Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Trainieren und evaluieren Sie DeepRacer AWS-Modelle mithilfe der DeepRacer AWS-Konsole
Um ein Reinforcement Learning-Modell zu trainieren, können Sie die DeepRacer AWS-Konsole verwenden. Erstellen Sie in der Konsole einen Trainingsjob, wählen Sie ein unterstütztes Framework und einen verfügbaren Algorithmus aus, fügen Sie eine Belohnungsfunktion hinzu und konfigurieren Sie die Trainingseinstellungen. Sie können das Training in einem Simulator beobachten. Die step-by-step Anweisungen finden Sie inTrainiere dein erstes DeepRacer AWS-Modell .
In diesem Abschnitt wird erklärt, wie ein DeepRacer AWS-Modell trainiert und bewertet wird. Er zeigt außerdem, wie man eine Belohnungsfunktion erstellt und verbessert, wie ein Aktionsraum die Modellleistung beeinflusst und wie Hyperparameter die Trainingsleistung beeinflussen. Sie erfahren zudem, wie Sie ein Trainingsmodell klonen können, um eine Trainingseinheit zu erweitern, wie Sie den Simulator zur Evaluierung der Trainingsleistung verwenden und wie Sie einige der Simulationen an die Herausforderungen der realen Welt anpassen können.
Themen
- Erstelle deine Belohnungsfunktion
- Erkunde den Actionraum, um ein robustes Modell zu trainieren
- Systematische Abstimmung von Hyperparametern
- Untersuchen Sie die Fortschritte bei der DeepRacer AWS-Schulung
- Klonen Sie ein trainiertes Modell, um einen neuen Trainingspass zu starten
- Bewerten Sie DeepRacer AWS-Modelle in Simulationen
- Optimieren Sie die DeepRacer AWS-Schulungsmodelle für reale Umgebungen
Erstelle deine Belohnungsfunktion
Eine Belohnungsfunktion beschreibt sofortiges Feedback (als Belohnung oder Strafpunkte), wenn sich Ihr DeepRacer AWS-Fahrzeug von einer Position auf der Strecke zu einer neuen Position bewegt. Der Zweck der Funktion ist es, das Fahrzeug dazu zu bringen, ein Ziel durch Bewegungen entlang der Strecke schnell und ohne Unfall oder Regelverstöße zu erreichen. Eine wünschenswerte Bewegung bringt eine bessere Bewertung für die entsprechende Aktion oder den Zielstatus. Eine illegale oder unnötige Bewegung führt zu einer niedrigeren Bewertung. Beim Training eines DeepRacer AWS-Modells ist die Belohnungsfunktion der einzige anwendungsspezifische Teil.
Im Allgemeinen gestalten Sie Ihre Belohnungsfunktion so, dass sie wie ein Incentive-Plan funktioniert. Verschiedene Incentive-Strategien können zu einem unterschiedlichen Fahrzeugverhalten führen. Um die Fahrt des Fahrzeugs zu beschleunigen, sollte die Funktion das Folgen der Strecke belohnen. Die Funktion sollte Strafen verteilen, wenn das Fahrzeug zum Beenden einer Runde zu lange braucht oder die Strecke verlässt. Um Zickzack-Fahrmuster zu vermeiden, könnte das Fahrzeug dafür belohnt werden, auf geraden Abschnitten der Strecke weniger zu lenken. Die Belohnungsfunktion kann positive Werte liefern, wenn das Fahrzeug bestimmte Meilensteine passiert (über waypoints). Dies könnte verhindern, dass das Fahrzeug abwartet oder in die falsche Richtung fährt. Vermutlich werden Sie die Belohnungsfunktion verändern, um die Streckenbedingungen zu berücksichtigen. Je stärker Ihre Belohnungsfunktion umgebungsspezifische Informationen berücksichtigt, desto wahrscheinlicher ist es jedoch, dass Ihr trainiertes Modell zu stark angepasst und weniger universell einsatzbar ist. Um Ihr Modell universeller einsetzbar zu gestalten, können Sie Aktionsräume ausprobieren.
Wenn ein Incentive-Plan nicht sorgfältig geprüft wird, kann er zu unbeabsichtigten Folgen mit gegenteiliger Wirkung
Zum Erstellen einer Belohnungsfunktion empfiehlt es sich, mit einer einfachen Funktion zu beginnen, die grundlegende Szenarien abdeckt. Sie können die Funktion erweitern, um mehr Aktionen zu verarbeiten. Schauen wir uns nun einige einfache Belohnungsfunktionen an.
Einfache Beispiele für Belohnungsfunktionen
Wir können mit der Erstellung der Belohnungsfunktion beginnen, indem wir zuerst die grundlegendste Situation berücksichtigen. Das ist eine Situation, in der von Anfang bis Ende auf einer geraden Strecke gefahren wird, ohne die Strecke zu verlassen. In diesem Szenario hängt die Logik der Belohnungsfunktion nur von on_track und progress ab. Als Versuch könnten Sie mit der folgenden Logik beginnen:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Diese Logik bestraft den Agenten, wenn er die Strecke verlässt. Sie belohnt den Agenten, wenn er zur Ziellinie fährt. Es ist sinnvoll, das gesteckte Ziel zu erreichen. Der Agent bewegt sich jedoch frei zwischen dem Startpunkt und der Ziellinie (einschließlich der Rückwärtsfahrt auf der Strecke). Das Training könnte nicht nur lange dauern, sondern das trainierte Modell würde beim Einsatz in einem realen Fahrzeug auch zu einer weniger effizienten Fahrweise führen.
In der Praxis lernt ein Agent effektiver, wenn er dies bit-by-bit im Laufe des Trainings tun kann. Dies bedeutet, dass eine Belohnungsfunktion Schritt für Schritt auf der Strecke kleinere Belohnungen ausgeben sollte. Damit der Agent auf der geraden Strecke fährt, können wir die Belohnungsfunktion wie folgt verbessern:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Mit dieser Funktion erhält der Agent umso mehr Belohnung, je näher er die Ziellinie erreicht. Dies sollte unproduktive Versuche der Rückwärtsfahrt reduzieren oder beseitigen. Im Allgemeinen wollen wir, dass die Belohnungsfunktion die Belohnung gleichmäßiger über den Aktionsraum verteilt. Das Entwickeln einer effektiven Belohnungsfunktion kann eine Herausforderung sein. Sie sollten mit einer einfachen Funktion beginnen und diese schrittweise erweitern oder verbessern. Durch systematisches Experimentieren kann die Funktion stabiler und effizienter werden.
Verbessern Sie Ihre Belohnungsfunktion
Nachdem Sie Ihr DeepRacer AWS-Modell erfolgreich für die einfache gerade Strecke trainiert haben, kann das DeepRacer AWS-Fahrzeug (virtuell oder physisch) von selbst fahren, ohne von der Strecke abzuweichen. Wenn Sie das Fahrzeug auf einer Ringstrecke fahren lassen, bleibt es nicht auf der Strecke. Die Belohnungsfunktion hat die Aktionen ignoriert, um Kurven zu lenken und so der Strecke zu folgen.
Damit Ihr Fahrzeug diese Aktionen ausführen kann, müssen Sie die Belohnungsfunktion erweitern. Die Funktion muss eine Belohnung gewähren, wenn der Agent eine zulässige Drehung macht, und eine Strafe vorsehen, wenn der Agent eine unzulässige Drehung macht. Dann sind Sie bereit, eine weitere Trainingsrunde zu beginnen. Um die Vorteile des vorherigen Trainings zu nutzen, können Sie das neue Training beginnen, indem Sie das vorher trainierte Modell klonen und so das zuvor erlernte Wissen weitergeben. Sie können diesem Muster folgen, um die Belohnungsfunktion schrittweise um weitere Funktionen zu erweitern, um Ihr DeepRacer AWS-Fahrzeug so zu trainieren, dass es in immer komplexeren Umgebungen fährt.
Weitere erweiterte Belohnungsfunktionen finden Sie in den folgenden Beispielen:
Erkunde den Actionraum, um ein robustes Modell zu trainieren
In der Regel sollten Sie Ihr Modell so zuverlässig wie möglich trainieren. Nur so können Sie es in möglichst vielen Umgebungen einsetzen. Ein zuverlässiges Modell ist ein Modell, das in einer Vielzahl von Streckenformen und -bedingungen eingesetzt werden kann. Ein zuverlässiges Modell ist grundsätzlich nicht "intelligent", denn seine Belohnungsfunktion deckt kein explizites, umgebungsspezifisches Wissen ab. Wenn dies der Fall wäre, würde Ihr Modell wahrscheinlich nur in einer Umgebung anwendbar sein, die der trainierten Umgebung ähnlich ist.
Die explizite Einbeziehung umgebungsspezifischer Informationen in die Belohnungsfunktion wird als Feature-Engineering (Funktionalitätsentwicklung) bezeichnet. Mit dem Feature-Engineering können Sie die Trainingszeit verkürzen. Sie können es für Lösungen einsetzen, die auf eine bestimmte Umgebung zugeschnitten sind. Um ein allgemein einsetzbares Modell zu trainieren, sollten Sie jedoch auf den großzügigen Einsatz von Feature-Engineering verzichten.
Wenn Sie beispielsweise ein Modell auf einer Rundstrecke trainieren, können Sie kein trainiertes Modell erwarten, das auf einer nicht kreisförmige Strecke einsetzbar ist (sofern Sie entsprechende geometrische Eigenschaften in die Belohnungsfunktion integriert haben).
Wie würden Sie ein Modell so zuverlässig wie möglich trainieren und gleichzeitig die Belohnungsfunktion so einfach wie möglich halten? Eine Methode besteht darin, den Aktionsraum mit den möglichen, vom Agenten durchführbaren Aktionen zu analysieren. Eine weitere ist das Experimentieren mit Hyperparametern für den zugrunde liegenden Trainingsalgorithmus. Meistens kommen beide Methoden zur Anwendung. Hier konzentrieren wir uns darauf, wie Sie den Aktionsraum erkunden können, um ein robustes Modell für Ihr DeepRacer AWS-Fahrzeug zu trainieren.
Beim Training eines DeepRacer AWS-Modells ist eine Aktion (a) eine Kombination aus Geschwindigkeit (tMeter pro Sekunde) und Lenkwinkel (sin Grad). Der Aktionsraum des Agenten definiert die möglichen Geschwindigkeitsbereiche und Lenkwinkel des Agenten. Für einen diskreten Aktionsraum von m Geschwindigkeiten ((v1, .., vn)) und n Lenkwinkeln ((s1, ..,
sm)) umfasst der Aktionsraum m*n mögliche Aktionen:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
Die tatsächlichen Werte von (vi,
sj) hängen von den Bereichen von vmax und |smax| ab und sind nicht einheitlich verteilt.
Jedes Mal, wenn Sie mit dem Training oder der Iteration Ihres DeepRacer AWS-Modells beginnenn, müssen Sie zunächst diem, vmax |smax| und/oder der Verwendung ihrer Standardwerte zustimmen. Basierend auf Ihrer Auswahl generiert der DeepRacer AWS-Service die verfügbaren Aktionen, die Ihr Agent im Rahmen der Schulung auswählen kann. Die erzeugten Aktionen sind nicht gleichmäßig über den Aktionsraum verteilt.
Im Allgemeinen geben eine größere Anzahl von Aktionen und größere Aktionsbereiche Ihrem Agenten mehr Raum oder Möglichkeiten, um auf unterschiedlichste Streckenbedingungen zu reagieren (z. B. eine Kurvenstrecke mit unregelmäßigen Kurvenwinkeln oder -richtungen). Je mehr Optionen dem Agenten zur Verfügung stehen, desto besser kann er mit Streckenvariationen umgehen. Infolgedessen können Sie erwarten, dass das trainierte Modell auch mit einer einfachen Belohnungsfunktion umfassender einsetzbar ist.
So kann Ihr Agent mithilfe eines grob eingeteilten Aktionsraums mit wenigen Geschwindigkeiten und Lenkwinkeln beispielsweise den Umgang mit einer geradlinigen Strecke schnell erlernen. Bei einer Strecke mit Kurven wird dieser grob eingeteilte Aktionsraum jedoch vermutlich dazu führen, dass der Agent bei Kurvenfahrten über die Streckenbegrenzung hinausfährt. Dies liegt daran, dass ihm nicht genügend Möglichkeiten zur Verfügung stehen, um die Geschwindigkeit oder die Lenkung zu ändern. Wenn Sie die Anzahl der Geschwindigkeiten oder der Lenkwinkel bzw. beides erhöhen, sollte der Agent in der Lage sein, durch Kurven zu manövrieren und innerhalb der Begrenzungen zu bleiben. Wenn sich Ihr Agent im Zickzack bewegt, können Sie außerdem versuchen, die Anzahl der Lenkbereiche zu erhöhen. So können Sie das Auftreten extremer Drehungen bei einem einzelnen Schritt reduzieren.
Wenn der Aktionsraum zu groß ist, kann die Trainingsleistung leiden. Denn in diesem Fall kann die Erkundung des Aktionsraums länger dauern. Stellen Sie sicher, dass Sie die Vorteile der allgemeinen Einsetzbarkeit eines Modells mit den Anforderungen an die Trainingsleistung in Einklang bringen. Diese Optimierung umfasst systematisches Experimentieren.
Systematische Abstimmung von Hyperparametern
Eine Möglichkeit zur Verbesserung der Leistung Ihres Modells besteht darin, einen besseren oder effektiveren Trainingsprozess zu implementieren. Um ein zuverlässiges Modell zu erhalten, muss das Training beispielsweise mehr oder weniger gleichmäßig über den Aktionsraum des Agenten verteilte Stichproben generieren. Dies erfordert eine ausreichende Mischung aus Erkundung und Förderung. Zu den diesbezüglichen Variablen gehören die Menge der verwendeten Trainingsdaten (number of episodes between each
training und batch size), die Lerngeschwindigkeit des Agenten (learning rate) und der Erkundungsanteil (entropy). Um das Training praxisnah zu gestalten, können Sie den Lernprozess beschleunigen. Zu den entsprechenden Variablen gehören learning rate, batch size, number of
epochs und discount factor.
Die Variablen mit Einfluss auf den Trainingsprozess werden als Hyperparameter des Trainings bezeichnet. Diese Algorithmusattribute stellen keine Eigenschaften des zugrunde liegenden Modells dar. Leider sind Hyperparameter empirischer Natur. Ihre optimalen Werte sind nicht für alle Anwendungszwecke bekannt und erfordern systematisches Experimentieren.
Bevor wir uns mit den Hyperparametern befassen, die angepasst werden können, um die Trainingsleistung Ihres DeepRacer AWS-Modells zu optimieren, definieren wir zunächst die folgende Terminologie.
- Datenpunkt
-
Ein Datenpunkt (auch Erfahrung) ist ein Tupel von (s,a,r,s'), wobei s für eine Beobachtung (oder einen Zustand) steht, die von der Kamera erfasst wird. a steht für eine vom Fahrzeug durchgeführte Aktion. r steht für die erwartete Belohnung, die durch die Aktion ausgelöst wird. s' steht für die neue Beobachtung, nachdem die Aktion durchgeführt wurde.
- Episode
-
Eine Episode ist ein Zeitraum, in dem das Fahrzeug von einem bestimmten Ausgangspunkt aus startet und die Strecke an deren Ende abschließt bzw. die Strecke verlässt. Sie stellt eine Abfolge von Erfahrungen dar. Episoden können unterschiedliche Längen haben.
- Erfahrungspuffer
-
Ein Erfahrungspuffer besteht aus einer Reihe von geordneten Datenpunkten, die über eine feste Anzahl von Episoden unterschiedlicher Länge während des Trainings gesammelt werden. Für AWS entspricht es den BildernDeepRacer, die von der an Ihrem DeepRacer AWS-Fahrzeug montierten Kamera aufgenommen wurden, und den vom Fahrzeug ausgeführten Aktionen. Es dient als Quelle, aus der Informationen für die Aktualisierung der zugrunde liegenden neuronalen Netzwerke (Richtlinien und Werte) stammen.
- Stapel
-
Ein Batch ist eine geordnete Liste von Erfahrungen, die einen Teil der Simulation über einen bestimmten Zeitraum darstellen und zur Aktualisierung der Gewichtung der Strategienetzwerke verwendet werden. Es handelt sich um eine Teilmenge des Erfahrungspuffers.
- Trainingsdaten
-
Trainingsdaten sind eine Reihe von Batches, die nach dem Zufallsprinzip aus einem Erfahrungspuffer entnommen und für das Training der Gewichtung der Strategienetzwerke verwendet werden.
| Hyperparameter | Beschreibung |
|---|---|
|
Gradientenabstieg-Batchgröße |
Die Anzahl der letzten Fahrzeugerfahrungen, die zufällig aus einem Erfahrungspuffer entnommen und zur Aktualisierung der zugrunde liegenden Gewichtung der neuronalen Deep-Learning-Netze verwendet wurden. Zufallsstichproben helfen, die in den Eingangsdaten enthaltenen Korrelationen zu reduzieren. Verwenden Sie eine größere Batchgröße, um stabilere und reibungslosere Aktualisierungen der Gewichtungen der neuronalen Netze zu fördern. Bedenken Sie jedoch, dass das Training länger dauern bzw. langsamer sein kann.
|
|
Number of epochs (Anzahl der Epochen) |
Die Anzahl der Durchläufe durch die Trainingsdaten zur Aktualisierung der Gewichtungen des neuronalen Netzes während des Gradientenabstiegs. Die Trainingsdaten entsprechen Stichproben aus dem Erfahrungspuffer. Verwenden Sie eine größere Anzahl von Epochen, um zuverlässigere Aktualisierungen zu fördern. Bedenken Sie jedoch, dass das Training länger dauern bzw. langsamer sein kann. Wenn die Batchgröße klein ist, können Sie eine kleinere Epochenanzahl verwenden.
|
|
Learning rate (Lernrate) |
Bei jeder Aktualisierung kann ein Teil der neuen Gewichtung aus dem Gradientenabstieg (oder Aufstieg) stammen. Der Rest kann dem vorhandenen Gewichtungswert entnommen werden. Die Lernrate steuert, wie stark ein Gradientenabstieg (oder Aufstieg) zur Gewichtung der Netze beiträgt. Verwenden Sie eine höhere Lernrate, um mehr Daten aus dem Gradientenabstieg einzubeziehen. So wird das Training schneller. Bedenken Sie jedoch, dass sich die erwartete Belohnung möglicherweise nicht annähert, wenn die Lernrate zu hoch ist.
|
Entropy |
Ein gewisses Maß an Unsicherheit, das für einen Zufallsfaktor in der Strategieverteilung verwendet wird. Die zusätzliche Unsicherheit hilft dem DeepRacer AWS-Fahrzeug, den Aktionsraum umfassender zu erkunden. Ein größerer Entropiewert veranlasst das Fahrzeug, den Aktionsraum gründlicher zu erforschen.
|
| Discount factor (Rabattfaktor) |
Ein Faktor gibt an, wie viele der zukünftigen Belohnungen zu der erwarteten Belohnung beitragen. Je größer der Discount factor (Abschlagfaktor)-Wert ist, desto weiter entfernt liegen die Beiträge, die das Fahrzeug für eine Bewegung berücksichtigt, und desto langsamer ist das Training. Mit dem Abschlagfaktor 0,9 berücksichtigt das Fahrzeug Belohnungen aus einer Schrittlänge von 10 für zukünftige Bewegungen. Mit dem Abschlagfaktor 0,999 berücksichtigt das Fahrzeug Belohnungen aus einer Schrittlänge von 1000 für zukünftige Bewegungen. Die empfohlenen Werte für den Abschlagfaktor sind 0,99, 0,999 und 0,9999.
|
| Loss type (Schadensart) |
Typ der Zielfunktion, mit der die Netzwerkgewichte aktualisiert werden. Ein guter Trainingsalgorithmus sollte schrittweise Änderungen an der Strategie des Agenten vornehmen, sodass er allmählich von zufälligen Aktionen zu strategischen Aktionen übergeht, um die Belohnung zu erhöhen. Aber wenn es eine zu große Veränderung bewirkt, dann wird das Training instabil und der Agent lernt am Ende nicht. Die Typen Huber loss (Huber-Verlust)
|
| Anzahl der Erfahrungsepisoden zwischen den einzelnen Iterationen zur Strategieaktualisierung | Die Größe des Erfahrungspuffers, aus dem Trainingsdaten zum Lernen der Gewichtung der Strategienetzwerke entnommen werden. Eine Episode ist ein Zeitraum, in dem der Agent von einem bestimmten Ausgangspunkt aus startet und die Strecke an deren Ende abschließt bzw. die Strecke verlässt. Sie besteht aus einer Reihe von Erfahrungen. Episoden können unterschiedliche Längen haben. Bei einfachen Reinforcement-Learning-Problemen kann ein kleiner Erfahrungspuffer ausreichen. Der Lernprozess ist schnell. Bei komplexeren Problemen mit mehr lokalen Maximallösungen ist ein größerer Erfahrungspuffer erforderlich, um mehr unkorrelierte Datenpunkte bereitzustellen. In diesem Fall ist das Training langsamer, aber stabiler. Die empfohlenen Werte sind 10, 20 und 40.
|
Untersuchen Sie die Fortschritte bei der DeepRacer AWS-Schulung
Nachdem Sie Ihren Trainingsauftrag gestartet haben, können Sie die Trainingsmetriken der Belohnungen und des Streckenabschlusses pro Episode prüfen, um die Leistung des Trainingsauftrags Ihres Modells zu ermitteln. In der DeepRacer AWS-Konsole werden die Metriken im Prämiendiagramm angezeigt, wie in der folgenden Abbildung dargestellt.
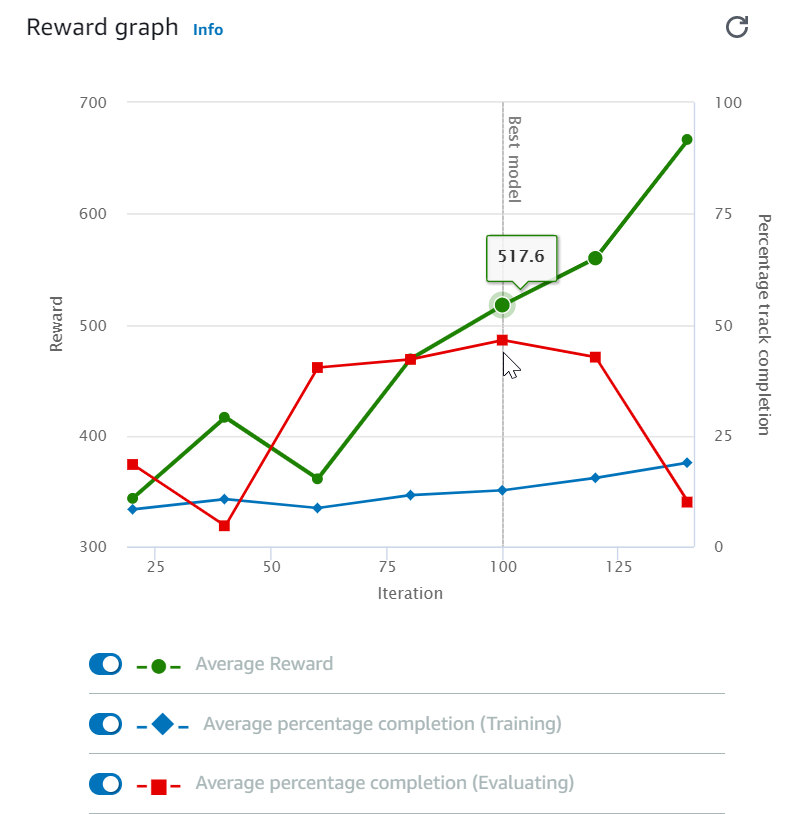
Sie können die pro Episode erworbene Belohnung, die gemittelte Belohnung pro Iteration, den Fortschritt pro Episode, den gemittelten Fortschritt pro Iteration oder eine beliebige Kombination hiervon anzeigen. Schalten Sie dazu die Schalter Reward (Episode, Average) (Belohnung (Episode, Durchschnitt)) oder Progress (Episode, Average) (Fortschritt (Episode, Durchschnitt)) unten im Reward graph (Belohnungsdiagramm)um. Die Belohnung und der Fortschritt pro Episode werden als Streudiagramme in verschiedenen Farben angezeigt. Die gemittelte Belohnung und der Streckenabschluss werden in Liniendiagrammen angezeigt und beginnen nach der ersten Iteration.
Der Belohnungsbereich wird auf der linken Seite des Diagramms angezeigt und der Fortschrittsbereich (0 - 100) auf der rechten Seite. Um den genauen Wert einer Trainingsmetrik zu lesen, bewegen Sie den Mauszeiger in die Nähe des Datenpunkts auf dem Diagramm.
Die Diagramme werden während des Trainings automatisch alle 10 Sekunden aktualisiert. Sie können die Schaltfläche „Refresh (Aktualisieren)” auswählen, um die Metrikanzeige manuell zu aktualisieren.
Ein Trainingsauftrag ist gut, wenn die gemittelte Belohnung und der Streckenabschluss die Tendenz zeigen, zu konvergieren. Insbesondere ist das Modell wahrscheinlich konvergiert, wenn der Fortschritt pro Episode kontinuierlich 100 % erreicht und die Belohnung ausgeglichen ist. Wenn dies nicht der Fall ist, klonen Sie das Modell und trainieren Sie es neu.
Klonen Sie ein trainiertes Modell, um einen neuen Trainingspass zu starten
Wenn Sie ein zuvor trainiertes Modell als Ausgangspunkt für eine neue Trainingsrunde klonen, können Sie die Trainingseffizienz verbessern. Modifizieren Sie dazu die Hyperparameter, um das bereits erlernte Wissen zu nutzen.
In diesem Abschnitt erfahren Sie, wie Sie ein trainiertes Modell mithilfe der DeepRacer AWS-Konsole klonen.
Um das Training des Reinforcement Learning-Modells mithilfe der AWS-Konsole zu wiederholen DeepRacer
-
Melden Sie sich bei der DeepRacer AWS-Konsole an, falls Sie noch nicht angemeldet sind.
-
Wählen Sie auf der Seite Modelle ein trainiertes Modell aus und wählen Sie dann in der Dropdownmenüliste Aktion die Option Klonen aus.
-
Gehen Sie für Model details (Modelldetails) wie folgt vor:
-
Geben Sie
RL_model_1als Model name (Modellname) ein, wenn Sie nicht möchten, dass ein Name für das geklonte Modell generiert wird. -
Geben Sie optional eine Beschreibung für das to-be-cloned Modell unter Modellbeschreibung ein — optional.
-
-
Wählen Sie für die Umgebungssimulation eine andere Track-Option.
-
Wählen Sie für die Reward function (Belohnungsfunktion) eines der verfügbaren Beispiele für Belohnungsfunktionen aus. Modifizieren Sie die Belohnungsfunktion. Berücksichtigen Sie zum Beispiel das Lenken.
-
Erweitern Sie Algorithm settings (Algorithmeneinstellungen) und probieren Sie verschiedene Optionen aus. Ändern Sie beispielsweise den Wert Gradient descent batch size (Gradientenabstieg-Batchgröße) von 32 auf 64 oder erhöhen Sie die Learning Rate (Lernrate), um das Training zu beschleunigen.
-
Experimentieren Sie mit verschiedenen Einstellungen der Stop conditions (Stoppbedingungen).
-
Wählen Sie Start training (Training starten) aus, um eine neue Runde des Trainings zu beginnen.
Wie beim Training eines robusten Machine-Learning-Modells im Allgemeinen ist es wichtig, dass Sie systematische Experimente durchführen, um die beste Lösung zu finden.
Bewerten Sie DeepRacer AWS-Modelle in Simulationen
Ein Modell auszuwerten bedeutet, die Leistung eines trainierten Modells zu testen. In AWS DeepRacer ist die Standard-Leistungskennzahl die durchschnittliche Zeit, in der drei aufeinanderfolgende Runden gefahren werden. Bei Verwendung dieser Metrik ist für zwei beliebige Modelle ein Modell besser als das andere, wenn es dazu führen kann, dass der Agent auf derselben Strecke schneller vorankommt.
Im Allgemeinen umfasst die Bewertung eines Modells die folgenden Aufgaben:
-
Konfigurieren und starten Sie einen Auswertungsauftrag.
-
Beobachten Sie die laufende Auswertung, während der Auftrag läuft. Dies kann im DeepRacer AWS-Simulator erfolgen.
-
Überprüfen Sie die Auswertungszusammenfassung, nachdem der Auswertungsauftrag abgeschlossen ist. Sie können einen laufenden Auswertungsauftrag jederzeit abbrechen.
Anmerkung
Die Bewertungszeit hängt von den ausgewählten Kriterien ab. Wenn Ihr Modell die Bewertungskriterien nicht erfüllt, wird die Bewertung so lange ausgeführt, bis das 20-Minuten-Limit erreicht ist.
-
Senden Sie das Bewertungsergebnis optional an eine qualifizierte DeepRacerAWS-Bestenliste. Das Ranglistenergebnis auf der Rangliste zeigt Ihnen, wie gut sich Ihr Modell im Vergleich zu anderen Teilnehmern schlägt.
Testen Sie ein DeepRacer AWS-Modell mit einem DeepRacer AWS-Fahrzeug, das auf einer physischen Strecke fährt, sieheBetreiben Sie Ihr DeepRacer AWS-Fahrzeug .
Optimieren Sie die DeepRacer AWS-Schulungsmodelle für reale Umgebungen
Viele Faktoren beeinflussen die praktische Leistung eines trainierten Modells. Dazu gehören beispielsweise der Aktionsraum, die Belohnungsfunktion und die Hyperparameter im Training, die Fahrzeugkalibrierung und die Bedingungen der Strecke in der echten Welt. Darüber hinaus ist die Simulation nur eine (oft grobe) Annäherung an die Praxis. Diese Faktoren sorgen dafür, dass das Training eines Modells in der Simulation und dessen späterer Einsatz in der echten Welt mit einer zufriedenstellenden Leistung schwierig ist.
Das Trainieren eines Modells für eine solide Leistung in der Praxis erfordert oft zahlreiche Iterationen zur Erforschung der Belohnungsfunktion, Aktionsräume, Hyperparameter und Bewertungen in der Simulation sowie dem Testen in einer realen Umgebung. Der letzte Schritt beinhaltet den sogenannten simulation-to-realWelttransfer (sim2real) und kann sich unhandlich anfühlen.
Berücksichtigen Sie die folgenden Punkte, um den sim2real-Vorgang einfacher zu gestalten:
-
Stellen Sie sicher, dass Ihr Fahrzeug sauber kalibriert ist.
Dies ist wichtig, da die simulierte Umgebung höchstwahrscheinlich eine teilweise Darstellung der realen Umgebung ist. Außerdem führt der Agent bei jedem Schritt eine Aktion durch, die auf der aktuellen von der Kamera aufgenommenen Streckenbedingung basiert. Es kann nicht weit genug sehen, um seine Route schnell zu planen. Um dies zu berücksichtigen, setzt die Simulation Grenzen für die Geschwindigkeit und Lenkung. Um sicherzustellen, dass das trainierte Modell in der realen Welt funktioniert, muss das Fahrzeug entsprechend diesen und anderen Simulationseinstellungen kalibriert sein. Weitere Informationen zur Kalibrierung Ihres Fahrzeugs finden Sie unter Kalibrieren Sie Ihr DeepRacer AWS-Fahrzeug.
-
Testen Sie Ihr Fahrzeug zunächst mit dem Standardmodell.
Ihr DeepRacer AWS-Fahrzeug verfügt über ein vortrainiertes Modell, das in die Inferenz-Engine geladen ist. Bevor Sie Ihr eigenes Modell in der realen Welt testen, vergewissern Sie sich, dass das Fahrzeug mit dem Standardmodell recht gut funktioniert. Wenn nicht, überprüfen Sie das physische Strecken-Setup. Das Testen eines Modells in einer falsch gebauten physischen Strecke führt wahrscheinlich zu einer schlechten Leistung. In solchen Fällen sollten Sie Ihre Strecke neu konfigurieren oder reparieren, bevor Sie mit dem Testen beginnen oder den Test fortsetzen.
Anmerkung
Beim Betrieb Ihres DeepRacer AWS-Fahrzeugs werden die Aktionen anhand des geschulten Richtliniennetzwerks abgeleitet, ohne dass die Belohnungsfunktion aufgerufen wird.
-
Stellen Sie sicher, dass das Modell in der Simulation funktioniert.
Wenn Ihr Modell in der realen Welt nicht gut funktioniert, könnten das Modell oder die Strecke fehlerhaft sein. Zur Klärung der Ursachen sollten Sie zunächst das Modell in Simulationen evaluieren, um zu prüfen, ob der simulierte Agent mindestens eine Runde beenden kann, ohne von der Strecke abzukommen. Sie können dies tun, indem Sie die Konvergenz der Belohnungen überprüfen, während Sie die Bewegungsbahn des Agenten im Simulator beobachten. Wenn die Belohnung das Maximum erreicht und wenn die simulierten Agenten ohne Unterbrechung eine Runde beenden, ist das Modell wahrscheinlich in Ordnung.
-
Trainieren Sie das Modell nicht zu stark.
Das Fortfahren mit dem Training, nachdem das Modell die Strecke in der Simulation konsequent absolviert hat, führt zu einer Überanpassung des Modells. Ein übertrainiertes Modell funktioniert in der realen Welt nicht besonders gut. Es kann selbst geringe Abweichungen zwischen der simulierten Strecke und der realen Umgebung nicht bewältigen.
-
Verwenden Sie mehrere Modelle aus verschiedenen Iterationen.
Eine typische Trainingseinheit produziert eine Reihe von Modellen, die irgendwo zwischen Unter- und Überanpassung liegen. Da es keine standardmäßigen Kriterien zur Bestimmung eines genau passenden Modells gibt, sollten Sie einige Modellkandidaten zwischen dem Zeitpunkt auswählen, an dem der Agent eine einzelne Runde im Simulator beendet, und dem Zeitpunkt, an dem er die Runde konsistent absolviert.
-
Beginnen Sie langsam und erhöhen Sie die Fahrgeschwindigkeit im Test schrittweise.
Wenn Sie das in Ihrem Fahrzeug eingesetzte Modell testen, beginnen Sie mit einem niedrigen Höchstgeschwindigkeitswert. Beispielsweise können Sie die Testgeschwindigkeit auf weniger als 10 % der Trainingsgeschwindigkeit festlegen. Erhöhen Sie dann schrittweise die Testgeschwindigkeitsbegrenzung, bis sich das Fahrzeug in Bewegung setzt. Die Testgeschwindigkeitsbegrenzung legen Sie bei der Kalibrierung des Fahrzeugs über die Gerätesteuerkonsole fest. Wenn das Fahrzeug zu schnell fährt, zum Beispiel wenn die Geschwindigkeit die Geschwindigkeit übersteigt, die beim Training im Simulator gemessen wurde, ist es unwahrscheinlich, dass das Modell auf der realen Strecke gut abschneidet.
-
Testen Sie ein Modell mit Ihrem Fahrzeug in verschiedenen Ausgangspositionen.
Das Modell lernt, einen bestimmten Weg in der Simulation zu nehmen, und kann auf seine Position innerhalb der Strecke reagieren. Sie sollten die Fahrzeugtests mit verschiedenen Positionen innerhalb der Streckenbegrenzungen (links, Mitte, rechts) starten, um zu sehen, ob das Modell von bestimmten Positionen aus gut funktioniert. Die meisten Modelle neigen dazu, das Fahrzeug nahe an der Seite einer der weißen Linien zu halten. Um den Weg des Fahrzeugs zu analysieren, zeichnen Sie Schritt für Schritt die Positionen des Fahrzeugs (x, y) aus der Simulation auf. So können Sie mögliche Wege identifizieren, die Ihr Fahrzeug in einer realen Umgebung zurücklegen muss.
-
Beginnen Sie die Tests mit einer geraden Strecke.
Eine gerade Strecke ist viel einfacher zu bewältigen als eine kurvige Strecke. Mit einer geraden Strecke zu beginnen bietet die Möglichkeit, schlechte Modelle schnell auszusortieren. Wenn ein Fahrzeug meistens daran scheitert, einer geraden Strecke zu folgen, wird das Modell auch auf kurvenreichen Strecken nicht gut funktionieren.
-
Achten Sie auf Verhaltensweisen, bei denen das Fahrzeug nur eine Art von Aktionen ausführt.
Wenn Ihr Fahrzeug nur eine Art von Aktion ausführen kann, z. B. das Fahrzeug nur nach links zu lenken, ist das Modell wahrscheinlich über- oder unterausgestattet. Zu viele Trainings-Iterationen bei gegebenen Modellparametern können dazu führen, dass das Modell übermäßig angepasst wird. Zu wenig Iterationen können dazu führen, dass es nicht richtig angepasst ist.
-
Achten Sie auf die Fähigkeit des Fahrzeugs, seinen Weg entlang einer Streckenbegrenzung zu korrigieren.
Ein gutes Modell bewirkt, dass sich das Fahrzeug bei Annäherung an die Streckenbegrenzungen selbst korrigiert. Die meisten gut trainierten Modelle verfügen über diese Fähigkeit. Wenn sich das Fahrzeug an beiden Streckenbegrenzungen selbst korrigieren kann, gilt das Modell als stabiler und hochwertiger.
-
Achten Sie auf ein inkonsistentes Verhalten des Fahrzeugs.
Ein Strategiemodell stellt eine Wahrscheinlichkeitsverteilung für das Ergreifen einer Aktion in einem bestimmten Zustand dar. Wenn das trainierte Modell in die Inferenz-Engine geladen wird, wählt ein Fahrzeug schrittweise entsprechend den Vorgaben des Modells die wahrscheinlichste Aktion aus. Wenn die Aktionswahrscheinlichkeiten gleichmäßig verteilt sind, kann das Fahrzeug alle Aktionen mit identischen oder sehr ähnlichen Wahrscheinlichkeiten durchführen. Dies führt zu einem unregelmäßigen Fahrverhalten. Wenn das Fahrzeug beispielsweise manchmal einer geraden Strecke folgt (z. B. die Hälfte der Zeit) und zu anderen Zeiten unnötige Kurven fährt, ist das Modell entweder zu wenig oder zu stark ausgestattet.
-
Achten Sie darauf, dass das Fahrzeug nur eine Art von Abbiegung (links oder rechts) ausführt.
Wenn das Fahrzeug sehr gut nach links abbiegt, aber nicht nach rechts lenkt (oder andersrum), müssen Sie die Lenkung Ihres Fahrzeugs sorgfältig kalibrieren oder neu kalibrieren. Alternativ können Sie versuchen, ein Modell zu verwenden, das mit Einstellungen trainiert wurde, die den zu testenden physischen Einstellungen entsprechen.
-
Achten Sie darauf, dass das Fahrzeug plötzlich abbiegt und von der Strecke abkommt.
Wenn das Fahrzeug den größten Teil des Weges korrekt zurücklegt, aber plötzlich von der Strecke abkommt, liegt dies wahrscheinlich an Ablenkungen in der Umgebung. Zu den häufigsten Ablenkungen gehören unerwartete oder unbeabsichtigte Lichtreflexionen. Verwenden Sie in solchen Fällen Barrieren um die Strecke herum oder andere Mittel, um grelles Licht zu reduzieren.
