally stored in the AWS Glue Data Catalog.
Storing connection properties in AWS Glue lets you reuse the connections across other AWS services. For example, after you configure an Athena connector to Amazon DynamoDB, you can reuse the properties and permissions that you specified for the connection for an AWS Glue ETL job that accesses your data in DynamoDB. For more information, see Use the Athena console to connect to a data source in the Amazon Athena User Guide and CreateDataCatalog in the Amazon Athena API Reference.
-
Querying Redshift data registered in AWS Glue Data Catalog – Athena now supports reading and writing to Redshift tables that are registered in Glue Data Catalog. For more information, see Register Redshift data catalogs in Athena.
-
Querying S3 tables from Athena S3 Table Buckets are a bucket type in Amazon S3 that is purpose-built to store tabular data in Apache Iceberg tables. Athena now supports DQL and DML queries on S3 tables. For more information, see Register S3 table bucket catalogs and query Tables from Athena.
October 30, 2024
Published on 2024-10-30
Athena releases JDBC driver version 3.3.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the JDBC 3.x driver, see JDBC 3.x driver download.
August 23, 2024
Published on 2024-09-05
Athena announces the following:
-
Querying federated views with passthrough queries – Federated passthrough queries are now supported for views. For more information, see Query federated views.
-
Multiple passthrough queries – You can now run more than one federated passthrough query in the same query execution. For more information, see Use federated passthrough queries.
-
Iceberg table OPTIMIZE fix – Fixed an issue where running
OPTIMIZEon an Iceberg table would not remove "delete" files when re-writing data files that had an associated delete file. For more information, see OPTIMIZE. -
Parquet LZ4 and LZO write support – Athena no longer supports writing Parquet files compressed with LZ4 or LZO formats. Reads for these compression formats are still supported. For information about compression formats in Athena, see Use compression in Athena.
July 29, 2024
Published on 2024-07-29
Athena releases JDBC driver version 3.2.2. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the JDBC 3.x driver, see JDBC 3.x driver download.
July 26, 2024
Published on 2024-08-01
Athena announces the following improvement.
-
Delta Lake table deletion vector support – Athena now supports reading from Delta Lake tables with deletion vectors
. For more information, see Query Linux Foundation Delta Lake tables.
July 3, 2024
Published on 2024-07-03
Athena releases JDBC driver version 3.2.1. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the JDBC 3.x driver, see JDBC 3.x driver download.
June 26, 2024
Published on 2024-06-26
Provisioned capacity is now generally available in the South America (São Paulo) and Europe (Spain) Regions. Provisioned capacity allows you to run SQL queries on fully-managed compute capacity and provides workload management capabilities that help you prioritize, control, and scale your most important interactive workloads. You can add capacity at any time to increase the number of queries that you run concurrently, control which workloads use the capacity, and share capacity among workloads.
For more information, see Manage query processing capacity. For pricing information, visit the Amazon Athena pricing
May 10, 2024
Published on 2024-07-15
Athena announces the following features and improvements.
-
Delta Lake – Athena added optimizations that filter out unneeded entries from checkpoint files. These optimizations enable significantly improved performance for queries with large checkpoint files that reference many Parquet data files.
For information about using Linux Foundation Delta Lake tables with Athena, see Query Linux Foundation Delta Lake tables.
April 26, 2024
Published on 2024-04-26
Athena releases JDBC driver version 3.2.0. For more information about this version of the driver, see Amazon Athena JDBC 3.x release notes. To download the JDBC 3.x driver, see JDBC 3.x driver download.
April 24, 2024
Published on 2024-04-24
Athena announces the following fixes and improvements.
-
Parquet – Athena now supports backwards compatible reads in Parquet for unannotated, repeated primitive fields that are not contained within a list or map group. This change prevents silently incorrect results from being returned and improves error messaging for schema mismatches.
For more information, see Support backwards compatible reads for unannotated repeated primitive fields in Parquet
on GitHub.com. -
Iceberg OPTIMIZE – Resolved an issue with
OPTIMIZEqueries that caused data to be lost when a non-partition key filter was used in aWHEREclause. For more information, see OPTIMIZE.
April 16, 2024
Published on 2024-04-16
Use the new Amazon Athena federated query passthrough feature to run entire queries
directly on the underlying data source. Federated passthrough queries help you take
advantage of the unique functions, query language, and performance capabilities of the
original data source. For example, you can run Athena queries on DynamoDB using the PartiQL
language. Federated passthrough queries are also useful when you want to run
SELECT queries that aggregate, join, or invoke functions of your data
source that are not available in Athena. Using passthrough queries can reduce the amount
of data processed by Athena and result in faster query times.
For more information, see Use federated passthrough queries. To upgrade the connectors that you use today to the latest version, see Update a data source connector.
April 10, 2024
Published on 2024-04-10
Athena announces the following features and improvements.
ODBC 1.2.3.1000 driver
ODBC 1.2.3.1000 driver release for Athena.
Resolved issues:
-
Proxy server connection issue – When a proxy server was used without the root certificate, the connector failed to establish a connection.
For more information, and to download the ODBC 1.x driver, release notes, and documentation, see Athena ODBC 1.x driver.
JDBC 2.1.5 driver
JBDC 2.1.5 driver release for Athena.
Updates and enhancements:
-
Updated the AWS Java SDK to use version 1.12.687.
-
Updated Jackson libraries to use version 2.16.0.
-
Updated Logback libraries to use version 1.3.14.
For more information, and to download the JDBC 2.x driver, release notes, and documentation, see Athena JDBC 2.x driver.
April 8, 2024
Published on 2024-04-08
Athena announces ODBC driver version 2.0.3.0. For more information, see the 2.0.3.0 release notes. To download the new ODBC v2 driver, see ODBC 2.x driver download. For connection information, see the Amazon Athena ODBC 2.x.
March 15, 2024
Published on 2024-03-18
Amazon Athena announces the availability of Athena SQL in the Canada West (Calgary) Region.
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
February 15, 2024
Published on 2024-02-15
Athena releases JDBC driver version 3.1.0.
Amazon Athena JDBC driver version 3.1.0 adds support for Microsoft Active Directory Federation Services (AD FS) Windows Integrated Authentication and form-based authentication. The 3.1.0 release also includes other minor improvements and bug fixes.
To download the JDBC v3 driver, see JDBC 3.x driver download.
January 31, 2024
Published on 2024-01-31
Athena announces the following features and improvements.
-
Hudi upgrade – You can now use Athena SQL to query Hudi 0.14.0 tables. For information about using Athena SQL to query Hudi tables, see Query Apache Hudi datasets.
Athena release notes for 2023
December 14, 2023
Published on 2023-12-14
Athena announces the following fixes and improvements.
Athena releases JDBC driver version 2.1.3. The driver resolves the following issues:
-
Logging has been improved to avoid conflicts with Spring Boot and Gradle application logging.
-
When using the
executeBatch()JDBC method to insert records, the driver incorrectly inserted only one record. Because Athena does not support batch execution of queries, the driver now reports an error when you useexecuteBatch(). To work around the limitation, you can submit single queries in a loop.
To download the new JDBC driver, release notes, and documentation, see Athena JDBC 2.x driver.
December 9, 2023
Published on 2023-12-09
Released the ODBC 1.2.1.1000 driver for Athena.
Features and enhancements:
-
Updated RStudio support – The ODBC driver now supports RStudio on macOS.
-
Single catalog and schema support – The connector can now return a single catalog and schema. For more information, see the downloadable installation and configuration guide.
Resolved issues:
-
Prepared statements – When prepared statements with an array of parameters using column-wise schema were run, the connector returned an incorrect query result.
-
Column size – When the
$file_modified_timesystem column was selected, the connector returned an incorrect column size. -
SQLPrepare – When binding parameters related to
SQLPrepareinSELECTqueries, the connector returned an error.
For more information, and to download the new drivers, release notes, and documentation, see Athena ODBC 1.x driver.
December 7, 2023
Published on 2023-12-07
Athena announces ODBC driver version 2.0.2.1. For more information, see the 2.0.2.1 release notes. To download the new ODBC v2 driver, see ODBC 2.x driver download. For connection information, see the Amazon Athena ODBC 2.x.
December 5, 2023
Published on 2023-12-05
You can now create Athena SQL workgroups that use AWS IAM Identity Center authentication mode. These workgroups support the Trusted identity propagation feature of IAM Identity Center. Trusted identity propagation permits identities to be used across AWS analytics services like Amazon Athena and Amazon EMR Studio.
For more information, see Use IAM Identity Center enabled Athena workgroups.
November 28, 2023
Published on 2023-11-28
You can now query data in the Amazon S3 Express One Zone storage class
For more information, see Query S3 Express One Zone data.
November 27, 2023
Published on 2023-11-27
Athena announces the following features and improvements.
-
Glue Data Catalog views – Glue Data Catalog views provide a single common view across AWS services like Amazon Athena and Amazon Redshift. In Glue Data Catalog views, access permissions are defined by the user who created the view instead of the user who queries the view. These views provide greater access control, help to ensure complete records, offer enhanced security, and can prevent access to underlying tables.
For more information, see Use Data Catalog views in Athena.
-
CloudTrail Lake support – You can now use Amazon Athena to analyze data in AWS CloudTrail Lake. AWS CloudTrail Lake is a managed data lake for CloudTrail that you can use to aggregate, immutably store, and analyze activity logs for audit, security, and operational investigations. To query your CloudTrail Lake activity logs from Athena, you do not have to move data or build separate data processing pipelines. No ETL operations are required.
To get started, enable data federation in CloudTrail Lake. When you share your CloudTrail Lake event data store metadata with AWS Glue Data Catalog, CloudTrail creates the necessary AWS Glue Data Catalog resources and registers the data with AWS Lake Formation. In Lake Formation, you can specify the users and roles that can use Athena to query your event data store.
For more information, see Enable Lake query federation in the AWS CloudTrail User Guide.
November 17, 2023
Published on 2023-11-17
Athena announces the following features and improvements.
Features
-
Cost-based optimizer – Athena announces general availability of cost-based optimization using statistics from AWS Glue. To optimize your queries in Athena SQL, you can request that Athena gather table or column-level statistics for your tables in AWS Glue. If all of the tables in your query have statistics, Athena uses the statistics to examine alternate execution plans and select the one that is most likely to be the fastest.
For more information, see Use the cost-based optimizer.
-
Amazon EMR Studio integration – You can now use Athena in an Amazon EMR Studio without having to use the Athena console directly. With the Athena integration in Amazon EMR, you can perform the following tasks:
-
Perform Athena SQL queries
-
View query results
-
View query history
-
View saved queries
-
Perform parameterized queries
-
View databases, tables, and views for a data catalog
For more information, see Amazon EMR Studio in the AWS service integrations with Athena topic.
-
-
Nested access control – Athena announces support for Lake Formation access control for nested data. In Lake Formation, you can define and apply data filters on nested columns that have
structdata types. You can use data filtering to restrict user access to sub-structures of nested columns. For information on how to create data filters for nested data, see Creating a data filter in the AWS Lake Formation Developer Guide. -
Provisioned capacity usage metrics – Athena announces new CloudWatch metrics for capacity reservations. You can use the new metrics to keep track of the number of DPUs you have provisioned and the number of DPUs being used by your queries. When queries finish, you can also view the number of DPUs the query consumed.
For more information, see Monitor Athena query metrics with CloudWatch.
Improvements
-
Error message change – The
Insufficient Lake Formation permissionserror message now readsTable not foundorSchema not found. This change was made to prevent malicious actors from inferring the existence of table or database resources from the error message.
November 16, 2023
Published on 2023-11-16
Athena releases a new JDBC driver that improves the experience of connecting to, querying, and visualizing data from compatible SQL development and business intelligence applications. The new driver is straightforward to upgrade. The driver can read query results directly from Amazon S3, making query results available to you sooner.
For more information, see Athena JDBC 3.x driver.
October 31, 2023
Published on 2023-10-31
Amazon Athena announces 1-hour reservations for provisioned capacity. Starting today, you can reserve and release provisioned capacity after one hour. This change makes it simpler to optimize cost for workloads whose demand changes over time.
Provisioned capacity is a feature of Athena that provides workload management capabilities that help you prioritize, control, and scale your most important interactive workloads. You can add capacity at any time to increase the number of queries that you run concurrently, control which workloads use the capacity, and share capacity among workloads.
For more information, see Manage query processing capacity. For pricing information, visit the Amazon Athena Pricing
October 25, 2023
Published on 2023-10-26
Athena announces the following fixes and improvements.
jackson-core package – JSON text with a numerical value larger than 1000 characters will now fail.
October 17, 2023
Published on 2023-10-17
Athena announces ODBC driver version 2.0.2.0. For more information, see the 2.0.2.0 release notes. To download the new ODBC v2 driver, see ODBC 2.x driver download. For connection information, see the Amazon Athena ODBC 2.x.
September 26, 2023
Published on 2023-09-26
Athena announces the following features and improvements.
-
Lake Formation read support for Delta Lake tables. For more information about using Delta Lake tables with Athena, see Query Linux Foundation Delta Lake tables.
August 23, 2023
Published on 2023-08-23
Amazon Athena announces the availability of Athena SQL in the Israel (Tel Aviv) Region.
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
August 10, 2023
Published on 2023-08-10
Athena announces the following fixes and improvements.
ODBC driver version 2.0.1.1
Athena announces ODBC driver version 2.0.1.1. For more information, see the 2.0.1.1 release notes. To download the new ODBC v2 driver, see ODBC 2.x driver download. For connection information, see the Amazon Athena ODBC 2.x.
JDBC driver version 2.1.1
Athena releases JDBC driver version 2.1.1. The driver resolves the following issues:
-
An error that occurred when a table was created with a statement that contained a regular expression.
-
An issue that caused the
ApplicationNameconnection parameter to be applied incorrectly.
To download the new JDBC driver, release notes, and documentation, see Connect to Amazon Athena with JDBC.
July 31, 2023
Published on 2023-07-31
Amazon Athena announces the availability of Athena SQL in additional AWS Regions.
This release expands the availability of Athena SQL to include Asia Pacific (Hyderabad), Asia Pacific (Melbourne), Europe (Spain), and Europe (Zurich).
For a complete list of the AWS services available in each AWS Region, see AWS Services by Region
July 27, 2023
Published on 2023-07-27
Athena releases Google BigQuery connector version 2023.30.1. This version of the connector reduces query execution time and adds support for querying against BigQuery private endpoints.
For information about the Google BigQuery connector, see Amazon Athena Google BigQuery connector. For information about updating your existing data source connectors, see Update a data source connector.
July 24, 2023
Published on 2023-07-24
Athena announces the following fixes and improvements.
-
Queries with unions – Improved the performance of certain queries with unions.
-
Joins with type comparisons – Fixed a potential query failure for
JOINstatements that included a comparison between two different types. -
Subqueries on nested columns – Fixed an issue related to query failures when subqueries were correlated on nested columns.
-
Iceberg views – Fixed a compatibility issue with the precision of timestamp columns in Apache Iceberg views. Iceberg views that have timestamp columns are now readable regardless of whether the columns were created on previous engine versions or Athena engine version 3.
July 20, 2023
Published on 2023-07-20
Athena releases JDBC driver version 2.1.0. The driver includes new enhancements and resolved an issue.
Enhancements
The following Jackson
-
jackson-annotations 2.15.2 (previously 2.14.0)
-
jackson-core 2.15.2 (previously 2.14.0)
-
jackson-databind 2.15.2 (previously 2.14.0)
Resolved issues
-
Fixed an issue with passing array parameters when the sql2o
library was used.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
July 13, 2023
Published on 2023-09-19
Athena announces the following features and improvements.
-
EXPLAIN ANALYZE – Added support for queue, analysis, planning, and execution time to the output of
EXPLAIN ANALYZE. -
EXPLAIN –
EXPLAINoutput now shows statistics when the query contains aggregations. -
Parquet Hive SerDe – Added the
parquet.ignore.statisticsproperty to enable processing statistics to be ignored when reading Parquet data. For information, see Ignore Parquet statistics.
For more information about EXPLAIN and EXPLAIN ANALYZE, see
Using EXPLAIN and EXPLAIN ANALYZE in Athena.
For more information about the Parquet Hive SerDe, see Parquet SerDe.
July 3, 2023
Published on 2023-07-25
As of July 3, 2023, Athena started redacting the query strings from CloudTrail logs. The
query string now has a value of ***OMITTED***. This change has been made to
prevent unintended disclosure of table names or filter values that could include
sensitive information. If you previously relied on CloudTrail logs to access full query
strings, we recommend using the Athena::GetQueryExecution API and passing
in the value of responseElements.queryExecutionId from the CloudTrail log. For
more information, see the GetQueryExecution action in the
Amazon Athena API Reference.
June 30, 2023
Published on 2023-06-30
The Athena query editor now supports typeahead code suggestions for a faster query authoring experience. You can now write SQL queries with enhanced accuracy and increased efficiency using the following features:
-
As you type, suggestions appear in real time for keywords, local variables, snippets, and catalog items.
-
When you type a database name or table name followed by a dot, the editor conveniently displays a list of tables or columns to choose from.
-
When you hover over a snippet suggestion, a synopsis shows a brief overview of the snippet's syntax and usage.
-
To improve code readability, keywords and their highlighting rules have also been updated to align with latest syntax of Trino and Hive.
This feature is enabled by default. You can enable or disable the feature in the code editor preferences settings.
To try the typeahead code suggestions in the Athena query editor, visit the Athena
console at https://console.aws.amazon.com/athena/
June 29, 2023
Published on 2023-06-29
-
Athena announces ODBC driver version 2.0.1.0. For more information, see the 2.0.1.0 release notes. To download the new ODBC v2 driver, see ODBC 2.x driver download. For connection information, see the Amazon Athena ODBC 2.x.
-
Athena and its features
are now available in the Middle East (UAE) Region. For a complete list of the AWS services available in each AWS Region, see AWS Services by Region .
June 28, 2023
Published on 2023-06-28
You can now use Amazon Athena to query restored objects from the S3 Glacier Flexible Retrieval (formerly Glacier) and S3 Glacier Deep Archive Amazon S3 storage classes. You configure this capability on a per-table basis. The feature is supported only for Apache Hive tables on Athena engine version 3.
For more information, see Query restored Amazon Glacier objects.
June 12, 2023
Published on 2023-06-12
Athena announces the following fixes and improvements.
-
Parquet Reader timestamps – Added support for reading timestamps as
bigint(millis) for Parquet Reader. This update provides parity with the support in previous engine versions. -
EXPLAIN ANALYZE – Added physical input read time to the query statistics and output of
EXPLAIN ANALYZE. For information aboutEXPLAIN ANALYZE, see Using EXPLAIN and EXPLAIN ANALYZE in Athena. -
INSERT – Improved query performance on tables written to with
INSERT. For information aboutINSERT, see INSERT INTO. -
Delta Lake tables – Corrected an issue with
DROP TABLEon Delta Lake tables that prevented them from being fully deleted when subject to concurrent modifications.
June 8, 2023
Published on 2023-06-08
Amazon Athena for Apache Spark announces the following new features.
-
Support for custom Java libraries and configuration – You can now use your own Java packages and custom configuration for your Apache Spark sessions in Athena. Use Spark properties to specify
.jarfiles, packages, or other custom configuration with the Athena console, the AWS CLI, or the Athena API. For more information, see Use Spark properties to specify custom configuration. -
Support for Apache Hudi, Apache Iceberg, and Delta Lake tables – Athena for Spark now supports the Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake open-source data lake storage table formats. For more information, see Use non-Hive table formats in Athena for Spark and the individual topics for using Use Apache Iceberg tables in Athena for Spark, Use Apache Hudi tables in Athena for Spark, and Use Linux Foundation Delta Lake tables in Athena for Spark tables in Athena for Spark.
-
Encryption support for Apache Spark – In Athena for Spark, you can now enable encryption on data in transit between Spark nodes and on local data at rest stored on disk by Spark. To enable Spark encryption, you can use the Athena console, the AWS CLI, or the Athena API. For more information, see Enable Apache Spark encryption.
For more information about Amazon Athena for Apache Spark, see Use Apache Spark in Amazon Athena.
June 2, 2023
Published on 2023-06-02
You can now delete capacity reservations in Athena and use CloudFormation templates to specify Athena capacity reservations.
-
Delete capacity reservations – You can now delete cancelled capacity reservations in Athena. A reservation must be cancelled before it can be deleted. Deleting a capacity reservation removes the reservation from your account immediately. The deleted reservation can no longer be referenced, including by its ARN. To delete a reservation, you can use the Athena console or the Athena API. For more information, see Delete a capacity reservation in the Amazon Athena User Guide and DeleteCapacityReservation in the Amazon Athena API Reference.
-
Use CloudFormation templates for capacity reservations – You can now use AWS CloudFormation templates to specify Athena capacity reservations using the
AWS::Athena::CapacityReservationresource. For more information, see AWS::Athena::CapacityReservation in the AWS CloudFormation User Guide.
For more information about using capacity reservations to provision your capacity in Athena, see Manage query processing capacity.
May 25, 2023
Published on 2023-05-25
Athena has released data source connector updates that improve federated query performance. New push-down optimizations and dynamic filtering enable more operations to be performed in the source database rather than in Athena. These optimizations reduce query runtime and the amount of data scanned. These improvements require Athena engine version 3.
The following connectors have been updated:
For information about upgrading your data source connectors, see Update a data source connector.
May 18, 2023
Published on 2023-05-18
You can now use AWS PrivateLink for IPv6 inbound connections to Amazon Athena.
Amazon Athena has expanded its support for inbound connections through Internet Protocol
Version 6 (IPv6) endpoints to include AWS PrivateLink
The rapid growth of the Internet is exhausting the availability of Internet Protocol version 4 (IPv4) addresses. IPv6 increases the number of available addresses by several times so that you no longer have to manage overlapping address spaces in your VPCs. With this release, you can now combine the benefits of IPv6 addressing with the security and performance advantages of AWS PrivateLink.
To connect programmatically to an AWS service, you can use the AWS CLI
May 15, 2023
Published on 2023-05-15
Athena announces the release of Apache Spark DataSourceV2 (DSV2) connectors for DynamoDB, CloudWatch Logs, CloudWatch Metrics, and AWS CMDB. Use the new DSV2 connectors to query these data sources using Spark. DSV2 connectors use the same parameters as their corresponding Athena federated connectors. The DSV2 connectors run directly on Spark workers and do not require you to deploy a Lambda function to use them.
For more information, see Work with data source connectors for Apache Spark.
May 10, 2023
Published on 2023-05-10
Released the ODBC 1.1.20 driver for Athena.
Features and enhancements:
-
Lake Formation endpoint override support.
-
The ADFS authentication plugin has a new parameter for setting the Relying Party value (
LoginToRP). -
AWS library updates.
Bug fixes:
-
Prepared statement deallocation failure when the
SQLPrepare()method failed to submit. -
Error in binding prepared statement parameters when converting a C type to SQL type.
-
Failure to return data when
EXPLAINandEXPLAIN ANALYZEqueries usedSQLPrepare()andSQLExecute().
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with ODBC.
May 8, 2023
Published on 2023-05-08
Athena announces the following fixes and improvements.
-
Updated Hudi integration – Athena has updated its integration with Apache Hudi. You can now use Athena to query Hudi 0.12.2 tables, and Hudi metadata listing for Hudi tables is now supported. For information, see Query Apache Hudi datasets and Use Hudi metadata for improved performance.
-
Timestamp conversion fix – Corrected the handling of timestamp conversions to a lower precision data type. Previously, Athena engine version 3 incorrectly rounded the value to the target type instead of truncating it during casting.
The following examples illustrate the incorrect handling prior to the fix.
Example 1: Casting from a timestamp in microseconds to milliseconds
Sample data
A, 2020-06-10 15:55:23.383 B, 2020-06-10 15:55:23.382 C, 2020-06-10 15:55:23.383345 D, 2020-06-10 15:55:23.383945 E, 2020-06-10 15:55:23.383345734 F, 2020-06-10 15:55:23.383945278The following query tries to retrieve the timestamps that match a specific value.
SELECT * FROM table WHERE timestamps.col = timestamp'2020-06-10 15:55:23.383'The query returned the following results.
A, 2020-06-10 15:55:23.383 C, 2020-06-10 15:55:23.383 E, 2020-06-10 15:55:23.383Prior to the fix, Athena did not include the values
2020-06-10 15:55:23.383945or2020-06-10 15:55:23.383945278because they got rounded to2020-06-10 15:55:23.384.Example 2: Casting from a timestamp to date
The following query returned an erroneous result.
SELECT date(timestamp '2020-12-31 23:59:59.999')Result
2021-01-01Prior to the fix, Athena rounded up the value, therefore moving the day forward. Such values are now truncated rather than rounded up.
April 28, 2023
Published on 2023-04-28
You can now use capacity reservations on Amazon Athena to run SQL queries on fully-managed compute capacity.
Provisioned capacity provides workload management capabilities that help you prioritize, control, and scale your most important interactive workloads. You can add capacity at any time to increase the number of queries that you run concurrently, control which workloads use the capacity, and share capacity among workloads.
For more information, see Manage query processing capacity. For pricing information, visit the Amazon Athena pricing
April 17, 2023
Published on 2023-04-17
Athena releases JDBC driver version 2.0.36. The driver includes new features and resolved an issue.
New features
-
You can now use customizable relying party identifiers with AD FS authentication.
-
You can now add the name of the application that is using the connector to the user agent string.
Resolved issues
-
Fixed an error that occurred when
getSchema()was used to retrieve a non-existent schema.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
April 14, 2023
Published on 2023-06-20
Athena announces the following fixes and improvements.
-
When you cast a string to timestamp, a space is required between the day and time or timezone. For more information, see Space required between date and time values when casting from string to timestamp.
-
Removed a breaking change in the way timestamp precision was handled. To maintain consistency between previous engine versions and Athena engine version 3, timestamp precision now defaults to milliseconds rather than microseconds.
-
Athena now consistently enforces access for the query output bucket when it runs queries. Please make sure that all IAM principals that run the StartQueryExecution action have the S3:GetBucketLocation permission on the query output bucket.
April 4, 2023
Published on 2023-04-04
You can now use Amazon Athena to create and query views on federated data sources. Use a single federated view to query multiple external tables or subsets of data. This simplifies the SQL required and gives you the flexibility of obfuscating sources of data from end users who must use SQL to query the data.
For more information, see Work with views and Run federated queries.
March 30, 2023
Published on 2023-03-30
Amazon Athena announces the availability of Amazon Athena for Apache Spark in additional AWS Regions.
This release expands the availability of Amazon Athena for Apache Spark to include Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), and Europe (Frankfurt).
For more information about Amazon Athena for Apache Spark, see Use Apache Spark in Amazon Athena.
March 28, 2023
Published on 2023-03-28
Athena announces the following fixes and improvements.
-
In the responses to the
GetQueryExecutionandBatchGetQueryExecutionAthena API actions, the newsubStatementTypefield shows the type of query that ran (for example,SELECT,INSERT,UNLOAD,CREATE_TABLE, orCREATE_TABLE_AS_SELECT). -
Fixed a bug in which manifest files were not encrypted correctly for Apache Hive write operations.
-
Athena engine version 3 now correctly handles
NaNandInfinityvalues in theapprox_percentilefunction. Theapprox_percentilefunction returns the approximate percentile for a dataset at the given percentage.Athena engine version 2 incorrectly treats
NaNas a value greater thanInfinity. Athena engine version 3 now handlesNaNandInfinityin accordance with the treatment of these values in other analytic and statistical functions. The following points describe the new behavior in greater detail.-
If
NaNis present in the dataset, Athena returnsNaN. -
If
NaNis not present, butInfinityis present, Athena treatsInfinityas a very large number. -
If multiple
Infinityvalues are present, Athena treats them as the same very large number. If necessary, Athena outputsInfinity. -
If a single dataset has both -
Infinityand-Double.MAX_VALUE, and a percentile result is-Double.MAX_VALUE, Athena returns-Infinity. -
If a single dataset has both
InfinityandDouble.MAX_VALUE, and a percentile result isDouble.MAX_VALUE, Athena returnsInfinity. -
To exclude
InfinityandNaNfrom a calculation, use theis_finite()function, as in the following example.approx_percentile(x, 0.5) FILTER (WHERE is_finite(x))
-
March 27, 2023
Published on 2023-03-27
You can now specify a minimum level of encryption for Athena SQL workgroups in Amazon Athena. This feature ensures that the results from all queries in the Athena SQL workgroup are encrypted at or above the level of encryption that you specify. You can choose among several levels of encryption strength to safeguard your data. To configure the minimum level of encryption that you want, you can use the Athena console, AWS CLI, API, or SDK.
The minimum encryption feature is not available for Apache Spark enabled workgroups. For more information, see Configure minimum encryption for a workgroup.
March 17, 2023
Published on 2023-03-17
Athena announces the following fixes and improvements.
-
Fixed an issue with the Amazon Athena DynamoDB connector that caused queries to fail with the error message
KeyConditionExpressions must only contain one condition per key.This issue occurs because Athena engine version 3 recognizes the opportunity to push down more kinds of predicates than Athena engine version 2. In Athena engine version 3, clauses like
some_column LIKE 'someprefix%are pushed down as filter predicates that apply a lower and upper bound on a given column. Athena engine version 2 did not push these predicates down. In Athena engine version 3, whensome_columnis a sort key column, the engine pushes the filter predicate down to the DynamoDB connector. The filter predicate then gets further pushed down to the DynamoDB service. Because DynamoDB does not support more than one filter condition on a sort key, DynamoDB returns the error.To correct this issue, update your Amazon Athena DynamoDB connector to version 2023.11.1. For instructions on updating the connector, see Update a data source connector.
March 8, 2023
Published on 2023-03-08
Athena announces the following fixes and improvements.
-
Fixed an issue with federated queries that caused timestamp predicate values to be sent as microseconds instead of milliseconds.
February 15, 2023
Published on 2023-02-15
Athena announces the following fixes and improvements.
-
You can now use client-side encryption to encrypt data in Amazon S3 for Iceberg write operations.
-
Fixed an issue that affected server-side encryption in Amazon S3 for Iceberg write operations.
January 31, 2023
Published on 2023-01-31
You can now use Amazon Athena to query data in Google Cloud Storage. Like Amazon S3, Google Cloud Storage is a managed service that stores data in buckets. Use the Athena connector for Google Cloud Storage to run interactive federated queries on your external data.
For more information, see Amazon Athena Google Cloud Storage connector.
January 20, 2023
Published on 2023-01-20
You can now see expanded documentation for Athena compression support. Individual topics have been added for Hive table compression, Iceberg table compression, and ZSTD compression levels.
For more information, see Use compression in Athena.
January 3, 2023
Published on 2023-01-03
Athena announces the following updates:
-
Additional commands for Hive metastores – You can use Athena to connect to your self-managed Apache Hive Metastore as a metadata catalog and query data stored in Amazon S3. With this release, you can use
CREATE TABLE AS(CTAS),INSERT INTO, and 12 additional Data Definition Language (DDL) commands to interact with the Apache Hive Metastore. You can manage your Hive Metastore schemas directly from Athena using this expanded set of SQL capabilities.For more information, see Use an external Hive metastore.
-
JDBC driver version 2.0.35 – Athena releases JDBC driver version 2.0.35. The JDBC 2.0.35 driver contains the following updates:
-
The driver now uses the following libraries for the Jackson JSON parser.
-
jackson-annotations 2.14.0 (previously 2.13.2)
-
jackson-core 2.14.0 (previously 2.13.2)
-
jackson-databind 2.14.0 (previously 2.13.2.2)
-
-
Support for JDBC version 4.1 has been discontinued.
For more information, and to download the new driver, release notes, and documentation, see Connect to Amazon Athena with JDBC.
-
Athena release notes for 2022
December 14, 2022
Published on 2022-12-14
You can now use the Amazon Athena connector for Kafka to run SQL queries on streaming data. For example, you can run analytical queries on real-time streaming data in Amazon Managed Streaming for Apache Kafka (Amazon MSK) and join it with historical data in your data lake in Amazon S3.
The Amazon Athena connector for Kafka supports queries on multiple streaming engines. You can use Athena to run SQL queries on Amazon MSK provisioned and serverless clusters, on self-managed Kafka deployments, and on streaming data in Confluent Cloud.
For more information, see Amazon Athena MSK connector.
December 2, 2022
Published on 2022-12-02
Athena releases JDBC driver version 2.0.34. The JDBC 2.0.34 driver includes the following new features and resolved issues:
-
Query result reuse support – You can now reuse the results of previously executed queries up to a time limit that you specify instead of having Athena recompute the results each time the query is run. For more information, see the Installation and Configuration Guide, available from the JDBC download page, and Reuse query results in Athena.
-
Ec2InstanceMetadata support – The JDBC driver now supports the Ec2InstanceMetadata authentication method using IAM instance profiles .
-
Character-based exception fix – Fixed an exception that occurred with queries containing certain language characters.
-
Vulnerability fix – Corrected a vulnerability related to AWS dependencies packaged with the connector.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
November 30, 2022
Published on 2022-11-30
You can now interactively create and run Apache Spark applications and Jupyter compatible notebooks on Athena. Run data analytics on Athena using Spark without having to plan for, configure, or manage resources. Submit Spark code for processing and receive the results directly. Use the simplified notebook experience in Amazon Athena console to develop Apache Spark applications using Python or Use Athena Spark APIs.
Apache Spark on Amazon Athena is serverless and provides automatic, on-demand scaling that delivers instant-on compute to meet changing data volumes and processing requirements.
For more information, see Use Apache Spark in Amazon Athena.
November 18, 2022
Published on 2022-11-18
You can now use the Amazon Athena connector for IBM Db2 to query Db2 from Athena. For example, you can run analytical queries over a data warehouse on Db2 and a data lake in Amazon S3.
The Amazon Athena Db2 connector exposes several configuration options through Lambda environment variables. For information about configuration options, parameters, connection strings, deployment, and limitations, see Amazon Athena IBM Db2 connector.
November 17, 2022
Published on 2022-11-17
Apache Iceberg support in Athena engine version 3 now offers the following enhanced ACID transaction features:
-
ORC and Avro support – Create Iceberg tables using the Apache Avro
and Apache ORC row and column-based file formats. Support for these formats is in addition to the existing support for Parquet. -
MERGE INTO – Use the
MERGE INTOcommand to merge data at scale efficiently.MERGE INTOcombines theINSERT,UPDATE, andDELETEoperations into one transaction. This reduces the processing overhead in your data pipeline and takes less SQL to write. For more information, see Update Iceberg table data and MERGE INTO. -
CTAS and VIEW support – Use the
CREATE TABLE AS SELECT(CTAS) andCREATE VIEWstatements with Iceberg tables. For more information, see CREATE TABLE AS and CREATE VIEW and CREATE PROTECTED MULTI DIALECT VIEW. -
VACUUM support – You can use the
VACUUMstatement to optimize your data lake by deleting snapshots and data that are no longer required. You can use this feature to improve read performance and meet regulatory requirements like GDPR. For more information, see Optimize Iceberg tables and VACUUM.
These new features require Athena engine version 3 and are available in all Regions where Athena is
supported. You can use them with the Athena
console
For information about using Iceberg in Athena, see Query Apache Iceberg tables.
November 14, 2022
Published on 2022-11-14
Amazon Athena now supports IPv6 endpoints for inbound connections that you can use to invoke Athena functions over IPv6. You can use this feature to meet IPv6 compliance requirements. It also removes the need for additional networking equipment to handle address translation between IPv4 and IPv6.
To use this feature, configure your applications to use the new Athena dual-stack
endpoints, which support both IPv4 and IPv6. Dual-stack endpoints use the format
athena.. For example, the
dual-stack endpoint in the US East (N. Virginia) Region is region.api.awsathena.us-east-1.api.aws.
When you make a request to a dual-stack Athena endpoint, the endpoint resolves to an
IPv6 or an IPv4 address depending on the protocol used by your network and client. To
connect programmatically to an AWS service, you can use the AWS CLI
For more information on service endpoints, see AWS service endpoints. To learn more about Athena's service endpoints, see Amazon Athena endpoints and quotas in the AWS documentation.
You can use the new Athena dual-stack endpoints for inbound connections at no additional cost. Dual-stack endpoints are generally available in all AWS Regions.
November 11, 2022
Published on 2022-11-11
Athena announces the following fixes and improvements.
-
Expanded Lake Formation fine-grained access control – You can now use AWS Lake Formation
fine-grained access control policies in Athena queries for data stored in any supported file or table format. You can use fine-grained access control in Lake Formation to restrict access to data in query results using data filters to achieve column-level, row-level, and cell-level security. Supported table formats in Athena include Apache Iceberg, Apache Hudi, and Apache Hive. Expanded fine-grained access control is available in all regions supported by Athena. The expanded table and file format support requires Athena engine version 3, which offers new features and improved query performance , but does not change how you set up fine-grained access control policies in Lake Formation. Use of this expanded fine-grained access control in Athena has the following considerations:
-
EXPLAIN – Row or cell filtering information defined in Lake Formation and query statistics information are not shown in the output of
EXPLAINandEXPLAIN ANALYZE. For information aboutEXPLAINin Athena, see Using EXPLAIN and EXPLAIN ANALYZE in Athena. -
External Hive metastores – Apache Hive hidden columns cannot be used for fine-grained access control filtering, and Apache Hive hidden system tables are not supported by fine-grained access control. For more information, see Considerations and limitations in the topic Use an external Hive metastore.
-
Query statistics – Stage-level input and output row count and data size information are not shown in Athena query statistics when a query has row-level filters defined in Lake Formation. For information about seeing statistics for Athena queries, see View statistics and execution details for completed queries and GetQueryRuntimeStatistics.
-
Workgroups – Users in the same Athena workgroup can see the data that Lake Formation fine-grained access control has configured to be accessible to the workgroup. For information about using Athena to query data registered with Lake Formation, see Use Athena to query data registered with AWS Lake Formation.
For information about using fine-grained access control in Lake Formation, see Manage fine-grained access control using AWS Lake Formation
in the AWS Big Data Blog. -
-
Athena Federated Query – Athena Federated Query now preserves the original casing of field names in
structobjects. Previously,structfield names were automatically made lower case.
November 8, 2022
Published on 2022-11-08
You can now use the query result reuse caching feature to accelerate repeat queries in Athena. A repeat query is a SQL query identical to one submitted just recently that produces the same results. When you need to run identical multiple queries, result reuse caching can decrease the time required to produce results. Result reuse caching also lowers costs by reducing the number of bytes scanned.
For more information, see Reuse query results in Athena.
October 13, 2022
Published on 2022-10-13
Athena announces Athena engine version 3.
Athena has upgraded its SQL query engine to include the latest features from the Trino
For more information, see Athena engine version 3.
October 10, 2022
Published on 2022-10-10
Athena releases JDBC driver version 2.0.33. The JDBC 2.0.33 driver includes the following changes:
-
New driver version, JDBC version, and plugin name properties were added to the user-agent string in the credentials provider class.
-
Error messages were corrected and necessary information added.
-
Prepared statements are now deallocated if the connection is closed or the Athena prepared statement execution fails.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
September 23, 2022
Published on 2022-09-26
The Amazon Athena Neptune connector now supports case insensitive matching on column and table names.
-
The Neptune data source connector can resolve column names on Neptune tables that use casing even if the column names are all lower cased in the table in AWS Glue. To enable this behavior, set the
enable_caseinsensitivematchenvironment variable totrueon the Neptune connector Lambda function. -
Because AWS Glue supports only lower case table names, when you create a AWS Glue table for Neptune, specify the AWS Glue table parameter
"glabel" =.table_name
For more information about the Neptune connector, see Amazon Athena Neptune connector.
September 13, 2022
Published on 2022-09-13
Athena announces the following fixes and improvements.
-
External Hive metastore – Athena now returns
NULLinstead of throwing an exception when aWHEREclause includes a partition that doesn't exist in an external Hive metastore (EHMS). The new behavior matches that of the AWS Glue Data Catalog. -
Parameterized queries – Values in parameterized queries can now be cast to the
DOUBLEdata type. -
Apache Iceberg – Write operations to Iceberg tables now succeed when Object Lock is enabled on an Amazon S3 bucket.
August 31, 2022
Published on 2022-08-31
Amazon Athena announces availability of Athena and its features
This release expands Athena's availability in Asia Pacific to include
Asia Pacific (Hong Kong), Asia Pacific (Jakarta), Asia Pacific (Mumbai),
Asia Pacific (Osaka), Asia Pacific (Seoul), Asia Pacific (Singapore),
Asia Pacific (Sydney), and Asia Pacific (Tokyo). For a complete list of
AWS services available in these and other Regions, refer to the AWS Regional Services List
August 23, 2022
Published on 2022-08-23
Release v2022.32.1
-
Added support to the Amazon Athena Oracle data source connector for SSL based connections to Amazon RDS instances. Support is limited to the Transport Layer Security (TLS) protocol and to authentication of the server by the client. Because mutual authentication it is not supported in Amazon RDS, the update does not include support for mutual authentication.
For more information, see Amazon Athena Oracle connector.
August 3, 2022
Published on 2022-08-03
Athena releases JDBC driver version 2.0.32. The JDBC 2.0.32 driver includes the following changes:
-
The
User-Agentstring sent to the Athena SDK has been extended to contain the driver version, JDBC specification version, and the name of the authentication plugin. -
Fixed a
NullPointerExceptionthat was thrown when no value was provided for theCheckNonProxyHostparameter. -
Fixed an issue with
login_urlparsing in the BrowserSaml authentication plugin. -
Fixed a proxy host issue that occurred when the
UseProxyforIdpparameter was set totrue.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
August 1, 2022
Published on 2022-08-01
Athena announces improvements to the Athena Query Federation SDK and Athena prebuilt data source connectors. The improvements include the following:
-
Struct parsing – Fixed a
GlueFieldLexerparsing issue in the Athena Query Federation SDK that prevented certain complicated structs from displaying all of their data. This issue affected connectors built on the Athena Query Federation SDK. -
AWS Glue tables – Added additional support for the
setanddecimalcolumn types in AWS Glue tables. -
DynamoDB connector – Added the ability to ignore casing on DynamoDB attribute names. For more information, see
disable_projection_and_casingin the Parameters section of the Amazon Athena DynamoDB connector page.
For more information, see Release v2022.30.2 of Athena Query Federation
July 21, 2022
Published on 2022-07-21
You can now analyze and debug your queries using performance metrics and interactive, visual query analysis tools in the Athena console. The query performance data and execution details can help you identify bottlenecks in queries, inspect the operators and statistics for each stage of a query, trace the volume of data flowing between stages, and validate the impact of query predicates. You can now:
-
Access the distributed and logical execution plan for your query in a single click.
-
Explore the operations at each stage before the stage is run.
-
Visualize the performance of completed queries with metrics for time spent in the queuing, planning, and execution stages.
-
Get information about the number of rows and amount of source data processed and output by your query.
-
See granular execution details for your queries presented in context and formatted as an interactive graph.
-
Use precise, stage-level execution details to understand the flow of data through your query.
-
Analyze query performance data programmatically using new APIs to get query runtime statistics, also released today.
To learn how to use these capabilities on your queries, watch the video
tutorial Optimize Amazon Athena
Queries with New Query Analysis Tools
For documentation, see View execution plans for SQL queries and View statistics and execution details for completed queries.
July 11, 2022
Published on 2022-07-11
You can now run parameterized queries directly from the Athena console or API without preparing SQL statements in advance.
When you run queries in the Athena console that have parameters in the form of question marks, the user interface now prompts you to enter values for the parameters directly. This eliminates the need to modify literal values in the query editor every time you want to run the query.
If you use the enhanced query execution API, you can now provide the execution parameters and their values in a single call.
For more information, see Use parameterized queries in this user guide and the AWS
Big Data Blog post Use Amazon Athena parameterized queries to provide data as a service
July 8, 2022
Published on 2022-07-08
Athena announces the following fixes and improvements.
-
Fixed an issue with
DATEcolumn conversion handling for SageMaker AI endpoints (UDF) that was causing query failures.
June 6, 2022
Published on 2022-06-06
Athena releases JDBC driver version 2.0.31. The JDBC 2.0.31 driver includes the following changes:
-
log4j dependency issue – Resolved a
Cannot find driver classerror message caused by a log4j dependency.
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
May 25, 2022
Published on 2022-05-25
Athena announces the following fixes and improvements.
-
Iceberg support
-
Introduced support for cross-region queries. Now you can query Iceberg tables in an AWS Region that is different from the AWS Region that you are using. Cross-region querying is not supported in the China Regions.
-
Introduced support for server side encryption configuration. Now you can use SSE-S3/SSE-KMS to encrypt data from Iceberg write operations in Amazon S3.
For more information about using Apache Iceberg in Athena, see Query Apache Iceberg tables.
-
-
JDBC 2.0.30 driver release
The JDBC 2.0.30 driver for Athena has the following improvements:
-
Fixes a data race issue that affected parameterized prepared statements.
-
Fixes an application start up issue that occurred in Gradle build environments.
To download the JDBC 2.0.30 driver, release notes, and documentation, see Connect to Amazon Athena with JDBC.
-
May 6, 2022
Published on 2022-05-06
Released the JDBC 2.0.29 and ODBC 1.1.17 drivers for Athena.
These drivers include the following changes:
-
Updated the SAML plugin browser launch process.
For more information about these changes, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
April 22, 2022
Published on 2022-04-22
Athena announces the following fixes and improvements.
-
Fixed an issue in the partition indices and filtering feature
with the partition cache that occurred when the following conditions were met: -
The
partition_filtering.enabledkey was set totruein the AWS Glue table properties for a table. -
The same table was used multiple times with different partition filter values.
-
April 21, 2022
Published on 2022-04-21
You can now use Amazon Athena to run federated queries on new data sources, including Google BigQuery, Azure Synapse, and Snowflake. New data source connectors include:
For a complete list of data sources supported by Athena, see Available data source connectors.
To make it easier to browse the available sources and connect to your data, you can now search, sort, and filter the available connectors from an updated Data Sources screen in the Athena console.
To learn about querying federated sources, see Use Amazon Athena Federated Query and Run federated queries.
April 13, 2022
Published on 2022-04-13
Athena releases JDBC driver version 2.0.28. The JDBC 2.0.28 driver includes the following changes:
-
JWT support – The driver now supports JSON web tokens (JWT) for authentication. For information about using JWT with the JDBC driver, see the installation and configuration guide, downloadable from the JDBC driver page.
-
Updated Log4j libraries – The JDBC driver now uses the following Log4j libraries:
-
Log4j-api 2.17.1 (previously 2.17.0)
-
Log4j-core 2.17.1 (previously 2.17.0)
-
Log4j-jcl 2.17.2
-
-
Other improvements – The new driver also includes the following improvements and bug fixes:
-
The Athena prepared statements feature is now available through JDBC. For information about prepared statements, see Use parameterized queries.
-
Athena JDBC SAML federation is now functional for the China Regions.
-
Additional minor improvements.
-
For more information, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC.
March 30, 2022
Published on 2022-03-30
Athena announces the following fixes and improvements.
-
Cross-region querying – You can now use Athena to query data located in an Amazon S3 bucket across AWS Regions including Asia Pacific (Hong Kong), Middle East (Bahrain), Africa (Cape Town), and Europe (Milan). Cross-region querying is not supported in the China Regions.
-
For a list of AWS Regions in which Athena is available, see Amazon Athena endpoints and quotas.
-
For information about enabling an AWS Region that is disabled by default, see Enabling a Region.
-
For information about querying across Regions, see Query across regions.
-
March 18, 2022
Published on 2022-03-18
Athena announces the following fixes and improvements.
-
Dynamic filtering – Dynamic filtering has been improved for integer columns by efficiently applying the filter to each record of a corresponding table.
-
Iceberg – Fixed an issue that caused failures when writing Iceberg Parquet files larger than 2GB.
-
Uncompressed output – CREATE TABLE statements now support writing uncompressed files. To write uncompressed files, use the following syntax:
-
CREATE TABLE (text file or JSON) – In
TBLPROPERTIES, specifywrite.compression = NONE. -
CREATE TABLE (Parquet) – In
TBLPROPERTIES, specifyparquet.compression = UNCOMPRESSED. -
CREATE TABLE (ORC) – In
TBLPROPERTIES, specifyorc.compress = NONE.
-
-
Compression – Fixed an issue with inserts for text file tables that created files compressed in one format but used another compression format file extension when non-default compression methods were used.
-
Avro – Fixed issues that occurred when reading decimals of the fixed type from Avro files.
March 2, 2022
Published on 2022-03-02
Athena announces the following features and improvements.
-
You can now grant the Amazon S3 bucket owner full control access over query results when ACLs are enabled for the query result bucket. For more information, see Specify a query result location.
-
You can now update existing named queries. For more information, see Use saved queries.
February 23, 2022
Published on 2022-02-23
Athena announces the following fixes and performance improvements.
-
Memory handling improvements to enhance performance and reduce memory errors.
-
Athena now reads ORC timestamp columns with time zone information stored in stripe footers and writes ORC files with time zone (UTC) in footers. This only impacts the behavior of ORC timestamp reads if the ORC file to be read was created in a non-UTC time zone environment.
-
Fixed incorrect symlink table size estimates that resulted in suboptimal query plans.
-
Lateral exploded views can now be queried in the Athena console from Hive metastore data sources.
-
Improved Amazon S3 read error messages to include more detailed Amazon S3 error code information.
-
Fixed an issue that caused output files in ORC format to become incompatible with Apache Hive 3.1.
-
Fixed an issue that caused table names with quotes to fail in certain DML and DDL queries.
February 15, 2022
Published on 2022-02-15
Amazon Athena has increased the active DML query quota in all AWS Regions. Active queries include both running and queued queries. With this change, you can now have more DML queries in an active state than before.
For information about Athena service quotas, see Service Quotas. For the query quotas in the Region where you use Athena, see Amazon Athena endpoints and quotas in the AWS General Reference.
To monitor your quota usage, you can use CloudWatch usage metrics. Athena publishes the
ActiveQueryCount metric in the AWS/Usage namespace. For
more information, see Monitor Athena usage metrics with CloudWatch.
After reviewing your usage, you can use the Service Quotas
February 14, 2022
Published on 2022-02-14
This release adds the ErrorType subfield to the AthenaError response object in the Athena GetQueryExecution API action.
While the existing ErrorCategory field indicates the general source of a
failed query (system, user, or other), the new ErrorType field provides
more granular information about the error that occurred. Combine the information from
both fields to gain insight into the causes of query failure.
For more information, see Athena error catalog.
February 9, 2022
Published on 2022-02-09
The old Athena console is no longer available. Athena's new console supports all of the
features of the earlier console, but with an easier to use, modern interface and
includes new features that improve the experience of developing queries, analyzing data,
and managing your usage. To use the new Athena console, visit https://console.aws.amazon.com/athena/
February 8, 2022
Published on 2022-02-08
Expected bucket owner – As an added security measure, you can now optionally specify the AWS account ID that you expect to be the owner of your query results output location bucket in Athena. If the account ID of the query results bucket owner does not match the account ID that you specify, attempts to output to the bucket will fail with an Amazon S3 permissions error. You can make this setting at the client or workgroup level.
For more information, see Specify a query result location.
January 28, 2022
Published on 2022-01-28
Athena announces the following engine feature enhancements.
-
Apache Hudi – Snapshot queries on Hudi Merge on Read (MoR) tables can now read timestamp columns that have the
INT64data type. -
UNION queries – Performance improvement and data scan reduction for certain
UNIONqueries that scan the same table multiple times. -
Disjunct queries – Performance improvement for queries that have only disjunct values for each partition column on the filter.
-
Partition projection enhancements
-
Multiple disjunct values are now allowed on the filter condition for columns of the
injectedtype. For more information, see Injected type. -
Performance improvement for columns of string-based types like
CHARorVARCHARthat have only disjunct values on the filter.
-
January 13, 2022
Published on 2022-01-13
Released the JDBC 2.0.27 and ODBC 1.1.15 drivers for Athena.
The JDBC 2.0.27 driver includes the following changes:
-
The driver has been updated to retrieve external catalogs.
-
The extended driver version number is now included in the
user-agentstring as part of the Athena API call.
The ODBC 1.1.15 driver includes the following changes:
-
Corrects an issue with second calls to
SQLParamData().
For more information about these changes, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
Athena release notes for 2021
November 26, 2021
Published on 2021-11-26
Athena announces the public preview of Athena ACID transactions, which add write,
delete, update, and time travel operations to Athena's SQL data manipulation language
(DML). Athena ACID transactions enable multiple concurrent users to make reliable,
row-level modifications to Amazon S3 data. Built on the Apache Iceberg
Athena ACID transactions and familiar SQL syntax simplify updates to your business and
regulatory data. For example, to respond to a data erasure request, you can perform a
SQL DELETE operation. To make manual record corrections, you can use a
single UPDATE statement. To recover data that was recently deleted, you can
issue time travel queries using a SELECT statement. Athena transactions are
available through Athena's console, API operations, and ODBC and JDBC drivers.
For more information, see Use Athena ACID transactions.
November 24, 2021
Published on 2021-11-24
Athena announces support for reading and writing ZStandard
For information about data compression in Athena, see Use compression in Athena.
November 22, 2021
Published on 2021-11-22
You can now manage AWS Step Functions workflows from the Amazon Athena console, making it easier to build scalable data processing pipelines, execute queries based on custom business logic, automate administrative and alerting tasks, and more.
Step Functions is now integrated with Athena's upgraded console, and you can use it to view an interactive workflow diagram of your state machines that invoke Athena. To get started, select Workflows from the left navigation panel. If you have existing state machines with Athena queries, select a state machine to view an interactive diagram of the workflow. If you are new to Step Functions, you can get started by launching a sample project from the Athena console and customizing it to suit your use cases.
For more information, see Build and orchestrate ETL pipelines using Amazon Athena and AWS Step Functions
November 18, 2021
Published on 2021-11-18
Athena announces new features and improvements.
-
Support for spill-to-disk for aggregation queries that contain
DISTINCT,ORDER BY, or both, as in the following example:SELECT array_agg(orderstatus ORDER BY orderstatus) FROM orders GROUP BY orderpriority, custkey -
Addressed memory handling issues for queries that use
DISTINCT. To avoid error messages likeQuery exhausted resources at this scale factorwhen you useDISTINCTqueries, choose columns that have a low cardinality forDISTINCT, or reduce the data size of the query. -
In
SELECT COUNT(*)queries that do not specify a specific column, improved performance and memory usage by keeping only the count without row buffering. -
Introduced the following string functions.
-
translate(source, from, to)– Returns thesourcestring with the characters found in thefromstring replaced by the corresponding characters in thetostring. If thefromstring contains duplicates, only the first is used. If thesourcecharacter does not exist in thefromstring, thesourcecharacter is copied without translation. If the index of the matching character in thefromstring is greater than the length of thetostring, the character is omitted from the resulting string. -
concat_ws(string0, array(varchar))– Returns the concatenation of elements in the array usingstring0as a separator. Ifstring0is null, then the return value is null. Any null values in the array are skipped.
-
-
Fixed a bug in which queries failed when trying to access a missing subfield in a
struct. Queries now return a null for the missing subfield. -
Fixed an issue with inconsistent hashing for the decimal data type.
-
Fixed an issue that caused exhausted resources when there were too many columns in a partition.
November 17, 2021
Published on 2021-11-17
Amazon Athena
When querying partitioned tables, Athena retrieves and filters the available table partitions to the subset relevant to your query. As new data and partitions are added, more time is required to process the partitions and query runtime can increase. To optimize partition processing and improve query performance on highly partitioned tables, Athena now supports AWS Glue partition indexes.
For more information, see Optimize queries with AWS Glue partition indexing and filtering.
November 16, 2021
Published on 2021-11-16
The new and improved Amazon Athena
-
Rearrange, navigate to, or close multiple query tabs from a redesigned query tab bar.
-
Read and edit queries more easily with improved SQL and text formatting.
-
Copy query results to your clipboard in addition to downloading the full result set.
-
Sort your query history, saved queries, and workgroups, and choose which columns to show or hide.
-
Use a simplified interface to configure data sources and workgroups in fewer clicks.
-
Set preferences for displaying query results, query history, line wrapping, and more.
-
Increase your productivity with new and improved keyboard shortcuts and embedded product documentation.
With today's announcement, the redesigned
console
If desired, you may use the earlier console by logging into your AWS account, choosing Amazon Athena, and deselecting New Athena experience from the navigation panel on the left.
November 12, 2021
Published on 2021-11-12
You can now use Amazon Athena to run federated queries on data sources located in an AWS account other than your own. Until today, querying this data required the data source and its connector to use the same AWS account as the user that queried the data.
As a data administrator, you can enable cross-account federated queries by sharing your data connector with a data analyst's account. As a data analyst, you can add a data connector that a data administrator has shared with you to your account. Configuration changes to the connector in the originating account apply automatically to the shared connector.
For information about enabling cross-account federated queries, see Enable cross-account federated queries. To learn about querying federated sources, see Use Amazon Athena Federated Query and Run federated queries.
November 2, 2021
Published on 2021-11-02
You can now use the EXPLAIN ANALYZE statement in Athena to view the
distributed execution plan and cost of each operation for your SQL queries.
For more information, see Using EXPLAIN and EXPLAIN ANALYZE in Athena.
October 29, 2021
Published on 2021-10-29
Athena releases JDBC 2.0.25 and ODBC 1.1.13 drivers and announces features and improvements.
JDBC and ODBC Drivers
Released JDBC 2.0.25 and ODBC 1.1.13 drivers for Athena. Both drivers offer support for browser SAML multi-factor authentication, which can be configured to work with any SAML 2.0 provider.
The JDBC 2.0.25 driver includes the following changes:
-
Support for browser SAML authentication. The driver includes a browser SAML plugin which can be configured to work with any SAML 2.0 provider.
-
Support for AWS Glue API calls. You can use the
GlueEndpointOverrideparameter to override the AWS Glue endpoint. -
Changed the
com.simba.athena.amazonawsclass path tocom.amazonaws.
The ODBC 1.1.13 driver includes the following changes:
-
Support for browser SAML authentication. The driver includes a browser SAML plugin which can be configured to work with any SAML 2.0 provider. For an example of how to use the browser SAML plugin with the ODBC driver, see Configure single sign-on using ODBC, SAML 2.0, and the Okta Identity Provider.
-
You can now configure the role session duration when you use ADFS, Azure AD, or Browser Azure AD for authentication.
For more information about these and other changes, and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
Features and Improvements
Athena announces the following features and improvements.
-
A new optimization rule has been introduced to avoid duplicate table scans in certain cases.
October 4, 2021
Published on 2021-10-04
Athena announces the following features and improvements.
-
SQL OFFSET – The SQL
OFFSETclause is now supported inSELECTstatements. For more information, see SELECT. -
CloudWatch usage metrics – Athena now publishes the
ActiveQueryCountmetric in theAWS/Usagenamespace. For more information, see Monitor Athena usage metrics with CloudWatch. -
Query planning – Fixed a bug that could in rare cases cause query planning timeouts.
September 16, 2021
Published on 2021-09-16
Athena announces the following new features and improvements.
Features
-
Added support for specifying text file and JSON compression in CTAS using the
write_compressiontable property. You can also specify thewrite_compressionproperty in CTAS for the Parquet and ORC formats. For more information, see CTAS table properties. -
The BZIP2 compression format is now supported for writing text file and JSON files. For more information about the compression formats in Athena, see Use compression in Athena.
Improvements
-
Fixed a bug in which identity information failed to be sent to the UDF Lambda function.
-
Fixed a predicate pushdown issue with disjunct filter conditions.
-
Fixed a hashing issue for decimal types.
-
Fixed an unnecessary statistics collection issue.
-
Removed an inconsistent error message.
-
Improved broadcast join performance by applying dynamic partition pruning in the worker node.
-
For federated queries:
-
Altered configuration to reduce the occurrence of
CONSTRAINT_VIOLATIONerrors in federated queries.
-
September 15, 2021
Published on 2021-09-15
You can now use a redesigned Amazon Athena console (Preview). A new Athena JDBC driver has been released.
Athena Console Preview
You can now use a redesigned Amazon Athena
To switch to the new console
Get started with the new console
Athena JDBC Driver 2.0.24
Athena announces availability of JDBC driver version 2.0.24 for Athena. This release
updates proxy support for all credentials providers. The driver now supports proxy
authentication for all hosts that are not supported by the
NonProxyHosts connection property.
As a convenience, this release includes downloads of the JDBC driver both with and without the AWS SDK. This JDBC driver version allows you to have both the AWS-SDK and the Athena JDBC driver embedded in project.
For more information and to download the new driver, release notes, and documentation, see Connect to Amazon Athena with JDBC.
August 31, 2021
Published on 2021-08-31
Athena announces the following feature enhancements and bug fixes.
-
Athena federation enhancements – Athena has added support to map types and better support for complex types as part of the Athena Query Federation SDK
. This version also includes some memory enhancements and performance optimizations. -
New error categories – Introduced the
USERandSYSTEMerror categories in error messages. These categories help you distinguish between errors that you can fix yourself (USER) and errors that can require assistance from Athena support (SYSTEM). -
Federated query error messaging – Updated
USER_ERRORcategorizations for federated query related errors. -
JOIN – Fixed spill-to-disk related bugs and memory issues to enhance performance and reduce memory errors in
JOINoperations.
August 12, 2021
Published on 2021-08-12
Released the ODBC 1.1.12 driver for Athena. This version corrects issues related to
SQLPrepare(), SQLGetInfo(), and
EndpointOverride.
To download the new driver, release notes, and documentation, see Connect to Amazon Athena with ODBC.
August 6, 2021
Published on 2021-08-06
Amazon Athena announces availability of Athena and its features
This release expands Athena's availability in Asia Pacific to include
Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Osaka),
Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), and
Asia Pacific (Tokyo). For a complete list of AWS services available in these and
other Regions, refer to the AWS Regional
Services List
August 5, 2021
Published on 2021-08-05
You can use the UNLOAD statement to write the output of a
SELECT query to the PARQUET, ORC, AVRO, and JSON formats.
For more information, see UNLOAD.
July 30, 2021
Published on 2021-07-30
Athena announces the following feature enhancements and bug fixes.
-
Dynamic filtering and partition pruning – Improvements increase performance and reduce the amount of data scanned in certain queries, as in the following example.
This example assumes that
Table_Bis an unpartitioned table that has file sizes that add up to less than 20 MB. For queries like this, less data is read fromTable_Aand the query completes more quickly.SELECT * FROM Table_A JOIN Table_B ON Table_A.date = Table_B.date WHERE Table_B.column_A = "value" -
ORDER BY with LIMIT, DISTINCT with LIMIT – Performance improvements to queries that use
ORDER BYorDISTINCTfollowed by aLIMITclause. -
Amazon Glacier Deep Archive files – When Athena queries a table that contains a mix of Amazon Glacier Deep Archive files and non-Amazon Glacier files, Athena now skips the Amazon Glacier Deep Archive files for you. Previously, you were required to manually move these files from the query location or the query would fail. If you want to use Athena to query objects in Amazon Glacier Deep Archive storage, you must restore them. For more information, see Restoring an archived object in the Amazon S3 User Guide.
-
Fixed a bug in which empty files created by the CTAS
bucketed_bytable property were not encrypted correctly.
July 21, 2021
Published on 2021-07-21
With the July 2021 release of Microsoft Power BI
Desktop
Because the connector uses your existing ODBC data source name (DSN) to connect to and run queries on Athena, it requires the Athena ODBC driver. To download the latest ODBC driver, see Connect to Amazon Athena with ODBC.
For more information, see Use the Amazon Athena Power BI connector.
July 16, 2021
Published on 2021-07-16
Amazon Athena has updated its integration with Apache Hudi. Hudi is an open-source data management framework used to simplify incremental data processing in Amazon S3 data lakes. The updated integration enables you to use Athena to query Hudi 0.8.0 tables managed through Amazon EMR, Apache Spark, Apache Hive or other compatible services. In addition, Athena now supports two additional features: snapshot queries on Merge-on-Read (MoR) tables and read support on bootstrapped tables.
Apache Hudi provides record-level data processing that can help you simplify development of Change Data Capture (CDC) pipelines, comply with GDPR-driven updates and deletes, and better manage streaming data from sensors or devices that require data insertion and event updates. The 0.8.0 release makes it easier to migrate large Parquet tables to Hudi without copying data so you can query and analyze them through Athena. You can use Athena's new support for snapshot queries to have near real-time views of your streaming table updates.
To learn more about using Hudi with Athena, see Query Apache Hudi datasets.
July 8, 2021
Published on 2021-07-08
Released the ODBC 1.1.11 driver for Athena. The ODBC driver can now authenticate the connection using a JSON Web Token (JWT). On Linux, the default value for the Workgroup property has been set to Primary.
For more information and to download the new driver, release notes, and documentation, see Connect to Amazon Athena with ODBC.
July 1, 2021
Published on 2021-07-01
On July 1, 2021, special handling of preview workgroups ended. While
AmazonAthenaPreviewFunctionality workgroups retain their name, they no
longer have special status. You can continue to use
AmazonAthenaPreviewFunctionality workgroups to view, modify, organize,
and run queries. However, queries that use features that were formerly in preview are
now subject to standard Athena billing terms and conditions. For billing information, see
Amazon Athena pricing
June 23, 2021
Published on 2021-06-23
Released JDBC 2.0.23 and ODBC 1.1.10 drivers for Athena. Both drivers offer improved read performance and support EXPLAIN statements and parameterized queries.
EXPLAIN statements show the logical or distributed execution plan of a
SQL query. Parameterized queries enable the same query to be used multiple times with
different values supplied at run time.
The JDBC release also adds support for Active Directory Federation Services 2019 and a custom endpoint override option for AWS STS. The ODBC release fixes an issue with IAM profile credentials.
For more information and to download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
May 12, 2021
Published on 2021-05-12
You can now use Amazon Athena to register an AWS Glue catalog from an account other than your own. After you configure the required IAM permissions for AWS Glue, you can use Athena to run cross-account queries.
For more information, see Register a Data Catalog from another account and Configure cross-account access to AWS Glue data catalogs.
May 10, 2021
Published on 2021-05-10
Released ODBC driver version 1.1.9.1001 for Athena. This version fixes an issue with
the BrowserAzureAD authentication type when using Azure Active Directory
(AD).
To download the new drivers, release notes, and documentation, see Connect to Amazon Athena with ODBC.
May 5, 2021
Published on 2021-05-05
You can now use the Amazon Athena Vertica connector in federated queries to query Vertica data sources from Athena. For example, you can run analytical queries over a data warehouse on Vertica and a data lake in Amazon S3.
To deploy the Athena Vertica connector, visit the AthenaVerticaConnector
The Amazon Athena Vertica connector exposes several configuration options through Lambda environment variables. For information about configuration options, parameters, connection strings, deployment, and limitations, see Amazon Athena Vertica connector.
For in-depth information about using the Vertica connector, see Querying a Vertica data source in Amazon Athena using the Athena Federated Query
SDK
April 30, 2021
Published on 2021-04-30
Released drivers JDBC 2.0.21 and ODBC 1.1.9 for Athena. Both releases support SAML authentication with Azure Active Directory (AD) and SAML authentication with PingFederate. The JDBC release also supports parameterized queries. For information about parameterized queries in Athena, see Use parameterized queries.
To download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
April 29, 2021
Published on 2021-04-29
Amazon Athena announces availability of Athena engine version 2 in the China (Beijing) and China (Ningxia) Regions.
April 26, 2021
Published on 2021-04-26
Window value functions in Athena engine version 2 now support IGNORE NULLS and
RESPECT NULLS.
For more information, see Value
Functions
April 21, 2021
Published on 2021-04-21
Amazon Athena announces availability of Athena engine version 2 in the Europe (Milan) and Africa (Cape Town) Regions.
April 5, 2021
Published on 2021-04-05
EXPLAIN Statement
You can now use the EXPLAIN statement in Athena to view the execution
plan for your SQL queries.
For more information, see Using EXPLAIN and EXPLAIN ANALYZE in Athena and Understand Athena EXPLAIN statement results.
SageMaker AI Machine Learning Models in SQL Queries
Machine learning model inference with Amazon SageMaker AI is now generally available for Amazon Athena. Use machine learning models in SQL queries to simplify complex tasks such as anomaly detection, customer cohort analysis, and time-series predictions by invoking a function in a SQL query.
For more information, see Use Machine Learning (ML) with Amazon Athena.
User Defined Functions (UDF)
User defined functions (UDFs) are now generally available for Athena. Use UDFs to leverage custom functions that process records or groups of records in a single SQL query.
For more information, see Query with user defined functions.
March 30, 2021
Published on 2021-03-30
Amazon Athena announces availability of Athena engine version 2 in the Asia Pacific (Hong Kong) and Middle East (Bahrain) Regions.
March 25, 2021
Published on 2021-03-25
Amazon Athena announces availability of Athena engine version 2 in the Europe (Stockholm) Region.
March 5, 2021
Published on 2021-03-05
Amazon Athena announces availability of Athena engine version 2 in the Canada (Central), Europe (Frankfurt), and South America (São Paulo) Regions.
February 25, 2021
Published on 2021-02-25
Amazon Athena announces general availability of Athena engine version 2 in the Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Europe (London), and Europe (Paris) Regions.
Athena release notes for 2020
December 16, 2020
Published on 2020-12-16
Amazon Athena announces availability of Athena engine version 2, Athena Federated Query, and AWS PrivateLink in additional Regions.
Athena engine version 2 and Athena Federated Query
Amazon Athena announces general availability of Athena engine version 2 and Athena Federated Query in the Asia Pacific (Mumbai), Asia Pacific (Tokyo), Europe (Ireland), and US West (N. California) Regions. Athena engine version 2 and federated queries are already available in the US East (N. Virginia), US East (Ohio), and US West (Oregon) Regions.
AWS PrivateLink
AWS PrivateLink for Athena is now supported in the Europe (Stockholm) Region. For information about AWS PrivateLink for Athena, see Connect to Amazon Athena using an interface VPC endpoint.
November 24, 2020
Published on 2020-11-24
Released drivers JDBC 2.0.16 and ODBC 1.1.6 for Athena. These releases support, at the account level, Okta Verify multifactor authentication (MFA). You can also use Okta MFA to configure SMS authentication and Google Authenticator authentication as factors.
To download the new drivers, release notes, and documentation, see Connect to Amazon Athena with JDBC and Connect to Amazon Athena with ODBC.
November 11, 2020
Published on 2020-11-11
Amazon Athena announces general availability in the US East (N. Virginia), US East (Ohio), and US West (Oregon) Regions for Athena engine version 2 and federated queries.
Athena engine version 2
Amazon Athena announces general availability of a new query engine version, Athena engine version 2, in the US East (N. Virginia), US East (Ohio), and US West (Oregon) Regions.
Athena engine version 2 includes performance enhancements and new feature capabilities such as schema evolution support for Parquet format data, additional geospatial functions, support for reading nested schema to reduce cost, and performance enhancements in JOIN and AGGREGATE operations.
-
For information about how to upgrade, see Change Athena engine versions.
-
For information about testing queries, see Test queries in advance of an engine version upgrade.
Federated SQL Queries
You can now use Athena's federated query in the US East (N. Virginia),
US East (Ohio), and US West (Oregon) Regions without using the
AmazonAthenaPreviewFunctionality workgroup.
Use Federated SQL queries to run SQL queries across relational, non-relational, object, and custom data sources. With federated querying, you can submit a single SQL query that scans data from multiple sources running on premises or hosted in the cloud.
Running analytics on data spread across applications can be complex and time consuming for the following reasons:
-
Data required for analytics is often spread across relational, key-value, document, in-memory, search, graph, object, time-series and ledger data stores.
-
To analyze data across these sources, analysts build complex pipelines to extract, transform, and load into a data warehouse so that the data can be queried.
-
Accessing data from various sources requires learning new programming languages and data access constructs.
Federated SQL queries in Athena eliminate this complexity by allowing users to
query the data in-place from wherever it resides. Analysts can use familiar SQL
constructs to JOIN data across multiple data sources for quick
analysis, and store results in Amazon S3 for subsequent use.
Data Source Connectors
To process federated queries, Athena uses Athena Data Source Connectors that run
on AWS Lambda
Custom Data Source Connectors
Using Athena Query Federation SDK
Next Steps
-
To learn more about the federated query feature, see Use Amazon Athena Federated Query.
-
To get started with using an existing connector, see Create a data source connection.
-
To learn how to build your own data source connector using the Athena Query Federation SDK, see Example Athena Connector
on GitHub.
October 22, 2020
Published on 2020-10-22
You can now call Athena with AWS Step Functions. AWS Step Functions can control certain AWS services directly using the Amazon States Language. You can use Step Functions with Athena to start and stop query execution, get query results, run ad-hoc or scheduled data queries, and retrieve results from data lakes in Amazon S3.
For more information, see Call Athena with Step Functions in the AWS Step Functions Developer Guide.
July 29, 2020
Published on 2020-07-29
Released JDBC driver version 2.0.13. This release supports using multiple data catalogs registered with Athena, Okta service for authentication, and connections to VPC endpoints.
To download and use the new version of the driver, see Connect to Amazon Athena with JDBC.
July 9, 2020
Published on 2020-07-09
Amazon Athena adds support for querying compacted Hudi datasets and adds the CloudFormation
AWS::Athena::DataCatalog resource for creating, updating, or deleting
data catalogs that you register in Athena.
Querying Apache Hudi Datasets
Apache Hudi is an open-source data management framework that simplifies incremental data processing. Amazon Athena now supports querying the read-optimized view of an Apache Hudi dataset in your Amazon S3-based data lake.
For more information, see Query Apache Hudi datasets.
CloudFormation Data Catalog Resource
To use Amazon Athena's federated query
feature to query any data source, you must first register your data
catalog in Athena. You can now use the CloudFormation AWS::Athena::DataCatalog
resource to create, update, or delete data catalogs that you register in
Athena.
For more information, see AWS::Athena::DataCatalog in the CloudFormation User Guide.
June 1, 2020
Published on 2020-06-01
Using Apache Hive Metastore as a Metacatalog with Amazon Athena
You can now connect Athena to one or more Apache Hive metastores in addition to the AWS Glue Data Catalog with Athena.
To connect to a self-hosted Hive metastore, you need an Athena Hive metastore connector. Athena provides a reference implementation connector that you can use. The connector runs as an AWS Lambda function in your account.
For more information, see Use an external Hive metastore.
May 21, 2020
Published on 2020-05-21
Amazon Athena adds support for partition projection. Use partition projection to speed up query processing of highly partitioned tables and automate partition management. For more information, see Use partition projection with Amazon Athena.
April 1, 2020
Published on 2020-04-01
In addition to the US East (N. Virginia) Region, the Amazon Athena federated query, user defined functions (UDFs), machine learning inference, and external Hive metastore features are now available in preview in the Asia Pacific (Mumbai), Europe (Ireland), and US West (Oregon) Regions.
March 11, 2020
Published on 2020-03-11
Amazon Athena now publishes Amazon EventBridge events for query state transitions. When a query transitions between states -- for example, from Running to a terminal state such as Succeeded or Cancelled -- Athena publishes a query state change event to EventBridge. The event contains information about the query state transition. For more information, see Monitor Athena query events with EventBridge.
March 6, 2020
Published on 2020-03-06
You can now create and update Amazon Athena workgroups by using the CloudFormation
AWS::Athena::WorkGroup resource. For more information, see AWS::Athena::WorkGroup in the CloudFormation User Guide.
Athena release notes for 2019
November 26, 2019
Published on 2019-12-17
Amazon Athena adds support for running SQL queries across relational, non-relational, object, and custom data sources, invoking machine learning models in SQL queries, User Defined Functions (UDFs) (Preview), using Apache Hive Metastore as a metadata catalog with Amazon Athena (Preview), and four additional query-related metrics.
Federated SQL Queries
Use Federated SQL queries to run SQL queries across relational, non-relational, object, and custom data sources.
You can now use Athena's federated query to scan data stored in relational, non-relational, object, and custom data sources. With federated querying, you can submit a single SQL query that scans data from multiple sources running on premises or hosted in the cloud.
Running analytics on data spread across applications can be complex and time consuming for the following reasons:
-
Data required for analytics is often spread across relational, key-value, document, in-memory, search, graph, object, time-series and ledger data stores.
-
To analyze data across these sources, analysts build complex pipelines to extract, transform, and load into a data warehouse so that the data can be queried.
-
Accessing data from various sources requires learning new programming languages and data access constructs.
Federated SQL queries in Athena eliminate this complexity by allowing users to
query the data in-place from wherever it resides. Analysts can use familiar SQL
constructs to JOIN data across multiple data sources for quick
analysis, and store results in Amazon S3 for subsequent use.
Data Source Connectors
Athena processes federated queries using Athena Data Source Connectors that run
on AWS Lambda
Custom Data Source Connectors
Using Athena Query Federation SDK
Preview Availability
Athena federated query is available in preview in the US East (N. Virginia) Region.
Next Steps
-
To begin your preview, follow the instructions in the Athena Preview Features FAQ
. -
To learn more about the federated query feature, see Using Amazon Athena Federated Query (Preview).
-
To get started with using an existing connector, see Create a data source connection.
-
To learn how to build your own data source connector using the Athena Query Federation SDK, see Example Athena Connector
on GitHub.
Invoking Machine Learning Models in SQL Queries
You can now invoke machine learning models for inference directly from your Athena queries. The ability to use machine learning models in SQL queries makes complex tasks such anomaly detection, customer cohort analysis, and sales predictions as simple as invoking a function in a SQL query.
ML Models
You can use more than a dozen built-in machine learning algorithms provided by
Amazon SageMaker
Preview Availability
Athena's ML functionality is available today in preview in the US East (N. Virginia) Region.
Next Steps
-
To begin your preview, follow the instructions in the Athena Preview Features FAQ
. -
To learn more about the machine learning feature, see Using Machine Learning (ML) with Amazon Athena (Preview).
User Defined Functions (UDFs) (Preview)
You can now write custom scalar functions and invoke them in your Athena queries.
You can write your UDFs in Java using the Athena
Query Federation SDKSELECT and
FILTER clauses of a SQL query. You can invoke multiple UDFs in the
same query.
Preview Availability
Athena UDF functionality is available in Preview mode in the US East (N. Virginia) Region.
Next Steps
-
To begin your preview, follow the instructions in the Athena Preview Features FAQ
. -
To learn more, see Querying with User Defined Functions (Preview).
-
For example UDF implementations, see Amazon Athena UDF Connector
on GitHub. -
To learn how to write your own functions using the Athena Query Federation SDK, see Creating and Deploying a UDF Using Lambda.
Using Apache Hive Metastore as a Metacatalog with Amazon Athena (Preview)
You can now connect Athena to one or more Apache Hive Metastores in addition to the AWS Glue Data Catalog with Athena.
Metastore Connector
To connect to a self-hosted Hive Metastore, you need an Athena Hive Metastore
connector. Athena provides a reference
Preview Availability
The Hive Metastore feature is available in Preview mode in the US East (N. Virginia) Region.
Next Steps
-
To begin your preview, follow the instructions in the Athena Preview Features FAQ
. -
To learn more about this feature, please visit our Using Athena Data Connector for External Hive Metastore (Preview).
New Query-Related Metrics
Athena now publishes additional query metrics that can help you understand Amazon Athena
-
Query Planning Time – The time taken to plan the query. This includes the time spent retrieving table partitions from the data source.
-
Query Queuing Time – The time that the query was in a queue waiting for resources.
-
Service Processing Time – The time taken to write results after the query engine finishes processing.
-
Total Execution Time – The time Athena took to run the query.
To consume these new query metrics, you can create custom dashboards, set alarms and triggers on metrics in CloudWatch, or use pre-populated dashboards directly from the Athena console.
Next Steps
For more information, see Monitoring Athena Queries with CloudWatch Metrics.
November 12, 2019
Published on 2019-12-17
Amazon Athena is now available in the Middle East (Bahrain) Region.
November 8, 2019
Published on 2019-12-17
Amazon Athena is now available in the US West (N. California) Region and the Europe (Paris) Region.
October 8, 2019
Published on 2019-12-17
Amazon Athena
To create an interface VPC endpoint to connect to Athena, you can use the AWS Management Console or AWS Command Line Interface (AWS CLI). For information about creating an interface endpoint, see Creating an Interface Endpoint.
When you use an interface VPC endpoint, communication between your VPC and Athena APIs
is secure and stays within the AWS network. There are no additional Athena costs to use
this feature. Interface VPC endpoint charges
To learn more about this feature, see Connect to Amazon Athena Using an Interface VPC Endpoint.
September 19, 2019
Published on 2019-12-17
Amazon Athena adds support for inserting new data to an existing table using the
INSERT INTO statement. You can insert new rows into a destination table
based on a SELECT query statement that runs on a source table, or based on
a set of values that are provided as part of the query statement. Supported data formats
include Avro, JSON, ORC, Parquet, and text files.
INSERT INTO statements can also help you simplify your ETL process. For
example, you can use INSERT INTO in a single query to select data from a
source table that is in JSON format and write to a destination table in Parquet
format.
INSERT INTO statements are charged based on the number of bytes that are
scanned in the SELECT phase, similar to how Athena charges for
SELECT queries. For more information, see Amazon Athena pricing
For more information about using INSERT INTO, including supported
formats, SerDes and examples, see INSERT
INTO in the Athena User Guide.
September 12, 2019
Published on 2019-12-17
Amazon Athena is now available in the Asia Pacific (Hong Kong) Region.
August 16, 2019
Published on 2019-12-17
Amazon Athena
When an Amazon S3 bucket is configured as Requester Pays, the requester, not the bucket owner, pays for the Amazon S3 request and data transfer costs. In Athena, workgroup administrators can now configure workgroup settings to allow workgroup members to query S3 Requester Pays buckets.
For information about how to configure the Requester Pays setting for your workgroup, refer to Create a Workgroup in the Amazon Athena User Guide. For more information about Requester Pays buckets, see Requester Pays Buckets in the Amazon Simple Storage Service Developer Guide.
August 9, 2019
Published on 2019-12-17
Amazon Athena now supports enforcing AWS Lake Formation
You can use this feature in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland). There are no additional charges to use this feature.
For more information about using this feature, see Use Athena to query data registered with AWS Lake Formation. For more information about
AWS Lake Formation, see AWS Lake Formation
June 26, 2019
Amazon Athena is now available in the Europe (Stockholm) Region. For a list of supported Regions, see AWS Regions and Endpoints.
May 24, 2019
Published on 2019-05-24
Amazon Athena is now available in the AWS GovCloud (US-East) and AWS GovCloud (US-West) Regions. For a list of supported Regions, see AWS Regions and Endpoints.
March 05, 2019
Published on 2019-03-05
Amazon Athena is now available in the Canada (Central) Region. For a list of
supported Regions, see AWS Regions and
Endpoints. Released the new version of the ODBC driver with support for
Athena workgroups. For more information, see the ODBC Driver Release Notes
To download the ODBC driver version 1.0.5 and its
documentation, see Connect to Amazon Athena with ODBC. For information about this version, see the ODBC
Driver Release Notes
To use workgroups with the ODBC driver, set the new connection property,
Workgroup, in the connection string as shown in the following
example:
Driver=Simba Athena ODBC Driver;AwsRegion=[Region];S3OutputLocation=[S3Path];AuthenticationType=IAM Credentials;UID=[YourAccessKey];PWD=[YourSecretKey];Workgroup=[WorkgroupName]
For more information, search for "workgroup" in the
ODBC Driver Installation and Configuration Guide version 1.0.5
This driver version lets you use Athena API workgroup actions to create and manage workgroups, and Athena API tag actions to add, list, or remove tags on workgroups. Before you begin, make sure that you have resource-level permissions in IAM for actions on workgroups and tags.
For more information, see:
If you use the JDBC driver or the AWS SDK, upgrade to the latest version of the driver and SDK, both of which already include support for workgroups and tags in Athena. For more information, see Connect to Amazon Athena with JDBC.
February 22, 2019
Published on 2019-02-22
Added tag support for workgroups in Amazon Athena. A tag consists of a key and a value, both of which you define. When you tag a workgroup, you assign custom metadata to it. You can add tags to workgroups to help categorize them, using AWS tagging best practices. You can use tags to restrict access to workgroups, and to track costs. For example, create a workgroup for each cost center. Then, by adding tags to these workgroups, you can track your Athena spending for each cost center. For more information, see Using Tags for Billing in the AWS Billing and Cost Management User Guide.
You can work with tags by using the Athena console or the API operations. For more information, see Tag Athena resources.
In the Athena console, you can add one or more tags to each of your workgroups, and
search by tags. Workgroups are an IAM-controlled resource in Athena. In IAM, you can
restrict who can add, remove, or list tags on workgroups that you create. You can also
use the CreateWorkGroup API operation that has the optional tag parameter
for adding one or more tags to the workgroup. To add, remove, or list tags, use
TagResource, UntagResource, and
ListTagsForResource. For more information, see Use API and AWS CLI tag operations.
To allow users to add tags when creating workgroups, ensure that you give each user
IAM permissions to both the TagResource and CreateWorkGroup
API actions. For more information and examples, see Use tag-based IAM access control policies.
There are no changes to the JDBC driver when you use tags on workgroups. If you create new workgroups and use the JDBC driver or the AWS SDK, upgrade to the latest version of the driver and SDK. For information, see Connect to Amazon Athena with JDBC.
February 18, 2019
Published on 2019-02-18
Added ability to control query costs by running queries in workgroups. For
information, see Use workgroups to control query access and costs. Improved the JSON OpenX
SerDe used in Athena, fixed an issue where Athena did not ignore objects transitioned to
the GLACIER storage class, and added examples for querying Network Load Balancer
logs.
Made the following changes:
-
Added support for workgroups. Use workgroups to separate users, teams, applications, or workloads, and to set limits on amount of data each query or the entire workgroup can process. Because workgroups act as IAM resources, you can use resource-level permissions to control access to a specific workgroup. You can also view query-related metrics in Amazon CloudWatch, control query costs by configuring limits on the amount of data scanned, create thresholds, and trigger actions, such as Amazon SNS alarms, when these thresholds are breached. For more information, see Use workgroups to control query access and costs and Use CloudWatch and EventBridge to monitor queries and control costs.
Workgroups are an IAM resource. For a full list of workgroup-related actions, resources, and conditions in IAM, see Actions, Resources, and Condition Keys for Amazon Athena in the Service Authorization Reference. Before you create new workgroups, make sure that you use workgroup IAM policies, and the AWS managed policy: AmazonAthenaFullAccess.
You can use workgroups in the console, with workgroup API operations, or with the JDBC driver. For information about creating workgroups, see Create a workgroup. To download the JDBC driver with workgroup support, see Connect to Amazon Athena with JDBC.
If you use workgroups with the JDBC driver, you must set the workgroup name in the connection string using the
Workgroupconfiguration parameter as in the following example:jdbc:awsathena://AwsRegion=<AWSREGION>;UID=<ACCESSKEY>; PWD=<SECRETKEY>;S3OutputLocation=s3://amzn-s3-demo-bucket/<athena-output>-<AWSREGION>/; Workgroup=<WORKGROUPNAME>;There are no changes in the way you run SQL statements or make JDBC API calls to the driver. The driver passes the workgroup name to Athena.
For information about differences introduced with workgroups, see Use Athena workgroup APIs and Troubleshoot workgroup errors.
-
Improved the JSON OpenX SerDe used in Athena. The improvements include, but are not limited to, the following:
-
Support for the
ConvertDotsInJsonKeysToUnderscoresproperty. When set toTRUE, it allows the SerDe to replace the dots in key names with underscores. For example, if the JSON dataset contains a key with the name"a.b", you can use this property to define the column name to be"a_b"in Athena. The default isFALSE. By default, Athena does not allow dots in column names. -
Support for the
case.insensitiveproperty. By default, Athena requires that all keys in your JSON dataset use lowercase. UsingWITH SERDE PROPERTIES ("case.insensitive"= FALSE;)allows you to use case-sensitive key names in your data. The default isTRUE. When set toTRUE, the SerDe converts all uppercase columns to lowercase.
For more information, see OpenX JSON SerDe.
-
-
Fixed an issue where Athena returned
"access denied"error messages, when it processed Amazon S3 objects that were archived to Glacier by Amazon S3 lifecycle policies. As a result of fixing this issue, Athena ignores objects transitioned to theGLACIERstorage class. Athena does not support querying data from theGLACIERstorage class.For more information, see Amazon S3 considerations and Transitioning to the GLACIER Storage Class (Object Archival) in the Amazon Simple Storage Service User Guide.
-
Added examples for querying Network Load Balancer access logs that receive information about the Transport Layer Security (TLS) requests. For more information, see Query Network Load Balancer logs.
Athena release notes for 2018
November 20, 2018
Published on 2018-11-20
Released the new versions of the JDBC and ODBC driver with support for federated
access to Athena API with the AD FS and SAML 2.0 (Security Assertion Markup Language
2.0). For details, see the JDBC Driver Release Notes
With this release, federated access to Athena is supported for the Active Directory Federation Service (AD FS 3.0). Access is established through the versions of JDBC or ODBC drivers that support SAML 2.0. For information about configuring federated access to the Athena API, see Enable federated access to the Athena API.
To download the JDBC driver version 2.0.6 and its
documentation, see Connect to Amazon Athena with JDBC. For information about this version, see JDBC Driver Release Notes
To download the ODBC driver version 1.0.4 and its
documentation, see Connect to Amazon Athena with ODBC. For information about this version, ODBC Driver Release Notes
For more information about SAML 2.0 support in AWS, see About SAML 2.0 Federation in the IAM User Guide.
October 15, 2018
Published on 2018-10-15
If you have upgraded to the AWS Glue Data Catalog, there are two new features that provide support for:
-
Encryption of the Data Catalog metadata. If you choose to encrypt metadata in the Data Catalog, you must add specific policies to Athena. For more information, see Access to Encrypted Metadata in the AWS Glue Data Catalog.
-
Fine-grained permissions to access resources in the AWS Glue Data Catalog. You can now define identity-based (IAM) policies that restrict or allow access to specific databases and tables from the Data Catalog used in Athena. For more information, see Configure access to databases and tables in the AWS Glue Data Catalog.
Note
Data resides in the Amazon S3 buckets, and access to it is controlled by Control access to Amazon S3 from Athena. To access data in databases and tables, continue to use access control policies to Amazon S3 buckets that store the data.
October 10, 2018
Published on 2018-10-10
Athena supports CREATE TABLE AS SELECT, which creates a table from the
result of a SELECT query statement. For details, see Creating a Table from
Query Results (CTAS).
Before you create CTAS queries, it is important to learn about their behavior in the Athena documentation. It contains information about the location for saving query results in Amazon S3, the list of supported formats for storing CTAS query results, the number of partitions you can create, and supported compression formats. For more information, see Considerations and limitations for CTAS queries.
Use CTAS queries to:
-
Create a table from query results in one step.
-
Create CTAS queries in the Athena console, using Examples. For information about syntax, see CREATE TABLE AS.
-
Transform query results into other storage formats, such as PARQUET, ORC, AVRO, JSON, and TEXTFILE. For more information, see Considerations and limitations for CTAS queries and Use columnar storage formats.
September 6, 2018
Published on 2018-09-06
Released the new version of the ODBC driver (version 1.0.3). The new version of the
ODBC driver streams results by default, instead of paging through them, allowing
business intelligence tools to retrieve large data sets faster. This version also
includes improvements, bug fixes, and an updated documentation for "Using SSL
with a Proxy Server". For details, see
the Release Notes
For downloading the ODBC driver version 1.0.3 and its documentation, see Connect to Amazon Athena with ODBC.
The streaming results feature is available with this new version of the ODBC driver.
It is also available with the JDBC driver. For
information about streaming results, see the ODBC Driver Installation and Configuration Guide
The ODBC driver version 1.0.3 is a drop-in replacement for the previous version of the driver. We recommend that you migrate to the current driver.
Important
To use the ODBC driver version 1.0.3, follow these requirements:
-
Keep the port 444 open to outbound traffic.
-
Add the
athena:GetQueryResultsStreampolicy action to the list of policies for Athena. This policy action is not exposed directly with the API and is only used with the ODBC and JDBC drivers, as part of streaming results support. For an example policy, see AWS managed policy: AWSQuicksightAthenaAccess.
August 23, 2018
Published on 2018-08-23
Added support for these DDL-related features and fixed several bugs, as follows:
-
Added support for
BINARYandDATEdata types for data in Parquet, and forDATEandTIMESTAMPdata types for data in Avro. -
Added support for
INTandDOUBLEin DDL queries.INTEGERis an alias toINT, andDOUBLE PRECISIONis an alias toDOUBLE. -
Improved performance of
DROP TABLEandDROP DATABASEqueries. -
Removed the creation of
_$folder$object in Amazon S3 when a data bucket is empty. -
Fixed an issue where
ALTER TABLE ADD PARTITIONthrew an error when no partition value was provided. -
Fixed an issue where
DROP TABLEignored the database name when checking partitions after the qualified name had been specified in the statement.
For more about the data types supported in Athena, see Data types in Amazon Athena.
For information about supported data type mappings between
types in Athena, the JDBC driver, and Java data types, see the "Data
Types" section in the JDBC Driver Installation and Configuration Guide
August 16, 2018
Published on 2018-08-16
Released the JDBC driver version 2.0.5. The new version of the JDBC driver streams results by default, instead of paging through them, allowing business intelligence tools to retrieve large data sets faster. Compared to the previous version of the JDBC driver, there are the following performance improvements:
-
Approximately 2x performance increase when fetching less than 10K rows.
-
Approximately 5-6x performance increase when fetching more than 10K rows.
The streaming results feature is available only with the JDBC driver. It is not
available with the ODBC driver. You cannot use it with the Athena API. For information about streaming results, see the JDBC Driver Installation and Configuration Guide
For downloading the JDBC driver version 2.0.5 and its documentation, see Connect to Amazon Athena with JDBC.
The JDBC driver version 2.0.5 is a drop-in replacement for the previous version of the
driver (2.0.2). To ensure that you can use the JDBC driver version 2.0.5, add the
athena:GetQueryResultsStream policy action to the list of policies for
Athena. This policy action is not exposed directly with the API and is only used with the
JDBC driver, as part of streaming results support. For an example policy, see AWS managed policy: AWSQuicksightAthenaAccess. For more information about migrating from version 2.0.2 to
version 2.0.5 of the driver, see the JDBC Driver Migration Guide
If you are migrating from a 1.x driver to a 2.x driver, you will need to migrate your
existing configurations to the new configuration. We highly recommend that you migrate
to the current version of the driver. For more information, see the JDBC Driver Migration Guide
August 7, 2018
Published on 2018-08-07
You can now store Amazon Virtual Private Cloud flow logs directly in Amazon S3 in a GZIP format, where you can
query them in Athena. For information, see Query Amazon VPC flow logs and Amazon VPC Flow Logs can now be delivered to S3
June 5, 2018
Published on 2018-06-05
Support for Views
Added support for views. You can now use CREATE VIEW and CREATE PROTECTED MULTI DIALECT VIEW, DESCRIBE VIEW, DROP VIEW, SHOW CREATE VIEW, and SHOW VIEWS in Athena. The query that defines the view runs each time you reference the view in your query. For more information, see Work with views.
Improvements and Updates to Error Messages
-
Included a GSON 2.8.0 library into the CloudTrail SerDe, to solve an issue with the CloudTrail SerDe and enable parsing of JSON strings.
-
Enhanced partition schema validation in Athena for Parquet, and, in some cases, for ORC, by allowing reordering of columns. This enables Athena to better deal with changes in schema evolution over time, and with tables added by the AWS Glue Crawler. For more information, see Handle schema updates.
-
Added parsing support for
SHOW VIEWS. -
Made the following improvements to most common error messages:
-
Replaced an
Internal Errormessage with a descriptive error message when a SerDe fails to parse the column in an Athena query. Previously, Athena issued an internal error in cases of parsing errors. The new error message reads:"HIVE_BAD_DATA: Error parsing field value for field 0: java.lang.String cannot be cast to org.openx.data.jsonserde.json.JSONObject". -
Improved error messages about insufficient permissions by adding more detail.
-
Bug Fixes
Fixed the following bugs:
-
Fixed an issue that enables the internal translation of
REALtoFLOATdata types. This improves integration with the AWS Glue crawler that returnsFLOATdata types. -
Fixed an issue where Athena was not converting AVRO
DECIMAL(a logical type) to aDECIMALtype. -
Fixed an issue where Athena did not return results for queries on Parquet data with
WHEREclauses that referenced values in theTIMESTAMPdata type.
May 17, 2018
Published on 2018-05-17
Increased query concurrency quota in Athena from five to twenty. This means that you
can submit and run up to twenty DDL queries and twenty SELECT
queries at a time. Note that the concurrency quotas are separate for DDL
and SELECT queries.
Concurrency quotas in Athena are defined as the number of queries that can be submitted
to the service concurrently. You can submit up to twenty queries of the same type
(DDL or SELECT) at a time. If you submit a query that
exceeds the concurrent query quota, the Athena API displays an error message.
After you submit your queries to Athena, it processes the queries by assigning resources based on the overall service load and the amount of incoming requests. We continuously monitor and make adjustments to the service so that your queries process as fast as possible.
For information, see Service Quotas.
This is an adjustable quota. You can use the Service Quotas console
April 19, 2018
Published on 2018-04-19
Released the new version of the JDBC driver (version 2.0.2) with support for returning
the ResultSet data as an Array data type, improvements, and bug fixes.
For details, see the Release Notes
For information about downloading the new JDBC driver version 2.0.2 and its documentation, see Connect to Amazon Athena with JDBC.
The latest version of the JDBC driver is 2.0.2. If you are migrating from a 1.x driver to a 2.x driver, you will need to migrate your existing configurations to the new configuration. We highly recommend that you migrate to the current driver.
For information about the changes introduced in the new
version of the driver, the version differences, and examples, see the JDBC Driver Migration Guide
April 6, 2018
Published on 2018-04-06
Use auto-complete to type queries in the Athena console.
March 15, 2018
Published on 2018-03-15
Added an ability to automatically create Athena tables for CloudTrail log files directly from the CloudTrail console. For information, see Use the CloudTrail console to create an Athena table for CloudTrail logs.
February 2, 2018
Published on 2018-02-12
Added an ability to securely offload intermediate data to disk for memory-intensive
queries that use the GROUP BY clause. This improves the reliability of such
queries, preventing "Query resource exhausted" errors.
January 19, 2018
Published on 2018-01-19
Athena uses Presto, an open-source distributed query engine, to run queries.
With Athena, there are no versions to manage. We have transparently upgraded the underlying engine in Athena to a version based on Presto version 0.172. No action is required on your end.
With the upgrade, you can now use Presto 0.172 Functions and Operators, including Presto 0.172 Lambda Expressions in Athena.
Major updates for this release, including the community-contributed fixes, include:
-
Support for ignoring headers. You can use the
skip.header.line.countproperty when defining tables, to allow Athena to ignore headers. This is supported for queries that use the LazySimpleSerDe and OpenCSV SerDe, and not for Grok or Regex SerDes. -
Support for the
CHAR(n)data type inSTRINGfunctions. The range forCHAR(n)is[1.255], while the range forVARCHAR(n)is[1,65535]. -
Support for correlated subqueries.
-
Support for Presto Lambda expressions and functions.
-
Improved performance of the
DECIMALtype and operators. -
Support for filtered aggregations, such as
SELECT sum(col_name) FILTER, whereid > 0. -
Push-down predicates for the
DECIMAL,TINYINT,SMALLINT, andREALdata types. -
Support for quantified comparison predicates:
ALL,ANY, andSOME. -
Added functions:
arrays_overlap(), array_except(), levenshtein_distance(), codepoint(), skewness(), kurtosis(), and typeof(). -
Added a variant of the
from_unixtime()function that takes a timezone argument. -
Added the
bitwise_and_agg()and bitwise_or_agg()aggregation functions. -
Added the
xxhash64()and to_big_endian_64()functions. -
Added support for escaping double quotes or backslashes using a backslash with a JSON path subscript to the
json_extract()and json_extract_scalar()functions. This changes the semantics of any invocation using a backslash, as backslashes were previously treated as normal characters.
For more information about functions and operators, see DML queries, functions, and operators in this guide, and Functions and
operators
Athena does not support all of Presto's features. For more information, see Limitations.
Athena release notes for 2017
November 13, 2017
Published on 2017-11-13
Added support for connecting Athena to the ODBC Driver. For information, see Connect to Amazon Athena with ODBC.
November 1, 2017
Published on 2017-11-01
Added support for querying geospatial data, and for Asia Pacific (Seoul), Asia Pacific (Mumbai), and EU (London) regions. For information, see Query geospatial data and AWS Regions and Endpoints.
October 19, 2017
Published on 2017-10-19
Added support for EU (Frankfurt). For a list of supported regions, see AWS Regions and Endpoints.
October 3, 2017
Published on 2017-10-03
Create named Athena queries with CloudFormation. For more information, see AWS::Athena::NamedQuery in the AWS CloudFormation User Guide.
September 25, 2017
Published on 2017-09-25
Added support for Asia Pacific (Sydney). For a list of supported regions, see AWS Regions and Endpoints.
August 14, 2017
Published on 2017-08-14
Added integration with the AWS Glue Data Catalog and a migration wizard for updating from the Athena managed data catalog to the AWS Glue Data Catalog. For more information, see Use AWS Glue Data Catalog to connect to your data.
August 4, 2017
Published on 2017-08-04
Added support for Grok SerDe, which provides easier pattern matching for records in unstructured text files such as logs. For more information, see Grok SerDe. Added keyboard shortcuts to scroll through query history using the console (CTRL + ⇧/⇩ using Windows, CMD + ⇧/⇩ using Mac).
June 22, 2017
Published on 2017-06-22
Added support for Asia Pacific (Tokyo) and Asia Pacific (Singapore). For a list of supported regions, see AWS Regions and Endpoints.
June 8, 2017
Published on 2017-06-08
Added support for Europe (Ireland). For more information, see AWS Regions and Endpoints.
May 19, 2017
Published on 2017-05-19
Added an Amazon Athena API and AWS CLI support for Athena; updated JDBC driver to version 1.1.0; fixed various issues.
-
Amazon Athena enables application programming for Athena. For more information, see Amazon Athena API Reference. The latest AWS SDKs include support for the Athena API. For links to documentation and downloads, see the SDKs section in Tools for Amazon Web Services
. -
The AWS CLI includes new commands for Athena. For more information, see the Amazon Athena API Reference.
-
A new JDBC driver 1.1.0 is available, which supports the new Athena API as well as the latest features and bug fixes. Download the driver at https://downloads.athena.us-east-1.amazonaws.com/drivers/AthenaJDBC41-1.1.0.jar
. We recommend upgrading to the latest Athena JDBC driver; however, you may still use the earlier driver version. Earlier driver versions do not support the Athena API. For more information, see Connect to Amazon Athena with JDBC. -
Actions specific to policy statements in earlier versions of Athena have been deprecated. If you upgrade to JDBC driver version 1.1.0 and have customer-managed or inline IAM policies attached to JDBC users, you must update the IAM policies. In contrast, earlier versions of the JDBC driver do not support the Athena API, so you can specify only deprecated actions in policies attached to earlier version JDBC users. For this reason, you shouldn't need to update customer-managed or inline IAM policies.
-
These policy-specific actions were used in Athena before the release of the Athena API. Use these deprecated actions in policies only with JDBC drivers earlier than version 1.1.0. If you are upgrading the JDBC driver, replace policy statements that allow or deny deprecated actions with the appropriate API actions as listed or errors will occur:
| Deprecated Policy-Specific Action | Corresponding Athena API Action |
|---|---|
|
|
|
|
|
|
Improvements
-
Increased the query string length limit to 256 KB.
Bug Fixes
-
Fixed an issue that caused query results to look malformed when scrolling through results in the console.
-
Fixed an issue where a
\u0000character string in Amazon S3 data files would cause errors. -
Fixed an issue that caused requests to cancel a query made through the JDBC driver to fail.
-
Fixed an issue that caused the AWS CloudTrail SerDe to fail with Amazon S3 data in US East (Ohio).
-
Fixed an issue that caused
DROP TABLEto fail on a partitioned table.
April 4, 2017
Published on 2017-04-04
Added support for Amazon S3 data encryption and released JDBC driver update (version 1.0.1) with encryption support, improvements, and bug fixes.
Features
-
Added the following encryption features:
-
Support for querying encrypted data in Amazon S3.
-
Support for encrypting Athena query results.
-
-
A new version of the driver supports new encryption features, adds improvements, and fixes issues.
-
Added the ability to add, replace, and change columns using
ALTER TABLE. For more information, see Alter Columnin the Hive documentation. -
Added support for querying LZO-compressed data.
For more information, see Encryption at rest.
Improvements
-
Better JDBC query performance with page-size improvements, returning 1,000 rows instead of 100.
-
Added ability to cancel a query using the JDBC driver interface.
-
Added ability to specify JDBC options in the JDBC connection URL. See Connect to Amazon Athena with JDBC for the most current JDBC driver.
-
Added PROXY setting in the driver, which can now be set using ClientConfiguration in the AWS SDK for Java.
Bug Fixes
Fixed the following bugs:
-
Throttling errors would occur when multiple queries were issued using the JDBC driver interface.
-
The JDBC driver would stop when projecting a decimal data type.
-
The JDBC driver would return every data type as a string, regardless of how the data type was defined in the table. For example, selecting a column defined as an
INTdata type usingresultSet.GetObject()would return aSTRINGdata type instead ofINT. -
The JDBC driver would verify credentials at the time a connection was made, rather than at the time a query would run.
-
Queries made through the JDBC driver would fail when a schema was specified along with the URL.
March 24, 2017
Published on 2017-03-24
Added the AWS CloudTrail SerDe, improved performance, fixed partition issues.
Features
-
Added the AWS CloudTrail SerDe, which has since been superseded by the Hive JSON SerDe for reading CloudTrail logs. For information about querying CloudTrail logs, see Query AWS CloudTrail logs.
Improvements
-
Improved performance when scanning a large number of partitions.
-
Improved performance on
MSCK Repair Tableoperation. -
Added ability to query Amazon S3 data stored in regions other than your primary Region. Standard inter-region data transfer rates for Amazon S3 apply in addition to standard Athena charges.
Bug Fixes
-
Fixed a bug where a "table not found error" might occur if no partitions are loaded.
-
Fixed a bug to avoid throwing an exception with
ALTER TABLE ADD PARTITION IF NOT EXISTSqueries. -
Fixed a bug in
DROP PARTITIONS.
February 20, 2017
Published on 2017-02-20
Added support for AvroSerDe and OpenCSVSerDe, US East (Ohio) Region, and bulk editing columns in the console wizard. Improved performance on large Parquet tables.
Features
-
Introduced support for new SerDes:
-
US East (Ohio) Region (us-east-2) launch. You can now run queries in this region.
-
You can now use the Create Table From S3 bucket data form to define table schema in bulk. In the query editor, choose Create, S3 bucket data, and then choose Bulk add columns in the Column details section.
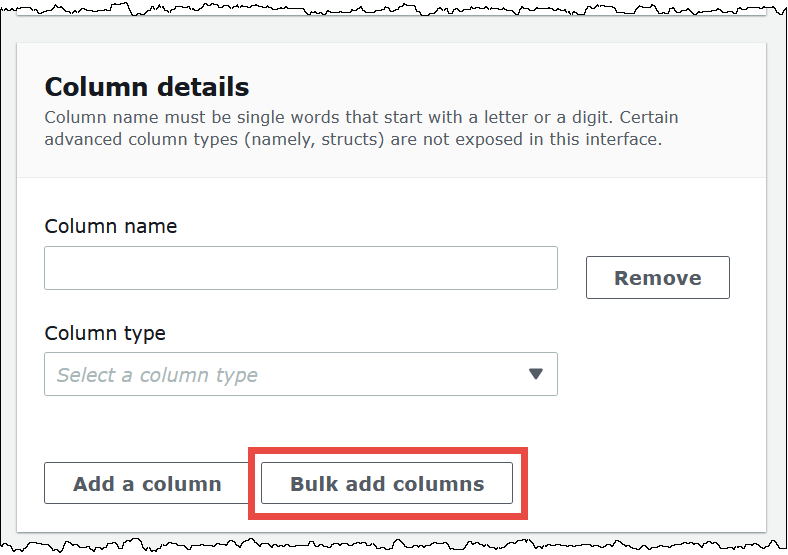
Type name value pairs in the text box and choose Add.
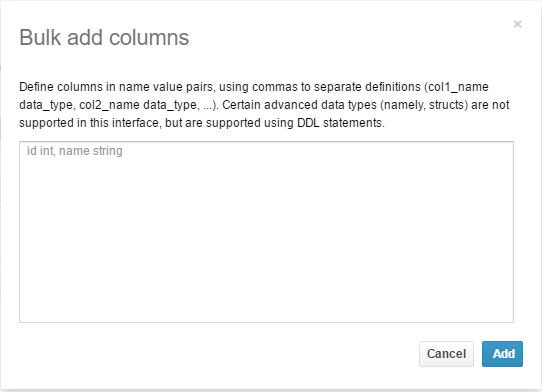
Improvements
-
Improved performance on large Parquet tables.
