Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Auto Scaling Scaling-Gruppenempfehlungen anzeigen
AWS Compute Optimizer generiert Instance-Typ-Empfehlungen für Amazon EC2 Auto Scaling (Auto Scaling) -Gruppen. Empfehlungen für Ihre Auto Scaling Scaling-Gruppen werden auf den folgenden Seiten der AWS Compute Optimizer Konsole angezeigt:
-
Auf der Seite mit den Empfehlungen für Auto Scaling Scaling-Gruppen werden alle Ihre aktuellen Auto Scaling Scaling-Gruppen, ihre Suchklassifizierungen, der aktuelle Instance-Typ, der aktuelle Stundenpreis für die ausgewählte Kaufoption und die aktuelle Konfiguration aufgeführt. Die Top-Empfehlung von Compute Optimizer ist neben jeder Ihrer Auto Scaling Scaling-Gruppen aufgeführt und beinhaltet den empfohlenen Instance-Typ, den Stundenpreis für die ausgewählte Kaufoption und den Preisunterschied zwischen Ihrer aktuellen Instance und der Empfehlung. Verwenden Sie die Seite mit den Empfehlungen, um die aktuellen Instances Ihrer Auto Scaling Scaling-Gruppen mit ihren wichtigsten Empfehlungen zu vergleichen. Dies kann Ihnen bei der Entscheidung helfen, ob Sie Ihre Instances vergrößern oder verkleinern sollten.
-
Auf der Seite mit den Auto Scaling Scaling-Gruppendetails, auf die Sie über die Seite mit den Empfehlungen für Auto Scaling Scaling-Gruppen zugreifen können, werden bis zu drei Optimierungsempfehlungen für eine bestimmte Auto Scaling Scaling-Gruppe aufgeführt. Sie listet die Spezifikationen für jede Empfehlung, ihr Leistungsrisiko und ihre Stundenpreise für die gewählte Kaufoption auf. Auf der Detailseite werden auch Diagramme zur Nutzungsmetrik für die aktuelle Auto Scaling Scaling-Gruppe angezeigt.
Die Empfehlungen werden täglich aktualisiert. Sie werden generiert, indem die Spezifikationen und Nutzungskennzahlen der aktuellen Auto Scaling Scaling-Gruppe über einen Zeitraum der letzten 14 Tage oder länger analysiert werden, wenn Sie die kostenpflichtige Funktion für erweiterte Infrastrukturmetriken aktivieren. Weitere Informationen finden Sie unter Metriken analysiert von AWS Compute Optimizer.
Beachten Sie, dass Compute Optimizer Empfehlungen für Auto Scaling Scaling-Gruppen generiert, die bestimmte Anforderungen erfüllen. Die Generierung von Empfehlungen kann bis zu 24 Stunden dauern und es müssen ausreichend Metrikdaten gesammelt werden. Weitere Informationen finden Sie unter Voraussetzungen für die Ressourcen.
Inhalt
- Klassifizierungen finden
- AWS Instanzempfehlungen auf Basis von Graviton
- Abgeleitete Workload-Typen
- Migrationsaufwand
- Preise und Kaufoptionen
- Geschätzte monatliche Einsparungen und Sparmöglichkeiten
- Leistungsrisiko
- Aktuelles Leistungsrisiko
- Diagramme zur Auslastung
- Zugreifen auf Auto Scaling Scaling-Gruppenempfehlungen und -details
Klassifizierungen finden
Die Spalte „Ergebnisse“ auf der Seite mit den Empfehlungen für Auto Scaling Scaling-Gruppen enthält eine Zusammenfassung der Leistung der einzelnen Auto Scaling Scaling-Gruppen im analysierten Zeitraum.
Die folgenden Klassifizierungen der Ergebnisse gelten für Auto Scaling Scaling-Gruppen.
| Klassifizierung | Beschreibung |
|---|---|
|
Nicht optimiert |
Eine Auto Scaling Scaling-Gruppe gilt als nicht optimiert, wenn Compute Optimizer eine Empfehlung identifiziert hat, die zu einer besseren Leistung oder zu besseren Kosten für Ihren Workload führen kann. |
|
Optimiert |
Eine Auto Scaling Scaling-Gruppe gilt als optimiert, wenn Compute Optimizer anhand des ausgewählten Instanztyps feststellt, dass die Gruppe für die Ausführung Ihres Workloads korrekt bereitgestellt wurde. Für optimierte Auto Scaling Scaling-Gruppen empfiehlt Compute Optimizer manchmal einen Instance-Typ der neuen Generation. |
AWS Instanzempfehlungen auf Basis von Graviton
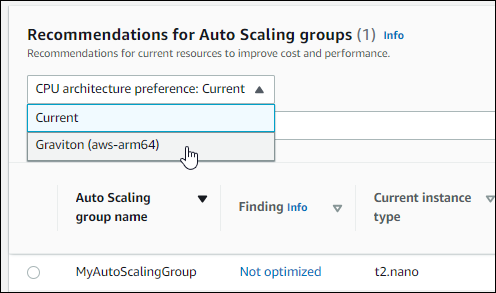
Wenn Sie sich die Auto Scaling Scaling-Gruppenempfehlungen ansehen, können Sie sehen, welche Auswirkungen die Ausführung Ihres Workloads auf AWS Graviton-basierten Instances auf Preis und Leistung hat. Wählen Sie dazu in der Dropdownliste mit den Architektureinstellungen Graviton (aws-arm64) aus. CPU Andernfalls wählen Sie Aktuell, um Empfehlungen anzuzeigen, die auf demselben CPU Anbieter und derselben Architektur wie die aktuelle Instanz basieren.
Anmerkung
Die Spalten Aktueller Preis, empfohlener Preis, Preisunterschied, Preisunterschied (%) und Geschätzte monatliche Einsparungen wurden aktualisiert, um einen Preisvergleich zwischen dem aktuellen Instance-Typ und dem Instance-Typ der ausgewählten CPU Architekturpräferenz zu ermöglichen. Wenn Sie beispielsweise Graviton (aws-arm64) wählen, werden die Preise zwischen dem aktuellen Instance-Typ und dem empfohlenen Graviton-basierten Instance-Typ verglichen.
Abgeleitete Workload-Typen
In der Spalte Abgeleitete Workload-Typen auf der Seite mit den Empfehlungen für Auto Scaling Scaling-Gruppen sind die Anwendungen aufgeführt, die möglicherweise auf Instances in der Auto Scaling Scaling-Gruppe ausgeführt werden, wie von Compute Optimizer abgeleitet. Dazu werden die Attribute der Instances in der Auto Scaling Scaling-Gruppe analysiert, z. B. der Instanzname, die Tags und die Konfiguration. Compute Optimizer kann derzeit ableiten, ob auf Ihren Instances AmazonEMR, Apache Cassandra, Apache Hadoop, Memcached, PostgreSQL, RedisNGINX, Kafka oder ausgeführt werden. SQLServer Compute Optimizer leitet die Anwendungen ab, die auf Ihren Instances ausgeführt werden, und ist so in der Lage, den Aufwand für die Migration Ihrer Workloads von x86-basierten Instance-Typen zu ARM-basierten Graviton-Instance-Typen zu ermitteln. AWS Weitere Informationen finden Sie unter Migrationsaufwand.
Anmerkung
Sie können nicht auf die SQLServer Anwendung in den Regionen Naher Osten (Bahrain), Afrika (Kapstadt), Asien-Pazifik (Hongkong), Europa (Mailand) und Asien-Pazifik (Jakarta) schließen.
Migrationsaufwand
In der Spalte Migrationsaufwand auf den Seiten mit den Empfehlungen für Auto Scaling Scaling-Gruppen und den Detailseiten für Auto Scaling-Gruppen ist der Aufwand aufgeführt, der möglicherweise erforderlich ist, um vom aktuellen Instance-Typ zum empfohlenen Instance-Typ zu migrieren. Der Migrationsaufwand ist beispielsweise Mittel, wenn kein Workload-Typ abgeleitet werden kann, ein AWS Graviton-Instanztyp jedoch empfohlen wird. Der Migrationsaufwand ist gering, wenn Amazon der abgeleitete Workload-Typ EMR ist und ein AWS Graviton-Instance-Typ empfohlen wird. Der Migrationsaufwand ist sehr gering, wenn sowohl der aktuelle als auch der empfohlene Instance-Typ dieselbe CPU Architektur haben. Weitere Informationen zur Migration von x86-basierten Instance-Typen zu ARM-basierten Graviton-Instance-Typen finden Sie unter Überlegungen bei der Umstellung von Workloads AWS auf Graviton2-basierte Amazon-Instances in AWS Graviton Getting Starged
Preise und Kaufoptionen
Auf den Seiten mit den Auto Scaling Scaling-Gruppenempfehlungen und den Auto Scaling Scaling-Gruppendetails können Sie wählen, ob Sie die Stundenpreise für aktuelle EC2 Instances in Ihren Auto Scaling Scaling-Gruppen und die empfohlenen Instances unter verschiedenen EC2 Amazon-Kaufoptionen anzeigen möchten. Sie können sich beispielsweise den Preis Ihrer aktuellen Instance und der empfohlenen Instance unter der Option Reserve Instances anzeigen lassen. Die Standardoption ist ein Jahr ohne Vorauskauf. Anhand der Preisinformationen können Sie sich ein Bild vom Preisunterschied zwischen Ihrer aktuellen Instance und der empfohlenen Instance machen.

Wichtig
Die auf der Seite mit den Empfehlungen aufgeführten Preise entsprechen möglicherweise nicht den tatsächlichen Preisen, die Sie für Ihre Instances zahlen. Weitere Informationen dazu, wie Sie den tatsächlichen Preis Ihrer aktuellen Instances ermitteln können, finden Sie in den EC2Amazon-Nutzungsberichten im Amazon Elastic Compute Cloud-Benutzerhandbuch.
Die folgenden Kaufoptionen können auf der Seite mit den Empfehlungen ausgewählt werden:
-
On-Demand-Instances — Eine On-Demand-Instance ist eine Instance, die Sie bei Bedarf verwenden. Sie haben die volle Kontrolle über ihren Lebenszyklus — Sie entscheiden, wann sie gestartet, gestoppt, in den Ruhezustand versetzt, gestartet, neu gestartet und beendet werden soll. Es sind keine längerfristigen Verpflichtungen oder Vorauszahlungen erforderlich. Weitere Informationen zu On-Demand-Instances finden Sie unter On-Demand-Instances im Amazon Elastic Compute Cloud-Benutzerhandbuch. Weitere Informationen zur Preisgestaltung finden Sie unter Preise für Amazon EC2 On-Demand-Instances
. -
Reserved Instances (Standardvertrag für ein Jahr oder drei Jahre, keine Vorauszahlung) — Reserved Instances bieten Ihnen im Vergleich zu den Preisen für On-Demand-Instances erhebliche Einsparungen bei Ihren EC2 Amazon-Kosten. Bei Reserved-Instances handelt es sich nicht um physische Instances, sondern um einen Fakturierungsrabatt für die Nutzung gewisser On-Demand-Instances in Ihrem Konto. Weitere Informationen zu Reserved Instances finden Sie unter Reserved Instances im Amazon Elastic Compute Cloud-Benutzerhandbuch. Weitere Informationen zu den Preisen finden Sie unter Amazon EC2 Reserved Instance Pricing
.
Weitere Informationen zu Kaufoptionen finden Sie unter Kaufoptionen für Instances im Amazon Elastic Compute Cloud-Benutzerhandbuch.
Geschätzte monatliche Einsparungen und Sparmöglichkeiten
Geschätzte monatliche Einsparungen (nach Rabatten)
In dieser Spalte sind die ungefähren monatlichen Kosteneinsparungen aufgeführt, die Sie durch die Migration Ihrer Workloads vom aktuellen Instance-Typ zum empfohlenen Instance-Typ im Rahmen der Preismodelle Savings Plans und Reserved Instances erzielen. Um Empfehlungen mit Rabatten für Savings Plans und Reserved Instances zu erhalten, muss die Einstellung „Sparschätzungsmodus“ aktiviert sein. Weitere Informationen finden Sie unter Modus zur Schätzung der Einsparungen.
Anmerkung
Wenn Sie die Einstellung für den Sparschätzungsmodus nicht aktivieren, werden in dieser Spalte die standardmäßigen Preisnachlassinformationen auf Abruf angezeigt.
Geschätzte monatliche Einsparungen (auf Anfrage)
In dieser Spalte sind die ungefähren monatlichen Kosteneinsparungen aufgeführt, die Sie durch die Migration Ihrer Workloads vom aktuellen Instance-Typ zum empfohlenen Instance-Typ im Rahmen des On-Demand-Preismodells erzielen.
Einsparungsmöglichkeit (%)
In dieser Spalte wird der prozentuale Unterschied zwischen dem Preis der aktuellen Instance und dem Preis des empfohlenen Instance-Typs aufgeführt. Wenn der Sparschätzungsmodus aktiviert ist, analysiert Compute Optimizer die Preisrabatte für Savings Plans und Reserved Instances, um den Prozentsatz der Sparmöglichkeiten zu ermitteln. Wenn der Sparschätzungsmodus nicht aktiviert ist, verwendet Compute Optimizer nur On-Demand-Preisinformationen. Weitere Informationen finden Sie unter Modus zur Schätzung der Einsparungen.
Wichtig
Wenn Sie Cost Optimization Hub in aktivieren AWS Cost Explorer, verwendet Compute Optimizer Cost Optimization Hub-Daten, zu denen auch Ihre spezifischen Preisrabatte gehören, um Ihre Empfehlungen zu generieren. Wenn Cost Optimization Hub nicht aktiviert ist, verwendet Compute Optimizer Cost Explorer Explorer-Daten und On-Demand-Preisinformationen, um Ihre Empfehlungen zu generieren. Weitere Informationen finden Sie unter Cost Explorer und Cost Optimization Hub aktivieren im AWS Cost Management Benutzerhandbuch.
Berechnung der geschätzten monatlichen Einsparungen
Für jede Empfehlung berechnen wir die Kosten für den Betrieb einer neuen Instance unter Verwendung des empfohlenen Instance-Typs. Die geschätzten monatlichen Einsparungen werden auf der Grundlage der Anzahl der Betriebsstunden für aktuelle Instances in der Auto Scaling Scaling-Gruppe und der Preisdifferenz zwischen dem aktuellen Instance-Typ und dem empfohlenen Instance-Typ berechnet. Die geschätzten monatlichen Einsparungen für Auto Scaling Scaling-Gruppen, die im Compute Optimizer Optimizer-Dashboard angezeigt werden, sind eine Summe der geschätzten monatlichen Einsparungen für alle überprovisionierten Instances in Auto Scaling Scaling-Gruppen im Konto.
Leistungsrisiko
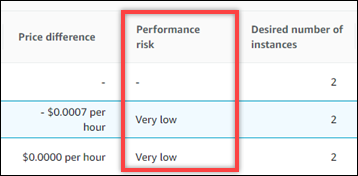
Die Spalte Leistungsrisiko auf der Seite mit den Auto Scaling Scaling-Gruppendetails definiert die Wahrscheinlichkeit, dass jeder empfohlene Instance-Typ den Ressourcenbedarf Ihres Workloads nicht erfüllt. Compute Optimizer berechnet eine individuelle Bewertung des Leistungsrisikos für jede Spezifikation der empfohlenen Instanz, einschließlich ArbeitsspeicherCPU, EBS Durchsatz, EBS IOPS Festplattendurchsatz, FestplatteIOPS, Netzwerkdurchsatz und Netzwerk. PPS Das Leistungsrisiko der empfohlenen Instanz wird anhand der maximalen Leistungsrisikobewertung für alle analysierten Ressourcenspezifikationen berechnet.
Die Werte reichen von sehr niedrig, niedrig, mittel, hoch und sehr hoch. Ein sehr geringes Leistungsrisiko bedeutet, dass die Empfehlung für den Instance-Typ voraussichtlich immer genügend Funktionen bietet. Je höher das Leistungsrisiko ist, desto wahrscheinlicher ist es, dass Sie überprüfen sollten, ob die Empfehlung den Leistungsanforderungen Ihres Workloads entspricht, bevor Sie Ihre Ressource migrieren. Entscheiden Sie, ob Sie die Leistungssteigerung, Kostensenkung oder beides optimieren möchten. Weitere Informationen finden Sie unter Ändern des Instance-Typs im Amazon Elastic Compute Cloud-Benutzerhandbuch.
Anmerkung
Im Compute Optimizer API wird das Leistungsrisiko AWS Command Line Interface (AWS CLI) und AWS SDKs auf einer Skala von 0 (sehr niedrig) bis 4 (sehr hoch) gemessen.
Aktuelles Leistungsrisiko
Die Spalte Aktuelles Leistungsrisiko auf der Seite mit den Empfehlungen für Auto Scaling Scaling-Gruppen definiert die Wahrscheinlichkeit, dass jede aktuelle Auto Scaling Scaling-Gruppe den Ressourcenbedarf ihrer Arbeitslast nicht erfüllt. Die aktuellen Werte für das Leistungsrisiko reichen von sehr niedrig, niedrig, mittel und hoch. Ein sehr geringes Leistungsrisiko bedeutet, dass die aktuelle Auto Scaling Scaling-Gruppe voraussichtlich immer genügend Funktionen bietet. Je höher das Leistungsrisiko ist, desto wahrscheinlicher ist es, dass Sie die von Compute Optimizer generierte Empfehlung berücksichtigen sollten.
Diagramme zur Auslastung
Auf der Seite mit den Auto Scaling Scaling-Gruppendetails werden Diagramme zur Nutzungsmetrik für aktuelle Instances in der Gruppe angezeigt. In den Diagrammen werden Daten für den Analysezeitraum angezeigt. Compute Optimizer verwendet den maximalen Nutzungspunkt innerhalb jedes Fünf-Minuten-Zeitintervalls, um Auto Scaling Scaling-Gruppenempfehlungen zu generieren.
Sie können die Diagramme so ändern, dass Daten für die letzten 24 Stunden, drei Tage, eine Woche oder zwei Wochen angezeigt werden. Wenn Sie die kostenpflichtige Funktion für erweiterte Infrastrukturkennzahlen aktivieren, können Sie Daten der letzten drei Monate einsehen.
Die folgenden Nutzungsdiagramme werden auf der Detailseite angezeigt:
| Name des Diagramms | Beschreibung |
|---|---|
|
Durchschnittliche CPU Auslastung (Prozent) |
Der durchschnittliche Prozentsatz der zugewiesenen EC2 Recheneinheiten, die von Instances in der Auto Scaling Scaling-Gruppe verwendet werden. |
|
Durchschnittliches Netzwerk in (MIB/Sekunde) |
Die Anzahl der Mebibyte (MiB) pro Sekunde, die auf allen Netzwerkschnittstellen von Instances in der Auto Scaling Scaling-Gruppe empfangen wurden. |
|
Durchschnittliche Netzwerkausgänge (MIB/Sekunde) |
Die Anzahl der Mebibyte (MiB) pro Sekunde, die von Instances in der Auto Scaling Scaling-Gruppe an alle Netzwerkschnittstellen gesendet werden. |
