Nach reiflicher Überlegung haben wir uns entschieden, Amazon Kinesis Data Analytics für SQL-Anwendungen einzustellen:
1. Ab dem 1. September 2025 werden wir keine Bugfixes für Amazon Kinesis Data Analytics for SQL-Anwendungen bereitstellen, da wir aufgrund der bevorstehenden Einstellung nur eingeschränkten Support dafür haben werden.
2. Ab dem 15. Oktober 2025 können Sie keine neuen Kinesis Data Analytics for SQL-Anwendungen mehr erstellen.
3. Wir werden Ihre Anwendungen ab dem 27. Januar 2026 löschen. Sie können Ihre Amazon Kinesis Data Analytics for SQL-Anwendungen nicht starten oder betreiben. Ab diesem Zeitpunkt ist kein Support mehr für Amazon Kinesis Data Analytics for SQL verfügbar. Weitere Informationen finden Sie unter Einstellung von Amazon Kinesis Data Analytics für SQL-Anwendungen.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon-Kinesis-Data-Analytics for SQL-Anwendungen: So funktioniert's
Anmerkung
Nach dem 12. September 2023 können Sie keine neuen Anwendungen mit Kinesis Data Firehose als Quelle erstellen, wenn Sie nicht bereits Kinesis Data Analytics for SQL. Weitere Informationen finden Sie unter Limits.
Eine Anwendung ist die primäre Ressource in Amazon-Kinesis-Data-Analytics, die Sie in Ihrem Konto erstellen können. Sie können Anwendungen mithilfe der AWS Management Console oder der Kinesis Data Analytics Analytics-API erstellen und verwalten. Kinesis Data Analytics bietet API-Operationen zur Verwaltung von Anwendungen. Eine Liste der verfügbaren API-Operationen finden Sie unter Aktionen.
Kinesis Data Analytics-Anwendungen lesen und verarbeiten kontinuierlich Streaming-Daten in Echtzeit. Sie schreiben Anwendungscode mithilfe von SQL, um die eingehenden Streaming-Daten zu verarbeiten und eine Ausgabe zu erzeugen. Anschließend schreibt Kinesis Data Analytics die Ausgabe an ein konfiguriertes Ziel. Das folgende Diagramm zeigt eine typische Anwendungsarchitektur.
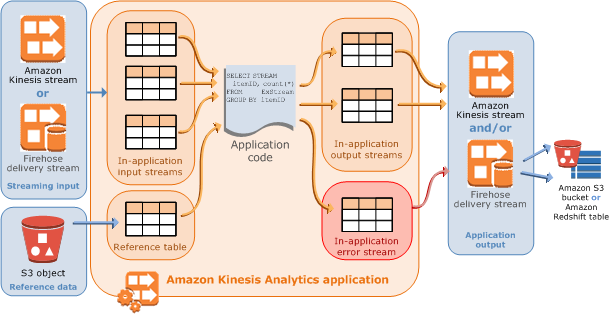
Jede Anwendung hat einen Namen, eine Beschreibung, eine Versions-ID und einen Status. Amazon-Kinesis-Data-Analytics weist eine Versions-ID zu, sobald Sie eine Anwendung erstellen. Diese Versionskennung wird aktualisiert, wenn Sie Teile der Anwendungskonfiguration aktualisieren. Wenn Sie beispielsweise eine Eingabekonfiguration hinzufügen oder löschen, eine Referenzdatenquelle hinzufügen, eine Ausgabekonfiguration hinzufügen oder löschen oder den Anwendungscode aktualisieren, aktualisiert Kinesis Data Analytics die aktuelle Anwendungsversions-ID. Außerdem verwaltet Kinesis Data Analytics die Zeitstempel der Anwendungserstellung und des letzten Änderungsdatums.
Zusätzlich zu diesen grundlegenden Eigenschaften enthalten Anwendungen Folgendes:
-
Eingabedaten: – die Streaming-Quelle für Ihre Anwendung. Sie können entweder einen Kinesis-Datenstream oder einen Firehose-Datenbereitstellungsstream als Streaming-Quelle auswählen. In der Eingabekonfiguration ordnen Sie die Streaming-Quelle einem In-Application-Eingabe-Stream zu. Der In-Application-Stream entspricht einer kontinuierlich aktualisierten Tabelle, auf die Sie die Operationen
SELECTundINSERT SQLanwenden können. In Ihrem Anwendungscode können Sie zusätzliche In-Application-Streams erstellen, um Zwischenergebnisse aus Abfragen zu speichern.Sie können optional eine einzelne Streaming-Quelle in mehrere In-Application-Eingabe-Streams aufteilen, um den Durchsatz zu verbessern. Weitere Informationen erhalten Sie unter Einschränkungen und Konfigurieren der Anwendungseingabe.
Amazon-Kinesis-Data-Analytics stellt für jeden In-Application-Stream eine Zeitstempelspalte mit dem Namen Zeitstempel und die ROWTIME-Spalte bereit. Sie verwenden diese Spalte in Abfragen mit Zeitfenstern. Weitere Informationen finden Sie unter Abfragen mit Fenstern.
Sie können optional eine Referenzdatenquelle zur Erweiterung Ihres Eingabedaten-Streams innerhalb der Anwendung konfigurieren. Sie erhalten dann eine In-Application-Referenztabelle. Sie müssen Ihre Referenzdaten als Objekt in Ihrem S3-Bucket speichern. Wenn die Anwendung gestartet wird, liest Amazon-Kinesis-Data-Analytics das Amazon-S3-Objekt und erstellt eine In-Application-Tabelle. Weitere Informationen finden Sie unter Konfigurieren der Anwendungseingabe.
-
Anwendungscode – Eine Reihe von SQL-Anweisungen, die Eingabedaten verarbeiten und Ausgabedaten erzeugen. Sie können SQL-Anweisungen für In-Application-Streams und Referenztabellen schreiben. Sie können auch JOIN-Abfragen erstellen, um Daten aus diesen beiden Quellen zu kombinieren.
Weitere Informationen zu den SQL-Sprachelementen, die von Kinesis Data Analytics unterstützt werden, finden Sie in der SQL-Referenz zu Amazon-Kinesis-Data-Analytics.
In seiner einfachsten Form kann der Anwendungscode aus einer einzelnen SQL-Anweisung bestehen, die aus Streaming-Eingabedaten auswählt und die Ergebnisse in Streaming-Ausgabedaten einfügt. Es kann sich auch um eine Reihe von SQL-Anweisungen handeln, wobei die Ausgabedaten einer SQL-Anweisung als Eingabedaten für die nächste SQL-Anweisung verwendet werden können. Außerdem können Sie Anwendungscode erstellen, um einen Eingabe-Stream in mehrere Streams aufzuteilen. Sie können dann zusätzliche Abfragen anwenden, um diese Streams zu verarbeiten. Weitere Informationen finden Sie unter Anwendungscode.
-
Output – Im Anwendungscode werden Abfrageergebnisse in In-Application-Streams eingespeist. Sie können in Ihrem Anwendungscode weitere In-Application-Streams erstellen, um Zwischenergebnisse zu speichern. Anschließend können Sie optional die Anwendungsausgabe so konfigurieren, dass Daten jener In-Application-Streams, die die Anwendungsausgabe enthalten (diese Streams werden auch als In-Application-Ausgabe-Streams bezeichnet), in externen Zielen dauerhaft gespeichert werden. Externe Ziele können ein Firehose-Lieferstream oder ein Kinesis-Datenstrom sein. Beachten Sie die folgenden Hinweise zu diesen Zielen:
-
Sie können einen Firehose-Lieferstream so konfigurieren, dass Ergebnisse in Amazon S3, Amazon Redshift oder Amazon OpenSearch Service (OpenSearch Service) geschrieben werden.
-
Sie können die Anwendungsausgabe auch in ein benutzerdefiniertes Ziel schreiben (anstatt in Amazon-S3 oder Amazon-Redshift). Legen Sie dazu in Ihrer Ausgabekonfiguration einen Kinesis-Datenstrom als Ziel fest. Anschließend konfigurieren Sie so, AWS Lambda dass der Stream abgefragt und Ihre Lambda-Funktion aufgerufen wird. Ihr Lambda-Funktionscode erhält Stream-Daten als Eingabe. Sie können die eingehenden Daten in Ihrem Lambda-Funktionscode an das gewünschte benutzerdefinierte Ziel schreiben. Weitere Informationen finden Sie unter Verwenden AWS Lambda mit Amazon Kinesis Data Analytics.
Weitere Informationen finden Sie unter Konfigurieren der Anwendungsausgabe.
-
Beachten Sie außerdem Folgendes:
-
Amazon-Kinesis-Data-Analytics benötigt Berechtigungen zum Lesen von Datensätzen aus einer Streaming-Quelle und zum Schreiben der Ausgabe von Anwendungen an externe Ziele. Sie verwenden IAM-Rollen, um diese Berechtigungen zu erteilen.
-
Kinesis Data Analytics stellt automatisch für jede Anwendung einen In-Application-Fehler-Stream bereit. Wenn Ihre Anwendung Probleme bei der Verarbeitung bestimmter Datensätze hat (z. B. wegen eines Typenkonflikts oder später Verfügbarkeit) wird dieser Datensatz in den Fehler-Stream geschrieben. Sie können die Ausgabe von Anwendungen so konfigurieren, dass Kinesis Data Analytics angewiesen wird, die Daten aus dem Fehler-Stream zur weiteren Auswertung an einem externen Ziel dauerhaft zu speichern. Weitere Informationen finden Sie unter Fehlerbehandlung.
-
Amazon-Kinesis-Data-Analytics stellt sicher, dass die Ausgabedatensätze Ihrer Anwendung in das konfigurierte Ziel geschrieben werden. Es wird ein „Mindestens einmal“-Verarbeitungs- und Bereitstellungsmodell verwendet – auch dann, wenn eine Anwendung unterbrochen wird. Weitere Informationen finden Sie unter Bereitstellungsmodell für die Weiterleitung der Anwendungsausgabe an ein externes Ziel.
