Tutorial: introducción a S3 Express One Zone
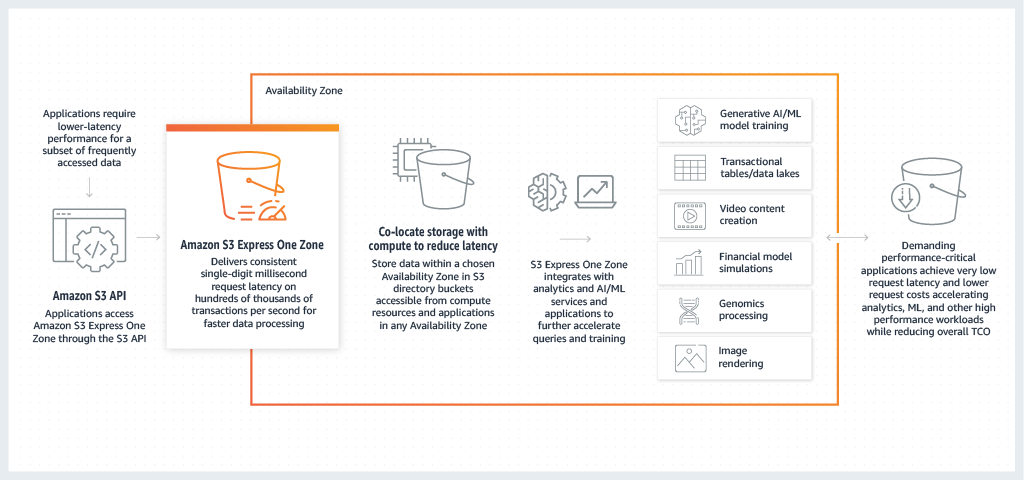
Amazon S3 Express One Zone es la primera clase de almacenamiento de S3 en la que se puede seleccionar una única zona de disponibilidad con la opción de coubicar su almacenamiento de objetos junto con sus recursos de computación, lo que ofrece la mayor velocidad de acceso posible. Los datos de S3 Express One Zone se almacenan en buckets de directorio ubicados en zonas de disponibilidad. Para obtener más información acerca de los buckets de directorio, consulte Buckets de directorio.
S3 Express One Zone es ideal para cualquier aplicación en la que sea importante minimizar la latencia de las solicitudes. Estas aplicaciones pueden ser flujos de trabajo interactivos entre humanos, como la edición de vídeo, en los que los profesionales creativos necesitan un acceso fluido al contenido desde sus interfaces de usuario. S3 Express One Zone también beneficia a las cargas de trabajo de análisis y machine learning que tienen requisitos de capacidad de respuesta similares a los de sus datos, especialmente las cargas de trabajo con muchos accesos más pequeños o un gran número de accesos aleatorios. S3 Express One Zone puede utilizarse con otros servicios de AWS como Amazon EMR, Amazon Athena, AWS Glue Data Catalog y Amazon SageMaker Model Training para admitir cargas de trabajo de análisis, inteligencia artificial y machine learning (IA/ML). Puede trabajar con la clase de almacenamiento S3 Express One Zone y los buckets de directorio mediante la consola de Amazon S3, los AWS SDK, la interfaz de la línea de comandos de AWS (CLI de AWS) y la API de REST de Amazon S3. Para obtener más información, consulte ¿Qué es S3 Express One Zone? y ¿En qué se diferencia S3 Express One Zone?
Objetivo
En este tutorial, aprenderá a crear un punto de conexión de puerta de enlace, a crear y asociar una política de IAM, a crear un bucket de directorio y, a continuación, a utilizar la acción de importación para rellenar el bucket de directorio con los objetos que actualmente están almacenados en el bucket de uso general. También puede cargar objetos de forma manual en el bucket de directorio.
Temas
Paso 2: crear un bucket de directorio de S3 Express One Zone
Paso 3: importar datos a un bucket de directorio de S3 Express One Zone
Paso 4: cargar manualmente objetos al bucket de directorio de S3 Express One Zone
Paso 5: vaciar el bucket de directorio de S3 Express One Zone
Paso 6: eliminar el bucket de directorio de S3 Express One Zone
Requisitos previos
Antes de empezar este tutorial, debe tener una Cuenta de AWS en la que puede iniciar sesión como usuario de AWS Identity and Access Management (IAM) con los permisos correctos.
Pasos secundarios
Cree una Cuenta de AWS
Para completar este tutorial, se necesita una Cuenta de AWS. Cuando se registra en AWS, su Cuenta de AWS se registra automáticamente en todos los servicios de AWS, incluido Amazon S3. Solo se le cobrará por los servicios que utilice. Para obtener más información acerca de los precios, consulte Precios de S3
Creación de un usuario de IAM en su Cuenta de AWS (consola)
AWS Identity and Access Management (IAM) es un Servicio de AWS que ayuda a los administradores a controlar de forma segura el acceso a los recursos de AWS. Los administradores de IAM controlan quién puede autenticarse (iniciar sesión) y autorizarse (tener permisos) para acceder a los objetos y utilizar buckets de directorio en S3 Express One Zone. El uso de IAM no está sujeto a ningún cargo adicional.
De forma predeterminada, los usuarios no tienen permisos para acceder a buckets de directorio y realizar operaciones en S3 Express One Zone. Para conceder permisos de acceso a los buckets de directorio y a las operaciones de S3 Express One Zone, puede usar IAM para crear usuarios o roles y asociar permisos a esas identidades. Para obtener más información acerca de cómo crear un usuario de IAM, consulte Creación del primer grupo de usuarios y administradores de IAM en la guía del usuario de IAM. Para obtener más información sobre cómo crear un rol de IAM, consulte Creación de un rol para delegar permisos a un usuario de IAM en la Guía del usuario de IAM.
Para simplificar, este tutorial crea y utiliza un usuario de IAM. Después de completar este tutorial, recuerde Eliminación del rol de IAM. Para uso en producción, le recomendamos que siga las Prácticas recomendadas de seguridad de IAM en la Guía del usuario de IAM. Una práctica recomendada exige que los usuarios humanos utilicen la federación con un proveedor de identidades para acceder a AWS con credenciales temporales. Otra práctica recomendada es exigir a las cargas de trabajo que utilicen credenciales temporales con roles de IAM para acceder a AWS. Para obtener más información sobre el uso de AWS IAM Identity Center para crear usuarios con credenciales temporales, consulte Introducción en la Guía del usuario de AWS IAM Identity Center.
aviso
Los usuarios de IAM tienen credenciales de larga duración, lo que supone un riesgo de seguridad. Para ayudar a mitigar este riesgo, le recomendamos que brinde a estos usuarios únicamente los permisos que necesitan para realizar la tarea y que los elimine cuando ya no los necesiten.
Creación de una política de IAM personalizada y asociación de esta a un rol o usuario de IAM (consola)
De forma predeterminada, los usuarios no tienen permisos para los buckets de directorio ni para las operaciones de S3 Express One Zone. Para conceder permisos de acceso a los buckets de directorio, puede usar IAM para crear usuarios, grupos o roles y asociar permisos a esas identidades. Los buckets de directorio son el único recurso que puede incluir en las políticas de bucket o en las políticas de identidad de IAM para el acceso a S3 Express One Zone.
Para utilizar las operaciones de la API de puntos de conexión regionales (operaciones de bucket o plano de control) con S3 Express One Zone, utilice el modelo de autorización de IAM, que no implica la administración de sesiones. Los permisos se conceden para las acciones de forma individual. Para utilizar las operaciones de la API de puntos de conexión zonales (operaciones de objeto o plano de datos), utilice CreateSession para crear y administrar sesiones optimizadas para la autorización de solicitudes de datos con baja latencia. Para recuperar y usar un token de sesión, debe permitir la acción s3express:CreateSession para su bucket de directorio en una política basada en identidades o en una política de bucket. Si accede a S3 Express One Zone en la consola de Amazon S3, a través de la interfaz de la línea de comandos de AWS (CLI de AWS) o mediante los AWS SDK, S3 Express One Zone crea una sesión en su nombre. Para obtener más información, consulte Autorización de CreateSession y AWS Identity and Access Management (IAM) para S3 Express One Zone.
Creación de una política de IAM y asociación de esta a un usuario (o rol) de IAM
Inicie sesión en la consola de administración de AWS y abra la consola de administración de IAM.
En el panel de navegación, seleccione Políticas.
Seleccione Crear política.
Seleccione JSON.
Copie la siguiente política en la ventana del Editor de políticas. Para poder crear buckets de directorio o utilizar S3 Express One Zone, debe conceder los permisos necesarios a su rol o usuarios de AWS Identity and Access Management (IAM). Esta política de ejemplo permite el acceso a la operación de la API
CreateSession(para utilizarla con las operaciones de la API zonales o de objeto) y a todas las operaciones de la API del punto de conexión regional (de bucket). Esta política permite que la operación de la APICreateSessionse utilice con todos los buckets de directorio, pero las operaciones de la API de punto de conexión regional solo se permiten con el bucket de directorio especificado. Para utilizar esta política de ejemplo, sustituyauser input placeholdersElija Siguiente.
Asigne un nombre a la política.
nota
Las etiquetas de bucket no son compatibles con S3 Express One Zone.
-
Seleccione Crear política.
-
Ahora que ha creado una política de IAM, puede asociarla a un usuario de IAM. En el panel de navegación, seleccione Políticas.
En la barra de búsqueda, escriba el nombre de la política.
En el menú Acciones, seleccione Asociar.
En Filtrar por tipo de entidad, seleccione Usuarios de IAM o Roles.
En el campo de búsqueda, escriba el nombre del usuario o rol que desee utilizar.
Seleccione Asociar política.
Temas
Siguientes pasos
En este tutorial, ha aprendido a crear un bucket de directorio y a utilizar la clase de almacenamiento S3 Express One Zone. Después de completar este tutorial, puede explorar los servicios relacionados de AWS que puede utilizar con la clase de almacenamiento S3 Express One Zone.
Puede utilizar los siguientes Servicios de AWS con la clase de almacenamiento S3 Express One Zone para admitir su caso de uso específico de baja latencia.
-
Amazon Elastic Compute Cloud (Amazon EC2): Amazon EC2 proporciona capacidad de computación escalable y segura en la Nube de AWS. El uso de Amazon EC2 reduce la necesidad de invertir inicialmente en hardware, de manera que puede desarrollar e implementar aplicaciones en menos tiempo. Puede usar Amazon EC2 para lanzar tantos servidores virtuales como necesite, configurar la seguridad y las redes, y administrar el almacenamiento.
-
AWS Lambda – Lambda es un servicio informático que permite ejecutar código sin aprovisionar ni administrar servidores. Puede configurar las opciones de notificación en un bucket y conceder a Amazon S3 permiso para invocar una función en la política de permisos basada en recursos de la función.
-
Amazon Elastic Kubernetes Service (Amazon EKS): Amazon EKS es un servicio administrado que elimina la necesidad de instalar, operar y mantener su propio plano de control de Kubernetes en AWS. Kubernetes
es un sistema de código abierto que automatiza la administración, el escalado y la implementación de aplicaciones en contenedores. -
Amazon Elastic Container Service (Amazon ECS): Amazon ECS es un servicio de orquestación de contenedores completamente administrado que facilita la implementación, la administración y el escalado de aplicaciones en contenedores.
-
Amazon EMR: Amazon EMR es una plataforma de clúster administrada que simplifica la ejecución de los marcos de macrodatos, tales como Apache Hadoop y Apache Spark, en AWS para procesar y analizar grandes cantidades de datos.
-
Amazon Athena: Athena es un servicio de consultas interactivo que facilita el análisis de datos directamente en Amazon S3 con SQL estándar. También puede usar Athena para ejecutar análisis de datos de forma interactiva mediante Apache Spark sin tener que planificar, configurar ni administrar los recursos. Cuando ejecuta aplicaciones de Apache Spark en Athena, envía el código de Spark para su procesamiento y recibe los resultados directamente.
-
Catálogo de datos de AWS Glue: AWS Glue es un servicio de integración de datos sin servidor que hace más fácil a los usuarios de análisis descubrir, preparar, trasladar e integrar datos desde varios orígenes. Puede utilizar AWS Glue para análisis, machine learning y desarrollo de aplicaciones. AWS Catálogo de datos de AWS Glue es un repositorio centralizado que almacena metadatos sobre los conjuntos de datos de su organización. Actúa como un índice para las métricas de tiempo de ejecución, esquema y ubicación de sus orígenes de datos.
-
Entrenamiento del modelo de tiempo de ejecución de Amazon SageMaker: el tiempo de ejecución de Amazon SageMaker es un servicio de machine learning completamente administrado. El tiempo de ejecución de SageMaker permite a los desarrolladores y a los analistas de datos crear y entrenar modelos de machine learning de forma rápida y sencilla y, a continuación, implementarlos directamente en un entorno alojado listo para producción.
Para obtener más información sobre S3 Express One Zone, consulte ¿Qué es S3 Express One Zone? y ¿En qué se diferencia S3 Express One Zone?
