Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Entrenamiento y evaluación de modelos de AWS DeepRacer con la consola AWS DeepRacer
Para entrenar un modelo de aprendizaje por refuerzo, puede utilizar la consola de AWS DeepRacer. En la consola, cree un trabajo de entrenamiento, elija un marco compatible y un algoritmo disponible, añada una función de recompensa y configure los ajustes de entrenamiento. También puede ver el procedimiento de entrenamiento en un simulador. Puede encontrar las instrucciones paso a paso en Entrene su primer modelo de AWS DeepRacer .
En esta sección le explicamos cómo entrenar y evaluar un modelo de AWS DeepRacer. También se muestra cómo crear y mejorar una función de recompensa, cómo un espacio de acción afecta al rendimiento del modelo y cómo afectan los hiperparámetros al rendimiento del entrenamiento. Asimismo, puede aprender a clonar un modelo de entrenamiento para ampliar una sesión de entrenamiento, cómo utilizar el simulador para evaluar el rendimiento del entrenamiento y cómo abordar algunos de los retos que plantea el paso de la simulación a la vida real.
Temas
- Creación de su función de recompensa
- Exploración del espacio de acción para entrenar un modelo sólido
- Ajuste sistemático de hiperparámetros
- Examen de progreso del trabajo de entrenamiento de AWS DeepRacer
- Clonación de un modelo entrenado para comenzar un nuevo paso de entrenamiento
- Evaluación de modelos de AWS DeepRacer en simulaciones
- Optimización del entrenamiento de modelos de AWS DeepRacer para entornos reales
Creación de su función de recompensa
Una función de recompensa aporta una valoración inmediata (como puntuación de recompensa o penalización) cuando su vehículo de AWS DeepRacer se desplaza de una posición en la pista a una nueva posición. El objetivo de la función es fomentar que el vehículo se mueva por la pista para llegar rápidamente a un destino sin sufrir accidentes ni cometer infracciones. Si el movimiento que realiza el vehículo es deseable, se obtiene una puntuación más alta por la acción o el estado de destino. Si, por el contrario, el movimiento no está permitido o es innecesario, la puntuación obtenida es más baja. Al entrenar un modelo de AWS DeepRacer, la función de recompensa es la única parte específica de la aplicación.
Por lo general, la función de recompensa se diseña para que sirva como plan de incentivos. Según la estrategia de incentivos que se diseñe, el comportamiento del vehículo será diferente. Para que el vehículo vaya más rápido, la función debe recompensar que el vehículo siga la pista. Por otra parte, la función tiene que sancionar al vehículo cuando este tarda demasiado en finalizar una vuelta o se sale de la pista. Para evitar un patrón de conducción en zigzag, la función puede premiar que el vehículo se mueva con menos vaivenes cuando está en las rectas de la pista. La función de recompensa puede puntuar positivamente que el vehículo cumpla determinados hitos, medidos por waypoints. Esto puede compensar las esperas o conducir en la dirección equivocada. También es probable que cambie la función de recompensa para tener en cuenta las condiciones de la pista. Sin embargo, cuanta más información específica del entorno tenga en cuenta la función, más probable será que el modelo esté excesivamente especializado y sea menos general. Para que la aplicación de su modelo sea más general, puede explorar el espacio de acción.
Si un plan de incentivos no se sopesa con cuidado, es posible que se obtengan consecuencias inesperadas no deseadas
Una buena práctica para crear una función de recompensa consiste en comenzar con una función sencilla que cubra situaciones básicas. Puede mejorar la función para que incluya más acciones. Veamos ahora algunas funciones de recompensa sencillas.
Ejemplos de funciones de recompensa sencillas
Podemos comenzar a crear la función de recompensa abordando primero la situación más básica. Se trata de conducir en una pista recta, desde principio a fin, sin salirse de la vía. En este caso, la lógica de la función de recompensa depende solo de on_track y progress. Como ensayo, puede comenzar con la lógica siguiente:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Con esta lógica, se penaliza al agente cuando este se sale de la pista y se le premia cuando llega a la línea de meta. Es una lógica razonable para lograr el objetivo marcado. Sin embargo, el agente deambula libremente entre el punto de inicio y la línea de meta, y esto incluye la posibilidad de circular marcha atrás en la pista. Con ello vemos que el entrenamiento no solo puede tardar mucho tiempo en completarse sino que, además, el modelo entrenado tendría una conducción menos eficiente cuando se implementase en el vehículo real.
En la práctica, el aprendizaje del agente es más efectivo si puede hacerlo paso a paso a lo largo del entrenamiento. Esto implica que una función de recompensa debe dar recompensas menores paso a paso a lo largo de la pista. Para que el agente circule en la pista recta, podemos mejorar la función de recompensa del siguiente modo:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Con esta función, el agente consigue mayor recompensa cuando más se acerca a la línea de meta. Esto debería reducir o eliminar los ensayos improductivos de conducir marcha atrás. En general, queremos que la función de recompensa distribuya la recompensa de forma más uniforme en el espacio de acción. Crear una función de recompensa que sea efectiva puede suponer un verdadero desafío. Debe comenzar por una función de recompensa que sea sencilla y luego irla mejorando progresivamente. A través de la experimentación sistemática, la función puede ir adquiriendo mayor solidez y eficacia.
Mejora para su función de recompensa
Tras haber entrenado con éxito su modelo de AWS DeepRacer para la pista recta simple, el vehículo de AWS DeepRacer (virtual o físico) puede conducir por sí solo sin salirse de la pista. Si deja que el vehículo circule en una pista en bucle, no se mantendrá en la pista. La función de recompensa ha pasado por alto las acciones para hacer giros para seguir la pista.
Para que el vehículo pueda ejecutar estas acciones, tendrá que mejorar la función de recompensa. La función tiene que recompensar al agente cuanto este toma una curva que está permitida y penalizarlo si toma una curva no permitida. Después ya estará listo para comenzar otra ronda de entrenamiento. Para aprovechar el entrenamiento anterior, puede comenzar el nuevo entrenamiento clonando el modelo entrenado anteriormente y, de esta forma, transmitir los conocimientos aprendidos con anterioridad. Puede seguir este patrón para añadir gradualmente más características a la función de recompensa con el fin de entrenar a su vehículo de AWS DeepRacer para que conduzca en entornos cada vez más complejos.
Para obtener más funciones de recompensa avanzadas, consulte los siguientes ejemplos:
Exploración del espacio de acción para entrenar un modelo sólido
Por regla general, entrene el modelo para que sea lo más sólido posible para que pueda aplicarlo a tantos entornos como pueda. Por modelo sólido se entiende un modelo que se puede aplicar a una amplia gama de formas y condiciones de pista. En términos generales, un modelo sólido no es "inteligente" porque su función de recompensa no tiene la capacidad para contener conocimientos explícitos sobre el entorno. De lo contrario, el modelo probablemente solo se pueda aplicar a un entorno similar al del entrenamiento.
incorporar explícitamente información específica del entorno a la función de recompensa equivale a ingeniería de funciones. La ingeniería de funciones ayuda a reducir el tiempo de entrenamiento y puede resultar útil en soluciones que se crean específicamente para un entorno determinado. Sin embargo, para entrenar un modelo que se pueda aplicar en general, debe abstenerse de intentar introducir una gran cantidad de ingeniería de funciones.
Por ejemplo, cuando entrene un modelo en una pista circular, no puede esperar obtener un modelo entrenado que se pueda aplicar a cualquier pista que no sea circular si tiene tales propiedades geométricas incorporadas explícitamente en la función de recompensa.
¿Qué puede hacer para entrenar un modelo que sea lo más sólido posible y que al mismo tiempo tenga una función de recompensa que sea también lo más sencilla posible? Una solución es explorar el espacio de acción que abarca las acciones que puede ejecutar su agente. Otra solución consiste en experimentar con hiperparámetros del algoritmo de entrenamiento subyacente. A menudo, usará ambas soluciones. Aquí, nos concentramos en cómo explorar el espacio de acción para entrenar un modelo sólido de su vehículo de AWS DeepRacer.
Al entrenar un modelo de AWS DeepRacer, una acción (a) es una combinación de velocidad (t metros por segundo) y ángulo de dirección (s en grados). El espacio de acción del agente define los intervalos de velocidad y el ángulo de dirección el agente puede tomar. Para un espacio de acción discreto con un número m de velocidades (v1, .., vn) y un número n de ángulos de dirección (s1, ..,
sm), existen m*n posibles acciones en el espacio de acción:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
Los valores reales de (vi,
sj) dependen de los intervalos de vmax y |smax|, y no se distribuyen de manera uniforme.
Cada vez que empiece a entrenar o iterar su modelo de AWS DeepRacer, comience primero por especificar n, m, vmax y |smax| o acepte para usar sus valores predeterminados. En función de su elección, el servicio de AWS DeepRacer genera las acciones disponibles que su agente puede elegir durante el entrenamiento. Las acciones generadas no se distribuyen de manera uniforme por el espacio de acción.
En general, cuanto mayor sea el número de acciones y los intervalos de acción, su agente tendrá más espacio u opciones para reaccionar a más condiciones de pista diferentes, como una pista con curvas y ángulos de giro o direcciones irregulares. Cuantas más acciones tenga el agente a su disposición, más fácilmente podrá gestionar las variaciones de pista. Como resultado, puede esperar que el modelo entrenado se aplique de forma más amplia, incluso cuando se utiliza una sencilla función de recompensa.
Por ejemplo, su agente puede aprender rápidamente a circular por pistas rectas mediante un espacio de acción general con un número pequeño de velocidades y ángulos de dirección. En una pista con curvas, este espacio de acción general probablemente hará que el agente se exceda y se salga de la pista al girar. Esto se debe a que no hay suficientes opciones a su disposición para ajustar su velocidad o dirección. Aumente el número de velocidades o el número de ángulos de dirección o ambos. El agente debe ser más capaz de maniobrar en las curvas y mantenerse en la pista. Del mismo modo, si su agente se desplaza en zigzag, puede intentar aumentar el número de intervalos de dirección para reducir los giros drásticos en cualquier paso determinado.
Cuando el espacio de acción es demasiado grande, el rendimiento del entrenamiento puede verse afectado, ya que tarda más tiempo en explorar el espacio de acción. Asegúrese de equilibrar los beneficios de la capacidad de aplicación general de un modelo con los requisitos de rendimiento del entrenamiento. Esta optimización requiere una experimentación sistemática.
Ajuste sistemático de hiperparámetros
Una forma de mejorar el rendimiento de su modelo es poner en práctica un proceso de entrenamiento mejor o más efectivo. Por ejemplo, para obtener un modelo sólido, el entrenamiento tiene que proporcionar a su agente un muestreo distribuido de forma más o menos uniforme en el espacio de acción del agente. Para ello se necesita una combinación de exploración y explotación adecuada. Entre las variables que afectan a esta combinación figuran la cantidad de datos de entrenamiento usados (number of episodes between each
training y batch size), la rapidez de aprendizaje del agente (learning rate), la parte de exploración (entropy). Para que el entrenamiento sea práctico, puede interesarle acelerar el proceso de aprendizaje. Las variables que afectan a este proceso son learning rate, batch size, number of
epochs y discount factor.
Las variables que afectan al proceso de entrenamiento se conocen como hiperparámetros de entrenamiento. Estos atributos de algoritmo no son propiedades del modelo subyacente. Desgraciadamente, los hiperparámetros son empíricos. Sus valores óptimos no se conocen para todos los efectos prácticos y requieren una experimentación sistemática para realizar deducciones.
Antes de analizar los hiperparámetros que se pueden ajustar para precisar el rendimiento del entrenamiento de su modelo de AWS DeepRacer, vamos a definir la siguiente terminología.
- Punto de datos
-
Un punto de datos, también conocido como una experiencia, es una tupla de (s, a, r, s'), donde s significa una observación o estado capturado por la cámara, a se utiliza para una acción realizada por el vehículo, r se refiere a la recompensa esperada a la que lleva dicha acción y s' se utiliza para la nueva observación después de la acción.
- Episodio
-
Un episodio es un período en el que el vehículo comienza desde un determinado punto de partida y acaba completando la pista o saliéndose de ella. Contiene una secuencia de experiencias. La longitud puede variar en función del episodio.
- Búfer de experiencia
-
Un búfer de experiencia consiste en una serie de puntos de datos ordenados recopilados durante un número fijo de episodios de diferentes longitudes durante el entrenamiento. Para AWS DeepRacer, corresponde a las imágenes captadas por la cámara montada en el vehículo de AWS DeepRacer y las acciones realizadas por el vehículo y sirve como origen del que se extrae información para actualizar las redes neuronales subyacentes (política y valor).
- Por lotes
-
Un lote es una lista ordenada de experiencias que representa una parte de la simulación a lo largo de un periodo de tiempo y que se utiliza para actualizar las ponderaciones de red de la política. Se trata de un subconjunto del búfer de experiencia.
- Datos de entrenamiento
-
Los datos de entrenamiento son un conjunto de lotes muestreados al azar de un búfer de experiencia y utilizados para el entrenamiento de ponderaciones de red de política.
| Hiperparámetros | Descripción |
|---|---|
|
Tamaño del lote de descenso de gradientes |
El número de experiencias del vehículo recientes muestreadas al azar de un búfer de experiencia que se utiliza para actualizar las ponderaciones de red neuronal de aprendizaje profundo subyacentes. El muestreo aleatorio ayuda a reducir las correlaciones inherentes a los datos de entrada. Utilice un tamaño de lote más grande para fomentar actualizaciones más estables y sin obstáculos de las ponderaciones de red neuronal; no obstante, tenga en cuenta que es posible que el entrenamiento se alargue o se ralentice.
|
|
Número de fechas de inicio |
El número de pases a través de los datos de entrenamiento necesarios para actualizar las ponderaciones de redes neuronales durante el descenso de gradientes. Los datos de entrenamiento corresponden a muestras aleatorias del búfer de experiencia. Utilice un mayor número de fechas de inicio si desea fomentar actualizaciones más estables, pero tenga en cuenta que el entrenamiento será más lento. Cuando el tamaño del lote es pequeño, puede utilizar un menor número de fechas de inicio
|
|
Tasa de aprendizaje |
En cada actualización, una parte de la nueva ponderación puede provenir del descenso (o ascenso) de gradientes, mientras que el resto puede provenir del valor de ponderación existente. La tasa de aprendizaje controla el grado de contribución de la actualización del descenso (o ascenso) de gradientes a las ponderaciones de red. Utilice un mayor índice de aprendizaje si desea incluir más contribuciones de descenso de gradientes para un entrenamiento más rápido, aunque debe tener en cuenta la posibilidad de que la recompensa esperada no se consiga si el índice de aprendizaje es demasiado elevado.
|
Entropy |
Grado de incertidumbre que se utiliza para determinar cuándo se debe agregar aleatoriedad a la distribución de política. La incertidumbre añadida ayuda al vehículo de AWS DeepRacer a explorar con mayor amplitud el espacio de acción. Un valor de entropía más alto hará que el vehículo explore el espacio de acción con más detalle.
|
| Discount factor (Factor de descuento) |
Un factor sirve para especificar en qué grado contribuyen las recompensas futuras a la recompensa esperada. Cuanto más elevado sea el valor del factor de descuento, más contribuciones valorará el vehículo para hacer un movimiento y más lento será el entrenamiento. Si el factor de descuento es de 0,9, el vehículo tendrá en cuenta las recompensas de alrededor de 10 pasos futuros para hacer un movimiento. Si el factor de descuento es de 0,999, el vehículo considerará descuentos de alrededor de 1000 pasos futuros para hacer un movimiento. Los valores recomendados para el factor de descuento son 0,99, 0,999 y 0,9999.
|
| Loss type (Tipo de pérdida) |
Tipo de la función objetivo utilizada para utilizar las ponderaciones de red. Un buen algoritmo de entrenamiento debería hacer cambios incrementales en la estrategia del agente para que pase gradualmente de realizar acciones aleatorias a realizar acciones estratégicas para mejorar la recompensa. Pero si hace un cambio demasiado grande, entonces el entrenamiento se vuelve inestable y el agente termina por no aprender. Los tipos Huber loss (Pérdida de Huber)
|
| Number of experience episodes between each policy-updating iteration (Número de episodios de experiencia entre cada iteración de actualización de política) | Tamaño del búfer de experiencia del que se extraen los datos de entrenamiento para las ponderaciones de red de la política de aprendizaje. Un episodio de experiencia es un período en el que el agente comienza desde un punto de partida determinado y termina completando la pista o saliéndose de la pista. Se compone de una secuencia de experiencias. La longitud puede variar en función del episodio. Para problemas de aprendizaje por refuerzo sencillos, puede bastar con un pequeño búfer de experiencia y el aprendizaje es rápido. Si los problemas son más complejos y tienen más máximos locales, se necesitará un búfer de experiencia más grande para proporcionar más puntos de datos sin correlacionar. En este caso, el entrenamiento es más lento pero más estable. Los valores recomendados son 10, 20 y 40.
|
Examen de progreso del trabajo de entrenamiento de AWS DeepRacer
Después de iniciar el trabajo de entrenamiento, puede examinar las métricas de entrenamiento de recompensas y lo que se ha completado la pista por episodio para determinar el rendimiento del trabajo de entrenamiento del modelo. En la consola de AWS DeepRacer, las métricas se muestran en el Gráfico de recompensas, tal y como se muestra en la siguiente ilustración.
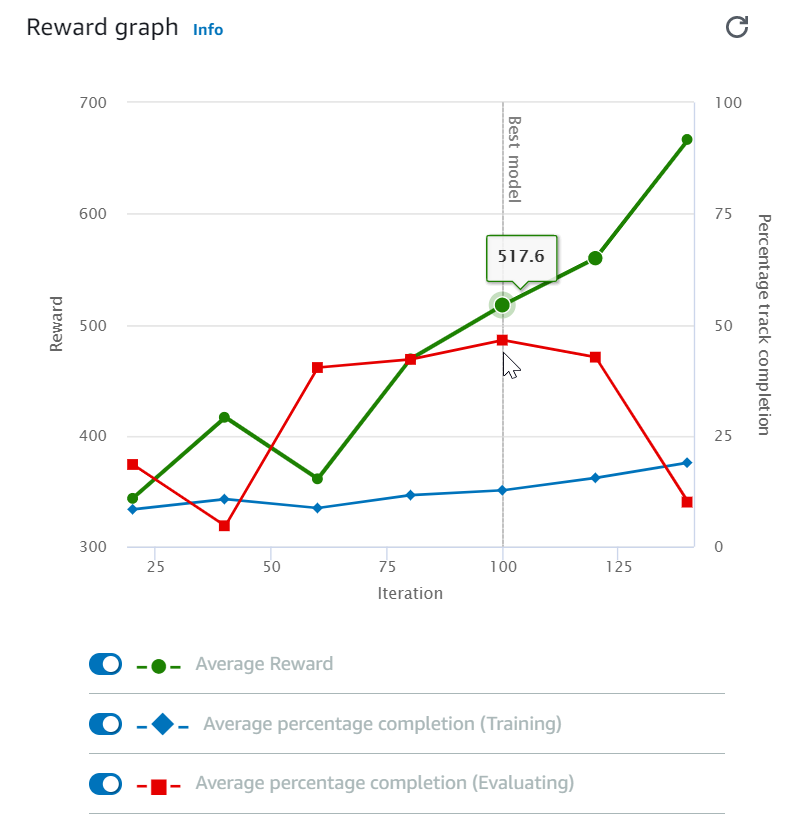
Puede optar por ver la recompensa ganada por episodio, la recompensa media por iteración, el progreso por episodio, el progreso medio por iteración o cualquier combinación de ellos. Para ello, cambie los conmutadores Reward (Episode, Average) [Recompensa (Episodio, media)] o Progress (Episode, Average) [Progreso (Episodio, media)] en la parte inferior del Reward graph (Gráfico de recompensa). La recompensa y el progreso por episodio se muestran como gráficos de dispersión en colores diferentes. La recompensa media y la finalización de pista se muestran mediante gráficos de líneas y comienzan después de la primera iteración.
El rango de recompensas se muestra en el lado izquierdo del gráfico y el rango de progreso (0-100) está en el lado derecho. Para leer el valor exacto de una métrica de entrenamiento, mueva el ratón cerca del punto de datos en el gráfico.
Los gráficos se actualizan automáticamente cada 10 segundos mientras el entrenamiento está en curso. Puede elegir el botón de actualización para actualizar manualmente la visualización de métricas.
Un trabajo de entrenamiento es bueno si la recompensa media y la finalización de pista muestran tendencias que convergen. En concreto, es probable que el modelo haya convergido si el progreso por episodio alcanza continuamente el 100 % y las recompensas se estabilizan De lo contrario, clone el modelo y vuelva a entrenarlo.
Clonación de un modelo entrenado para comenzar un nuevo paso de entrenamiento
Si clona un modelo entrenado previamente para que sea el punto de partida de una nueva ronda de entrenamiento, puede mejorar la eficacia del entrenamiento. Para ello, modifique los hiperparámetros para utilizar el conocimiento ya aprendido.
En esta sección, aprenderá a clonar un modelo entrenado usando la consola de AWS DeepRacer.
Para iterar el entrenamiento del modelo de aprendizaje por refuerzo mediante la consola de AWS DeepRacer
-
Inicie sesión en la consola de AWS DeepRacer si aún no lo ha hecho.
-
En la página Models (Modelos), elija un modelo entrenado y, a continuación, elija Clone (Clonar) en la lista de menú desplegable Action (Acción).
-
En Model details (Detalles de modelo), haga lo siguiente:
-
Escriba
RL_model_1en Model name (Nombre de modelo), si no desea que se genere un nombre para el modelo clonado. -
Si lo desea, puede incluir una descripción para el modelo que se va a clonar en Model description - optional (Descripción de modelo: opcional).
-
-
En Simulación de entorno, elija otra opción de pista.
-
En Función de recompensa, elija uno de los ejemplos de recompensa disponibles. Modifique la función de recompensa. Por ejemplo, considere la dirección.
-
Expanda la configuración del algoritmo y pruebe otras opciones. Por ejemplo, cambie el valor del tamaño de lote del descenso de gradiente de 32 a 64 o aumente el Learning rate (Tasa de aprendizaje) para acelerar el entrenamiento.
-
Experimente con distintas opciones de las Stop conditions (Condiciones de detención).
-
Elija Start training (Comenzar entrenamiento) para empezar una nueva ronda de entrenamiento.
Al igual que con el entrenamiento de un modelo de aprendizaje automático sólido en general, es importante que lleve a cabo una experimentación sistemática para obtener la mejor solución.
Evaluación de modelos de AWS DeepRacer en simulaciones
Evaluar un modelo consiste en probar el rendimiento de un modelo entrenado. En AWS DeepRacer, la métrica de rendimiento estándar es el tiempo medio que se tarda en acabar tres vueltas consecutivas. Con esta métrica, de los dos modelos, uno es mejor que el otro si puede hacer que el agente vaya más rápido en la misma pista.
En general, la evaluación de un modelo incluye las siguientes tareas:
-
Configurar y comenzar un trabajo de evaluación.
-
Observar la evaluación en curso mientras se está ejecutando el trabajo. Esto puede hacerse en el simulador de AWS DeepRacer.
-
Inspeccionar el resumen de la evaluación después de haber realizado el trabajo de evaluación. Puede terminar un trabajo de evaluación en curso en cualquier momento.
nota
El tiempo de evaluación depende de los criterios que seleccione. Si su modelo no satisface los criterios de evaluación, la evaluación se seguirá ejecutando hasta que alcance el tope de 20 minutos.
-
También tiene la opción de enviar el resultado de la evaluación a una tabla de clasificación de AWS DeepRacer elegible. La clasificación de la tabla de clasificación le permite informarse del rendimiento de su modelo en comparación con otros participantes.
Pruebe un modelo de AWS DeepRacer con un vehículo de AWS DeepRacer que circule por una pista física. Consulte Opere su vehículo AWS DeepRacer .
Optimización del entrenamiento de modelos de AWS DeepRacer para entornos reales
Muchos factores influyen en el rendimiento real de un modelo entrenado, como la elección del espacio de acción, la función de recompensa, los hiperparámetros utilizados en el entrenamiento y la calibración del vehículo así como las condiciones de la pista en tiempo real. Además, la simulación es solo una aproximación (a menudo general) del mundo real. Todo esto hace que sea un verdadero desafío entrenar un modelo en simulación, aplicarlo en el mundo real y conseguir un buen rendimiento.
Entrenar un modelo para que tenga un rendimiento sólido en el mundo real a menudo requiere numerosas iteraciones de exploración de la función de recompensa, los espacios de acción, los hiperparámetros y la evaluación en simulación, y luego realizar pruebas en un entorno real. En el último paso tiene lugar la denominada transferencia de simulación a mundo real (sim2real) y puede ser difícil.
Para abordar los desafíos que plantea el sim2real, tenga en cuenta las siguientes consideraciones:
-
Asegúrese de que el vehículo esté bien calibrado.
Esto es importante porque es muy probable que el entorno simulado sea solo una representación parcial del entorno real. Además, en cada paso, el agente ejecuta una acción en la condición actual de la pista, tal como se ha tomado en una imagen de la cámara. No puede ver con suficiente perspectiva para planificar su ruta a alta velocidad. Para dar cabida a estos factores, la simulación impone límites a la velocidad y la dirección. Para garantizar que el modelo entrenado funcione en el mundo real, el vehículo tiene que calibrarse correctamente para adaptarse a estas condiciones y otros ajustes de simulación. Para obtener más información para calibrar su vehículo, consulte Calibración de su vehículo de AWS DeepRacer.
-
Pruebe su vehículo primero con el modelo predeterminado.
El vehículo de AWS DeepRacer viene con un modelo entrenado previamente cargado en su motor de inferencia. Antes de probar su propio modelo en el mundo real, compruebe que el vehículo funcione razonablemente bien con el modelo predeterminado. Si no es así, compruebe la configuración de la pista física. Probar un modelo en una pista física creada incorrectamente probablemente dé lugar a un mal rendimiento. En estos casos, vuelva a configurar o repare la pista antes de comenzar o reanudar las pruebas.
nota
Al ejecutar su vehículo de AWS DeepRacer, las acciones se deducen en función de la red de políticas entrenada, sin invocar la función de recompensa.
-
Asegúrese de que el modelo funcione en simulación.
Si el modelo no funciona bien en el mundo real, es posible que el modelo o la pista sea defectuoso. Para averiguar la causa inicial, en primer lugar debe evaluar el modelo en simulaciones para comprobar si el agente simulado puede finalizar al menos una vuelta sin salirse de la pista. Puede hacerlo inspeccionando la convergencia de las recompensas al mismo tiempo que observa la trayectoria del agente en el simulador. Si la recompensa llega al máximo cuando el agente simulado completa una vuelta sin errores, probablemente el modelo es bueno.
-
No entrene en exceso el modelo.
Si sigue entrenando el modelo después de que este haya completado la pista de simulación correctamente causará un ajuste excesivo del modelo. Un modelo entrenado en exceso no funcionará bien en el mundo real, ya que no puede gestionar incluso pequeñas variaciones entre la pista simulada y el entorno real.
-
Utilice varios modelos de diferentes iteraciones.
Normalmente, en una sesión de entrenamiento típica se generan varios modelos que van desde modelos insuficientemente ajustados a modelos ajustados en exceso. Como no existen criterios a priori para determinar un modelo que sea adecuado, debe elegir varios modelos candidatos entre el momento en que el agente completa una única vuelta en el simulador y el momento en que realiza las vueltas de forma correcta.
-
Comience lentamente y luego vaya aumentando gradualmente la velocidad de conducción en las pruebas.
Al probar el modelo implementado en su vehículo, comience con un valor de velocidad máxima que sea pequeño. Por ejemplo, puede establecer el límite de velocidad de la prueba en <10 % del límite de velocidad de entrenamiento. Luego incremente gradualmente el límite de velocidad de prueba hasta que el vehículo comience a moverse. Puede establecer el límite de velocidad de prueba al calibrar el vehículo mediante la consola de control del dispositivo. Si el vehículo va demasiado rápido, por ejemplo, la si velocidad supera aquellas observadas durante el entrenamiento en simulador, es probable que el modelo no tenga un buen rendimiento en la pista real.
-
Pruebe un modelo con su vehículo en diferentes posiciones de partida.
El modelo aprende a tomar una ruta determinada en la simulación y puede ser sensible a su posición en la pista. Debe comenzar las pruebas del vehículo con diferentes posiciones en la pista (de la izquierda al centro y luego a la derecha) para ver si el modelo tiene un buen rendimiento desde determinadas posiciones. La mayoría de los modelos tienden a dejar el vehículo cerca de uno de los laterales de las líneas blancas. Para ayudar a analizar la ruta del vehículo, trace las posiciones del vehículo (x, y) paso a paso desde la simulación para identificar las rutas que probablemente tomará el vehículo en un entorno real.
-
Comience las pruebas con una pista recta.
Una pista recta es mucho más fácil de recorrer que una pista con curvas. Comenzar la prueba con una pisa recta es útil para descartar modelos deficientes rápidamente. Si el vehículo no puede seguir una pista recta la mayor parte del tiempo, tampoco tendrá un buen rendimiento en las pistas con curvas.
-
Observe si el comportamiento del vehículo permite un solo tipo de acción.
Si su vehículo solo puede ejecutar un tipo de acción como, por ejemplo, dirigir el vehículo únicamente hacia la izquierda, es probable que el modelo sobremodele o inframodele los datos. Con determinados parámetros de modelo, demasiadas iteraciones en el entrenamiento pueden hacer que el modelo esté excesivamente ajustado. También puede darse el caso de que si las iteraciones son escasas, el modelo esté insuficientemente ajustado.
-
Observe si vehículo tiene capacidad para corregir su ruta a lo largo del límite de una pista.
Un buen modelo hará que el vehículo se corrija a sí mismo cuando se acerque a los límites de la pista. La mayoría de los modelos bien entrenados tienen esta capacidad. Si el vehículo se puede corregir a sí mismo en ambos límites de la pista, se considerará que el modelo es más sólido y de mayor calidad.
-
Observe si el vehículo tiene un comportamiento incoherente.
Un modelo de política representa una distribución de probabilidad para ejecutar una acción en un determinado estado. Con el modelo entrenado cargado en el motor de inferencia, un vehículo elegirá la acción más probable, paso a paso, de acuerdo con lo que indica el modelo. Si las probabilidades de acción están distribuidas de forma uniforme, el vehículo puede ejecutar cualquiera de las acciones de probabilidades que sean iguales o muy parecidas. Esto dará lugar a un comportamiento de conducción errático. Por ejemplo, cuando el vehículo a veces sigue una trayectoria recta (por decir, la mitad del tiempo) y realiza giros innecesarios en otras ocasiones, el modelo sobremodela o inframodela los datos..
-
Preste atención a un solo tipo de giro (a la izquierda o a la derecha) realizado por el vehículo.
Si el vehículo gira muy bien a la izquierda, pero le falla la dirección a la derecha, o viceversa, si el vehículo solo gira bien hacia la derecha, pero no hacia la izquierda, tendrá que calibrar o volver a calibrar cuidadosamente la dirección del vehículo. De forma alternativa, puede intentar utilizar un modelo que se entrena con una configuración muy parecida a la configuración física que se está probando.
-
Preste atención a si el vehículo realiza giros repentinos y se sale de la trayectoria.
Si el vehículo sigue la ruta correctamente la mayor parte del tiempo, pero de repente se desvía fuera de la pista, es probable que se deba a distracciones en el entorno. Las distracciones más frecuentes suelen ser reflejos de luz inesperados o no deseados. En tales casos, utilice barreras en torno a la pista u otros medios para reducir las luces brillantes.
