Esta es la guía para desarrolladores de AWS CDK v2. La primera versión del CDK pasó a la etapa de mantenimiento el 1.° de junio de 2022 y no cuenta con soporte desde el 1.° de junio de 2023.
Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Mejores prácticas para desarrollar e implementar una infraestructura de nube con el AWS CDK
Con la AWS CDK, los desarrolladores o administradores pueden definir su infraestructura de nube mediante un lenguaje de programación compatible. Las aplicaciones de CDK deben organizarse en unidades lógicas, como la API, la base de datos y los recursos de supervisión y, opcionalmente, tener una canalización para las implementaciones automatizadas. Las unidades lógicas deben implementarse como constructos que incluyan lo siguiente:
-
Infraestructura (como buckets de Amazon S3, bases de datos de Amazon RDS o una red de Amazon VPC).
-
Código de tiempo de ejecución (como las AWS funciones Lambda)
-
Código de configuración.
Las pilas definen el modelo de implementación de estas unidades lógicas. Para obtener una introducción más detallada a los conceptos en los que se basa la CDK, consulte Introducción a la AWS CDK.
El AWS CDK refleja una consideración cuidadosa de las necesidades de nuestros clientes y equipos internos y de los patrones de falla que suelen surgir durante la implementación y el mantenimiento continuo de aplicaciones en la nube complejas. Descubrimos que los fallos suelen estar relacionados con «out-of-band» cambios en una aplicación que no se han probado completamente, como los cambios de configuración. Por lo tanto, desarrollamos el AWS CDK en torno a un modelo en el que toda la aplicación se define en código, no solo en la lógica empresarial, sino también en la infraestructura y la configuración. De esta forma, los cambios propuestos pueden revisarse detenidamente, probarse de manera exhaustiva en entornos que se asemejen en mayor o menor medida a los de producción y revertirse por completo si algo sale mal.
En el momento de la implementación, la AWS CDK sintetiza un conjunto de nubes que contiene lo siguiente:
-
AWS CloudFormation plantillas que describen su infraestructura en todos los entornos de destino
-
Recursos de archivos que contienen su código de tiempo de ejecución y sus archivos de apoyo.
Con CDK, cada confirmación realizada en la rama principal del control de versiones de la aplicación puede representar una versión completa, coherente e implementable de la aplicación. De este modo, la aplicación se puede implementar automáticamente cada vez que se realice un cambio.
La filosofía en la que se basa el AWS CDK se basa en nuestras mejores prácticas recomendadas, que hemos dividido en cuatro amplias categorías.
sugerencia
Tenga en cuenta también las mejores prácticas AWS CloudFormation y los AWS servicios individuales que utilice, cuando proceda a la infraestructura definida por el CDK.
Prácticas recomendadas de organizaciones
En las etapas iniciales de la adopción de las AWS CDK, es importante considerar cómo configurar su organización para el éxito. Se recomienda contar con un equipo de expertos que se encargue de entrenar y guiar al resto de la empresa a medida que adopta CDK. El tamaño de este equipo puede variar, desde una o dos personas en una empresa pequeña hasta un centro de excelencia (CCoE) completo en la nube en una empresa más grande. Este equipo es responsable de establecer estándares y políticas para la infraestructura en la nube de su empresa, y también de entrenar y guiar a los desarrolladores.
La CCo E podría proporcionar orientación sobre qué lenguajes de programación deberían usarse para la infraestructura de nube. Los detalles varían de una organización a otra, pero una buena política permite garantizar que los desarrolladores entienden y pueden mantener la infraestructura en la nube de la empresa.
La CCo E también crea una «landing zone» que define tus unidades organizativas en su interior AWS. Una landing zone es un AWS entorno multicuenta preconfigurado, seguro, escalable y basado en planes de mejores prácticas. Para unir los servicios que componen su zona de aterrizaje, puede usar AWS Control Tower
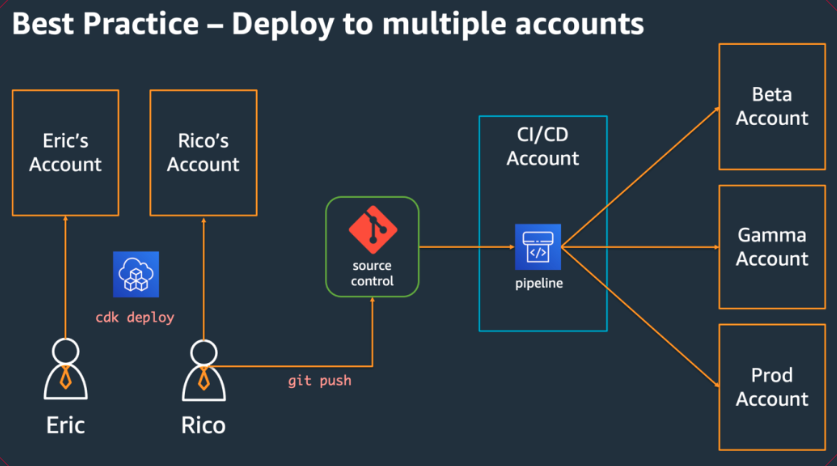
Los equipos de desarrollo deberían poder usar sus propias cuentas para realizar pruebas e implementar nuevos recursos en estas cuentas según sea necesario. Los desarrolladores individuales pueden utilizar estos recursos como extensiones de su propia estación de trabajo de desarrollo. Con CDK Pipelines, AWS las aplicaciones de CDK se pueden implementar a través de CI/CD una cuenta en entornos de prueba, integración y producción (cada uno aislado en su AWS propia región o cuenta). Para ello, se fusiona el código de los desarrolladores en el repositorio canónico de la organización.
Prácticas recomendadas de codificación
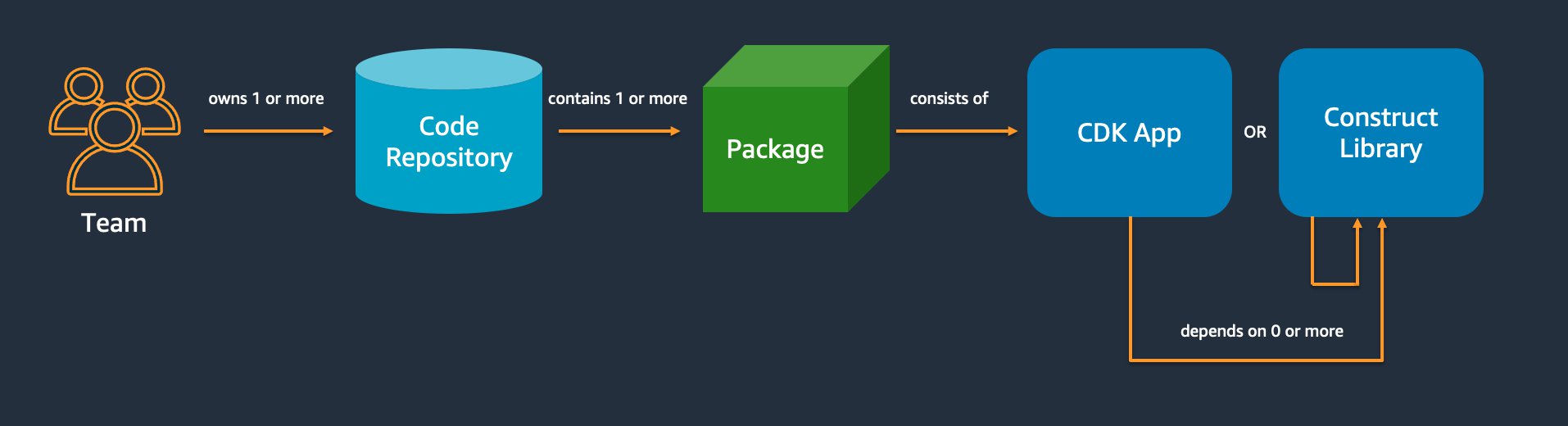
En esta sección, se presentan las prácticas recomendadas para organizar el código AWS CDK. El siguiente diagrama muestra la relación entre un equipo y los repositorios de código, los paquetes, las aplicaciones y las bibliotecas de constructos de ese equipo.
- Comience de forma sencilla y añada complejidad solo cuando la necesite
-
El principal propósito de la mayoría de las prácticas recomendadas es simplificar al máximo las cosas, pero no demasiado. Agregue complejidad solo cuando sus requisitos exijan una solución más complicada. Con el AWS CDK, puede refactorizar el código según sea necesario para adaptarlo a los nuevos requisitos. No es necesario que diseñe por adelantado todos los escenarios posibles.
- Alinéese con el marco de AWS Well-Architected
-
El AWS Well-Architected
Framework define un componente como el código, la configuración AWS y los recursos que, en conjunto, cumplen con un requisito. El componente suele ser la unidad de responsabilidad técnica y está desacoplado de otros componentes. El término carga de trabajo se usa para identificar un grupo de componentes que, en conjunto, proporcionan valor de negocio. La carga de trabajo suele ser el nivel de detalle sobre el que hablan los líderes tecnológicos y comerciales. Una aplicación de AWS CDK se asigna a un componente tal como se define en el AWS Well-Architected Framework. AWS Las aplicaciones CDK son un mecanismo para codificar y ofrecer las mejores prácticas de aplicaciones en la nube de Well-Architected. También puede crear y compartir componentes como bibliotecas de códigos reutilizables a través de repositorios de artefactos, como AWS CodeArtifact.
- Cada aplicación comienza con un único paquete en un único repositorio
-
Un solo paquete es el punto de entrada de su aplicación AWS CDK. Aquí, usted define cómo y dónde implementar las diferentes unidades lógicas de su aplicación. También debe definir la CI/CD canalización para implementar la aplicación. Los constructos de la aplicación definen las unidades lógicas de la solución.
Utilice paquetes adicionales para los constructos que utilice en más de una aplicación. (Los constructos compartidos también deben tener su propio ciclo de vida y estrategia de pruebas). Las dependencias entre los paquetes del mismo repositorio se administran mediante las herramientas de compilación de su repositorio.
Si bien es posible, no recomendamos colocar varias aplicaciones en el mismo repositorio, en especial cuando se utilizan canalizaciones de implementación automatizadas. De este modo, se aumenta el “radio de impacto” de los cambios durante la implementación. Cuando hay varias aplicaciones en un repositorio, los cambios en una aplicación provocan la implementación de las demás (aunque las otras no hayan cambiado). Además, una interrupción en una aplicación impide que se implementen las demás.
- Mueva el código a los repositorios en función del ciclo de vida del código o de la propiedad del equipo
-
Cuando los paquetes comiencen a usarse en varias aplicaciones, muévalos a su propio repositorio. De esta forma, las cargas de trabajo de las aplicaciones que los utilizan pueden hacer referencia a los paquetes, y también se pueden actualizar en cadencias independientes de los ciclos de vida de las aplicaciones. Sin embargo, al principio podría tener sentido colocar todos los constructos compartidos en un repositorio.
Además, mueva los paquetes a su propio repositorio cuando diferentes equipos estén trabajando en ellos. Esto ayuda a aplicar el control de acceso.
Para consumir paquetes más allá de los límites del repositorio, necesitas un repositorio de paquetes privado, similar a NPM o Maven Central PyPi, pero interno en tu organización. También necesitas un proceso de publicación que compile, pruebe y publique el paquete en el repositorio de paquetes privado. CodeArtifactpuede alojar paquetes para los lenguajes de programación más populares.
Las dependencias de los paquetes del repositorio de paquetes las gestiona el administrador de paquetes de su idioma, como NPM for TypeScript or JavaScript applications. Su administrador de paquetes garantiza que las compilaciones sean repetibles. Para ello, graba las versiones específicas de cada paquete del que depende su aplicación. También le permite actualizar esas dependencias de manera controlada.
Los paquetes compartidos necesitan una estrategia de pruebas diferente. En el caso de una sola aplicación, podría bastar con implementarla en un entorno de pruebas y confirmar que continúa funcionando. Pero los paquetes compartidos deben probarse por separado de la aplicación que los utilice, como si se estuvieran lanzando al público. (Es posible que su organización decida lanzar al público algunos paquetes compartidos).
Tenga en cuenta que un constructo puede ser arbitrariamente simple o complejo. Un
Bucketes un constructo, pero tambiénCameraShopWebsitepodría ser uno.
- La infraestructura y el código de ejecución se encuentran en el mismo paquete
-
Además de generar AWS CloudFormation plantillas para implementar la infraestructura, la AWS CDK también agrupa activos de tiempo de ejecución, como funciones Lambda e imágenes de Docker, y los despliega junto con su infraestructura. Esto hace posible combinar el código que define la infraestructura y el código que implementa la lógica de tiempo de ejecución en un solo constructo. Hacer esto es una práctica recomendada. No es necesario que estos dos tipos de código se encuentren en repositorios separados o incluso en paquetes separados.
Para desarrollar los dos tipos de código juntos, puede utilizar un constructo independiente que describa por completo una parte de la funcionalidad, incluidas su infraestructura y lógica. Con un constructo independiente, puede probar los dos tipos de código de forma aislada, compartir y reutilizar el código en todos los proyectos y versionar todo el código de forma sincronizada.
Prácticas recomendadas para constructos
Esta sección contiene las prácticas recomendadas para desarrollar constructos. Los constructos son módulos reutilizables y compatibles con la composición que encapsulan los recursos. Son los componentes básicos de las aplicaciones de CDK. AWS
- Modele con componentes fijos e impleméntelo con pilas
-
Las pilas son la unidad de implementación: todos los elementos de una pila se implementan juntos. Por lo tanto, cuando cree las unidades lógicas de nivel superior de su aplicación a partir de varios AWS recursos, represente cada unidad lógica como una construcción, no como una pila. Utilice las pilas únicamente para describir cómo deben componerse y conectarse los constructos en los distintos escenarios de implementación.
Por ejemplo, si una de sus unidades lógicas es un sitio web, los constructos que lo integran (como un bucket de Amazon S3, la API Gateway, las funciones de Lambda o las tablas de Amazon RDS) deben estar compuestas en un único constructo de alto nivel. Luego, ese constructo se instancia en una o más pilas para su implementación.
Al utilizar constructos para la compilación y pilas para la implementación, mejora el potencial de reutilización de su infraestructura y obtiene más flexibilidad a la hora de implementarla.
- Configure con propiedades y métodos, no con variables de entorno
-
Las búsquedas de variables de entorno dentro de los constructos y las pilas son un antipatrón común. Tanto los constructos como las pilas deben aceptar un objeto de propiedades para permitir una configurabilidad completa en el código. De lo contrario, se crea una dependencia de la máquina en la que se ejecutará el código, lo que crea aún más información de configuración a la que hay que hacerle seguimiento y administrar.
En general, las búsquedas de variables de entorno deben limitarse al nivel superior de una aplicación de AWS CDK. También deberían usarse para transmitir la información necesaria para ejecutarse en un entorno de desarrollo. Para obtener más información, consulte Entornos del CDK. AWS
- Realice pruebas unitarias de su infraestructura
-
Para ejecutar de forma coherente un conjunto completo de pruebas unitarias en el momento de la compilación en todos los entornos, evite las búsquedas en la red durante la síntesis y modele todas las etapas de producción en código. (Estas prácticas recomendadas se describen más adelante). Si una sola confirmación siempre da como resultado la misma plantilla generada, puede confiar en las pruebas unitarias que escriba para confirmar que las plantillas generadas tienen el aspecto esperado. Para obtener más información, consulte Probar aplicaciones de AWS CDK.
- No cambie el ID lógico de los recursos con estado
-
Si se cambia el ID lógico de un recurso, se sustituirá por uno nuevo en la siguiente implementación. Esto no suele necesitarse para los recursos con estado, como las bases de datos y los buckets de S3, ni para la infraestructura persistente, como un Amazon VPC. Tenga cuidado con cualquier refactorización del código AWS CDK que pueda provocar un cambio en el identificador. Escribe pruebas unitarias que confirmen que la lógica IDs de tus recursos con estado permanece estática. El ID lógico deriva del
idespecificado al crear el constructo y de la posición de este en el árbol de constructos. Para obtener más información, consulte Logical IDs.
- Los constructos no son suficientes para garantizar la conformidad
-
Muchos clientes empresariales diseñan sus propios contenedores para las construcciones de nivel 2 (las construcciones «seleccionadas» que representan AWS recursos individuales e incorporan prácticas recomendadas y predeterminadas). Estos contenedores aplican las prácticas recomendadas de seguridad, como el cifrado estático y las políticas de IAM específicas. Por ejemplo, puede crear una
MyCompanyBucketque luego utilice en sus aplicaciones en lugar del constructo habitual deBucketde Amazon S3. Este patrón es útil para ofrecer directrices de seguridad al principio del ciclo de vida de desarrollo del software, pero no debe basarse en él como único medio de aplicación.En su lugar, utilice AWS funciones como las políticas de control de servicios y los límites de permisos para reforzar las barreras de seguridad a nivel de la organización. Utilice Aspects y el AWS CDK o herramientas como CloudFormation Guard
para hacer afirmaciones sobre las propiedades de seguridad de los elementos de la infraestructura antes de su despliegue. Use AWS CDK para lo que mejor sabe hacer. Por último, tenga en cuenta que escribir sus propias construcciones «L2+» puede impedir que sus desarrolladores aprovechen los paquetes de AWS CDK, como AWS Solutions Constructs, o las construcciones de terceros de Construct Hub. Por lo general, estos paquetes se basan en construcciones de AWS CDK estándar y no podrán usar las construcciones de su contenedor.
Prácticas recomendadas de la aplicación
En esta sección, analizamos cómo escribir sus aplicaciones de AWS CDK, combinando construcciones para definir cómo están conectados sus recursos. AWS
- Tome decisiones en el momento de la síntesis
-
Si bien AWS CloudFormation le permite tomar decisiones en el momento de la implementación (utilizando
Conditions{ Fn::If }, yParameters) y el AWS CDK le brinda cierto acceso a estos mecanismos, le recomendamos que no los utilice. Los tipos de valores que puede utilizar y los tipos de operaciones que puede realizar con ellos son limitados en comparación con lo que está disponible en el lenguaje de programación de uso general.En su lugar, intente tomar todas las decisiones, como qué construcción crear una instancia, en su aplicación de AWS CDK, utilizando las
ifinstrucciones del lenguaje de programación y otras funciones. Por ejemplo, una expresión común de CDK, que repite una lista y crea instancias de una construcción con valores de cada elemento de la lista, simplemente no es posible utilizar expresiones. AWS CloudFormationAWS CloudFormation Tómatelo como un detalle de implementación que el AWS CDK utiliza para despliegues sólidos en la nube, no como un objetivo lingüístico. No estás escribiendo AWS CloudFormation plantillas en TypeScript Python, estás escribiendo código CDK que resulta que se usa CloudFormation para la implementación.
- Usa nombres de recursos generados, no nombres físicos
-
Los nombres son un recurso valioso. Cada nombre solo se puede usar una vez. Por lo tanto, si codifica el nombre de una tabla o de un bucket en su infraestructura y aplicación, no podrá implementar esa parte de la infraestructura dos veces en la misma cuenta. (El nombre del que hablamos aquí es el nombre especificado, por ejemplo, por la propiedad del
bucketNamede un constructo de bucket de Amazon S3).Y lo que es peor, no puede realizar cambios en el recurso que necesiten su sustitución. Si una propiedad solo se puede establecer en el momento de la creación del recurso, como
KeySchemade una tabla de Amazon DynamoDB, entonces esa propiedad es inmutable. Se requiere un nuevo recurso para cambiar esta propiedad. Sin embargo, el nuevo recurso debe tener el mismo nombre para que sea una verdadera sustitución. No obstante, no puede tener el mismo nombre mientras el recurso existente siga usando ese nombre.Lo mejor es especificar la menor cantidad de nombres posible. Si omites los nombres de los recursos, el AWS CDK los generará automáticamente sin problemas. Supongamos que tiene una tabla como recurso. A continuación, puede pasar el nombre de la tabla generada como variable de entorno a la AWS función Lambda. En su aplicación AWS CDK, puede hacer referencia al nombre de la tabla como.
table.tableNameComo alternativa, puedes generar un archivo de configuración en tu EC2 instancia de Amazon al iniciarla o escribir el nombre real de la tabla en el almacén de parámetros de AWS Systems Manager para que la aplicación pueda leerlo desde allí.Si el lugar donde lo necesitas es en otra pila de AWS CDK, es aún más sencillo. Si suponemos que una pila define el recurso y otra pila necesita usarlo, se aplica lo siguiente:
-
Si las dos pilas están en la misma aplicación de AWS CDK, pasa una referencia entre las dos pilas. Por ejemplo, guarda una referencia en el constructo del recurso como un atributo de la pila que la define (
this.stack.uploadBucket = amzn-s3-demo-bucket). A continuación, pasa ese atributo al constructor de la pila que necesita el recurso. -
Cuando las dos pilas estén en aplicaciones de AWS CDK diferentes, utilice un
frommétodo estático para utilizar un recurso definido externamente en función de su ARN, nombre u otros atributos. (Por ejemplo, useTable.fromArn()para una tabla de DynamoDB). Utilice laCfnOutputconstrucción para imprimir el ARN u otro valor necesario en la salida decdk deploy, o busque en la consola de AWS administración. Como alternativa, la segunda aplicación puede leer la CloudFormation plantilla generada por la primera aplicación y recuperar ese valor de laOutputssección.
-
- Defina las políticas de eliminación y la retención de registros
-
La AWS CDK intenta evitar que pierdas datos mediante políticas que conservan todo lo que has creado de forma predeterminada. Por ejemplo, la política de eliminación predeterminada de los recursos que contienen datos (como los buckets de Amazon S3 y las tablas de bases de datos) consiste en no eliminar el recurso cuando se elimina de la pila. En su lugar, el recurso queda huérfano de la pila. Del mismo modo, el valor predeterminado de CDK es retener todos los registros para siempre. En los entornos de producción, estos valores predeterminados pueden traducirse rápidamente en el almacenamiento de grandes cantidades de datos que en realidad no se necesitan y en la correspondiente factura. AWS
Considere de manera minuciosa qué políticas quiere para cada recurso de producción y especifíquelas según corresponda. Usa Aspects y la AWS CDK para validar las políticas de eliminación y registro de tu pila.
- Separe su aplicación en varias pilas según lo exijan los requisitos de implementación
-
No existe una regla estricta sobre la cantidad de pilas que necesita su aplicación. Por lo general, terminará tomando la decisión en función de sus patrones de implementación. Tenga en cuenta lo siguiente:
-
Por lo general, es más sencillo mantener tantos recursos en la misma pila como sea posible, así que manténgalos juntos a menos que quiera separarlos.
-
Considere la posibilidad de mantener los recursos con estado (como las bases de datos) en una pila separada de los recursos sin estado. Luego, puede activar la protección contra terminación en la pila con estado. De esta forma, destruirá o creará con total libertad varias copias de la pila sin estado sin arriesgarse a perder datos.
-
Los recursos con estado son más sensibles a la hora de cambiar el nombre del constructo, ya que este cambio implica la sustitución de recursos. Por lo tanto, no anide los recursos con estado dentro de constructos que puedan moverse o cambiar de nombre (a menos que el estado pueda volver a construirse si se pierde, como el caché). Esta es otra buena razón para colocar los recursos con estado en su propia pila.
-
- Comprométase
cdk.context.jsona evitar un comportamiento no determinista -
El determinismo es clave para el éxito de las implementaciones de CDK AWS . Básicamente, una aplicación de AWS CDK debería tener el mismo resultado siempre que se implemente en un entorno determinado.
Como tu aplicación AWS CDK está escrita en un lenguaje de programación de uso general, puede ejecutar código arbitrario, usar bibliotecas arbitrarias y realizar llamadas de red arbitrarias. Por ejemplo, puedes usar un AWS SDK para recuperar cierta información de tu AWS cuenta mientras sintetizas tu aplicación. Si lo hace, tenga en cuenta que tendrá que configurar las credenciales con requisitos adicionales, aumentará la latencia y habrá una posibilidad, por más pequeña que sea, de que se produzca un error cada vez que ejecute
cdk synth.Nunca modifiques tu AWS cuenta ni tus recursos durante la síntesis. Sintetizar una aplicación no debería tener efectos secundarios. Los cambios en la infraestructura solo deberían producirse en la fase de implementación, una vez que se haya generado la AWS CloudFormation plantilla. De esta forma, si hay algún problema, se AWS CloudFormation puede revertir automáticamente el cambio. Para realizar cambios que no se puedan realizar fácilmente en el marco de AWS CDK, usa recursos personalizados para ejecutar código arbitrario en el momento de la implementación.
Incluso las llamadas de solo lectura estrictas no son siempre seguras. Tenga en cuenta lo que ocurre si cambia el valor devuelto por una llamada de red. ¿Qué parte de su infraestructura se verá afectará por eso? ¿Qué pasará con los recursos ya implementados? Estos son dos ejemplos de situaciones en las que un cambio repentino en los valores podría provocar un problema.
-
Si aprovisiona una Amazon VPC a todas las zonas de disponibilidad disponibles en una región específica y el número de ellas AZs es de dos el día de la implementación, su espacio IP se divide por la mitad. Si AWS lanza una nueva zona de disponibilidad al día siguiente, la siguiente implementación intentará dividir el espacio IP en tercios, lo que requerirá que se vuelvan a crear todas las subredes. Probablemente esto no sea posible porque tus EC2 instancias de Amazon siguen ejecutándose y tendrás que limpiarlas manualmente.
-
Si busca la imagen de máquina Amazon Linux más reciente e implementa una EC2 instancia de Amazon y, al día siguiente, se publica una nueva imagen, una implementación posterior recoge la nueva AMI y reemplaza todas las instancias. Puede que esto no sea lo que esperaba que ocurriera.
Estas situaciones pueden ser perniciosas, ya que el cambio AWS radical puede producirse tras meses o años de implementaciones satisfactorias. De repente, sus implementaciones están fallando “sin motivo alguno” y hace tiempo que olvidó lo que hizo y por qué.
Afortunadamente, el AWS CDK incluye un mecanismo denominado proveedores de contexto para registrar una instantánea de valores no deterministas. Esto permite que las futuras operaciones de síntesis produzcan exactamente la misma plantilla que cuando se implementaron por primera vez. Los únicos cambios en la nueva plantilla son aquellos que usted realizó en el código. Cuando utiliza el método
.fromLookup()de un constructo, el resultado de la llamada se almacena en caché encdk.context.json. Para asegurarse de que en las futuras ejecuciones de su aplicación CDK se utilice el mismo valor, debería confirmarlo con el control de versiones junto con el resto del código. El kit de herramientas CDK incluye comandos para administrar el caché de contexto, de modo que pueda actualizar entradas específicas cuando lo necesite. Para obtener más información, consulte Los valores de contexto y la CDK. AWSSi necesita algún valor (de AWS o de otro lugar) para el que no haya un proveedor de contexto de CDK nativo, le recomendamos que escriba un script independiente. El script debe recuperar el valor y escribirlo en un archivo, y, luego, leerlo en la aplicación CDK. Ejecute el script solo cuando desee actualizar el valor almacenado, no como parte de su proceso de compilación habitual.
-
- Deje que la AWS CDK administre las funciones y los grupos de seguridad
-
Con la
grantspropiedad de la biblioteca de construcción AWS CDK y sus prácticos métodos, puede crear funciones de AWS Identity and Access Management que concedan acceso a un recurso a otro mediante permisos de ámbito mínimo. Por ejemplo, considere la siguiente línea:amzn-s3-demo-bucket.grants.read(myLambda)Esta línea única agrega una política al rol de la función de Lambda (que también se crea para usted). Esa función y sus políticas son más de una docena de líneas CloudFormation que no es necesario escribir. La AWS CDK solo concede los permisos mínimos necesarios para que la función lea el contenido del bucket.
Si se requiere que los desarrolladores utilicen siempre funciones predefinidas creadas por un equipo de seguridad, la codificación de la AWS CDK se vuelve mucho más complicada. Sus equipos podrían perder mucha flexibilidad a la hora de diseñar sus aplicaciones. Una mejor alternativa es utilizar políticas de control de servicios y límites de permisos para garantizar que los desarrolladores se mantengan dentro de las barreras de protección.
- Modele todas las etapas de producción en código
-
En AWS CloudFormation los escenarios tradicionales, el objetivo es producir un único artefacto parametrizado para que pueda implementarse en varios entornos de destino después de aplicar los valores de configuración específicos de esos entornos. En el CDK, puede y debe crear esa configuración en su código fuente. Cree una pila para su entorno de producción y una pila independiente para cada una de las demás etapas. A continuación, coloque los valores de configuración de cada pila en el código. Utilice servicios como Secrets Manager
y Systems Manager Parameter Store para valores confidenciales que no desee registrar en el control de código fuente, utilizando los nombres o ARNs de esos recursos. Al sintetizar la aplicación, el conjunto de nube creado en la carpeta
cdk.outcontiene una plantilla independiente para cada entorno. Toda la compilación es determinista. No hay out-of-band cambios en la aplicación y cualquier confirmación determinada siempre arroja exactamente la misma AWS CloudFormation plantilla y los recursos correspondientes. Esto hace que las pruebas unitarias sean mucho más fiables.
- Mídelo todo
-
Lograr el objetivo de una implementación continua y completa, sin intervención humana, requiere un nivel de automatización alto. Esa automatización solo es posible con una supervisión exhaustiva. Para medir todos los aspectos de los recursos implementados, cree métricas, alarmas y paneles de control. No se limite a medir aspectos como el uso de la CPU y el espacio en el disco. Registre también las métricas de su empresa y utilícelas para automatizar las decisiones de implementación, como las reversiones. La mayoría de las construcciones L2 de AWS CDK tienen métodos prácticos que te ayudan a crear métricas, como el
metricUserErrors()método de la clase.dynamodb.Table
