Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Entrene su primer modelo de AWS DeepRacer
En este tutorial se muestra cómo entrenar su primer modelo con la consola AWS DeepRacer.
Entrenar un modelo de aprendizaje de refuerzo mediante la consola de AWS DeepRacer
Descubra dónde encontrar el botón Crear modelo en la consola AWS DeepRacer para comenzar su viaje de formación de modelos.
Entrene un modelo de aprendizaje por refuerzo
-
Si es la primera vez que utiliza AWS DeepRacer, elija Crear modelo en la página de inicio del servicio o seleccione Comenzar en el encabezado Aprendizaje por refuerzo del panel de navegación principal.
-
En la página Introducción al aprendizaje de refuerzo en Paso 2: Crear un modelo, elija Crear modelo.
Como alternativa, elija Sus modelos en el encabezado Aprendizaje por refuerzo del panel de navegación principal. En la página Your models (Sus modelos), elija Create model (Crear modelo).
Especifique el nombre y el entorno del modelo
Asigne un nombre a su modelo y aprenda a elegir la pista de simulación adecuada para usted.
Especifique el nombre y el entorno del modelo
-
En la página Crear modelo, en Detalles de entrenamiento escriba un nombre para el modelo.
-
También puede optar por agregar una descripción de trabajo.
-
Para obtener más información acerca de las etiquetas adicionales, consulte Etiquetado.
-
En Simulación de entorno, elija una pista que sirva de entorno de formación para su agente de AWS DeepRacer. En Dirección de seguimiento, elija Sentido horario o Antihorario. A continuación, haga clic en Next.
Para su primera carrera, elija una pista con una forma sencilla y curvas suaves. En iteraciones posteriores, puede elegir pistas más complejas para mejorar progresivamente sus modelos. Para entrenar un modelo para un determinado evento de carreras, elija la pista más parecida a la pista del evento.
-
En la parte inferior de la página, elija Siguiente.
Elige un tipo de carrera y un algoritmo de entrenamiento
La consola AWS DeepRacer tiene tres tipos de carreras y dos algoritmos de entrenamiento entre los que elegir. Descubra cuáles son adecuados para su nivel de habilidad y sus objetivos de entrenamiento.
Para elegir un tipo de carrera y un algoritmo de entrenamiento
-
En la página Crear modelo, en Tipo de carrera, seleccione Contrarreloj, Evasión de objetos o Cara a cara con robot.
Para la primera vez que juegue, le recomendamos que elija Contrarreloj. Para obtener información sobre cómo optimizar la configuración de los sensores de su agente para este tipo de carrera, consulte Adaptación del entrenamiento de AWS DeepRacer para pruebas contrarreloj.
-
De forma opcional, para carreras posteriores, puede elegir Esquivar objetos para recorrer obstáculos inmóviles colocados en ubicaciones fijas o aleatorias a lo largo de la pista elegida. Para obtener más información, consulte Adaptación del entrenamiento de AWS DeepRacer para carreras de evasión de obstáculos.
-
Elija Ubicación fija para generar cajas en ubicaciones fijas designadas por el usuario en los dos carriles de la pista o seleccione Ubicación aleatoria para generar objetos que se distribuyan aleatoriamente en los dos carriles al principio de cada episodio de su simulación de entrenamiento.
-
A continuación, elija un valor para el número de objetos en una pista.
-
Si elige Ubicación fija, puede ajustar la ubicación de cada objeto en la pista. Para la ubicación del carril, elija entre el carril interior y el carril exterior. De forma predeterminada, los objetos se distribuyen uniformemente por la vía. Para cambiar la distancia entre la línea de inicio y la meta de un objeto, introduzca un porcentaje de esa distancia entre siete y 90 en el campo Ubicación (%) entre la salida y la meta.
-
-
Para carreras más ambiciosas, elija Carrera competitiva para competir contra un máximo de vehículos robot que se mueven a una velocidad constante. Para obtener más información, consulte Adaptación del entrenamiento de AWS DeepRacer para carreras de ganador único.
-
En Eligir el número de vehículos robot, seleccione el número de vehículos robot con el que quiere que entrene su agente.
-
A continuación, elija la velocidad en milímetros por segundo a la que quiere que los vehículos robot viajen por la pista.
-
Si lo prefiere, marque la casilla Activar cambios de carril para que los vehículos robot puedan cambiar de carril aleatoriamente cada 1 a 5 segundos.
-
-
En Algoritmo de entrenamiento e hiperparámetros, elija el algoritmo Soft Actor Critic (SAC) o Proximal Policy Optimization (PPO). En la consola AWS DeepRacer, los modelos SAC deben entrenarse en espacios de acción continua. Los modelos PPO se pueden entrenar en espacios de acción continuos o discretos.
-
En Algoritmo e hiperparámetros de entrenamiento, use los valores predeterminados de hiperparámetros tal como están.
Más adelante, para mejorar el rendimiento del entrenamiento, expanda Hyperparameters (Hiperparámetros) y modifique los valores predeterminados como se indica a continuación:
-
Para Gradient descent batch size (Tamaño de lote de descenso de gradientes), elija las opciones disponibles.
-
Para Number of epochs (Número de fechas de inicio), establezca un valor válido.
-
Para Learning rate (Ritmo de aprendizaje), establezca un valor válido.
-
Para el valor alfa del SAC (solo para el algoritmo SAC), establezca un valor válido.
-
Para Entropy (Entropía), establezca un valor válido.
-
Para Discount factor (Factor de descuento), establezca un valor válido.
-
Para Loss type (Tipo de pérdida), elija las opciones disponibles.
-
Para Number of experience episodes between each policy-updating iteration (Número de episodios de experiencia entre cada iteración de actualización de política), establezca un valor válido.
Para obtener más información acerca de los hiperparámetros, consulte Ajuste sistemático de hiperparámetros.
-
-
Elija Siguiente.
Defina el espacio de acción
En la página Definir un espacio de acción, si ha elegido entrenar con el algoritmo Soft Actor Critic (SAC), su espacio de acción predeterminado es el espacio de acción continua. Si ha elegido entrenar con el algoritmo Proximal Policy Optimization (PPO), elija entre un espacio de acción continuo o un espacio de acción discreto. Para obtener más información sobre cómo cada espacio de acción y algoritmo moldea la experiencia de entrenamiento del agente, consulte Espacio de acción y función de recompensa de AWS DeepRacer.
-
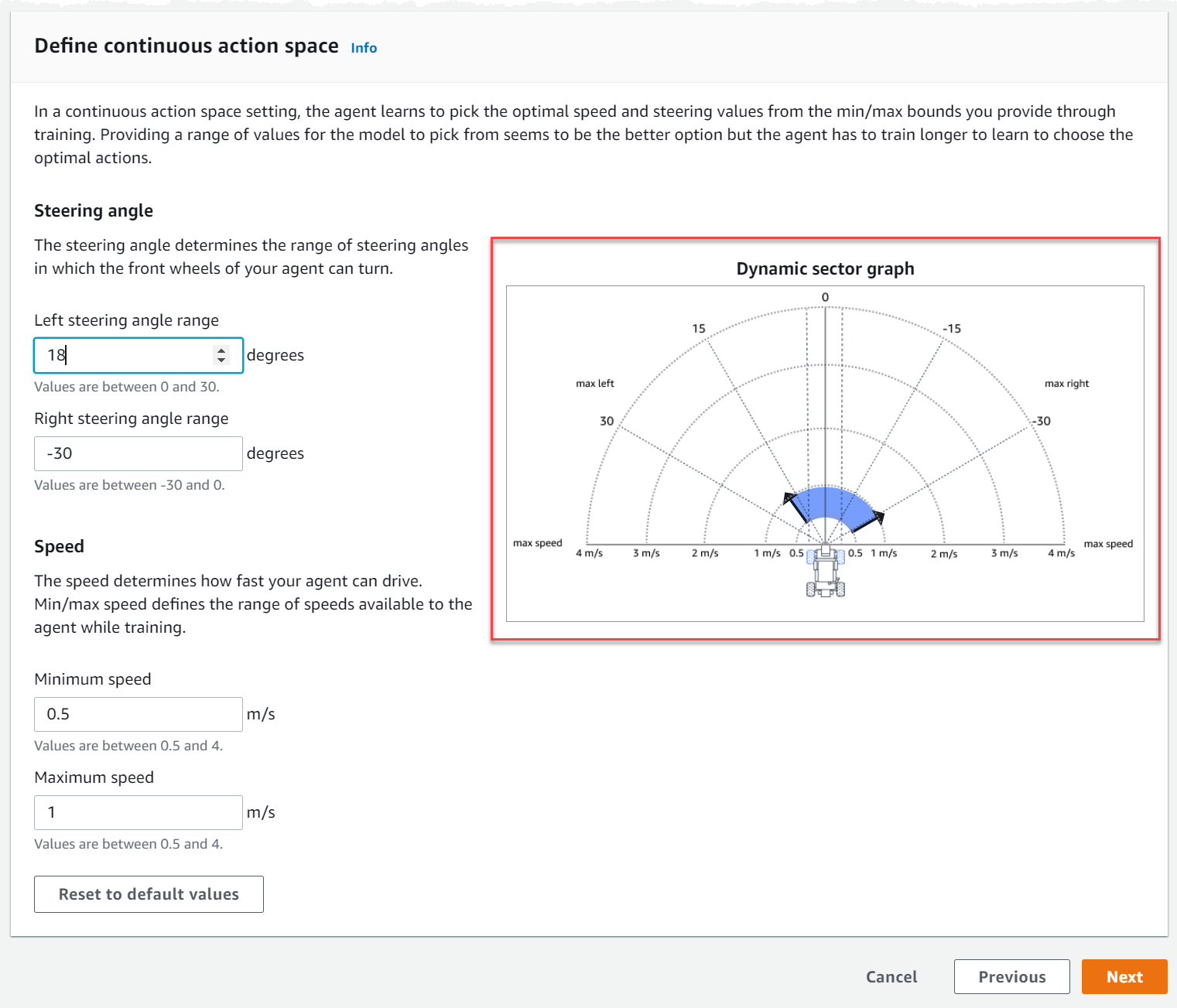
En Definir un espacio de acción continuo, seleccione los grados del rango del ángulo de giro izquierdo y el rango del ángulo de giro derecho.
Intente introducir diferentes grados para cada rango de ángulo de giro y observe cómo cambia la visualización del rango para representar sus elecciones en el gráfico del sector dinámico.
-
En Velocidad, introduzca una velocidad mínima y máxima para su agente en milímetros por segundo.
Observe cómo se reflejan sus cambios en el Gráfico del sector dinámico.
-
Si lo desea, elija Restablecer los valores predeterminados para borrar los valores no deseados. Le recomendamos que pruebe diferentes valores en la gráfica para experimentar y aprender.
-
Elija Siguiente.
-
Seleccione un Valor de granularidad del ángulo de dirección del menú desplegable.
-
Elija un valor en grados entre 1 y 30 grados para el ángulo de giro máximo de su agente.
-
Seleccione un Valor de granularidad de velocidad del menú desplegable.
-
Elija un valor en milímetros por segundo entre 0,1 y 4 para la Velocidad máxima de su agente.
-
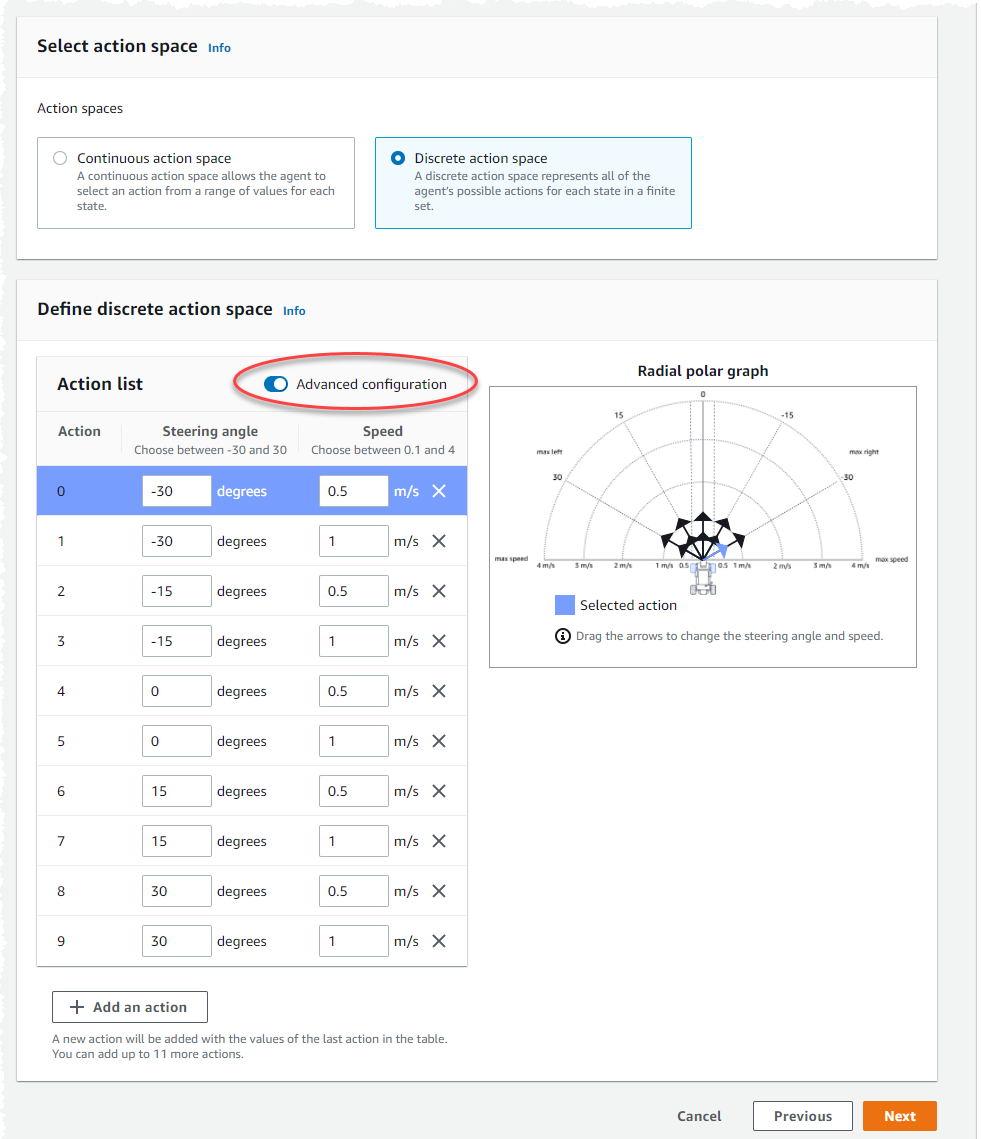
Utilice los ajustes de acción predeterminados de la Lista de acciones o, si lo desea, active la Configuración avanzada para ajustar los ajustes. Si selecciona Anterior o desactiva la Configuración avanzada después de ajustar los valores, perderá los cambios.
-
Introduzca un valor en grados entre -30 y 30 grados en la columna del Ángulo de dirección.
-
Introduzca un valor entre 0,1 y 4 milímetros por segundo para un máximo de nueve acciones en la columna Velocidad.
-
Si lo desea, seleccione Añadir una acción para aumentar el número de filas de la lista de acciones.
-
Si lo desea, seleccione una X en una fila para eliminarla.
-
-
Elija Siguiente.
Elige un vehículo virtual
Describe cómo comenzar a utilizar vehículos virtuales. Consiga nuevos coches personalizados, trabajos de pintura y modificaciones compitiendo en la Open Division cada mes.
Para elegir un coche virtual
-
En la página Elegir la configuración de la carrocería del vehículo y el sensor, elija una carrocería que sea compatible con su tipo de carrera y su espacio de acción. Si no tiene un coche que coincida en su garaje, vaya a Su garaje, en el apartado Aprendizaje por refuerzo del panel de navegación principal, para crear uno.
Para el entrenamiento Contrarreloj, lo único que necesita es la configuración de sensores y la cámara de lente única predeterminados de The Original DeePracer, pero todas las demás carrocerías y configuraciones de sensores funcionan siempre que el espacio de acción coincida. Para obtener más información, consulte Adaptación del entrenamiento de AWS DeepRacer para pruebas contrarreloj.
Para el entrenamiento para Esquivar objetos, las cámaras estéreo son útiles, pero también se puede usar una sola cámara para evitar obstáculos estacionarios en ubicaciones fijas. El sensor LiDAR es opcional. Consulte Espacio de acción y función de recompensa de AWS DeepRacer.
Para el entrenamiento Cara a cara con robot, además de una sola cámara o una cámara estéreo, una unidad LiDAR es óptima para detectar y evitar puntos ciegos al rebasar a otros vehículos en movimiento. Para obtener más información, consulte Adaptación del entrenamiento de AWS DeepRacer para carreras de ganador único.
-
Elija Siguiente.
Personalice su función de recompensa
La función de recompensa es una parte fundamental del aprendizaje por refuerzo. Aprenda a utilizarla para incentivar a su coche (agente) a realizar acciones específicas mientras explora la pista (entorno). Al igual que fomentar y desalentar ciertos comportamientos en una mascota, puede usar esta herramienta para animar a su vehículo a completar una vuelta lo más rápido posible y evitar que se salga de la pista o choque con objetos.
Personalizar su función de recompensa
-
En la página Create model (Crear modelo) en Reward function (Función de recompensa), utilice el ejemplo de función de recompensa predeterminado sin modificar para su primer modelo.
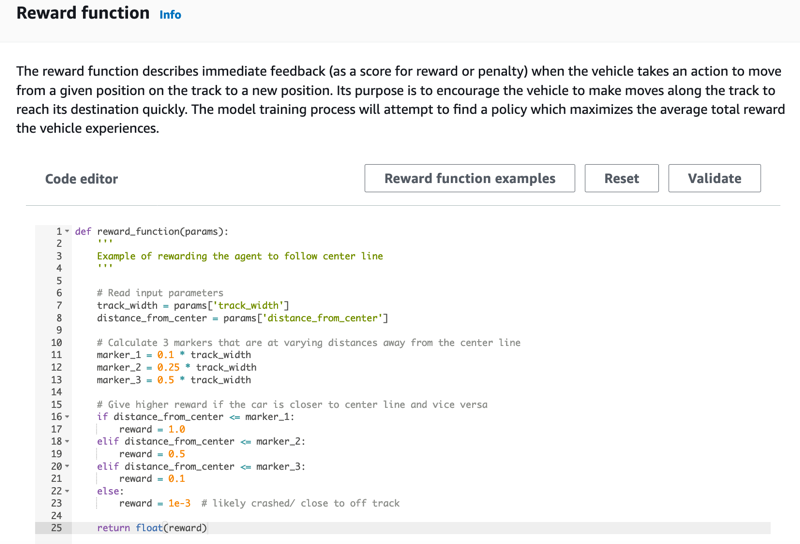
Más adelante, puede elegir ejemplos de funciones de recompensa para seleccionar otra función de ejemplo y, a continuación, seleccionar Usar código para aceptar la función de recompensa seleccionada.
Tiene a su disposición cuatro funciones de ejemplo con las que puede comenzar. Ilustran cómo seguir el centro de la pista (valor predeterminado), cómo mantener al agente dentro de los límites de la pista, cómo evitar la conducción en zigzag y cómo evitar choques con obstáculos inmóviles u otros vehículos en movimiento.
Para obtener más información sobre la función de recompensa, consulte Referencia de funciones de DeepRacer recompensas de AWS.
-
En Condiciones de parada, deje igual el valor predeterminado de Tiempo máximo o establezca un nuevo valor para terminar la tarea de entrenamiento, con el fin de ayudar a evitar tareas de entrenamiento de larga duración (y posibles fugas).
Al experimentar en la fase inicial de entrenamiento, debe comenzar con un pequeño valor para este parámetro y luego entrenar progresivamente durante mayores períodos de tiempo.
-
En la sección Enviar automáticamente a AWS DeepRacer, está marcada de forma predeterminada la opción Enviar este modelo a AWS DeepRacer automáticamente tras completar la formación y tener la oportunidad de ganar premios. Si lo desea, puede optar por no introducir su modelo seleccionando la marca de verificación.
-
En Requisitos de la liga, seleccione su País de residencia y acepte los términos y condiciones marcando la casilla.
-
Elija Crear modelo para empezar a crear el modelo y aprovisionar la instancia del trabajo de entrenamiento.
-
Cuando lo envíe, observe cómo se inicializa y ejecuta la tarea de entrenamiento.
El proceso de inicialización toma unos minutos en cambiar el estado de Inicialización a En curso.
-
Vea el Reward graph (Gráfico de recompensas) y el Simulation video stream (Flujo de vídeo de simulación) para observar el progreso del trabajo de entrenamiento. Puede elegir el botón de actualización junto al Reward graph (Gráfico de recompensas) periódicamente para actualizar el Reward graph (Gráfico de recompensas) hasta que se complete el trabajo de entrenamiento.
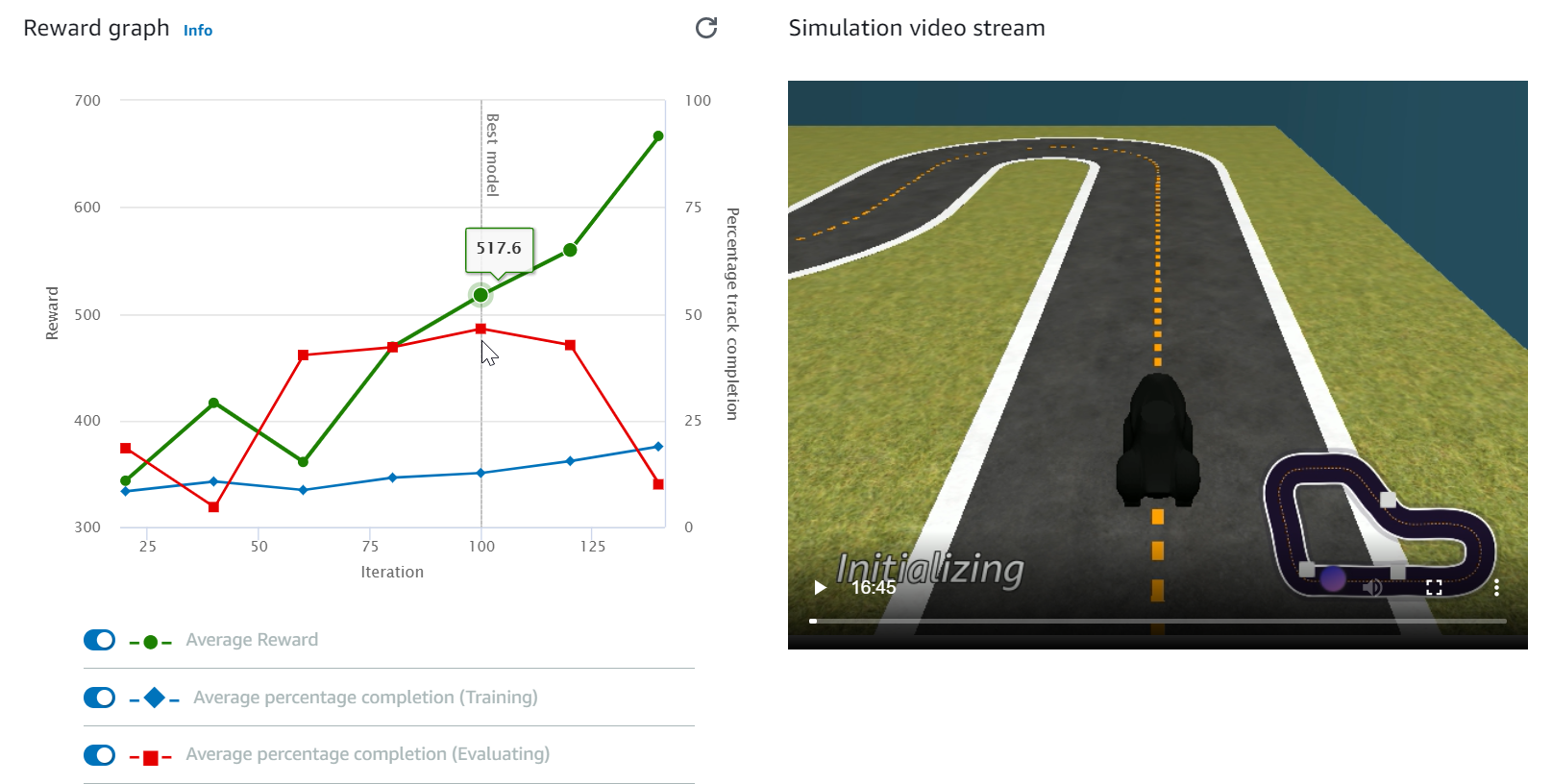
El trabajo de entrenamiento se está ejecutando en la nube de AWS, por lo que no es necesario mantener la consola de AWS DeepRacer. Siempre puede volver a la consola para comprobar el modelo en cualquier momento mientras el trabajo está en curso.
Si la ventana de Transmisión de vídeo de simulación o la pantalla del Gráfico de recompensas deja de responder, actualice la página del navegador para actualizar el progreso del entrenamiento.
