Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Para ejecutar un trabajo híbrido con Amazon Braket Hybrid Jobs, primero debe definir su algoritmo. Puede definirlo escribiendo el script del algoritmo y, si lo desea, otros archivos de dependencia mediante el Amazon Braket Python SDK
En cualquier caso, a continuación, debe crear un trabajo híbrido con Amazon Braket. API, donde proporciona el script o contenedor de su algoritmo, selecciona el dispositivo cuántico objetivo que va a utilizar el trabajo híbrido y, a continuación, elige entre una variedad de ajustes opcionales. Los valores predeterminados que se proporcionan para estos ajustes opcionales funcionan en la mayoría de los casos de uso. Para que el dispositivo de destino ejecute su Hybrid Job, puede elegir entre una QPU o un simulador bajo demanda (como SV1, DM1 o TN1) o la clásica instancia de trabajo híbrida en sí misma. Con un simulador bajo demanda o una QPU, su contenedor de trabajos híbrido realiza llamadas a la API a un dispositivo remoto. Con los simuladores integrados, el simulador está integrado en el mismo contenedor que el script del algoritmo. Los simuladores Lightning
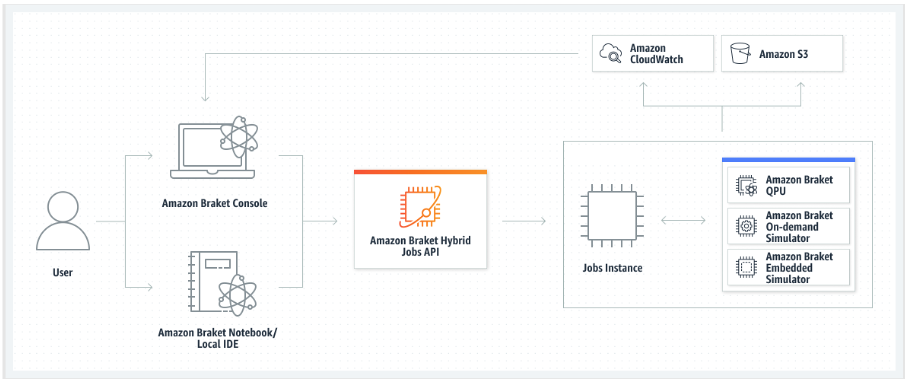
Si el dispositivo de destino es un simulador integrado o bajo demanda, Amazon Braket comienza a ejecutar el trabajo híbrido de inmediato. Activa la instancia de trabajo híbrida (puede personalizar el tipo de instancia en API call), ejecuta su algoritmo, escribe los resultados en Amazon S3 y libera sus recursos. Esta versión de recursos garantiza que solo pague por lo que utilice.
El número total de trabajos híbridos simultáneos por unidad de procesamiento cuántico (QPU) está restringido. En la actualidad, solo se puede ejecutar un trabajo híbrido en una QPU en un momento dado. Las colas se utilizan para controlar la cantidad de trabajos híbridos que se pueden ejecutar a fin de no superar el límite permitido. Si el dispositivo de destino es una QPU, el trabajo híbrido entra primero en la cola de trabajos de la QPU seleccionada. Amazon Braket activa la instancia de trabajo híbrida necesaria y ejecuta tu trabajo híbrido en el dispositivo. Mientras dure su algoritmo, su trabajo híbrido tiene acceso prioritario, lo que significa que las tareas cuánticas de su trabajo híbrido se ejecutan antes que otras tareas cuánticas de Braket que están en cola en el dispositivo, siempre que las tareas cuánticas del trabajo se envíen a la QPU una vez cada pocos minutos. Una vez que haya completado su trabajo híbrido, se liberarán los recursos, lo que significa que solo pagará por lo que utilice.
nota
Los dispositivos son regionales y tu trabajo híbrido se ejecuta de la Región de AWS misma manera que tu dispositivo principal.
Tanto en el escenario objetivo del simulador como en el de la QPU, tiene la opción de definir métricas algorítmicas personalizadas, como la energía de su hamiltoniano, como parte de su algoritmo. Estas métricas se notifican automáticamente a Amazon CloudWatch y, desde allí, se muestran casi en tiempo real en la consola Amazon Braket.
nota
Si deseas usar una instancia basada en GPU, asegúrate de usar uno de los simuladores basados en GPU disponibles con los simuladores integrados en Braket (por ejemplo,). lightning.gpu Si eliges uno de los simuladores integrados basados en la CPU (por ejemplo, obraket:default-simulator)lightning.qubit, no se utilizará la GPU y es posible que incurras en costes innecesarios.
