Amazon Redshift unterstützt die Verwendung von Python-UDFs nach dem 30. Juni 2026 nicht mehr. Wir werden damit beginnen, es schrittweise durchzusetzen. Weitere Informationen zu den Einzelheiten zum Ende der Lebensdauer und zu den Migrationsoptionen von Python finden Sie in dem Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: So laden Sie Daten aus Amazon S3
In diesem Tutorial durchlaufen Sie den kompletten Prozess des Ladens von Daten in Ihre Amazon-Redshift-Datenbanktabellen aus Datendateien in einem Amazon-S3-Bucket.
In diesem Tutorial führen Sie folgende Aufgaben aus:
-
Laden Sie Datendateien als kommagetrennte Werte (CSV), als durch bestimmte Zeichen getrennte Werte und Formate mit fester Breite herunter.
-
Erstellen eines Amazon-S3-Buckets und Upload der Datendateien zu diesem Bucket.
-
Starten eines Amazon-Redshift-Clusters und Erstellen von Datenbanktabellen.
-
Verwenden von COPY-Befehlen zum Laden der Tabellen aus den Datendateien auf Amazon S3.
-
Beheben von Ladefehlern und Modifizieren Ihrer COPY-Befehle zur Behebung der Fehler.
Voraussetzungen
Sie benötigen die folgenden Voraussetzungen:
-
Ein AWS Konto zum Starten eines Amazon Redshift Redshift-Clusters und zum Erstellen eines Buckets in Amazon S3.
-
Ihre AWS Anmeldeinformationen (IAM-Rolle) zum Laden von Testdaten aus Amazon S3. Wenn Sie eine neue IAM-Rolle benötigen, wechseln Sie zu Erstellen von IAM-Rollen.
-
Ein SQL-Client, z. B. der Konsolenabfrage-Editor von Amazon Redshift.
Dieses Tutorial kann unabhängig von anderen absolviert werden. Zusätzlich zu diesem Tutorial empfehlen wir die folgenden Tutorials, um ein umfassenderes Verständnis vom Entwurf und von der Verwendung von Amazon-Redshift-Datenbanken zu erhalten:
-
Das Handbuch Erste Schritte mit Amazon Redshift begleitet Sie beim Erstellen eines Amazon-Redshift-Clusters und dem Laden von Beispieldaten.
-Übersicht
Sie können zum Hinzufügen von Daten zu Ihren Amazon-Redshift-Tabellen einen INSERT-Befehl oder einen COPY-Befehl verwenden. Der COPY-Befehl bietet den Umfang und die Geschwindigkeit eines Data Warehouse von Amazon Redshift und ist damit um ein Vielfaches schneller und effizienter als INSERT-Befehle.
Der COPY-Befehl nutzt die massive Parallelverarbeitungsarchitektur (Massively Parallel Processing, MPP) von Amazon Redshift, um Daten parallel aus mehreren Datenquellen zu lesen und zu laden. Sie können aus Datendateien in Amazon S3, Amazon EMR oder auf jedem Remote-Host laden, der über eine Secure Shell (SSH)-Verbindung erreichbar ist. Oder Sie können direkt aus einer Amazon-DynamoDB-Tabelle laden.
In diesem Tutorial verwenden Sie den Befehl COPY, um Daten aus Amazon S3 zu laden. Viele der hier vorgestellten Prinzipien gelten auch für das Laden aus anderen Datenquellen.
Weitere Informationen zur Verwendung des COPY-Befehls finden Sie in diesen Ressourcen:
Schritt 1: Erstellen eines Clusters
Wenn Sie bereits einen Cluster haben, den Sie verwenden möchten, können Sie diesen Schritt überspringen.
Verwenden Sie für die Übungen in diesem Tutorial einen Vierknoten-Cluster.
So erstellen Sie einen Cluster
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. Wählen Sie über das Navigationsmenü Dashboard für bereitgestellte Cluster aus.
Wichtig
Stellen Sie sicher, dass Sie über die erforderlichen Berechtigungen verfügen, um die Cluster-Operationen durchzuführen. Informationen zur Erteilung der erforderlichen Berechtigungen finden Sie unter Autorisieren von Amazon Redshift für den Zugriff auf AWS Dienste.
-
Wählen Sie oben rechts die AWS Region aus, in der Sie den Cluster erstellen möchten. Wählen Sie für die Zwecke dieses Tutorials USA West (Oregon) aus.
-
Wählen Sie im Navigationsmenü Clusters (Cluster) und dann Create cluster (Cluster erstellen) aus. Die Seite Create Cluster (Cluster erstellen) wird angezeigt.
-
Auf der Seite Cluster erstellen geben Sie die Parameter für Ihren Cluster ein. Wählen Sie Ihre eigenen Werte für die Parameter aus, außer die folgenden Werte zu ändern:
Wählen Sie
dc2.largeals Knotentyp.Klicken Sie für die Anzahl der Knoten auf
4.Wählen Sie im Abschnitt Cluster permissions (Clusterberechtigungen) eine IAM-Rolle aus Available IAM roles (Verfügbare IAM-Rollen) aus. Diese Rolle sollte eine sein, die Sie zuvor erstellt haben und die Zugriff auf Amazon S3 hat. Wählen Sie dann Associate IAM role (IAM-Rolle zuordnen) aus, um sie der Liste der Associated IAM roles (Zugeordneten IAM-Rollen) für den Cluster hinzuzufügen.
-
Wählen Sie Create cluster (Cluster erstellen).
Befolgen Sie die Schritte im Handbuch Erste Schritte mit Amazon Redshift zur Verbindung zu Ihrem Cluster von einem SQL-Client aus sowie zum Testen einer Verbindung. Sie müssen die verbleibenden Schritte aus "Erste Schritte" nicht durchführen, um Tabellen zu erstellen, Daten hochzuladen und Beispielabfragen auszuprobieren.
Schritt 2: Herunterladen der Datendateien
In diesem Schritt laden Sie einen Satz Beispieldatendateien auf Ihren Computer herunter. Im nächsten Schritt laden Sie die Dateien in einen Amazon S3 Bucket hoch.
So laden Sie die Datendateien herunter:
-
Laden Sie die komprimierte Datei herunter: LoadingDataSampleFiles.zip.
-
Extrahieren Sie die Dateien in einen Ordner auf Ihrem Computer.
-
Prüfen Sie, ob Ihr Ordner die folgenden Dateien enthält.
customer-fw-manifest customer-fw.tbl-000 customer-fw.tbl-000.bak customer-fw.tbl-001 customer-fw.tbl-002 customer-fw.tbl-003 customer-fw.tbl-004 customer-fw.tbl-005 customer-fw.tbl-006 customer-fw.tbl-007 customer-fw.tbl.log dwdate-tab.tbl-000 dwdate-tab.tbl-001 dwdate-tab.tbl-002 dwdate-tab.tbl-003 dwdate-tab.tbl-004 dwdate-tab.tbl-005 dwdate-tab.tbl-006 dwdate-tab.tbl-007 part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
Schritt 3: Hochladen der Datei in einen Amazon S3 Bucket
In diesem Schritt erstellen Sie einen Amazon S3 Bucket und laden die Datendateien in diesen Bucket.
Hochladen der Dateien in einen Amazon S3 Bucket
-
Erstellen eines Buckets in Amazon S3.
Weitere Informationen zum Erstellen eines Buckets finden Sie unter Erstellen von Buckets im Benutzerhandbuch für Amazon Simple Storage Service.
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/
. -
Wählen Sie Create Bucket (Bucket erstellen) aus.
-
Wählen Sie eine AWS-Region.
Erstellen Sie den Bucket in derselben Region, in der sich auch Ihr Cluster befindet. Wenn sich Ihr Cluster in der Region USA West (Oregon) befindet, wählen Sie USA West (Oregon) Region (us-west-2) aus.
-
Geben Sie im Feld Bucket-Name des Dialogfelds Bucket erstellen einen Bucket-Namen ein.
Der von Ihnen gewählte Bucket-Name muss unter allen in Amazon S3 vorhandenen Bucket-Namen eindeutig sein. Eine Möglichkeit, für Eindeutigkeit zu sorgen, besteht darin, vor den Namen von Buckets den Namen Ihres Unternehmens zu setzen. Bucket-Namen müssen bestimmten Regeln folgen. Weitere Informationen finden Sie unter Bucket-Einschränkungen und -Limits im Benutzerhandbuch zu Amazon Simple Storage Service.
-
Wählen Sie die empfohlenen Standardwerte für die restlichen Optionen.
-
Wählen Sie Create Bucket (Bucket erstellen) aus.
Wenn Amazon S3 Ihren Bucket erfolgreich erstellt hat, wird der leere Bucket in der Konsole im Feld Buckets angezeigt.
-
-
Erstellen Sie einen Ordner.
-
Wählen Sie den Namen des neuen Buckets.
-
Wählen Sie die Schaltfläche Ordner erstellen aus.
-
Geben Sie als Namen für den neuen Ordner ein
load.Anmerkung
Der von Ihnen erstellte Bucket befindet sich nicht in einer Sandbox. In dieser Übung fügen Sie Objekte zu einem echten Bucket hinzu. Für die Zeit, in der Sie die Objekte im Bucket speichern, wird Ihnen ein Nominalbetrag berechnet. Weitere Informationen zu Amazon-S3-Preisen finden Sie unter Amazon-S3-Preise
.
-
-
Laden Sie die Datendateien in den neuen Amazon S3 Bucket.
-
Wählen Sie auf den Namen des Datenordners aus.
-
Wählen Sie im Assistenten für das Hochladen die Option Dateien hinzufügen.
Befolgen Sie die Amazon-S3-Konsolenanweisungen, um alle heruntergeladenen und extrahierten Dateien hochzuladen.
-
Klicken Sie auf Upload.
-
Benutzeranmeldeinformationen
Der COPY-Befehl in Amazon Redshift muss einen Lesezugriff auf Dateiobjekte im Amazon-S3-Bucket besitzen. Wenn Sie dieselben Benutzer-Anmeldeinformationen verwenden, um den Amazon-S3-Bucket zu erstellen und den Amazon-Redshift-Befehl COPY auszuführen, verfügt der Befehl COPY über alle erforderlichen Berechtigungen. Wenn Sie andere Benutzeranmeldeinformationen verwenden möchten, können Sie den Zugriff über die Amazon-S3-Zugriffssteuerungselemente gewähren. Der Amazon Redshift COPY-Befehl erfordert mindestens ListBucket und GetObject Berechtigungen für den Zugriff auf die Dateiobjekte im Amazon S3 S3-Bucket. Weitere Informationen über Zugriffsrichtlinien für Amazon-S3-Ressourcen finden Sie unter Managing access permissions to your Amazon S3 resources (Verwaltung der Zugriffsberechtigungen zu Ihren Amazon-S3-Ressourcen).
Schritt 4: Erstellen der Beispieltabellen
Für dieses Tutorial verwenden Sie einen Satz von Tabellen, die auf dem Schema „Star Schema Benchmark (SSB)“ basieren. Das folgende Diagramm zeigt das SSB-Datenmodell.
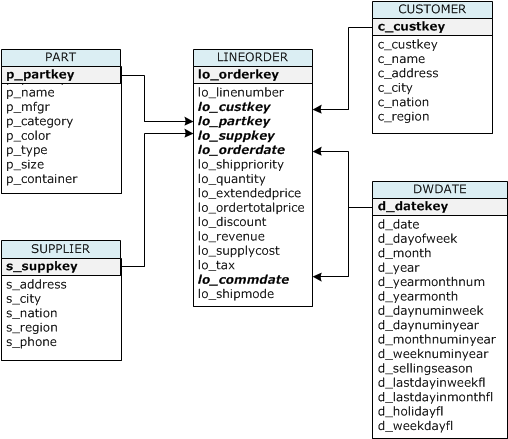
Die SSB-Tabellen sind möglicherweise bereits in der aktuellen Datenbank vorhanden. Wenn ja, führen Sie einen Drop für die Tabellen aus, um sie aus der Datenbank zu entfernen, bevor Sie sie im nächsten Schritt mit den Befehlen CREATE TABLE erstellen. Die in diesem Tutorial verwendeten Tabellen haben möglicherweise andere Attribute als die vorhandenen Tabellen.
So erstellen Sie die Beispieltabellen:
-
Um die SSB-Tabellen zu löschen, führen Sie die folgenden Befehle in Ihrem SQL-Client aus.
drop table part cascade; drop table supplier; drop table customer; drop table dwdate; drop table lineorder; -
Führen Sie die folgenden CREATE TABLE-Befehle in Ihrem SQL-Client aus.
CREATE TABLE part ( p_partkey INTEGER NOT NULL, p_name VARCHAR(22) NOT NULL, p_mfgr VARCHAR(6), p_category VARCHAR(7) NOT NULL, p_brand1 VARCHAR(9) NOT NULL, p_color VARCHAR(11) NOT NULL, p_type VARCHAR(25) NOT NULL, p_size INTEGER NOT NULL, p_container VARCHAR(10) NOT NULL ); CREATE TABLE supplier ( s_suppkey INTEGER NOT NULL, s_name VARCHAR(25) NOT NULL, s_address VARCHAR(25) NOT NULL, s_city VARCHAR(10) NOT NULL, s_nation VARCHAR(15) NOT NULL, s_region VARCHAR(12) NOT NULL, s_phone VARCHAR(15) NOT NULL ); CREATE TABLE customer ( c_custkey INTEGER NOT NULL, c_name VARCHAR(25) NOT NULL, c_address VARCHAR(25) NOT NULL, c_city VARCHAR(10) NOT NULL, c_nation VARCHAR(15) NOT NULL, c_region VARCHAR(12) NOT NULL, c_phone VARCHAR(15) NOT NULL, c_mktsegment VARCHAR(10) NOT NULL ); CREATE TABLE dwdate ( d_datekey INTEGER NOT NULL, d_date VARCHAR(19) NOT NULL, d_dayofweek VARCHAR(10) NOT NULL, d_month VARCHAR(10) NOT NULL, d_year INTEGER NOT NULL, d_yearmonthnum INTEGER NOT NULL, d_yearmonth VARCHAR(8) NOT NULL, d_daynuminweek INTEGER NOT NULL, d_daynuminmonth INTEGER NOT NULL, d_daynuminyear INTEGER NOT NULL, d_monthnuminyear INTEGER NOT NULL, d_weeknuminyear INTEGER NOT NULL, d_sellingseason VARCHAR(13) NOT NULL, d_lastdayinweekfl VARCHAR(1) NOT NULL, d_lastdayinmonthfl VARCHAR(1) NOT NULL, d_holidayfl VARCHAR(1) NOT NULL, d_weekdayfl VARCHAR(1) NOT NULL ); CREATE TABLE lineorder ( lo_orderkey INTEGER NOT NULL, lo_linenumber INTEGER NOT NULL, lo_custkey INTEGER NOT NULL, lo_partkey INTEGER NOT NULL, lo_suppkey INTEGER NOT NULL, lo_orderdate INTEGER NOT NULL, lo_orderpriority VARCHAR(15) NOT NULL, lo_shippriority VARCHAR(1) NOT NULL, lo_quantity INTEGER NOT NULL, lo_extendedprice INTEGER NOT NULL, lo_ordertotalprice INTEGER NOT NULL, lo_discount INTEGER NOT NULL, lo_revenue INTEGER NOT NULL, lo_supplycost INTEGER NOT NULL, lo_tax INTEGER NOT NULL, lo_commitdate INTEGER NOT NULL, lo_shipmode VARCHAR(10) NOT NULL );
Schritt 5: Ausführen der COPY-Befehle
Sie führen COPY-Befehle aus, um jede der Tabellen im SSB-Schema zu laden. Die Beispiele für COPY-Befehle demonstrieren das Laden aus unterschiedlichen Dateiformaten unter Verwendung verschiedener COPY-Befehlsoptionen sowie die Behebung von Ladefehlern.
COPY-Befehlssyntax
Die grundlegende COPY-Befehlssyntax ist wie folgt.
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
Zur Ausführung eines COPY-Befehls geben Sie die folgenden Werte an.
Tabellenname
Die Zieltabelle für den COPY-Befehl. Die Tabelle muss in der Datenbank bereits vorhanden sein. Die Tabelle kann temporär oder persistent sein. Der COPY-Befehl fügt die neuen Eingabedaten den vorhandenen Zeilen in der Tabelle an.
Spaltenliste
Standardmäßig lädt COPY Felder aus den Quelldaten in ihrer Reihenfolge in die Tabellenspalten. Sie können optional eine Spaltenliste angeben, d. h. eine durch Kommas getrennte Liste von Spaltennamen, um Datenfelder bestimmten Spalten zuzuordnen. In diesem Tutorial verwenden Sie keine Spaltenlisten. Weitere Informationen finden Sie unter Column List in der Referenz zum COPY-Befehl.
Datenquelle
Sie können den COPY-Befehl verwenden, um Daten aus einem Amazon-S3-Bucket, aus einem Amazon-EMR-Cluster, über eine SSH-Verbindung aus einem Remote-Host oder aus einer Amazon-DynamoDB-Tabelle zu laden. Für dieses Tutorial laden Sie Datendateien in einen Amazon-S3-Bucket. Beim Laden von Amazon S3 müssen Sie den Namen des Buckets und den Speicherort der Datendateien angeben. Dazu geben Sie entweder einen Objektpfad für die Datendateien oder den Speicherort einer Manifestdatei an, die jede Datendatei und ihren Speicherort explizit auflistet.
-
Schlüsselpräfix
Ein in Amazon S3 gespeichertes Objekt wird durch einen Objektschlüssel eindeutig definiert, der den Bucketnamen, eventuelle Ordnernamen sowie den Objektnamen enthält. Ein Schlüsselpräfix bezieht sich auf eine Reihe von Objekten, die das gleiche Präfix haben. Der Objektpfad ist ein Schlüsselpräfix, das der COPY-Befehl verwendet, um alle Objekte mit dem gleichen Schlüsselpräfix zu laden. Beispielsweise kann sich das Schlüsselpräfix
custdata.txtauf eine einzelne Datei oder auf einen Satz von Dateien einschließlichcustdata.txt.001,custdata.txt.002und so weiter beziehen. -
Manifestdatei
In einigen Fällen müssen Sie möglicherweise Dateien mit unterschiedlichen Präfixen laden, z. B. aus mehreren Buckets oder Ordnern. In anderen Fällen müssen Sie möglicherweise Dateien ausschließen, die ein Präfix verwenden. In diesen Fällen können Sie eine Manifestdatei verwenden. Eine Manifestdatei führt alle Ladedateien und ihre eindeutigen Objektschlüssel explizit auf. Sie verwenden eine Manifestdatei, um die PART-Tabelle später in diesem Tutorial zu laden.
Anmeldeinformationen
Um auf die AWS Ressourcen zuzugreifen, die die zu ladenden Daten enthalten, müssen Sie die AWS Zugangsdaten für einen Benutzer mit ausreichenden Rechten angeben. Diese Anmeldeinformationen enthalten einen Amazon-Ressourcennamen (ARN) für die IAM-Rolle. Um Daten aus Amazon S3 zu laden, müssen die Anmeldeinformationen ListBucket und GetObject Berechtigungen enthalten. Weitere Anmeldeinformationen sind erforderlich, wenn Ihre Daten verschlüsselt sind. Weitere Informationen finden Sie unter Autorisierungsparameter in der Referenz zum COPY-Befehl. Weitere Informationen zur Verwaltung des Zugriffs finden Sie unter Managing access permissions to your Amazon S3 resources (Verwaltung von Zugriffsberechtigungen für Ihre Amazon-S3-Ressourcen).
Optionen
Sie können mit dem COPY-Befehl eine Reihe von Parametern angeben, um Dateiformate anzugeben, Datenformate zu verwalten, mit Fehlern umzugehen und andere Features zu steuern. In diesem Tutorial verwenden Sie die folgenden COPY-Befehlsoptionen und -Funktionen:
-
Schlüsselpräfix
Informationen zum Laden von mehreren Dateien durch Angabe eines Schlüsselpräfixes finden Sie unter Laden der Tabelle PART mit NULL AS.
-
CSV-Format
Informationen zum Laden von Daten im CSV-Format finden Sie unter Laden der Tabelle PART mit NULL AS.
-
NULL AS
Hinweise zum Laden von PART mit der Option NULL AS finden Sie unter Laden der Tabelle PART mit NULL AS.
-
Character-delimited formatieren
Hinweise zur Verwendung der Option DELIMITER finden Sie unter Die Optionen DELIMITER und REGION.
-
REGION
Informationen zur Verwendung der Option REGION finden Sie unter Die Optionen DELIMITER und REGION.
-
Fixed-format Breite
Informationen zum Laden der Tabelle CUSTOMER aus Daten mit fester Breite finden Sie unter Laden der Tabelle CUSTOMER mit MANIFEST.
-
MAXERROR
Hinweise zur Verwendung der Option MAXERROR finden Sie unter Laden der Tabelle CUSTOMER mit MANIFEST.
-
ACCEPTINVCHARS
Hinweise zur Verwendung der Option ACCEPTINVCHARS finden Sie unter Laden der Tabelle CUSTOMER mit MANIFEST.
-
MANIFEST
Hinweise zur Verwendung der Option MANIFEST finden Sie unter Laden der Tabelle CUSTOMER mit MANIFEST.
-
DATEFORMAT
Hinweise zur Verwendung der Option DATEFORMAT finden Sie unter Laden der Tabelle DWDATE mit DATEFORMAT.
-
GZIP, LZOP und BZIP2
Informationen zum Komprimieren von Dateien finden Sie unter Laden von mehreren Datendateien.
-
COMPUPDATE
Hinweise zur Verwendung der Option COMPUPDATE finden Sie unter Laden von mehreren Datendateien.
-
Mehrere Dateien
Informationen zum Laden mehrerer Dateien finden Sie unter Laden von mehreren Datendateien.
Laden der SSB-Tabellen
Mit den folgenden COPY-Befehlen laden Sie jede der Tabellen im SSB-Schema. Der Befehl für jede Tabelle demonstriert unterschiedliche COPY-Optionen und Fehlerbehebungstechniken.
Gehen Sie zum Laden der SSB-Tabellen wie folgt vor:
Ersetzen Sie den Bucket-Namen und AWS Anmeldedaten
Die COPY-befehle in diesem Tutorial werden im folgenden Format angegeben.
copy table from 's3://<your-bucket-name>/load/key_prefix' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' options;
Gehen Sie für jeden COPY-Befehl wie folgt vor:
-
<your-bucket-name>Ersetzen Sie ihn durch den Namen eines Buckets in derselben Region wie Ihr Cluster.Für diesen Schritt wird davon ausgegangen, dass Bucket und Cluster sich in derselben Region befinden. Alternativ können Sie die Region mittels der Option REGION mit dem Befehl COPY angeben.
-
Ersetzen Sie
<aws-account-id>und<role-name>durch Ihre eigene AWS-Konto und IAM-Rolle. Das Segment der Anmeldedatenzeichenfolge, das in einfachen Anführungszeichen eingeschlossen ist, darf keine Leerzeichen oder Zeilenumbrüche enthalten. Beachten Sie, dass sich das Format des ARNs geringfügig von dem im Beispiel verwendeten Format unterscheiden kann. Am besten kopieren Sie den ARN für die Rolle aus der IAM-Konsole, um sicherzustellen, dass er korrekt ist, wenn Sie die COPY-Befehle ausführen.
Laden der Tabelle PART mit NULL AS
In diesem Schritt verwenden Sie die Optionen CSV und NULL AS, um die PART-Tabelle zu laden.
Der COPY-Befehl kann Daten aus mehreren Dateien parallel laden, was viel schneller ist als das Laden aus einer einzelnen Datei. Zur Demonstration dieses Prinzips sind die Daten für jede Tabelle in diesem Tutorial in acht Dateien unterteilt, obwohl die Dateien sehr klein sind. In einem späteren Schritt vergleichen Sie den Zeitunterschied zwischen dem Laden aus einer einzelnen Datei und dem Laden aus mehreren Dateien. Weitere Informationen finden Sie unter Laden von Datendateien.
Schlüsselpräfix
Sie können aus mehreren Dateien durch die Angabe eines Schlüsselpräfixes den Dateiensatz oder durch die explizite Auflistung der Dateien in einer Manifestdatei laden. In diesem Schritt verwenden Sie ein Schlüsselpräfix. In einem späteren Schritt verwenden Sie eine Manifestdatei. Das Schlüsselpräfix 's3://amzn-s3-demo-bucket/load/part-csv.tbl' lädt den folgenden Satz der Dateien im Ordner load.
part-csv.tbl-000 part-csv.tbl-001 part-csv.tbl-002 part-csv.tbl-003 part-csv.tbl-004 part-csv.tbl-005 part-csv.tbl-006 part-csv.tbl-007
CSV-Format
CSV (Comma Separated Values) ist ein für den Import und den Export von Spreadsheet-Daten häufig verwendetes Format. CSV ist flexibler als das Comma-Delimited Format, da es den Einschluss von Zeichenfolgen mit Anführungszeichen in Feldern erlaubt. Das Standard-Anführungszeichen für COPY aus dem CSV-Format ist das doppelte Anführungszeichen ("), Sie können aber mit der Option QUOTE AS ein anderes Zeichen angeben. Wenn Sie das Anführungszeichen innerhalb des Feldes verwenden, verwenden Sie ein weiteres Anführungszeichen als Escape-Zeichen.
Der folgende Auszug aus einer CSV-formatted Datendatei für die PART-Tabelle zeigt Zeichenketten, die in doppelte Anführungszeichen () "LARGE ANODIZED
BRASS" eingeschlossen sind. Er zeigt außerdem eine Zeichenfolge, die in zwei doppelte Anführungszeichen innerhalb einer Zeichenfolge mit Anführungszeichen eingeschlossen () ist. ("MEDIUM ""BURNISHED"" TIN").
15,dark sky,MFGR#3,MFGR#47,MFGR#3438,indigo,"LARGE ANODIZED BRASS",45,LG CASE 22,floral beige,MFGR#4,MFGR#44,MFGR#4421,medium,"PROMO, POLISHED BRASS",19,LG DRUM 23,bisque slate,MFGR#4,MFGR#41,MFGR#4137,firebrick,"MEDIUM ""BURNISHED"" TIN",42,JUMBO JAR
Die Daten für die PART-Tabelle enthalten Zeichen, die dazu führen, dass COPY fehlschlägt. In dieser Übung finden Sie die Fehler und beheben sie.
Um Daten im CSV-Format zu laden, fügen Sie Ihrem COPY-Befehl csv hinzu. Führen Sie den folgenden Befehl aus, um die PART-Tabelle zu laden.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv;
Sie könnten eine Fehlermeldung ähnlich der folgenden erhalten.
An error occurred when executing the SQL command: copy part from 's3://amzn-s3-demo-bucket/load/part-csv.tbl' credentials' ... ERROR: Load into table 'part' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 1.46s 1 statement(s) failed. 1 statement(s) failed.
Um mehr Informationen zu dem Fehler zu erhalten, fragen Sie die Tabelle STL_LOAD_ERRORS ab. Die folgende Abfrage verwendet die Funktion SUBSTRING zum Kürzen von Spalten zur besseren Lesbarkeit sowie LIMIT 10, um die Anzahl der ausgegebenen Zeilen zu reduzieren. Sie können die Werte in substring(filename,22,25) an die Länge Ihres Bucketnamens anpassen.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as reason from stl_load_errors order by query desc limit 10;
query | filename | line | column | type | pos | --------+-------------------------+-----------+------------+------------+-----+---- 333765 | part-csv.tbl-000 | 1 | | | 0 | line_text | field_text | reason ------------------+------------+---------------------------------------------- 15,NUL next, | | Missing newline: Unexpected character 0x2c f
NULL AS
Die part-csv.tbl-Datendateien verwenden das NUL-Begrenzungszeichen (\x000 oder \x0) zur Anzeige von NULL-Werten.
Anmerkung
Trotz ihrer sehr ähnlichen Schreibweise sind NUL und NULL nicht identisch. NUL ist ein UTF-8 Zeichen mit Codepunktx000, das häufig verwendet wird, um das Ende eines Datensatzes (EOR) anzuzeigen. NULL ist ein SQL-Wert, der für die Abwesenheit von Daten steht.
Standardmäßig behandelt COPY das Begrenzungszeichen NUL als EOR-Zeichen und beendet den Datensatz, was oft zu unerwarteten Ergebnissen oder einem Fehler führt. Es gibt keine einzige Standardmethode, um NULL in Textdaten anzuzeigen. Mit der Befehlsoption NULL AS COPY können Sie also angeben, welches Zeichen beim Laden der Tabelle durch NULL ersetzt werden soll. In diesem Beispiel soll COPY das NUL-Begrenzungszeichen als NULL-Wert behandeln.
Anmerkung
Die Tabellenspalte, die den NULL-Wert erhält, muss als nullfähig konfiguriert sein. Das bedeutet, dass sie die NOT NULL-Einschränkung in der CREATE TABLE-Spezifikation nicht enthalten darf.
Führen Sie den folgenden COPY-Befehl aus, um PART mit der Option NULL AS zu laden.
copy part from 's3://<your-bucket-name>/load/part-csv.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' csv null as '\000';
Um zu prüfen, ob COPY NULL-Werte geladen hat, führen Sie den folgenden Befehl aus, um nur die Zeilen auszuwählen, die NULL enthalten.
select p_partkey, p_name, p_mfgr, p_category from part where p_mfgr is null;
p_partkey | p_name | p_mfgr | p_category -----------+----------+--------+------------ 15 | NUL next | | MFGR#47 81 | NUL next | | MFGR#23 133 | NUL next | | MFGR#44 (2 rows)
Die Optionen DELIMITER und REGION
Die Optionen DELIMITER und REGION sind wichtig, um zu verstehen, wie Daten geladen werden.
Character-delimited Format
Die Felder in einer durch Zeichen getrennten Datei sind durch ein bestimmtes Zeichen getrennt, z. B. durch einen senkrechten Strich (|), ein Komma (,) oder ein Tabulatorzeichen (\ t). Character-delimited Dateien können jedes einzelne ASCII-Zeichen, einschließlich eines der nicht druckbaren ASCII-Zeichen, als Trennzeichen verwenden. Sie geben das Trennzeichen mit der Option DELIMITER an. Das Standardtrennzeichen ist der senkrechte Strich (|).
Der folgende Auszug aus den Daten für die Tabelle SUPPLIER verwendet den senkrechten Strich als Trennzeichen.
1|1|257368|465569|41365|19950218|2-HIGH|0|17|2608718|9783671|4|2504369|92072|2|19950331|TRUCK 1|2|257368|201928|8146|19950218|2-HIGH|0|36|6587676|9783671|9|5994785|109794|6|19950416|MAIL
REGION
Wann immer möglich, sollten Sie Ihre Ladedaten in derselben AWS Region wie Ihr Amazon Redshift Redshift-Cluster lokalisieren. Wenn sich Ihre Daten und Ihr Cluster in derselben Region befinden, reduzieren Sie die Latenz und vermeiden Kosten für den regionenübergreifenden Datentransfer. Weitere Informationen finden Sie unter Bewährte Methoden für Amazon Redshift zum Laden von Daten.
Wenn Sie Daten aus einer anderen AWS Region laden müssen, verwenden Sie die Option REGION, um die AWS Region anzugeben, in der sich die Ladedaten befinden. Wenn Sie eine Region angeben, müssen sich alle Ladedaten, einschließlich der Manifestdateien, in der benannten Region befinden. Weitere Informationen finden Sie unter REGION.
Wenn sich Ihr Cluster in der Region USA Ost (Nord-Virginia) befindet und sich Ihr Amazon-S3-Bucket in der Region USA West (Oregon) befindet, zeigt der folgende COPY-Befehl, wie die Tabelle SUPPLIER aus Daten mit Pipe-Trennzeichen geladen wird.
copy supplier from 's3://amzn-s3-demo-bucket/ssb/supplier.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '|' gzip region 'us-west-2';
Laden der Tabelle CUSTOMER mit MANIFEST
In diesem Schritt laden Sie die Tabelle CUSTOMER mit den Optionen FIXEDWIDTH, MAXERROR, ACCEPTINVCHARS und MANIFEST.
Die Beispieldaten für diese Übung enthalten Zeichen, die beim Laden durch COPY Fehler verursachen. Mit der Option MAXERRORS und der Systemtabelle STL_LOAD_ERRORS können Sie die Ladefehler ausfindig machen und mit den Optionen ACCEPTINVCHARS und MANIFEST die Fehler beheben.
Fixed-Width Formatieren
Fixed-width Format definiert jedes Feld als eine feste Anzahl von Zeichen, anstatt Felder durch ein Trennzeichen zu trennen. Der folgende Auszug aus den Daten für die Tabelle CUSTOMER verwendet das Format mit fester Breite.
1 Customer#000000001 IVhzIApeRb MOROCCO 0MOROCCO AFRICA 25-705 2 Customer#000000002 XSTf4,NCwDVaWNe6tE JORDAN 6JORDAN MIDDLE EAST 23-453 3 Customer#000000003 MG9kdTD ARGENTINA5ARGENTINAAMERICA 11-783
Die Reihenfolge der label/width Paare muss exakt mit der Reihenfolge der Tabellenspalten übereinstimmen. Weitere Informationen finden Sie unter FIXEDWIDTH.
Die Spezifikationszeichenfolge für die feste Breite der Daten für die Tabelle CUSTOMER ist die folgende.
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
Um die Tabelle CUSTOMER aus Daten mit fester Breite zu laden, führen Sie den folgenden Befehl aus.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10';
Sie sollten eine Fehlermeldung ähnlich der folgenden erhalten.
An error occurred when executing the SQL command: copy customer from 's3://amzn-s3-demo-bucket/load/customer-fw.tbl' credentials'... ERROR: Load into table 'customer' failed. Check 'stl_load_errors' system table for details. [SQL State=XX000] Execution time: 2.95s 1 statement(s) failed.
MAXERROR
Standardmäßig schlägt der COPY-Befehl beim ersten Auftreten eines Fehlers fehl und gibt eine Fehlermeldung aus. Um beim testen Zeit zu sparen, können Sie die Option MAXERROR verwenden, damit COPY eine bestimmte Anzahl von Fehlern übergeht, bevor der Befehl fehlschlägt. Da wir beim ersten Test des Ladens der Daten der Tabelle CUSTOMER Fehler erwarten, fügen Sie dem COPY-Befehl maxerror 10 hinzu.
Führen Sie zum Test mit den Optionen FIXEDWIDTH und MAXERROR den folgenden Befehl aus.
copy customer from 's3://<your-bucket-name>/load/customer-fw.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10;
Diesmal erhalten Sie statt einer Fehlermeldung eine Warnmeldung, ähnlich der folgenden.
Warnings: Load into table 'customer' completed, 112497 record(s) loaded successfully. Load into table 'customer' completed, 7 record(s) could not be loaded. Check 'stl_load_errors' system table for details.
Die Warnung gibt an, dass COPY auf sieben Fehler gestoßen ist. Fragen Sie zur Prüfung der Fehler die Tabelle STL_LOAD_ERRORS ab, wie im folgenden Beispiel gezeigt.
select query, substring(filename,22,25) as filename,line_number as line, substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text, substring(raw_field_value,0,15) as field_text, substring(err_reason,0,45) as error_reason from stl_load_errors order by query desc, filename limit 7;
Das Ergebnis der Abfrage von STL_LOAD_ERRORS sollte ähnlich wie folgt aussehen.
query | filename | line | column | type | pos | line_text | field_text | error_reason --------+---------------------------+------+-----------+------------+-----+-------------------------------+------------+---------------------------------------------- 334489 | customer-fw.tbl.log | 2 | c_custkey | int4 | -1 | customer-fw.tbl | customer-f | Invalid digit, Value 'c', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 6 | c_custkey | int4 | -1 | Complete | Complete | Invalid digit, Value 'C', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 3 | c_custkey | int4 | -1 | #Total rows | #Total row | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 5 | c_custkey | int4 | -1 | #Status | #Status | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl.log | 1 | c_custkey | int4 | -1 | #Load file | #Load file | Invalid digit, Value '#', Pos 0, Type: Integ 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 334489 | customer-fw.tbl000 | 1 | c_address | varchar | 34 | 1 Customer#000000001 | .Mayag.ezR | String contains invalid or unsupported UTF8 (7 rows)
Bei der Untersuchung der Ergebnisse sehen Sie zwei Meldungen in der Spalte error_reasons:
-
Invalid digit, Value '#', Pos 0, Type: IntegDiese Fehler wurden von der Datei
customer-fw.tbl.logverursacht. Das Problem besteht darin, dass es sich um eine Protokolldatei und nicht um eine Datendatei handelt, die daher nicht geladen werden sollte. Sie können eine Manifestdatei verwenden, um das Laden falscher Dateien zu vermeiden. -
String contains invalid or unsupported UTF8Der VARCHAR-Datentyp unterstützt UTF-8 Multibyte-Zeichen bis zu drei Byte. Wenn die Ladedaten nicht unterstützte oder ungültige Zeichen enthalten, können Sie jedes ungültige Zeichen mit der Option ACCEPTINVCHARS gegen ein angegebenes Alternativzeichen austauschen.
Ein weiteres Problem mit der Last ist schwieriger zu erkennen – die Last führte zu unerwarteten Ergebnissen. Fragen Sie mit dem folgenden Befehl die Tabelle CUSTOMER ab, um dieses Problem zu untersuchen.
select c_custkey, c_name, c_address from customer order by c_custkey limit 10;
c_custkey | c_name | c_address -----------+---------------------------+--------------------------- 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tE 3 | Customer#000000003 | MG9kdTD 3 | Customer#000000003 | MG9kdTD 4 | Customer#000000004 | XxVSJsL 4 | Customer#000000004 | XxVSJsL 5 | Customer#000000005 | KvpyuHCplrB84WgAi 5 | Customer#000000005 | KvpyuHCplrB84WgAi 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx 6 | Customer#000000006 | sKZz0CsnMD7mp4Xd0YrBvx (10 rows)
Die Zeilen sollten eindeutig sein, es gibt jedoch Duplikate.
Eine weitere Möglichkeit zur Untersuchung unerwarteter Ergebnisse besteht darin, die Anzahl der geladenen Zeilen zu prüfen. In unserem Fall sollten 100000 Zeilen geladen werden, die Lademeldung gab 112497 geladene Datensätze an. Die zusätzlichen Zeilen wurden geladen, weil COPY eine überzählige Datei, , geladen hat., customer-fw.tbl0000.bak.
In dieser Übung verwenden Sie eine Manifestdatei, um das Laden der falschen Dateien zu vermeiden.
ACCEPTINVCHARS
Standardmäßig gilt, dass COPY beim Treffen auf eine von dem Datentyp der Spalte nicht unterstütztes Zeichen die Zeile überspringt und einen Fehler ausgibt. Hinweise zu ungültigen UTF-8 Zeichen finden Sie unter. Fehler beim Laden von Multibyte-Zeichen
Sie können die Option MAXERRORS verwenden, um Fehler zu ignorieren und den Ladevorgang fortzusetzen, dann STL_LOAD_ERRORS abfragen, um die ungültigen Zeichen zu finden und anschließend die Datendateien korrigieren. MAXERRORS wird jedoch sinnvollerweise für die Behebung von Ladeproblemen verwendet und sollte generell nicht in einer Produktionsumgebung genutzt werden.
Die Option ACCEPTINVCHARS ist normalerweise die bessere Wahl für den Umgang mit ungültigen Zeichen. ACCEPTINVCHARS instruiert COPY dazu, jedes ungültige Zeichen durch ein festgelegtes gültiges Zeichen zu ersetzen und den Ladevorgang fortzusetzen. Sie können jedes gültige ASCII-Zeichen, ausgenommen NULL, als Austauschzeichen festlegen. Das Standard-Austauschzeichen ist ein Fragezeichen (?). COPY ersetzt Multibyte-Zeichen durch eine Austauschzeichenfolge gleicher Länge. Ein 4-Byte-Zeichen wird etwa durch ersetzt '????'.
COPY gibt die Anzahl der Zeilen zurück, die ungültige UTF-8 Zeichen enthielten. Außerdem wird für jede betroffene Zeile ein Eintrag in die Systemtabelle STL_REPLACEMENTS hinzugefügt (bis zu maximal 100 Zeilen pro Knotenebene). Zusätzliche ungültige UTF-8 Zeichen werden ebenfalls ersetzt, aber diese Ersetzungsereignisse werden nicht aufgezeichnet.
ACCEPTINVCHARS ist nur für VARCHAR-Spalten gültig.
Für diesen Schritt fügen Sie die ACCEPTINVCHARS mit dem Ersetzungszeichen '^' hinzu.
MANIFEST
Wenn Sie von Amazon S3 mit einem Schlüsselpräfix kopieren, besteht die Gefahr, dass Sie unerwünschte Tabellen laden. Beispielsweise enthält der Ordner 's3://amzn-s3-demo-bucket/load/ acht Datendateien, die das Schlüsselpräfix customer-fw.tbl gemeinsam haben: customer-fw.tbl0000, customer-fw.tbl0001 usw. Dieser Ordner enthält aber auch die überschüssigen Dateien customer-fw.tbl.log und customer-fw.tbl-0001.bak.
Um sicherzustellen, dass Sie alle und nur die korrekten Dateien laden, verwenden Sie eine Manifestdatei. Das Manifest ist eine Textdatei im JSON-Format, die den eindeutigen Objektschlüssel für jede zu ladende Quelldatei ausdrücklich aufführt. Die Dateiobjekte können sich in verschiedenen Ordnern oder Buckets, müssen sich aber in derselben Region befinden. Weitere Informationen finden Sie unter MANIFEST.
Nachfolgend sehen Sie den customer-fw-manifest-Text.
{ "entries": [ {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-000"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-001"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-002"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-003"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-004"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-005"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-006"}, {"url":"s3://<your-bucket-name>/load/customer-fw.tbl-007"} ] }
So laden Sie die Daten für die Tabelle CUSTOMER mit der Manifestdatei:
-
Öffnen Sie die Datei
customer-fw-manifestin einem Text-Editor. -
Ersetzen Sie
<your-bucket-name>durch den Namen von Ihrem Bucket. -
Speichern Sie die Datei.
-
Laden Sie die Datei in den Ladeordner in Ihrem Bucket.
-
Führen Sie den folgenden COPY-Befehl aus.
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10' maxerror 10 acceptinvchars as '^' manifest;
Laden der Tabelle DWDATE mit DATEFORMAT
In diesem Schritt verwenden Sie die Optionen DELIMITER und DATEFORMAT, um die Tabelle DWDATE zu laden.
Beim Laden der Spalten DATE und TIMESTAMP erwartet COPY das Standardformat YYYY-MM-DD für Datums- und YYYY-MM-DD HH:MI:SS Zeitstempel. Wenn die Ladedaten das Standardformat nicht verwenden, können Sie das Format mithilfe von DATEFORMAT und TIMEFORMAT angeben.
Der folgende Auszug zeigt Datumsformate in der Tabelle DWDATE. Beachten Sie, dass die Datumsformate in Spalte zwei nicht konsistent sind.
19920104 1992-01-04 Sunday January 1992 199201 Jan1992 1 4 4 1... 19920112 January 12, 1992 Monday January 1992 199201 Jan1992 2 12 12 1... 19920120 January 20, 1992 Tuesday January 1992 199201 Jan1992 3 20 20 1...
DATEFORMAT
Sie können nur ein Datumsformat angeben. Wenn die Ladedaten inkonsistente Formate enthalten, möglicherweise in verschiedenen Spalten, oder wenn das Format zum Zeitpunkt des Ladevorgangs nicht bekannt ist, verwenden Sie DATEFORMAT mit dem Argument 'auto'. Wenn 'auto' angegeben ist, erkennt COPY jedes gültige Datums- oder Zeitformat und konvertiert es in das Standardformat. Die Option 'auto' erkennt verschiedene Formate, die bei der Verwendung einer DATEFORMAT- und TIMEFORMAT-Zeichenfolge nicht unterstützt werden. Weitere Informationen finden Sie unter Verwenden der automatischen Erkennung bei DATEFORMAT und TIMEFORMAT.
Führen Sie den folgenden COPY-Befehl aus, um die Tabelle DWDATE zu laden.
copy dwdate from 's3://<your-bucket-name>/load/dwdate-tab.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' delimiter '\t' dateformat 'auto';
Laden von mehreren Datendateien
Sie können die Optionen GZIP und COMPUPDATE verwenden, um eine Tabelle zu laden.
Sie können eine Tabelle aus einer einzelnen Datendatei oder aus mehreren Dateien laden. Auf diese Weise können Sie die Ladezeiten der beiden Methoden vergleichen.
GZIP, LZOP und BZIP2
Sie können Ihre Dateien mit den Kompressionsformaten gzip, lzop und bzip2 komprimieren. Beim laden aus komprimierten Dateien dekomprimiert COPY diese während des Ladevorgangs. Die Komprimierung Ihrer Dateien spart Speicherplatz und verkürzt die Ladezeiten.
COMPUPDATE
Wenn COPY eine leere Tabelle ohne Kompressionskodierungen lädt, analysiert der Befehl die Ladedaten, um die optimalen Kodierungen zu bestimmen. Anschließend ändert er die Tabelle, um diese Kodierungen vor dem beginn des Ladevorgangs anzuwenden. Diese Analyse nimmt Zeit in Anspruch, findet aber höchstens einmal pro Tabelle statt. Um Zeit zu sparen, können Sie diesen Schritt überspringen, indem Sie COMPUPDATE ausschalten. Um eine genaue Auswertung der COPY-Zeiten zu ermöglichen, schalten Sie COMPUPDATE für diesen Schritt aus.
Mehrere Dateien
Der Befehl COPY kann Daten sehr effizient laden, wenn er aus mehreren Dateien parallel statt aus einer einzigen Datei lädt. Sie können Ihre Daten in Dateien aufteilen, sodass die Anzahl der Dateien ein Vielfaches der Anzahl der Schichten in Ihrem Cluster beträgt. In diesem Fall teilt Amazon Redshift den Workload auf und verteilt die Daten gleichmäßig auf die Schichten. Die Anzahl der Slices pro Knoten ist von der Knotengröße des Clusters abhängig. Weitere Informationen zur Anzahl der Slices für die einzelnen Knotengrößen finden Sie unter About Clusters and Nodes (Informationen zu Clustern und Knoten) im Managementleitfaden zu Amazon Redshift.
Beispielsweise können die in diesem Tutorial verwendeten Datenverarbeitungsknoten jeweils zwei Slices enthalten. Ein aus vier Knoten bestehender Cluster hat daher acht Slices. In früheren Schritten waren die Ladedaten in acht Dateien enthalten, obwohl diese sehr klein waren. Sie können den Zeitunterschied zwischen dem Laden aus einer einzigen großen Datei und dem Laden aus mehreren Dateien vergleichen.
Selbst Dateien, die 15 Millionen Datensätze enthalten und ungefähr 1,2 GB belegen, sind im Kontext von Amazon Redshift sehr klein. Sie sind jedoch ausreichend, um den Leistungsvorteil des Ladens aus mehreren Dateien zu zeigen.
In der folgenden Abbildung werden die Datendateien für LINEORDER gezeigt.
So evaluieren Sie die Leistung von COPY mit mehreren Dateien:
-
In einem Labortest wurde der folgende Befehl ausgeführt, um COPY aus einer einzelnen Datei auszuführen. Dieser Befehl zeigt einen fiktiven Bucket.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-single.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Die Ergebnisse sind wie folgt. Beachten Sie die Ausführungszeit.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 51.56s -
Anschließend wurde der folgende COPY-Befehl ausgeführt, um Daten aus mehreren Dateien zu kopieren.
copy lineorder from 's3://amzn-s3-demo-bucket/load/lo/lineorder-multi.tbl' credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>' gzip compupdate off region 'us-east-1'; -
Die Ergebnisse sind wie folgt. Beachten Sie die Ausführungszeit.
Warnings: Load into table 'lineorder' completed, 14996734 record(s) loaded successfully. 0 row(s) affected. copy executed successfully Execution time: 17.7s -
Vergleichen Sie die Ausführungszeiten.
In unserem Experiment sank die Zeit für das Laden von 15 Millionen Datensätzen von 51,56 Sekunden auf 17,7 Sekunden, d. h. um 65,7 Prozent.
Diese Ergebnisse basieren auf der Verwendung eines Clusters mit vier Knoten. Wenn Ihr Cluster mehr Knoten hat, vervielfachen sich die Zeiteinsparungen. Bei typischen Amazon-Redshift-Clustern mit manchmal Hunderten von Knoten ist der Unterschied noch viel deutlicher. Wenn Sie einen Cluster mit nur einem Knoten haben, besteht nur ein geringer Unterschied zwischen den Ausführungszeiten.
Schritt 6: Bereinigen und Analysieren der Datenbank
Immer wenn Sie eine größere Zahl von Zeilen hinzufügen, löschen oder modifizieren, sollten Sie einen VACUUM- und dann einen ANALYZE-Befehl ausführen. Eine Bereinigung gewinnt den Speicherplatz gelöschter Zeilen zurück und stellt die Sortierfolge wieder her. Der ANALYZE-Befehl aktualisiert die Statistik-Metadaten, wodurch der Abfrageoptimierer korrektere Abfragepläne erstellen kann. Weitere Informationen finden Sie unter Bereinigen von Tabellen.
Wenn Sie die Daten in der Reihenfolge des Sortierschlüssels laden, geht die Bereinigung sehr schnell. In diesem Tutorial haben Sie eine große Zahl von Zeilen hinzugefügt, jedoch in leere Tabellen. Daher muss die Sortierung nicht wiederhergestellt werden; weiterhin haben Sie keine Zeilen gelöscht. COPY aktualisiert automatisch die Statistik nach dem Laden einer leeren Tabelle, diese sollte daher aktuell sein. Aus Gründen der guten Organisation schließen Sie dieses Tutorial jedoch ab, indem Sie ein Vacuuming und eine Analyse Ihrer Datenbank durchführen.
Führen Sie zum Bereinigen und Analysieren der Datenbank die folgenden Befehle aus.
vacuum; analyze;
Schritt 7: Bereinigen Ihrer Ressourcen
Solange dieser ausgeführt wird, fallen Gebühren für Ihren Cluster an. Wenn Sie dieses Tutorial abgeschlossen haben, sollten Sie Ihre Umgebung wieder auf den ursprünglichen Zustand zurücksetzen, indem Sie die Schritte in Schritt 5: Aufheben des Zugriffs und Löschen Ihres Beispielclusters im Handbuch Erste Schritte in Amazon Redshift ausführen.
Wenn Sie den Cluster behalten möchten, den von den SSB-Tabellen beanspruchten Speicherplatz jedoch zurückgewinnen möchten, führen Sie die folgenden Befehle aus.
drop table part; drop table supplier; drop table customer; drop table dwdate; drop table lineorder;
Next
Zusammenfassung
In diesem Tutorial haben Sie Datendateien zu Amazon S3 hochgeladen und dann die Daten mit dem COPY-Befehl aus den Dateien in Amazon-Redshift-Tabellen geladen.
Sie haben Daten unter Verwendung der folgenden Formate geladen:
-
Character-delimited
-
CSV
-
Fixed-width
Mit der Systemtabelle STL_LOAD_ERRORS haben Sie Ladefehler ermittelt und dann mit den Optionen REGION, MANIFEST, MAXERROR, ACCEPTINVCHARS, DATEFORMAT und NULL AS beseitigt.
Zum Laden der Daten haben Sie die folgenden bewährten Verfahren verwendet:
Für weitere Informationen zu bewährten Verfahren für Amazon Redshift vgl. die folgenden Links:
