Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Minimieren Sie den Planungsaufwand
Wie in den wichtigsten Themen in Apache Spark besprochen, generiert der Spark-Treiber den Ausführungsplan. Auf der Grundlage dieses Plans werden dem Spark-Executor Aufgaben für die verteilte Verarbeitung zugewiesen. Der Spark-Treiber kann jedoch zu einem Engpass werden, wenn es eine große Anzahl kleiner Dateien gibt oder wenn der eine große Anzahl von AWS Glue Data Catalog Partitionen enthält. Analysieren Sie die folgenden Kennzahlen, um einen hohen Planungsaufwand zu ermitteln.
CloudWatch Metriken
Überprüfen Sie die CPUAuslastung und die Speicherauslastung für die folgenden Situationen:
-
Die CPUAuslastung des Spark-Treibers und die Speicherauslastung werden als hoch aufgezeichnet. Normalerweise verarbeitet der Spark-Treiber Ihre Daten nicht, sodass die CPU Last- und Speicherauslastung nicht ansteigt. Wenn die Amazon S3 S3-Datenquelle jedoch zu viele kleine Dateien enthält, kann das Auflisten aller S3-Objekte und das Verwalten einer großen Anzahl von Aufgaben zu einer hohen Ressourcenauslastung führen.
-
Es besteht eine lange Pause, bis die Verarbeitung in Spark Executor beginnt. Im folgenden Beispiel-Screenshot ist die CPU Last des Spark-Executors bis 10:57 Uhr zu niedrig, obwohl der Job um 10:00 Uhr gestartet wurde. AWS Glue Dies deutet darauf hin, dass der Spark-Treiber möglicherweise lange braucht, um einen Ausführungsplan zu generieren. In diesem Beispiel dauert das Abrufen der großen Anzahl von Partitionen im Datenkatalog und das Auflisten der großen Anzahl kleiner Dateien im Spark-Treiber sehr lange.
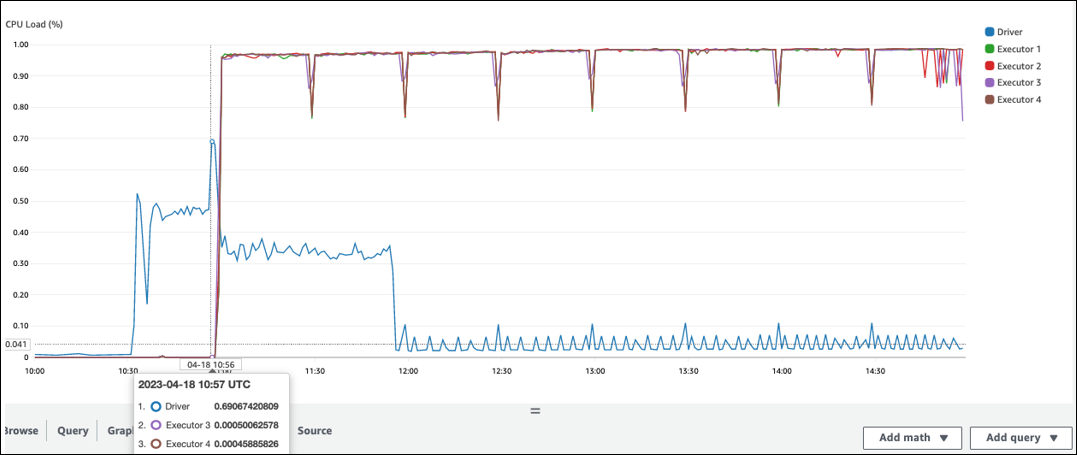
Spark-Benutzeroberfläche
Auf der Registerkarte Job in der Spark-Benutzeroberfläche können Sie die Zeit für die Einreichung sehen. Im folgenden Beispiel hat der Spark-Treiber Job0 um 10:56:46 Uhr gestartet, obwohl der Job um 10:00:00 Uhr gestartet wurde. AWS Glue

Sie können auch die Aufgaben (für alle Phasen): Erfolgreich/Gesamtzeit auf der Registerkarte Job sehen. In diesem Fall wird die Anzahl der Aufgaben als aufgezeichnet. 58100 Wie im Abschnitt Amazon S3 auf der Seite Aufgaben parallelisieren erklärt, entspricht die Anzahl der Aufgaben in etwa der Anzahl der S3-Objekte. Das bedeutet, dass es in Amazon S3 etwa 58.100 Objekte gibt.
Weitere Informationen zu diesem Job und zum Zeitplan finden Sie auf der Registerkarte Phase. Wenn Sie einen Engpass beim Spark-Treiber feststellen, sollten Sie die folgenden Lösungen in Betracht ziehen:
-
Wenn Amazon S3 zu viele Dateien enthält, beachten Sie die Hinweise zur übermäßigen Parallelität im Abschnitt Zu viele Partitionen auf der Seite Aufgaben parallelisieren.
-
Wenn Amazon S3 über zu viele Partitionen verfügt, beachten Sie die Hinweise zur übermäßigen Partitionierung im Abschnitt Zu viele Amazon S3 S3-Partitionen auf der Seite Menge der gescannten Daten reduzieren. Aktivieren Sie AWS Glue Partitionsindizes, wenn es viele Partitionen gibt, um die Latenz beim Abrufen von Partitionsmetadaten aus dem Datenkatalog zu reduzieren. Weitere Informationen finden Sie unter Verbessern der Abfrageleistung mithilfe von AWS Glue Partitionsindizes
. -
Wenn zu JDBC viele Partitionen vorhanden sind, verringern Sie den
hashpartitionWert. -
Wenn DynamoDB zu viele Partitionen hat, verringern Sie den
dynamodb.splitsWert. -
Wenn Streaming-Jobs zu viele Partitionen haben, verringern Sie die Anzahl der Shards.
