Amazon Redshift unterstützt die Verwendung von Python-UDFs nach dem 30. Juni 2026 nicht mehr. Wir werden damit beginnen, es schrittweise durchzusetzen. Weitere Informationen zu den Einzelheiten zum Ende der Lebensdauer und zu den Migrationsoptionen von Python finden Sie in dem Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erste Schritte mit Data Warehouses von Amazon Redshift Serverless
Wenn Sie Amazon Redshift Serverless zum ersten Mal verwenden, empfehlen wir Ihnen, die folgenden Abschnitte zu lesen, um Ihnen den Einstieg in die Verwendung von Amazon Redshift Serverless zu erleichtern. Der grundlegende Ablauf von Amazon Redshift Serverless besteht darin, Serverless-Ressourcen zu erstellen, eine Verbindung zu Amazon Redshift Serverless herzustellen, Beispieldaten zu laden und dann Abfragen für die Daten auszuführen. Bei Verwendung dieses Handbuchs haben Sie die Möglichkeit, Beispieldaten aus Amazon Redshift Serverless oder aus einem Amazon-S3-Bucket zu laden. Die Beispieldaten werden in der gesamten Amazon-Redshift-Dokumentation verwendet, um Features zu demonstrieren. Für die ersten Schritte bei der Verwendung von Amazon Redshift bereitgestellter Data Warehouses vgl. Erste Schritte mit von Amazon Redshift bereitgestellten Data Warehouses.
Melde dich an für ein AWS-Konto
Um loszulegen AWS, benötigen Sie eine AWS-Konto. Informationen zum Erstellen eines AWS-Konto finden Sie unter Erste Schritte mit einem AWS-Konto im AWS -Kontenverwaltung Referenzhandbuch.
Erstellen eines Data Warehouse mit Amazon Redshift Serverless
Wenn Sie sich zum ersten Mal bei der Amazon-Redshift-Serverless-Konsole anmelden, werden Sie aufgefordert, auf die Informationen zu den ersten Schritten zuzugreifen, die Sie zum Erstellen und Verwalten von Serverless-Ressourcen verwenden können. In diesem Handbuch werden Sie Serverless-Ressourcen unter Verwendung der Standardeinstellungen von Amazon Redshift Serverless erstellen.
Wenn Sie Ihre Einrichtung genauer kontrollieren möchten, wählen Sie Customize settings (Einstellungen anpassen) aus.
Anmerkung
Redshift Serverless erfordert eine Amazon-VPC mit drei Subnetzen in drei verschiedenen Availability Zones. Redshift Serverless benötigt außerdem mindestens 3 verfügbare IP-Adressen. Stellen Sie sicher, dass die Amazon VPC, die Sie für Redshift Serverless verwenden, drei Subnetze in drei verschiedenen Availability Zones und mindestens 3 verfügbare IP-Adressen hat, bevor Sie fortfahren. Weitere Informationen zum Erstellen von Subnetzen finden Sie unter Erstellen eines Subnetzes im Benutzerhandbuch von Amazon Virtual Private Cloud. Weitere Informationen zu IP-Adressen in einer Amazon VPC finden Sie unter IP-Adressierung für Ihre VPCs und Subnetze.
So nehmen Sie die Konfiguration mit Standardeinstellungen vor:
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon Redshift Redshift-Konsole unter https://console.aws.amazon.com/redshiftv2/
. Wählen Sie Redshift Serverless Free Trial testen.
-
Wählen Sie unter Configuration (Konfiguration) die Option Use default settings (Standardeinstellungen verwenden) aus. Amazon Redshift Serverless erstellt einen Standard-Namespace mit einer zugeordneten Standardarbeitsgruppe. Wählen Sie Save configuration (Konfiguration speichern) aus.
Anmerkung
Ein Namespace ist eine Sammlung von Datenbankobjekten und Benutzern. In Namespaces sind alle Ressourcen zusammengefasst, die Sie in Amazon Redshift Serverless verwenden, wie Schemata, Tabellen, Benutzer, Datashares und Snapshots.
Eine Arbeitsgruppe ist eine Sammlung von Rechenressourcen. In Arbeitsgruppen sind Rechenressourcen enthalten, die Amazon Redshift Serverless zur Ausführung von Datenverarbeitungsaufgaben verwendet.
Der folgende Screenshot zeigt die Standardeinstellungen für Amazon Redshift Serverless.
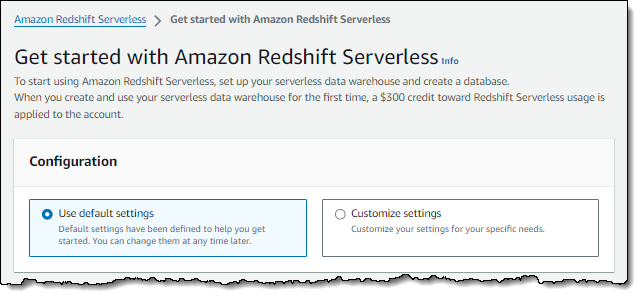
-
Nachdem die Einrichtung abgeschlossen ist, wählen Sie Continue (Weiter), um zu Serverless Dashboard zu wechseln. Wie Sie sehen, sind die Serverless-Arbeitsgruppe und der Serverless-Namespace verfügbar.
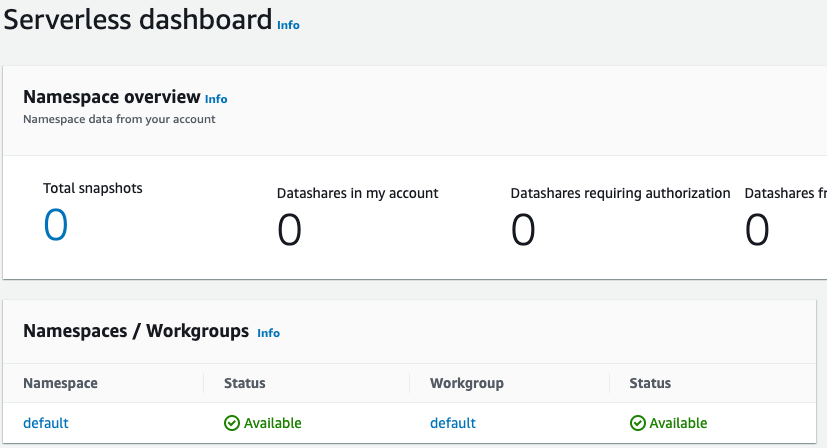
Anmerkung
Wenn Redshift Serverless die Arbeitsgruppe nicht erfolgreich erstellt, können Sie wie folgt vorgehen:
Beheben Sie alle Fehler, die Redshift Serverless meldet, wie z. B. zu wenige Subnetze in Ihrer Amazon VPC.
Löschen Sie den Namespace, indem Sie default-namespace im Redshift-Serverless-Dashboard und dann Aktionen, Namespace löschen auswählen. Das Löschen eines Namespaces dauert mehrere Minuten.
Wenn Sie die Redshift-Serverless-Konsole erneut öffnen, wird der Begrüßungsbildschirm angezeigt.
Laden von Beispieldaten
Nachdem Sie Ihr Data Warehouse mit Amazon Redshift Serverless eingerichtet haben, können Sie den Amazon Redshift Query Editor v2 verwenden, um Beispieldaten zu laden.
-
Um Query Editor v2 über die Amazon-Redshift-Serverless-Konsole zu starten, wählen Sie Daten abfragen aus. Wenn Sie den Abfrage-Editor v2 über die Amazon-Redshift-Serverless-Konsole aufrufen, wird er in einer neuen Browser-Registerkarte geöffnet. Der Abfrage-Editor v2 stellt eine Verbindung von Ihrem Clientcomputer mit der Amazon-Redshift-Serverless-Umgebung her.
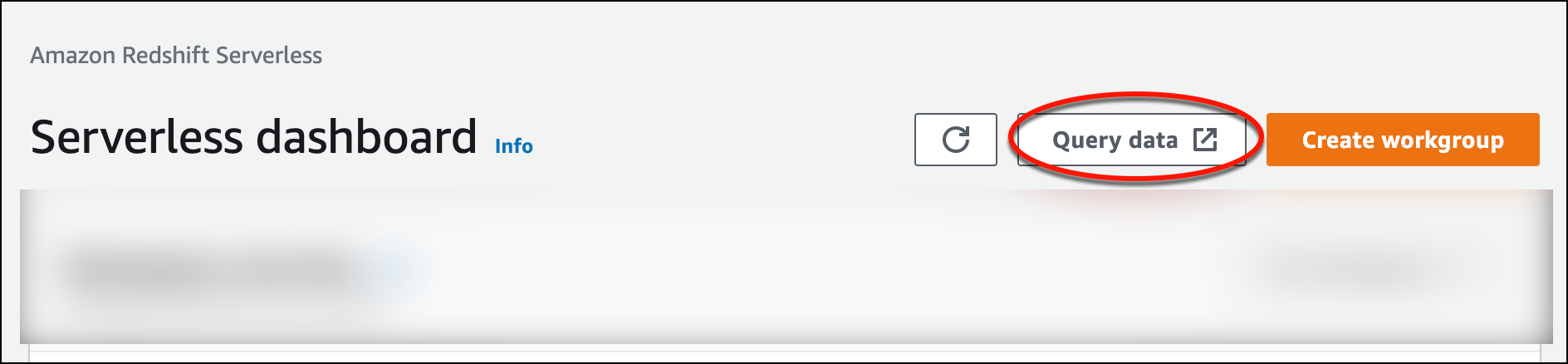
-
Für dieses Handbuch verwenden Sie Ihr AWS Administratorkonto und das AWS KMS key Standardkonto. Informationen zur Konfiguration von Query Editor v2, einschließlich der erforderlichen Berechtigungen, finden Sie unter Konfigurieren Ihres AWS-Konto im Managementleidfaden zu Amazon Redshift. Informationen zur Konfiguration von Amazon Redshift für die Verwendung eines vom Kunden verwalteten Schlüssels oder zur Änderung des von Amazon Redshift verwendeten KMS-Schlüssels finden Sie unter Ändern des AWS KMS Schlüssels für einen Namespace.
-
Um eine Verbindung zu einer Arbeitsgruppe herzustellen, wählen Sie den Namen der Arbeitsgruppe im Strukturansichtsbereich aus.
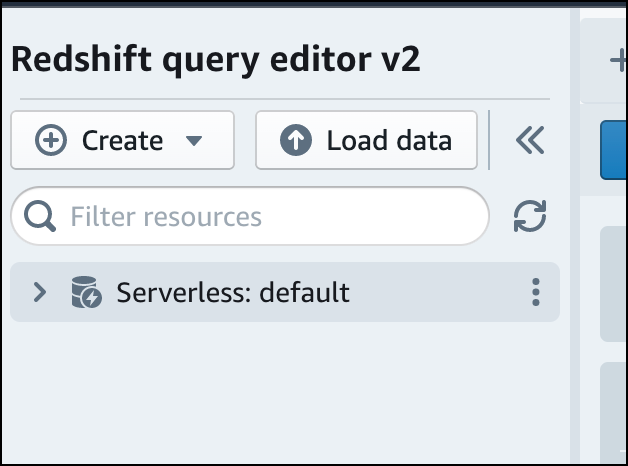
-
Wenn Sie in Query Editor v2 zum ersten Mal eine Verbindung zu einer neuen Arbeitsgruppe herstellen, müssen Sie den Authentifizierungstyp auswählen, der für die Verbindung zur Arbeitsgruppe verwendet werden soll. Lassen Sie für diese Anleitung die Option Verbundbenutzer ausgewählt und wählen Sie Verbindung erstellen aus.
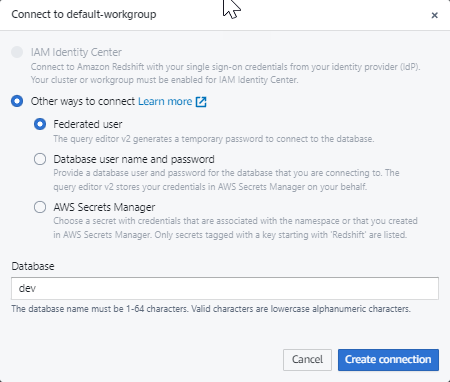
Sobald Sie verbunden sind, können Sie Beispieldaten aus Amazon Redshift Serverless oder aus einem Amazon-S3-Bucket laden.
-
Erweitern Sie unter der Standardarbeitsgruppe von Amazon Redshift Serverless die Datenbank sample_data_dev. Es gibt drei Beispielschemata, die drei Beispieldatensätzen entsprechen, die Sie in die Amazon-Redshift-Serverless-Datenbank laden können. Wählen Sie den Beispieldatensatz, den Sie laden möchten, und dann Beispiel-Notebooks öffnen aus.
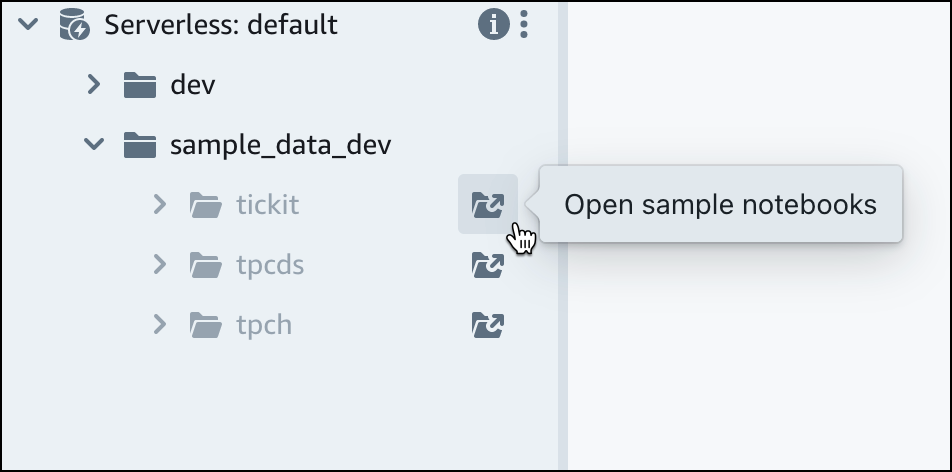
Anmerkung
Ein SQL-Notizbuch enthält SQL- und Markdown-Zellen. Sie können damit mehrere SQL-Befehle in einem einzigen Dokument organisieren, kommentieren und freigeben.
-
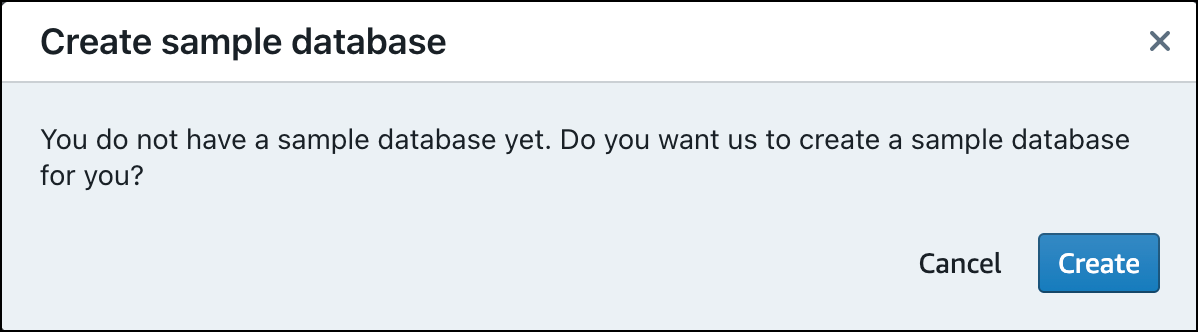
Wenn Sie zum ersten Mal Daten laden, fordert Query Editor v2 Sie auf, eine Beispieldatenbank zu erstellen. Wählen Sie Erstellen aus.
Ausführen von Beispielabfragen
Nachdem Sie Amazon Redshift Serverless eingerichtet haben, können Sie einen Beispieldatensatz in Amazon Redshift Serverless verwenden. Amazon Redshift Serverless lädt den Beispieldatensatz, z. B. den Tickit-Datensatz, automatisch und Sie können die Daten sofort abfragen.
-
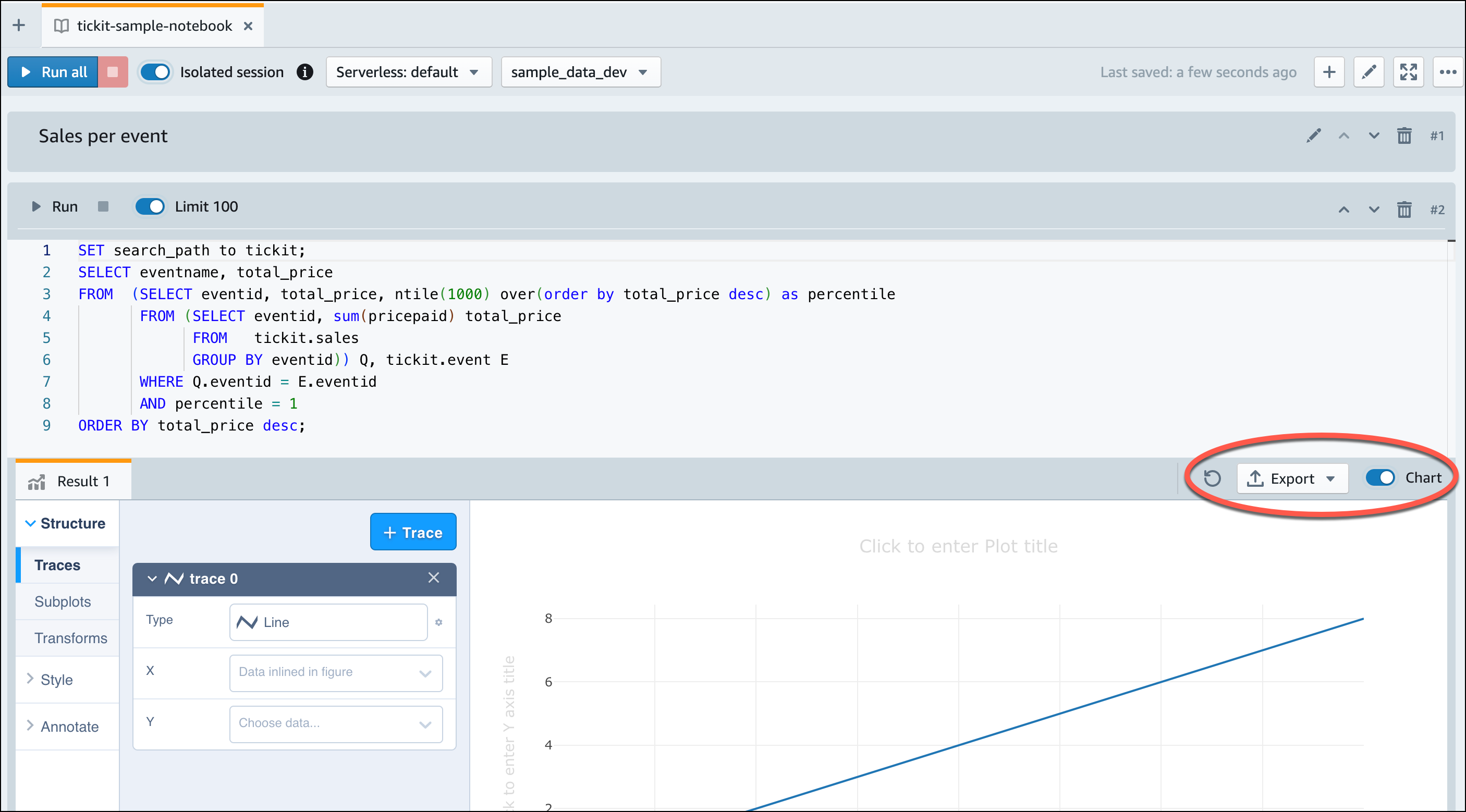
Sobald Amazon Redshift Serverless mit dem Laden der Beispieldaten fertig ist, werden alle Beispielabfragen in den Editor geladen. Sie können Alle ausführen auswählen, um alle Abfragen aus den Beispiel-Notebooks auszuführen.
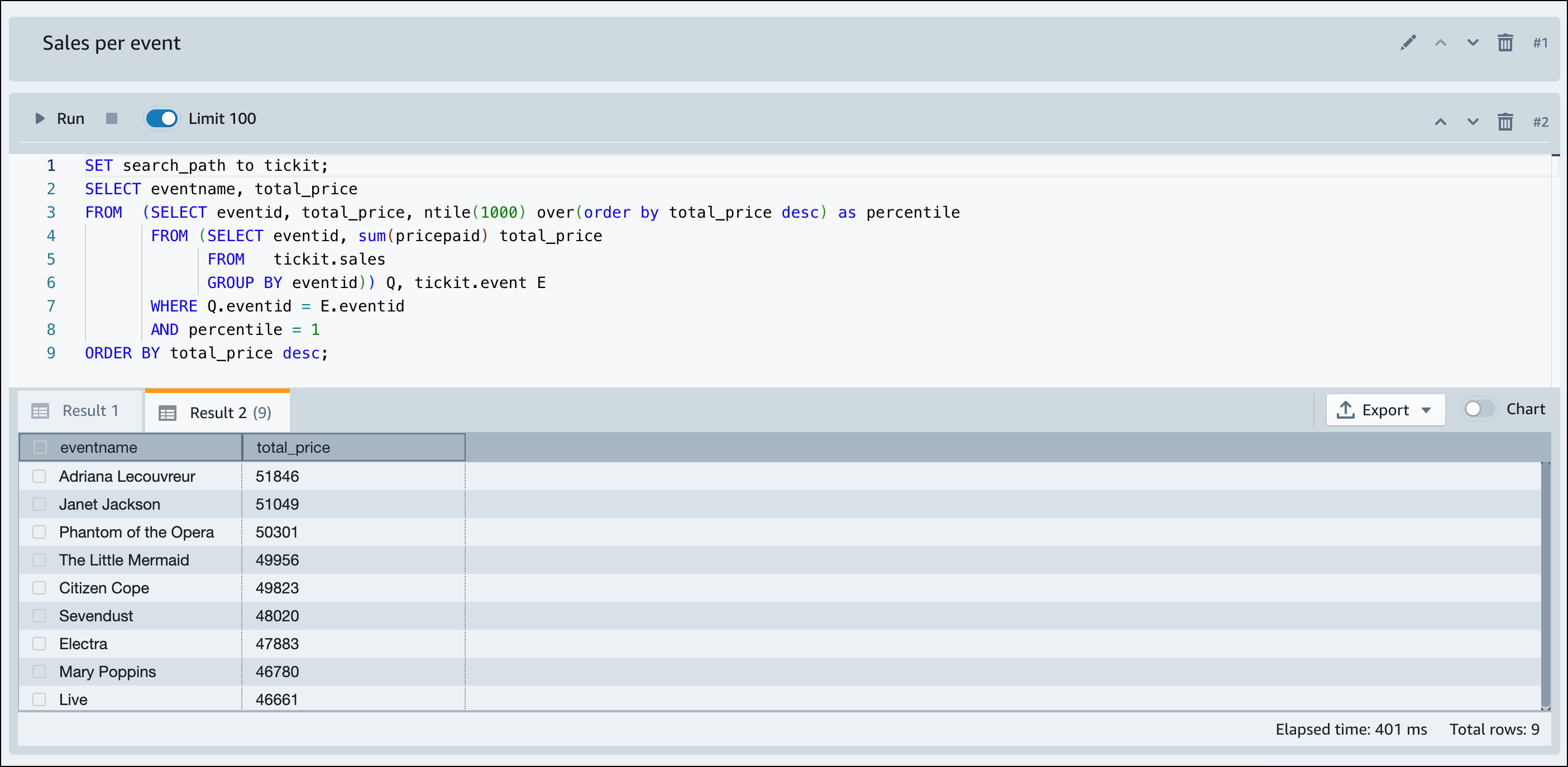
Sie können die Ergebnisse auch als JSON- oder CSV-Datei exportieren oder die Ergebnisse in einem Diagramm anzeigen.
Sie können Daten auch aus einem Amazon-S3-Bucket laden. Weitere Informationen hierzu finden Sie unter Laden von Daten aus Amazon S3.
Laden von Daten aus Amazon S3
Nachdem Sie Ihr Data Warehouse erstellt haben, können Sie Daten aus Amazon S3 laden.
An diesem Punkt verfügen Sie über eine Datenbank namens dev. Als Nächstes legen Sie Tabellen in der Datenbank an, laden Daten in die Tabellen hoch und führen testweise eine Abfrage durch. Die Beispieldaten werden der Einfachheit halber in einem Amazon-S3-Bucket bereitgestellt.
-
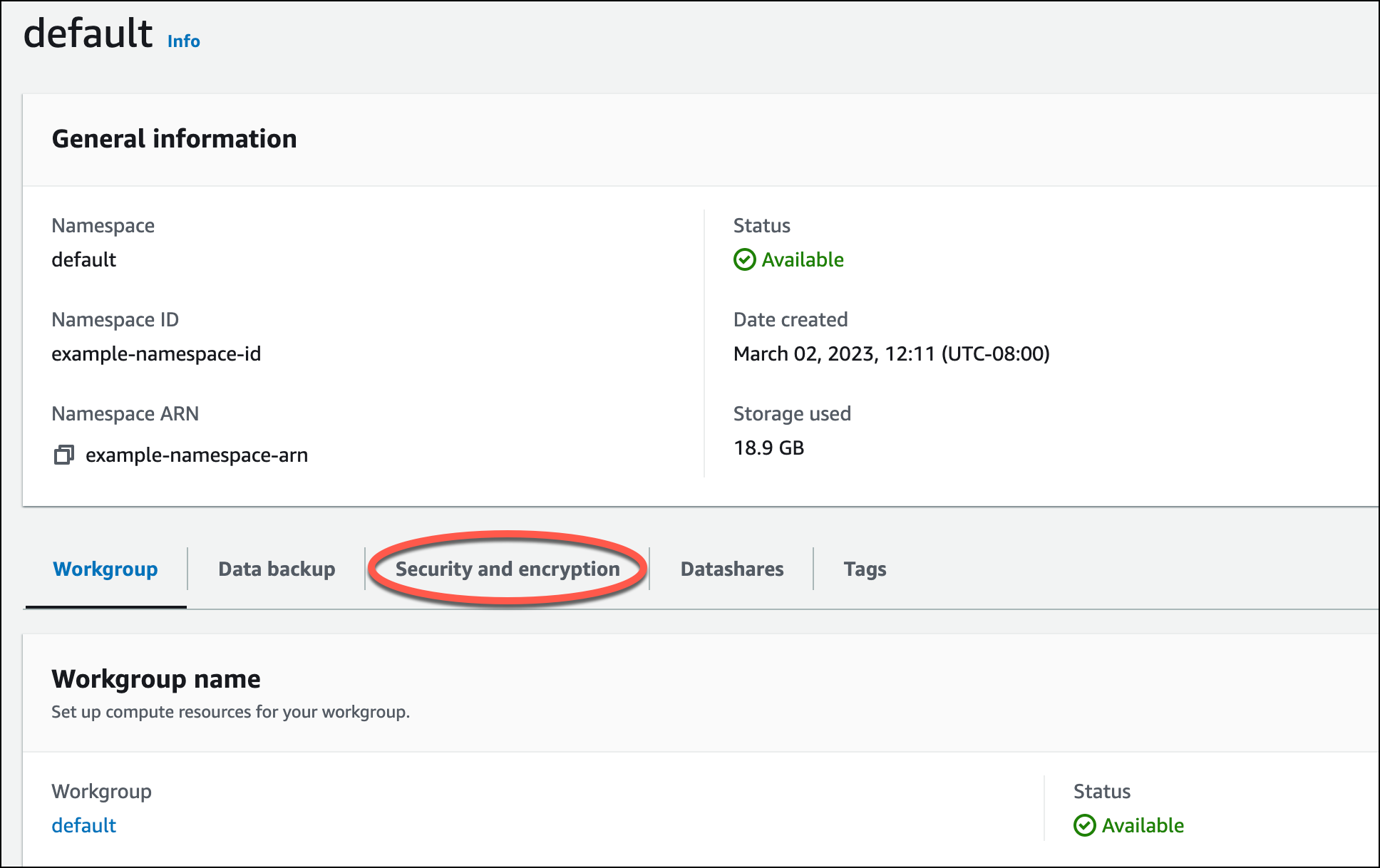
Vor dem Laden von Daten aus Amazon S3 müssen Sie zunächst eine IAM-Rolle mit den erforderlichen Berechtigungen erstellen und Ihrem Serverless-Namespace anfügen. Kehren Sie dazu zur Redshift Serverless-Konsole zurück und wählen Sie Namespace-Konfiguration. Wählen Sie dazu im Navigationsmenü Ihren Namespace und dann Sicherheit und Verschlüsselung. Wählen Sie IAM-Rollen verwalten.
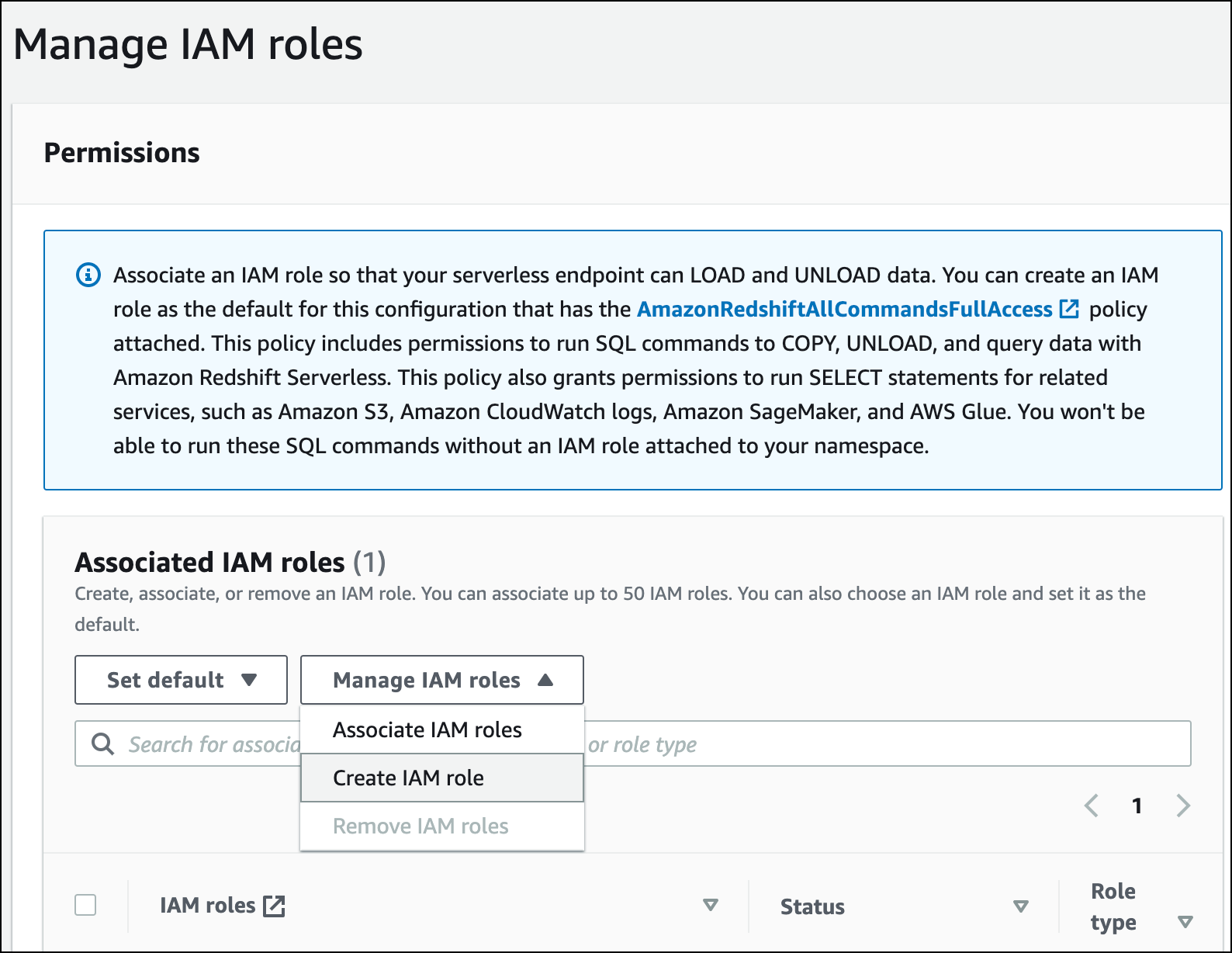
Erweitern Sie das Menü IAM-Rollen verwalten und wählen Sie IAM-Rolle erstellen aus.
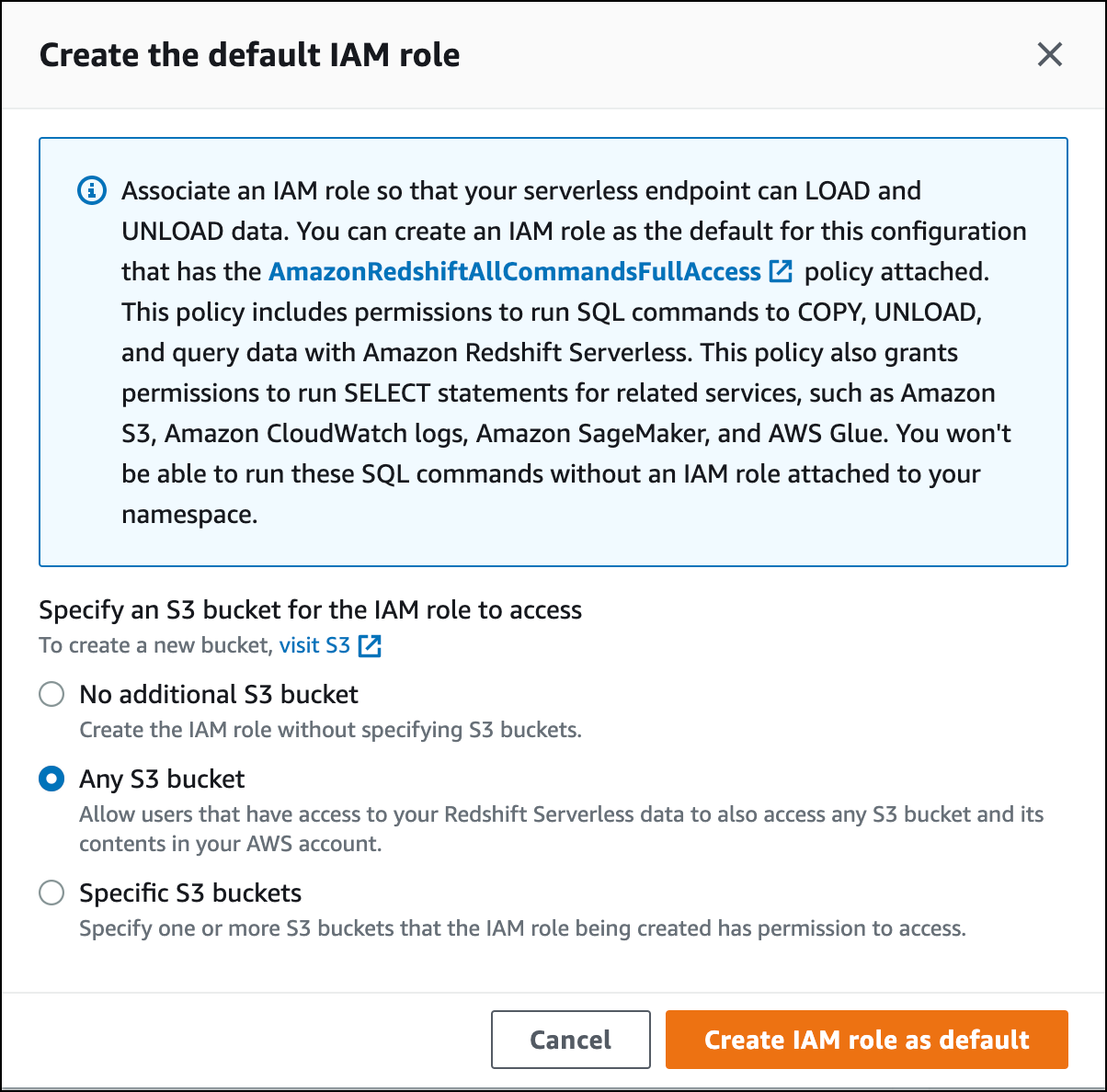
Wählen Sie die Ebene des S3-Bucket-Zugriffs aus, die Sie dieser Rolle gewähren möchten, und wählen Sie IAM-Rolle als Standard erstellen aus.
-
Wählen Sie Änderungen speichern aus. Sie können jetzt Beispieldaten aus Amazon S3 laden.
In den folgenden Schritten werden Daten in einem öffentlichen Amazon-Redshift-S3-Bucket verwendet, Sie können jedoch dieselben Schritte unter Verwendung Ihres eigenen S3-Buckets und eigener SQL-Befehle wiederholen.
Laden von Beispieldaten aus Amazon S3
-
Wählen Sie in Query Editor v2 „
 hinzufügen“ und dann Notebook aus, um ein neues SQL-Notebook zu erstellen.
hinzufügen“ und dann Notebook aus, um ein neues SQL-Notebook zu erstellen.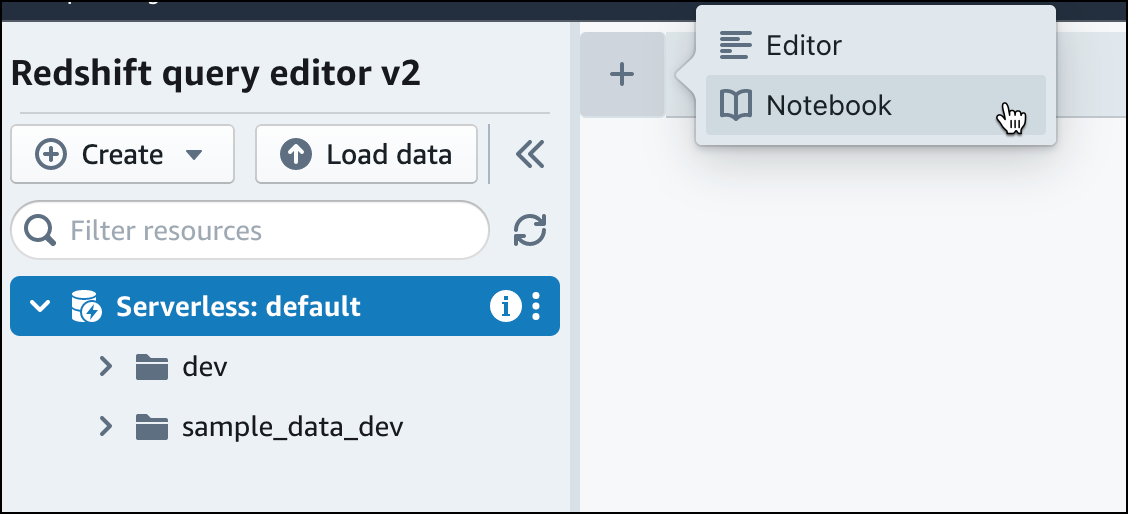
-
Wechseln Sie zur
dev-Datenbank.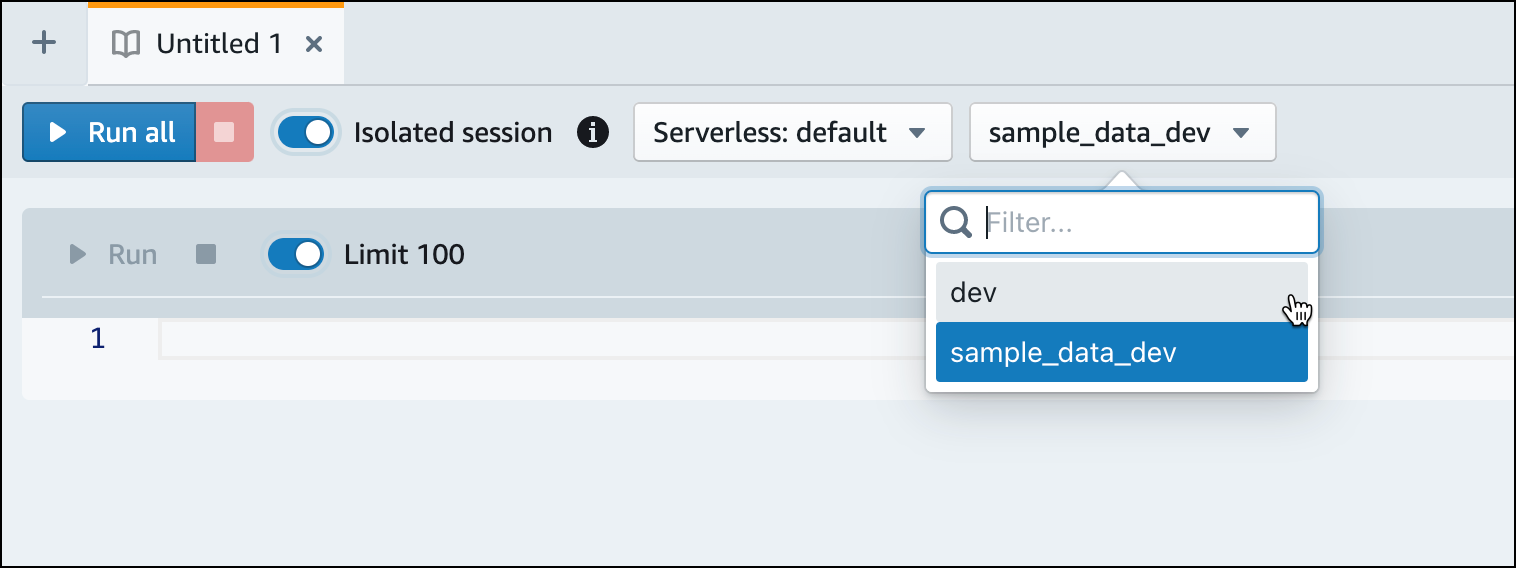
-
Erstellen Sie Tabellen.
Wenn Sie Query Editor v2 verwenden, kopieren Sie die folgenden Create-Table-Anweisungen und führen Sie sie aus, um Tabellen in der
dev-Datenbank zu erstellen. Weitere Informationen zur Syntax finden Sie unter CREATE TABLE im Datenbankentwicklerhandbuch zu Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
Erstellen Sie in Query Editor v2 eine neue SQL-Zelle in Ihrem Notebook.
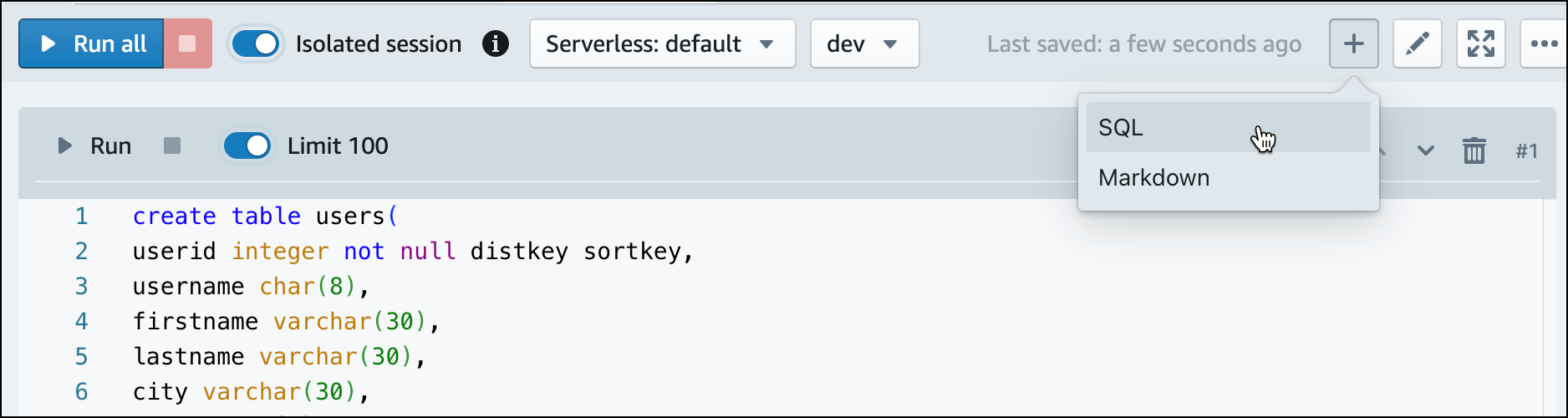
-
Verwenden Sie nun den Befehl COPY in Query Editor v2, um große Datensätze aus Amazon S3 oder Amazon DynamoDB in Amazon Redshift zu laden. Weitere Informationen zur COPY-Syntax finden Sie unter COPY im Datenbankentwicklerhandbuch zu Amazon Redshift.
Sie können den Befehl COPY mit Beispieldaten ausführen, die in einem öffentlichen S3-Bucket verfügbar sind. Führen Sie die folgenden SQL-Befehle in Query Editor v2 aus.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Erstellen Sie nach dem Laden der Daten eine weitere SQL-Zelle in Ihrem Notebook und probieren Sie einige Beispielabfragen aus. Weitere Informationen zur Verwendung des SELECT-Befehls finden Sie unter SELECT im Amazon-Redshift-Entwicklerhandbuch. Verwenden Sie Query Editor v2, um die Struktur und die Schemata der Beispieldaten zu verstehen.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Nachdem Sie nun Daten geladen und einige Beispielabfragen ausgeführt haben, können Sie andere Bereiche von Amazon Redshift Serverless erkunden. In der folgenden Übersicht erfahren Sie mehr über die Verwendungsmöglichkeiten von Amazon Redshift Serverless.
-
Sie können Daten aus einem Amazon-S3-Bucket laden. Weitere Informationen finden Sie unter Laden von Daten aus Amazon S3.
-
Sie können Query Editor v2 verwenden, um Daten aus einer lokalen zeichengetrennten Datei mit weniger als 5 MB zu laden. Weitere Informationen finden Sie unter Laden von Daten aus einer lokalen Datei.
-
Sie können eine Verbindung zu Amazon Redshift Serverless mit SQL-Tools von Drittanbietern mit dem JDBC- und ODBC-Treiber herstellen. Weitere Informationen finden Sie unter Verbinden mit Amazon Redshift Serverless.
-
Sie können die Amazon-Redshift-Daten-API auch verwenden, um eine Verbindung mit Amazon Redshift Serverless herzustellen. Weitere Informationen finden Sie unter Verwenden der Amazon-Redshift-Daten-API
. -
Sie können Ihre Daten in Amazon Redshift Serverless mit Redshift ML verwenden, um Machine-Learning-Modelle mit dem Befehl CREATE MODEL zu erstellen. Im Tutorial: Erstellen von Kundenabwanderungsmodellen erfahren Sie, wie Sie ein Redshift-ML-Modell erstellen.
-
Sie können Daten aus einem Amazon S3 Data Lake abfragen, ohne Daten in Amazon Redshift Serverless laden zu müssen. Weitere Informationen finden Sie unter Abfragen eines Data Lake.
