Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Dans un aperçu, vous pouvez visualiser les anomalies relatives aux ressources Amazon RDS. Sur une page d'analyse réactive, dans la section Mesures agrégées, vous pouvez consulter une liste des anomalies avec les chronologies correspondantes. Certaines sections affichent également des informations sur les groupes de journaux et les événements liés aux anomalies. Dans un aperçu réactif, les anomalies causales ont chacune une page correspondante contenant des détails sur l'anomalie.
Visualisation de l'analyse détaillée d'une anomalie réactive du RDS
À ce stade, analysez l'anomalie pour obtenir une analyse détaillée et des recommandations pour vos instances de base de données Amazon RDS.
L'analyse détaillée n'est disponible que pour les instances de base de données Amazon RDS sur lesquelles Performance Insights est activé.
Pour accéder à la page de détails des anomalies
-
Sur la page d'aperçu, recherchez une métrique agrégée avec le type de ressource AWS/RDS.
-
Sélectionnez Afficher les détails.
La page de détails de l'anomalie apparaît. Le titre commence par « Anomalie des performances de la base de données » et nomme la ressource « Afficher ». La console détecte par défaut l'anomalie la plus grave, quel que soit le moment où elle s'est produite.
-
(Facultatif) Si plusieurs ressources sont concernées, choisissez-en une autre dans la liste en haut de la page.
Vous trouverez ci-dessous les descriptions des composants de la page de détails.
Vue d'ensemble des ressources
La section supérieure de la page de détails est la vue d'ensemble des ressources. Cette section résume l'anomalie de performance rencontrée par votre instance de base de données Amazon RDS.
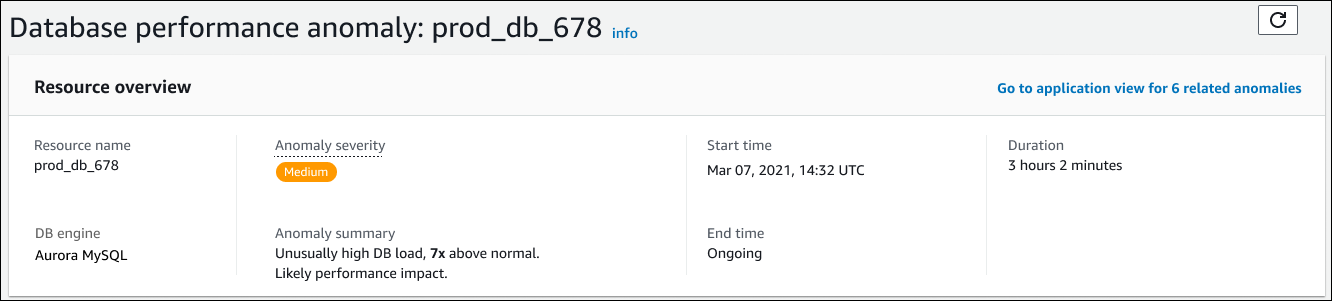
Cette section contient les champs suivants :
-
Nom de la ressource : nom de l'instance de base de données qui présente l'anomalie. Dans cet exemple, la ressource s'appelle prod_db_678.
-
Moteur de base de données : nom de l'instance de base de données présentant l'anomalie. Dans cet exemple, le moteur est Aurora MySQL.
-
Gravité de l'anomalie : mesure de l'impact négatif de l'anomalie sur votre instance. Les sévérités possibles sont élevées, moyennes et faibles.
-
Résumé de l'anomalie : bref résumé du problème. Un résumé typique est une charge de base de données anormalement élevée.
-
Heure de début et heure de fin : heure de début et de fin de l'anomalie. Si l'heure de fin est en cours, l'anomalie persiste.
-
Durée : durée du comportement anormal. Dans cet exemple, l'anomalie est permanente et se produit depuis 3 heures et 2 minutes.
Métrique principale
La section Métrique principale résume l'anomalie occasionnelle, qui est l'anomalie de premier niveau de l'aperçu. Vous pouvez considérer l'anomalie causale comme le problème général rencontré par votre instance de base de données.
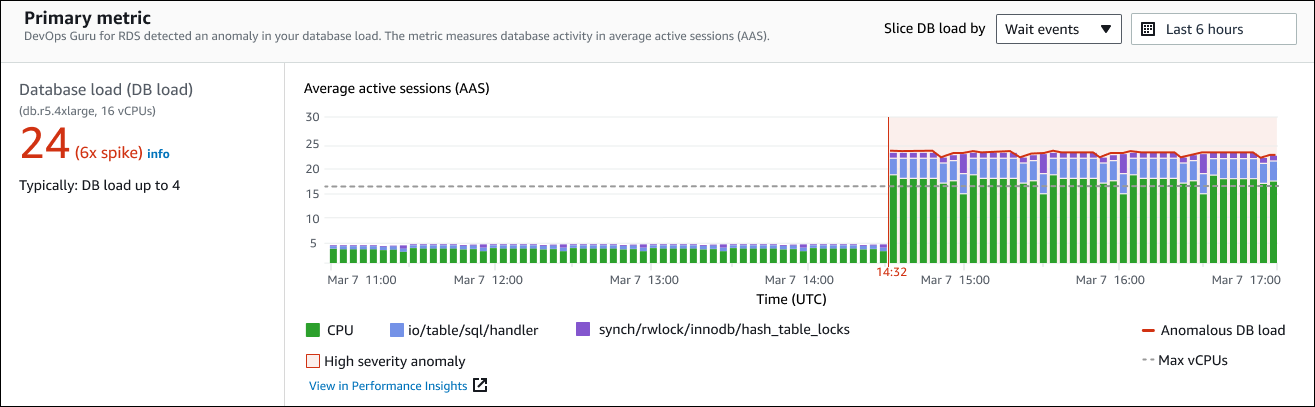
Le panneau de gauche fournit plus de détails sur le problème. Dans cet exemple, le résumé inclut les informations suivantes :
-
Charge de base de données (charge de base de données) : catégorisation de l'anomalie en tant que problème de chargement de base de données. La métrique correspondante dans Performance Insights est
DBLoad. Cette statistique est également publiée sur Amazon CloudWatch. -
db.r5.4xlarge — La classe d'instance de base de données. Le nombre de vCPUs, 16 dans cet exemple, correspond à la ligne pointillée du graphique Average active sessions (AAS).
-
24 (6x pic) — La charge de base de données, mesurée en nombre moyen de sessions actives (AAS) pendant l'intervalle de temps indiqué dans l'aperçu. Ainsi, à tout moment pendant la période de l'anomalie, 24 sessions en moyenne étaient actives sur la base de données. La charge de base de données est 6 fois supérieure à la charge de base de données normale pour cette instance.
-
Généralement : charge de base de données jusqu'à 4 : valeur de référence de la charge de base de données, mesurée en AAS, pendant une charge de travail typique. La valeur 4 signifie que, pendant les opérations normales, en moyenne 4 sessions ou moins sont actives sur la base de données à un moment donné.
Par défaut, le graphique de charge est découpé en fonction des événements d'attente. Cela signifie que pour chaque barre du graphique, la plus grande zone colorée représente l'événement d'attente qui contribue le plus à la charge totale de la base de données. Le graphique indique l'heure (en rouge) à laquelle le problème a commencé. Concentrez votre attention sur les événements d'attente qui occupent le plus d'espace dans la barre :
-
CPU -
IO:wait/io/sql/table/handler
Les événements d'attente précédents apparaissent plus que d'habitude pour cette base de données Aurora MySQL. Pour savoir comment optimiser les performances à l'aide d'événements d'attente dans Amazon Aurora, consultez les sections Tuning with wait events for Aurora MySQL et Tuning with wait events for Aurora PostgreSQL dans le guide de l'utilisateur Amazon Aurora. Pour savoir comment optimiser les performances à l'aide d'événements d'attente dans RDS pour PostgreSQL, consultez la section Optimisation avec des événements d'attente pour RDS pour PostgreSQL dans le guide de l'utilisateur Amazon RDS.
Métriques associées
La section Paramètres connexes répertorie les anomalies contextuelles, qui sont des constatations spécifiques au sein de l'anomalie causale. Ces résultats fournissent des informations supplémentaires sur les problèmes de performance.
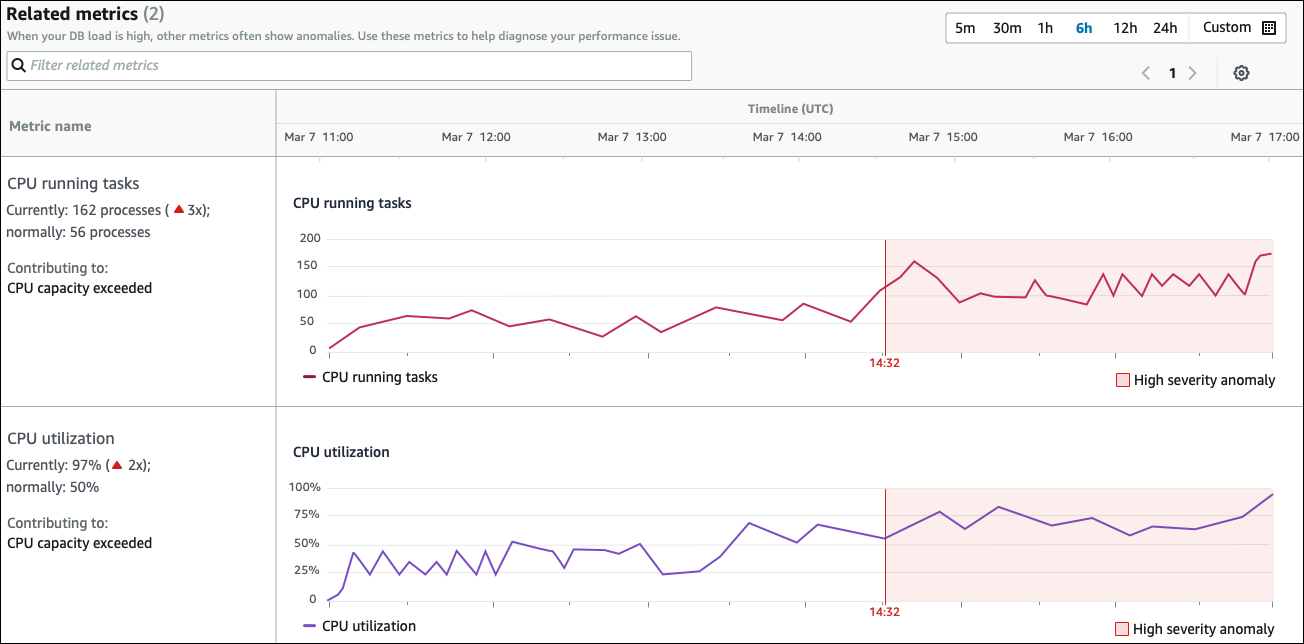
Le tableau des mesures associées comporte deux colonnes : nom des mesures et chronologie (UTC). Chaque ligne du tableau correspond à une métrique spécifique.
La première colonne de chaque ligne contient les informations suivantes :
-
Name— Le nom de la métrique. La première ligne identifie la métrique en tant que tâches exécutées par le processeur. -
Actuellement : valeur actuelle de la métrique. Dans la première ligne, la valeur actuelle est de 162 processus (3x).
-
Normalement : référence de cette métrique pour cette base de données lorsqu'elle fonctionne normalement. DevOpsGuru for RDS calcule la base de référence comme étant la valeur du 95e percentile sur une semaine d'historique. La première ligne indique que 56 processus sont généralement exécutés sur le processeur.
-
Contribution à — Le résultat associé à cette métrique. Dans la première ligne, la métrique des tâches exécutées par le processeur est associée à l'anomalie de dépassement de la capacité du processeur.
La colonne Chronologie affiche un graphique linéaire pour la métrique. La zone ombrée indique l'intervalle de temps pendant DevOps lequel Guru for RDS a qualifié le résultat de grave.
Analyse et recommandations
Alors que l'anomalie causale décrit le problème global, une anomalie contextuelle décrit une constatation spécifique qui nécessite une enquête. Chaque résultat correspond à un ensemble de mesures connexes.
Dans l'exemple suivant de section Analyse et recommandations, l'anomalie de charge de base de données élevée a deux résultats.
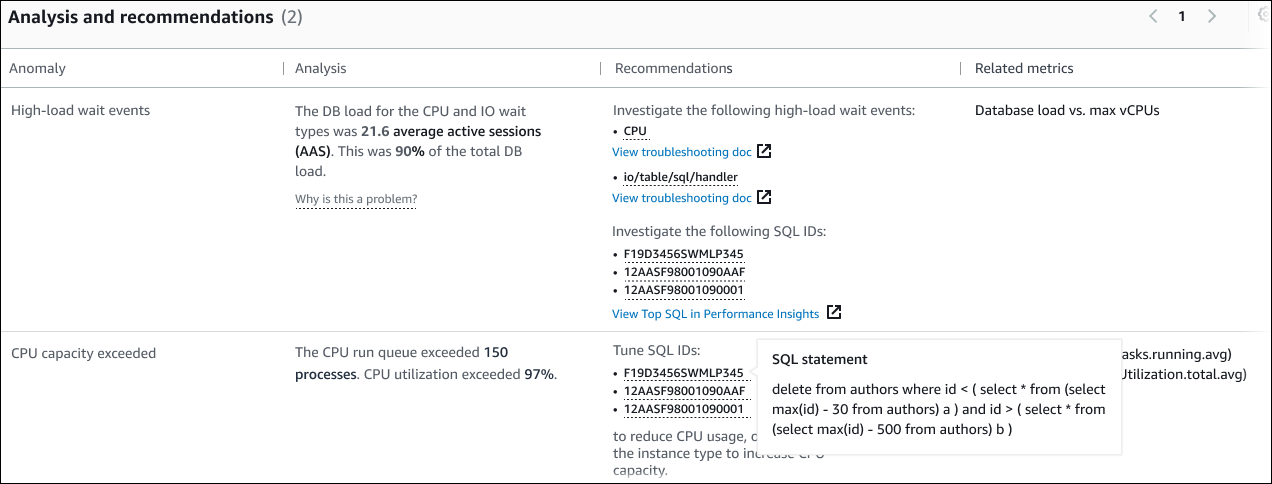
Cette table possède les colonnes suivantes :
-
Anomalie — Description générale de cette anomalie contextuelle. Dans cet exemple, la première anomalie concerne les événements d'attente liés à une charge élevée, et la seconde, le dépassement de la capacité du processeur.
-
Analyse — Explication détaillée de l'anomalie.
Dans la première anomalie, trois types d'attente contribuent à 90 % de la charge de base de données. Dans la deuxième anomalie, la file d'attente d'exécution du processeur dépassait 150, ce qui signifie qu'à tout moment, plus de 150 sessions attendaient le temps du processeur. L'utilisation du processeur était supérieure à 97 %, ce qui signifie que pendant la durée du problème, le processeur était occupé 97 % du temps. Ainsi, le processeur était occupé presque continuellement alors qu'en moyenne 150 sessions attendaient de s'exécuter sur le processeur.
-
Recommandations — La réponse suggérée par l'utilisateur à l'anomalie.
Dans la première anomalie, DevOps Guru for RDS vous recommande d'étudier les événements
cpud'attente et.io/table/sql/handlerPour savoir comment optimiser les performances de votre base de données en fonction de ces événements, consultez la section cpu et io/table/sql/handlerle guide de l'utilisateur Amazon Aurora.Dans le cas de la deuxième anomalie, DevOps Guru for RDS recommande de réduire la consommation du processeur en ajustant trois instructions SQL. Vous pouvez survoler les liens pour voir le texte SQL.
-
Métriques associées : mesures qui vous fournissent des mesures spécifiques pour l'anomalie. Pour plus d'informations sur ces métriques, consultez la référence des métriques pour Amazon Aurora dans le guide de l'utilisateur Amazon Aurora ou la référence des métriques pour Amazon RDS dans le guide de l'utilisateur Amazon RDS.
Dans le cas de la première anomalie, DevOps Guru for RDS recommande de comparer la charge de base de données au processeur maximal de votre instance. Dans la deuxième anomalie, il est recommandé d'examiner la file d'attente du processeur, l'utilisation du processeur et le taux d'exécution du SQL.
