Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen von Aufträgen mit benutzerdefinierten Connectors
Sie können Connectors und Verbindungen sowohl für Datenquellenknoten als auch für Datenzielknoten in AWS Glue Studio erstellen.
Erstellen von Aufträgen, die einen Connector für die Datenquelle verwenden
Wenn Sie einen neuen Auftrag erstellen, können Sie einen Connector für die Datenquelle und die Datenziele auswählen.
Aufträge erstellen, die Connectors für die Datenquelle oder das Datenziel verwenden
Melden Sie sich bei an AWS Management Console und öffnen Sie die AWS Glue Studio Konsole unter https://console.aws.amazon.com/gluestudio/.
-
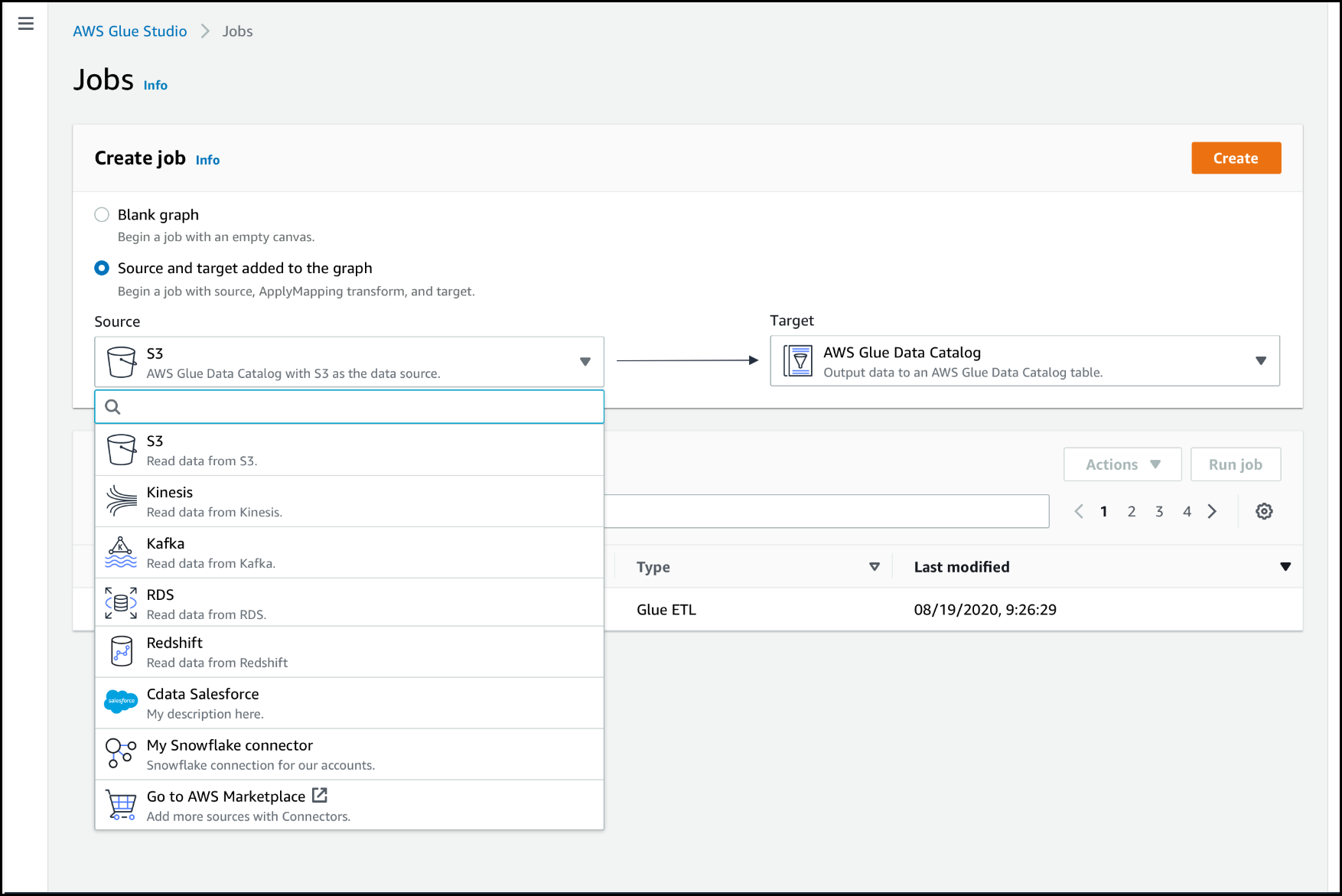
Wählen Sie auf der Seite Connectors in der Ressourcenliste Your Connections (Ihre Verbindungen) die Verbindung aus, die Sie in Ihrem Auftrag verwenden möchten. Klicken Sie dann auf Create job (Auftrag erstellen).
Alternativ können Sie in AWS Glue Studio auf der Seite Jobs (Aufträge) unter Create Job (Auftrag erstellen) die Option Source and target added to the graph (Quelle und Ziel zum Diagramm hinzugefügt) auswählen. In der Dropdown-Liste Source (Quelle) wählen Sie den benutzerdefinierten Connector aus, den Sie in Ihrem Auftrag verwenden möchten. Sie können auch einen Connector für Target (Ziel) auswählen.
-
Klicken Sie dann auf Create (Erstellen), um den visuellen Auftragseditor zu öffnen.
-
Konfigurieren Sie den Datenquellknoten, wie unter Konfigurieren von Quelleneigenschaften für Knoten, die Connectors verwenden beschrieben.
-
Fahren Sie mit der Erstellung Ihres ETL Jobs fort, indem Sie Transformationen, zusätzliche Datenspeicher und Datenziele hinzufügen, wie unter beschriebenStarten von visuellen ETL Jobs in AWS Glue Studio.
-
Passen Sie die Umgebung der Auftragsausführung an, indem Sie Auftragseigenschaften konfigurieren, wie unter Ändern der Auftragseigenschaften beschrieben.
-
Speichern Sie den Auftrag und führen Sie ihn aus.
Konfigurieren von Quelleneigenschaften für Knoten, die Connectors verwenden
Nachdem Sie einen Auftrag erstellt haben, der einen Connector für die Datenquelle verwendet, zeigt der visuelle Auftragseditor ein Auftragsdiagramm mit einem Datenquellenknoten an, der für den Connector konfiguriert ist. Sie müssen die Datenquelleneigenschaften für diesen Knoten konfigurieren.
Eigenschaften für einen Datenquellenknoten konfigurieren, der einen Connector verwendet
-
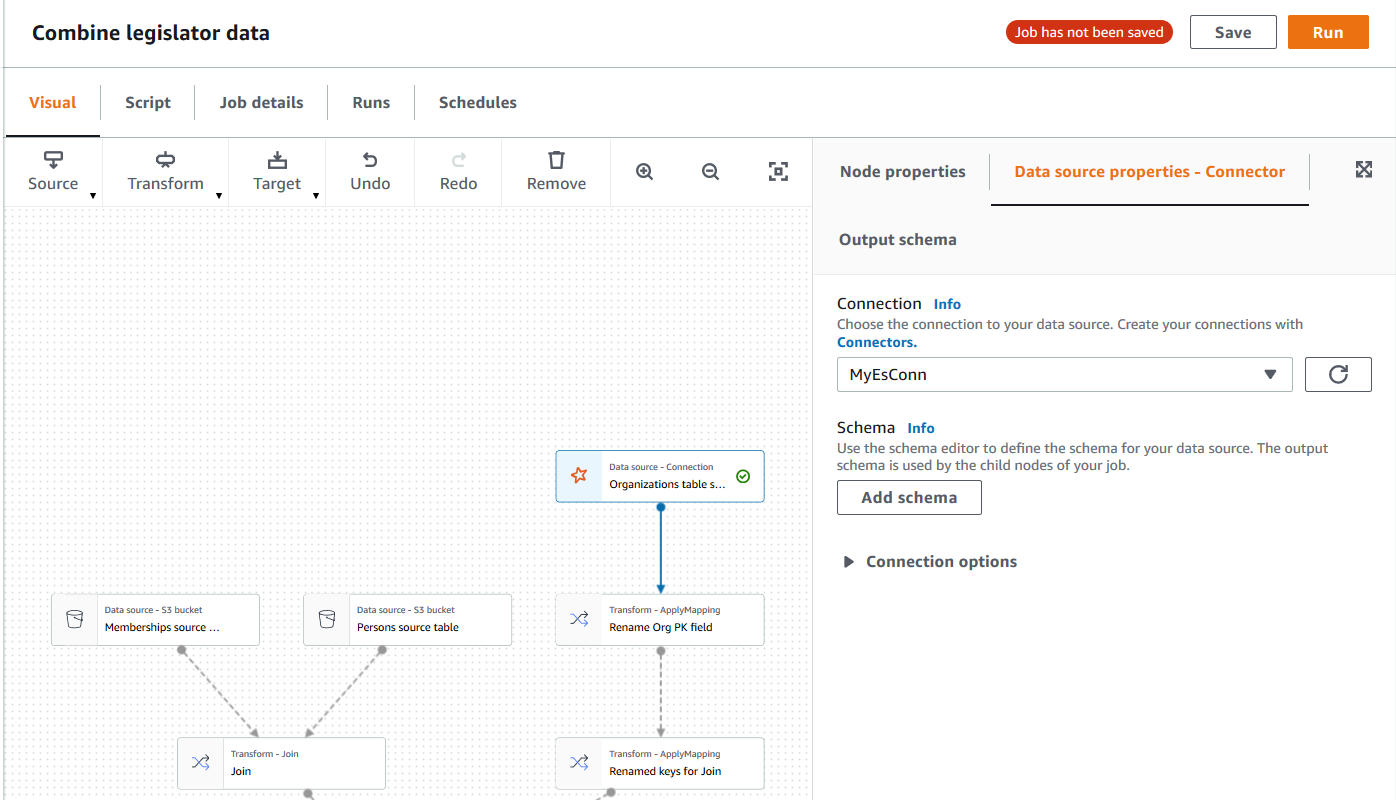
Wählen Sie den Connector-Datenquellknoten im Auftragsdiagramm aus, oder fügen Sie einen neuen Knoten hinzu und wählen Sie den Connector für den Node type (Knotentyp) aus. Wählen Sie dann auf der rechten Seite im Bereich „Node Details“ (Knotendetails) die Registerkarte Data source properties (Datenquelleneigenschaften) aus, falls sie nicht bereits ausgewählt ist.
-
Wählen Sie auf der Registerkarte Data source properties (Datenquelleneigenschaften) die Verbindung aus, die Sie für diesen Auftrag verwenden möchten.
Geben Sie die zusätzlichen Informationen ein, die für jeden Verbindungstyp erforderlich sind:
- JDBC
-
-
Eingabeart der Datenquelle: Geben Sie entweder einen Tabellennamen oder eine SQL Abfrage als Datenquelle an. Abhängig vom gewählten Typ müssen Sie die folgenden zusätzlichen Informationen eingeben:
-
Table name (Tabellenname): Der Name der Tabelle in der Datenquelle. Wenn die Datenquelle den Begriff Tabelle nicht verwendet, geben Sie den Namen einer geeigneten Datenstruktur an, wie in den Benutzerinformationen zur Verwendung des Konnektors angegeben (verfügbar unter AWS Marketplace).
-
Filter predicate (Filterprädikat): Eine Bedingungsklausel, die beim Lesen der Datenquelle verwendet werden soll, ähnelt einer WHERE-Klausel zum Abrufen einer Teilmenge der Daten.
-
Abfragecode: Geben Sie eine SQL Abfrage ein, mit der ein bestimmter Datensatz aus der Datenquelle abgerufen werden soll. Ein Beispiel für eine einfache SQL Abfrage ist:
SELECT column_list FROM
table_name WHERE where_clause
-
Schema: Da AWS Glue Studio Informationen in der Verbindung gespeicherte Informationen verwendet, um auf die Datenquelle zuzugreifen, anstatt Metadateninformationen aus einer Data-Catalog-Tabelle abzurufen, müssen Sie die Schemametadaten für die Datenquelle bereitstellen. Klicken Sie auf Add schema (Schema hinzufügen), um den Schema-Editor zu öffnen.
Anweisungen zur Verwendung des Schema-Editors finden Sie unter Bearbeiten des Schemas in einem benutzerdefinierten Transformationsknoten.
-
Partition column (Partitionsspalte): (Optional) Sie können die Datenlesevorgänge partitionieren, indem Sie Werte für Partition column (Partitionsspalte), Lower bound (Untergrenze), Upper bound (Obergrenze) und Number of partitions (Anzahl der Partitionen) aus.
Die Werte für lowerBound und upperBound werden verwendet, um den Partitionsschritt zu bestimmen, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen der Tabelle werden partitioniert und zurückgegeben.
Die Spaltenpartitionierung fügt der Abfrage, die zum Lesen der Daten verwendet wird, eine zusätzliche Partitionierungsbedingung hinzu. Wenn Sie eine Abfrage anstelle eines Tabellennamens verwenden, sollten Sie überprüfen, ob die Abfrage mit der angegebenen Partitionierungsbedingung funktioniert. Zum Beispiel:
-
Wenn Ihr Abfrageformat "SELECT col1 FROM table1" lautet, dann testen Sie die Abfrage, indem Sie eine WHERE-Klausel am Ende der Abfrage stellen, die die Partitionsspalte verwendet.
-
Wenn Ihr Abfrageformat "SELECT col1 FROM table1 WHERE
col2=val" lautet, dann testen Sie die Abfrage, indem Sie die WHERE-Klausel mit AND und einem Ausdruck erweitern, der die Partitionsspalte verwendet.
-
Datentypumwandlung: Wenn die Datenquelle Datentypen verwendet, die in nicht verfügbar sindJDBC, geben Sie in diesem Abschnitt an, wie ein Datentyp aus der Datenquelle in JDBC Datentypen konvertiert werden soll. Sie können bis zu 50 verschiedene Datentypkonvertierungen angeben. Alle Spalten in der Datenquelle, die denselben Datentyp verwenden, werden auf die gleiche Weise konvertiert.
Wenn Sie beispielsweise drei Spalten in der Datenquelle haben, die den Float Datentyp verwenden, und Sie angeben, dass der Float Datentyp in den JDBC String Datentyp konvertiert werden soll, werden alle drei Spalten, die den Float Datentyp verwenden, in String Datentypen konvertiert.
-
Job bookmark keys (Schlüssel für Auftragslesezeichen): Auftragslesezeichen helfen AWS Glue bei der Pflege von Zustandsinformationen und verhindern die Wiederaufbereitung alter Daten. Geben Sie eine oder mehrere Spalten als Lesezeichenschlüssel an. AWS Glue Studioverwendet Lesezeichenschlüssel, um Daten nachzuverfolgen, die bereits während einer früheren Ausführung des ETL Jobs verarbeitet wurden. Alle Spalten, die Sie für benutzerdefinierte Lesezeichenschlüssel verwenden, müssen streng monoton erhöht oder verringert werden, aber Lücken sind zulässig.
Wenn Sie mehrere Lesezeichenschlüssel eingeben, werden diese zu einem einzigen zusammengesetzten Schlüssel zusammengefasst. Ein zusammengesetzter Schlüssel für Auftragslesezeichen sollte keine doppelten Spalten enthalten. Wenn Sie keine Lesezeichenschlüssel angeben, verwendet AWS Glue Studio standardmäßig den Primärschlüssel als Lesezeichenschlüssel, vorausgesetzt, dass der Primärschlüssel sequenziell erhöht oder verringert wird (ohne Lücken). Wenn die Tabelle keinen Primärschlüssel hat, aber die Eigenschaft „Job bookmark“ (Auftragslesezeichen) aktiviert ist, müssen Sie benutzerdefinierte Schlüssel für Auftragslesezeichen angeben. Andernfalls schlagen die Suche nach standardmäßig zu verwendenden Primärschlüsseln und die Auftragsausführung fehl.
Job bookmark keys sorting order (Sortierreihenfolge der Schlüssel für Auftragslesezeichen): Wählen Sie aus, ob die Schlüsselwerte auf- oder absteigend sortiert werden.
- Spark
-
-
Schema: Da AWS Glue Studio Informationen in der Verbindung gespeicherte Informationen verwendet, um auf die Datenquelle zuzugreifen, anstatt Metadateninformationen aus einer Data-Catalog-Tabelle abzurufen, müssen Sie die Schemametadaten für die Datenquelle bereitstellen. Klicken Sie auf Add schema (Schema hinzufügen), um den Schema-Editor zu öffnen.
Anweisungen zur Verwendung des Schema-Editors finden Sie unter Bearbeiten des Schemas in einem benutzerdefinierten Transformationsknoten.
-
Connection options (Verbindungsoptionen): Geben Sie nach Bedarf weitere Schlüssel-Wert-Paare ein, um zusätzliche Verbindungsinformationen oder -optionen bereitzustellen. Sie können beispielsweise einen Datenbanknamen, einen Tabellennamen, einen Benutzernamen und ein Passwort eingeben.
Beispielsweise geben Sie für OpenSearch die folgenden Schlüssel-Wert-Paare ein, wie unter beschrieben: Tutorial: Den AWS Glue Connector für Elasticsearch verwenden
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Ein Beispiel für die mindestens zu verwendenden Verbindungsoptionen finden Sie im Beispieltestskript MinimalSparkConnectorTest.scala on GitHub, das die Verbindungsoptionen zeigt, die Sie normalerweise in einer Verbindung bereitstellen würden.
- Athena
-
-
Table name (Tabellenname): Der Name der Tabelle in der Datenquelle. Wenn Sie einen Konnektor zum Lesen aus CloudWatch Athena-Logs verwenden, würden Sie den Tabellennamen all_log_streams eingeben.
-
Athena schema name (Name des Athena-Schemas): Wählen Sie das Schema in Ihrer Athena-Datenquelle aus, das der Datenbank entspricht, die die Tabelle enthält. Wenn Sie einen Konnektor zum Lesen aus CloudWatch Athena-Logs verwenden, würden Sie einen Schemanamen eingeben, der dem ähnelt/aws/glue/name.
-
Schema: Da AWS Glue Studio Informationen in der Verbindung gespeicherte Informationen verwendet, um auf die Datenquelle zuzugreifen, anstatt Metadateninformationen aus einer Data-Catalog-Tabelle abzurufen, müssen Sie die Schemametadaten für die Datenquelle bereitstellen. Klicken Sie auf Add schema (Schema hinzufügen), um den Schema-Editor zu öffnen.
Anweisungen zur Verwendung des Schema-Editors finden Sie unter Bearbeiten des Schemas in einem benutzerdefinierten Transformationsknoten.
-
Additional connection options (Zusätzliche Verbindungsoptionen): Geben Sie nach Bedarf weitere Schlüssel-Wert-Paare ein, um zusätzliche Verbindungsinformationen oder -optionen bereitzustellen.
Ein Beispiel finden Sie in der README.md Datei unter https://github.com/aws-samples/aws-glue-samples/tree/master/ /Development/Athena GlueCustomConnectors. In den Schritten in diesem Dokument zeigt der Beispiel-Code die minimal erforderlichen Verbindungsoptionen tableName, schemaName und className an. Im Code-Beispiel werden diese Optionen als Teil der Variable optionsMap spezifiziert, aber Sie können sie für Ihre Verbindung angeben und dann die Verbindung verwenden.
-
(Optional) Nachdem Sie die erforderlichen Informationen angegeben haben, können Sie mit der Registerkarte Output schema (Ausgabeschema) im Bereich mit den Knotendetails das daraus resultierende Datenschema für die Datenquelle sehen. Das auf dieser Registerkarte angezeigte Schema wird von allen untergeordneten Knoten verwendet, die Sie dem Auftragsdiagramm hinzufügen.
-
(Optional) Nachdem Sie die Knoteneigenschaften und Datenquelleneigenschaften konfiguriert haben, sehen Sie auf der Registerkarte Data preview (Datenvorschau) im Bereich mit den Knotendetails eine Vorschau des Datensatzes aus Ihrer Datenquelle. Wenn Sie diese Registerkarte zum ersten Mal für einen Knoten in Ihrem Job auswählen, werden Sie aufgefordert, eine Rolle für den Zugriff auf die Daten anzugeben. IAM Die Nutzung dieser Funktion ist mit Kosten verbunden, und die Abrechnung beginnt, sobald Sie eine IAM Rolle angeben.
Konfigurieren von Zieleigenschaften für Knoten, die Connectors verwenden
Wenn Sie einen Connector für den Datenzieltyp verwenden, müssen Sie die Eigenschaften des Datenzielknotens konfigurieren.
Eigenschaften für einen Datenzielknoten konfigurieren, der einen Connector verwendet
-
Wählen Sie den Zielknoten der Connector-Daten im Auftragsdiagramm aus. Wählen Sie dann auf der rechten Seite im Bereich „Node Details“ (Knotendetails) die Registerkarte Data target properties (Datenzieleigenschaften) aus, falls sie nicht bereits ausgewählt ist.
-
Wählen Sie auf der Registerkarte Data target properties (Datenzieleigenschaften) die Verbindung für Schreibvorgänge im Ziel aus.
Geben Sie die zusätzlichen Informationen ein, die für jeden Verbindungstyp erforderlich sind:
- JDBC
-
-
Connection (Verbindung): Wählen Sie die Verbindung aus, die Sie mit Ihrem Connector verwenden möchten. Weitere Informationen zum Herstellen einer Verbindung finden Sie unter Erstellen von Verbindungen für Connectors.
-
Table name (Tabellenname): Der Name der Tabelle im Datenziel. Wenn das Datenziel den Begriff Tabelle nicht verwendet, geben Sie den Namen einer geeigneten Datenstruktur an, wie in den Informationen zur Verwendung des benutzerdefinierten Connectors angegeben (verfügbar unter AWS Marketplace).
-
Batch size (Batchgröße) (Optional): Geben Sie die Anzahl der Zeilen oder Datensätze ein, die in einem einzigen Vorgang in die Zieltabelle eingefügt werden sollen. Der Standardwert lautet 1 000.
- Spark
-
-
Connection (Verbindung): Wählen Sie die Verbindung aus, die Sie mit Ihrem Connector verwenden möchten. Wenn Sie zuvor keine Verbindung erstellt haben, wählen Sie Create connection (Verbindung erstellen) aus. Weitere Informationen zum Herstellen einer Verbindung finden Sie unter Erstellen von Verbindungen für Connectors.
-
Connection options (Verbindungsoptionen): Geben Sie nach Bedarf weitere Schlüssel-Wert-Paare ein, um zusätzliche Verbindungsinformationen oder -optionen bereitzustellen. Sie können einen Datenbanknamen, einen Tabellennamen, einen Benutzernamen und ein Passwort eingeben.
Beispielsweise geben Sie für OpenSearch die folgenden Schlüssel-Wert-Paare ein, wie unter beschrieben: Tutorial: Den AWS Glue Connector für Elasticsearch verwenden
-
es.net.http.auth.user :
username
-
es.net.http.auth.pass :
password
-
es.nodes : https://<Elasticsearch
endpoint>
-
es.port : 443
-
path: <Elasticsearch
resource>
-
es.nodes.wan.only : true
Ein Beispiel für die mindestens zu verwendenden Verbindungsoptionen finden Sie im Beispieltestskript MinimalSparkConnectorTest.scala on GitHub, das die Verbindungsoptionen zeigt, die Sie normalerweise in einer Verbindung bereitstellen würden.
-
Nachdem Sie die erforderlichen Informationen angegeben haben, können Sie mit der Registerkarte Output schema (Ausgabeschema) im Bereich mit den Knotendetails das daraus resultierende Datenschema für die Datenquelle sehen.