Aidez à améliorer cette page
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pour contribuer à ce guide de l'utilisateur, cliquez sur le GitHub lien Modifier cette page sur qui se trouve dans le volet droit de chaque page.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Découvrez le changement de zone du contrôleur de récupération d’application (ARC) Amazon dans Amazon EKS
Kubernetes dispose de fonctionnalités natives qui vous permettent de rendre vos applications plus résilientes face à des événements tels que la dégradation de l’état ou la défaillance d’une zone de disponibilité (AZ). Lorsque vous exécutez vos charges de travail dans un cluster Amazon EKS, vous pouvez améliorer davantage la tolérance aux pannes et la récupération de votre environnement d’application en utilisant le changement de zone du contrôleur de récupération d’application (ARC) Amazon ou le changement automatique de zone. Le changement de zone ARC est conçu comme une mesure temporaire qui vous permet de déplacer le trafic d’une ressource hors d’une AZ défaillante jusqu’à l’expiration du changement de zone ou jusqu’à ce que vous l’annuliez. Vous pouvez prolonger le changement de zone si nécessaire.
Vous pouvez démarrer un changement de zone pour un cluster EKS, ou vous pouvez autoriser AWS le transfert de trafic pour vous en activant le changement automatique de zone. Ce transfert met à jour le flux de trafic réseau est-ouest dans votre cluster afin de ne prendre en compte que les points de terminaison réseau pour les pods s’exécutant sur des composants master dans des AZ saines. De plus, tout ALB ou NLB gérant le trafic entrant pour les applications de votre cluster EKS effectuera automatiquement le routage du trafic vers des cibles situées dans les zones de disponibilité saines. Pour les clients qui recherchent une disponibilité maximale, dans le cas où une zone de disponibilité serait défaillante, il peut être important de pouvoir détourner tout le trafic de la zone défaillante jusqu’à ce qu’elle soit rétablie. Pour cela, vous pouvez également activer un ALB ou un NLB avec le changement de zone ARC.
Comprendre le flux de trafic réseau est-ouest entre les pod
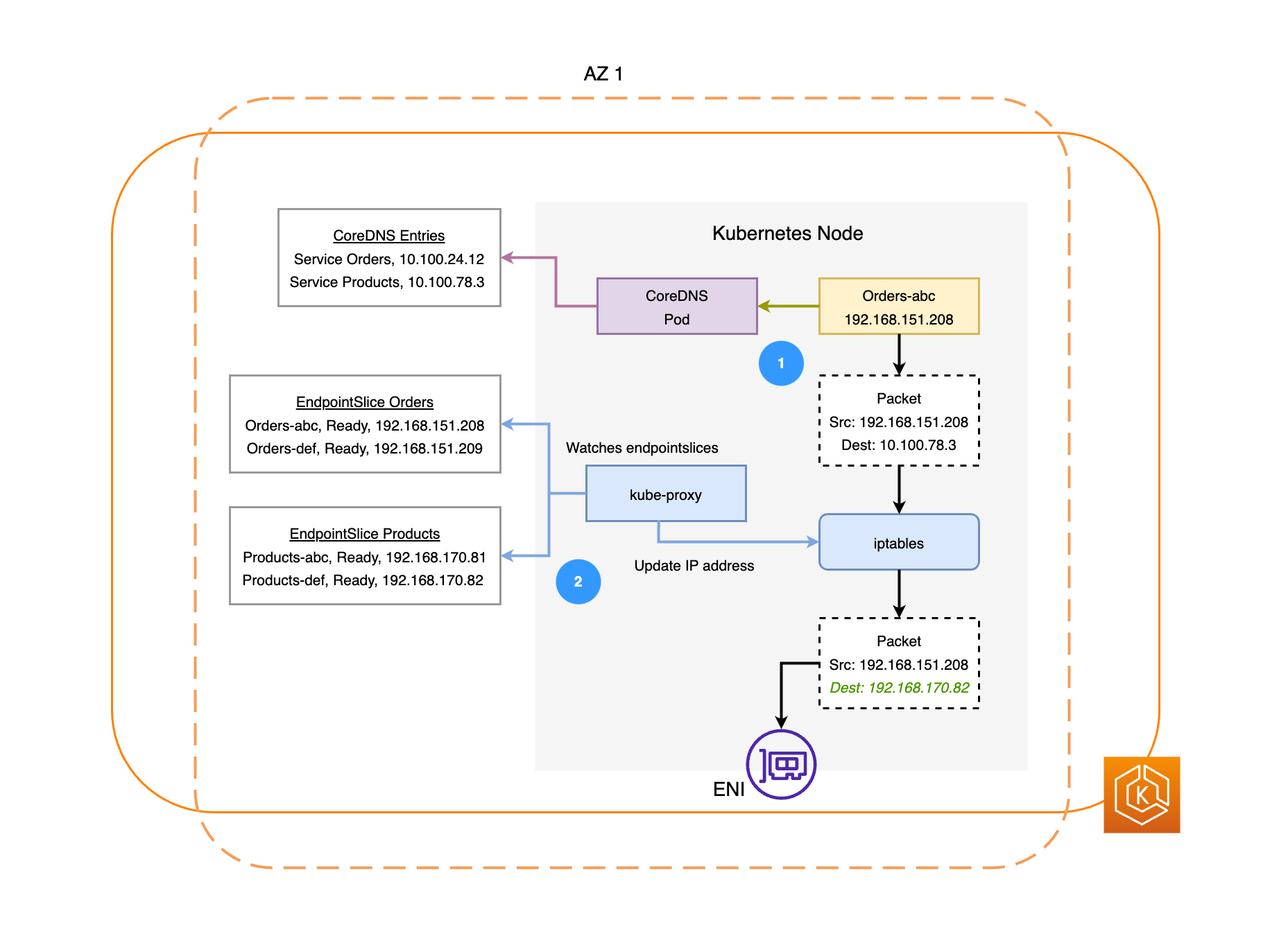
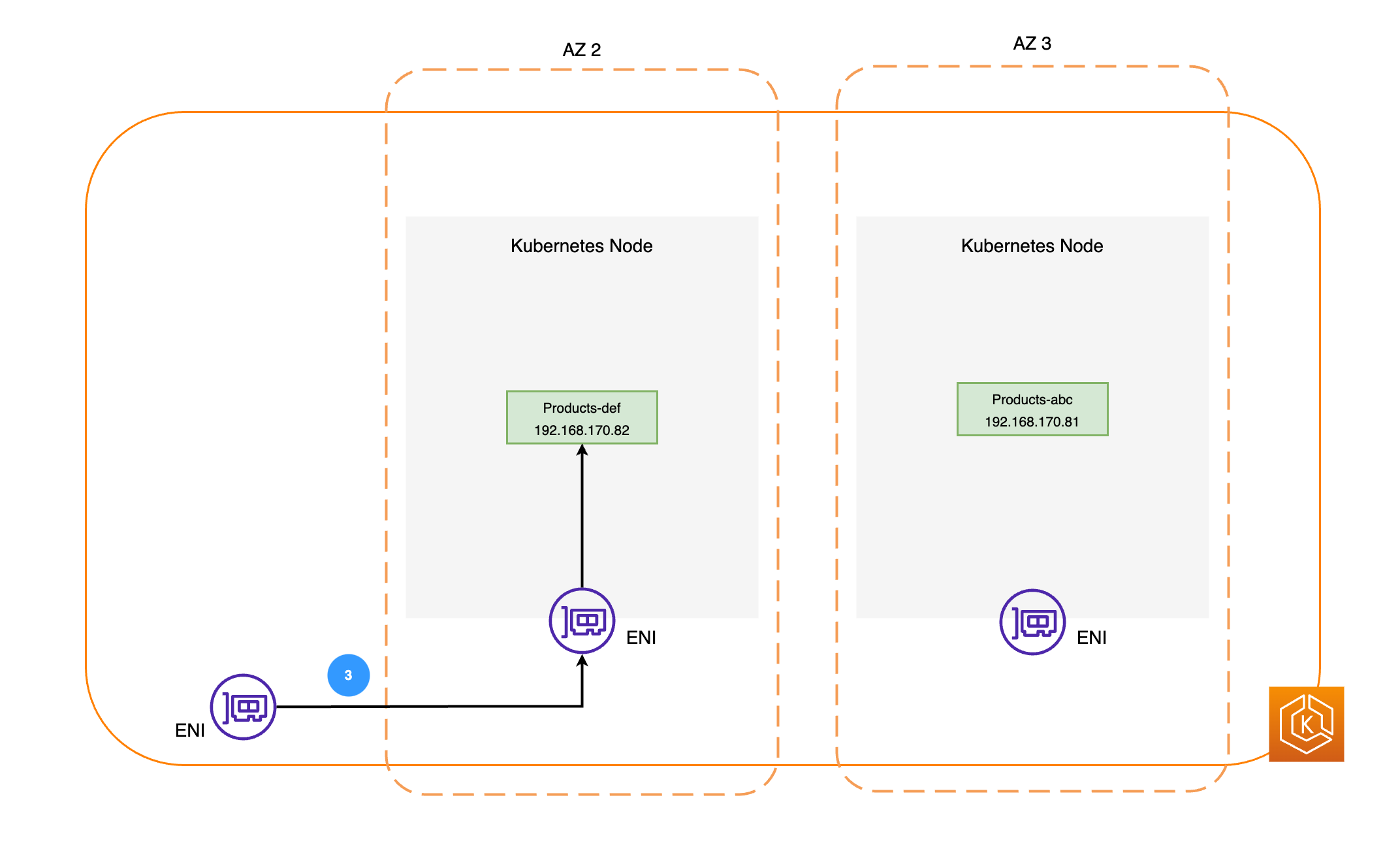
Le diagramme suivant illustre deux exemples de charges de travail, Orders et Products. L’objectif de cet exemple est de montrer comment les charges de travail et les pods situés dans différentes zones de disponibilité communiquent.
-
Pour que Orders puisse communiquer avec Products, Orders doit d’abord résoudre le nom DNS du service de destination. Orders communique avec CoreDNS pour récupérer l’adresse IP virtuelle (IP du cluster) de ce service. Une fois que Orders a résolu le nom du service Products, il envoie le trafic vers cette adresse IP cible.
-
Le kube-proxy s'exécute sur tous les nœuds du cluster et surveille en permanence EndpointSlices
les services. Lorsqu'un service est créé, un EndpointSlice est créé et géré en arrière-plan par le EndpointSlice contrôleur. Chacun EndpointSlice possède une liste ou un tableau de points de terminaison contenant un sous-ensemble d'adresses Pod, ainsi que les nœuds sur lesquels ils s'exécutent. Le kube-proxy configure des règles de routage pour chacun de ces points de terminaison de pods à l’aide de iptablessur les nœuds. Le kube-proxy est également responsable d’une forme basique d’équilibrage de charge, redirigeant le trafic destiné à l’adresse IP du cluster d’un service vers l’adresse IP d’un pod directement. Le kube-proxy effectue cette opération en réécrivant l’adresse IP de destination sur la connexion sortante. -
Les paquets réseau sont ensuite envoyés au pod Produits dans la zone de disponibilité 2 à l’aide des ENI sur les nœuds respectifs, comme indiqué dans le schéma précédent.
Comprendre le changement de zone ARC dans Amazon EKS
En cas de défaillance d’une zone de disponibilité dans votre environnement, vous pouvez initier un changement de zone pour votre environnement de cluster Amazon EKS. Vous pouvez également autoriser la gestion du trafic changeant AWS à votre place grâce à l'autoshift zonal. Grâce à l'autoshift zonal, il AWS surveille l'état général de la zone Z et répond à une éventuelle détérioration de la zone Z en transférant automatiquement le trafic vers l'autre zone affectée dans votre environnement de cluster.
Une fois que le changement de zone est activé avec ARC sur votre cluster Amazon EKS, vous pouvez démarrer un changement de zone ou activer le décalage automatique de zone à l'aide de la console ARC, de la AWS CLI ou des API de décalage de zone et de décalage automatique de zone. Lors d’un changement de zone EKS, les opérations suivantes sont effectuées automatiquement :
-
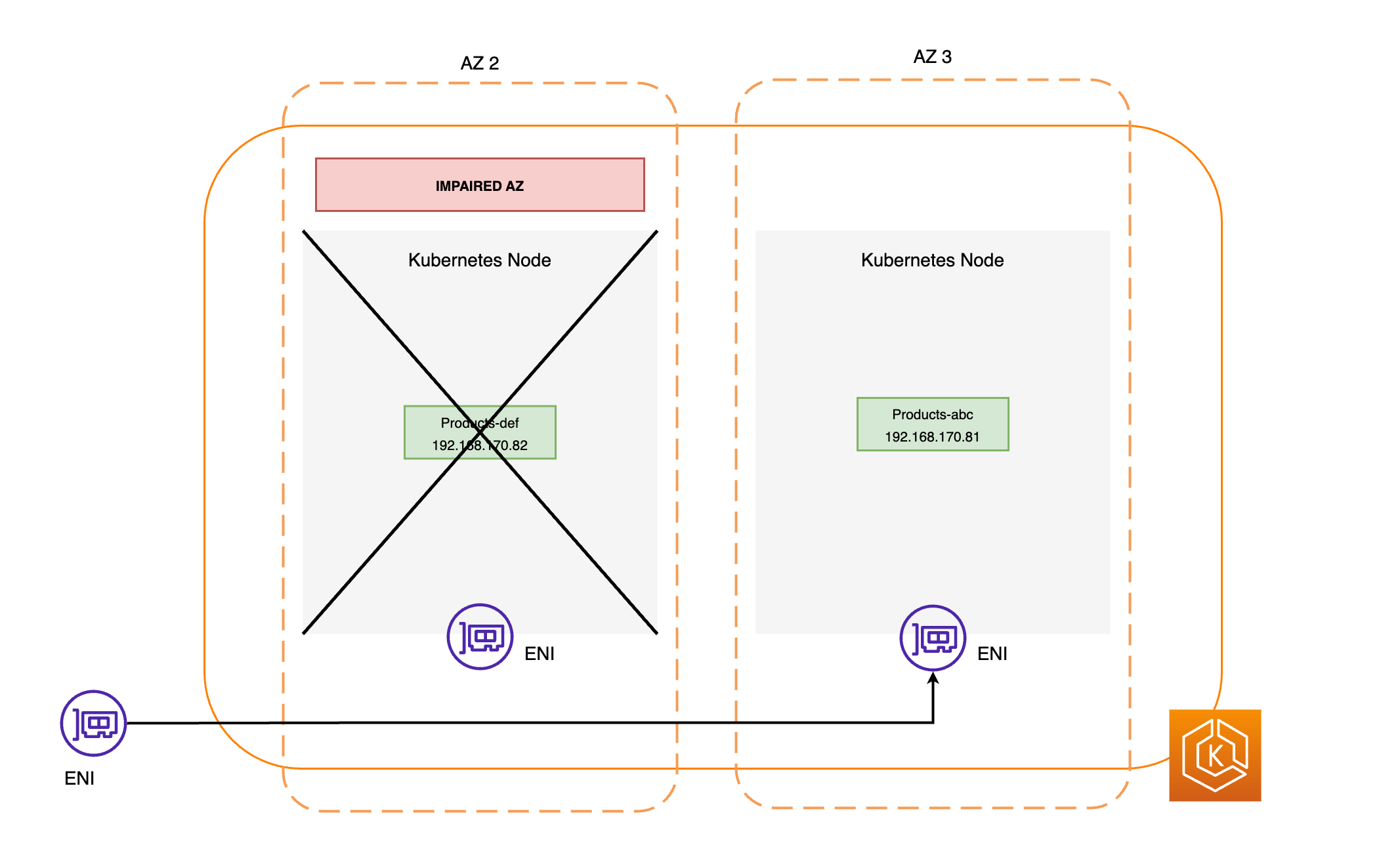
Tous les nœuds de la zone de disponibilité affectée sont isolés. Cela empêche le planificateur Kubernetes de planifier de nouveaux pods sur les nœuds de la zone de disponibilité défaillante.
-
Si vous utilisez le mode automatique EKS, le mode automatique EKS arrête automatiquement le provisionnement de nouveaux nœuds dans la zone AZ altérée. Les actions de perturbation volontaires telles que la consolidation et la dérive qui affecteraient l'AZ altérée sont également suspendues. Les pods soumis à des exigences de planification strictes qui ciblent l'AZ altérée (telles que les liaisons de volume persistantes, l'affinité des nœuds ou les contraintes strictes de répartition topologique) n'entraînent pas de tentatives de lancement de nouveaux nœuds vers cette AZ.
-
Si vous utilisez des groupes de nœuds gérés, le rééquilibrage des zones de disponibilité est suspendu et votre groupe Auto Scaling est mis à jour pour garantir que les nouveaux nœuds de plan de données EKS ne sont lancés que dans des zones de disponibilité saines.
-
Les nœuds de la zone de disponibilité défaillante ne sont pas résiliés et les pods ne sont pas expulsés des nœuds. Cela garantit que lorsque le changement de zone expire ou est annulé, votre trafic peut être renvoyé en toute sécurité vers la zone de disponibilité pour une capacité maximale.
-
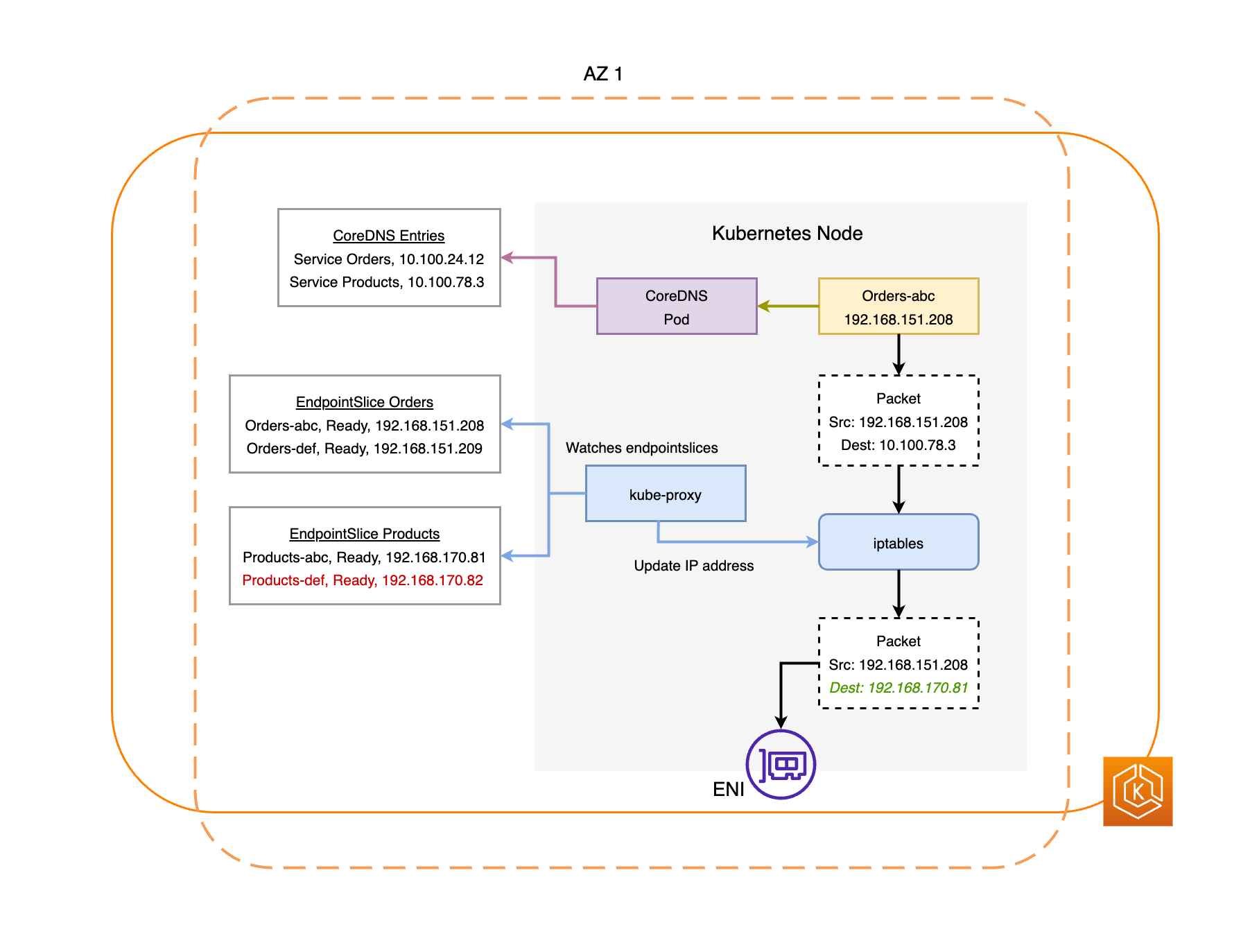
Le EndpointSlice contrôleur trouve tous les points de terminaison du Pod dans la zone AZ altérée et les retire de la zone correspondante EndpointSlices. Cela garantit que seuls les points de terminaison des pods dans les zones de disponibilité saines sont ciblés pour recevoir le trafic réseau. Lorsqu'un décalage de zone est annulé ou expire, le EndpointSlice contrôleur le met à jour EndpointSlices pour inclure les points de terminaison dans l'AZ restaurée.
Les diagrammes suivants fournissent une vue d’ensemble de la manière dont le changement de zone EKS garantit que seuls les points de terminaison de pods sains sont ciblés dans votre environnement de cluster.
Exigences relatives au changement de zone EKS
Important
Un changement de zone déplace tout le trafic interne au cluster hors d'une zone de disponibilité. Si vos charges de travail ne sont pas réparties sur plusieurs zones comportant suffisamment de répliques, le lancement d'un changement de zone peut en soi avoir un impact sur la disponibilité de vos applications, car il n'existe aucun point de terminaison sain pour recevoir du trafic. Vous devez vérifier que votre environnement de cluster peut fonctionner avec un AZ de moins avant d'activer le changement automatique de zone ou de démarrer un changement de zone manuel.
Pour que le changement de zone fonctionne correctement avec EKS, vous devez configurer votre environnement de cluster à l’avance afin qu’il soit résilient en cas de défaillance d’une zone de disponibilité. Voici une liste d’options de configuration qui contribuent à garantir la résilience.
-
Provisionnez les composants master de votre cluster sur plusieurs AZ
-
Provisionnez une capacité de calcul suffisante pour faire face à la suppression d’une seule AZ
-
Pre-scale vos Pods, y compris CoreDNS, dans chaque AZ
-
Répartissez plusieurs réplicas de pods sur toutes les AZ, afin de vous assurer que lorsque vous vous éloignez d’une seule AZ, vous disposez toujours d’une capacité suffisante
-
Effectuez la colocalisation des pods interdépendants ou liés dans la même zone de disponibilité
-
Vérifiez que votre environnement de cluster fonctionne comme prévu sans une zone de disponibilité en démarrant manuellement un changement de zone à partir d’une zone de disponibilité. Vous pouvez également activer le transfert automatique de zone et vous fier aux essais de transfert automatique. Il n’est pas nécessaire de tester les déplacements manuels ou les tests de déplacement de zone pour que le changement de zone fonctionne dans EKS, mais cela est fortement recommandé.
Provisionnez vos composants master EKS dans plusieurs zones de disponibilité
AWS Les régions disposent de plusieurs sites distincts dotés de centres de données physiques, appelés zones de disponibilité (AZ). Les AZ sont conçues pour être physiquement isolées les unes des autres afin d’éviter tout impact simultané qui pourrait affecter l’ensemble d’une région. Lorsque vous provisionnez un cluster EKS, nous vous recommandons de déployer vos composants master sur plusieurs AZ d’une région. Cela permet de rendre votre environnement de cluster plus résistant à la défaillance d’une seule AZ et vous permet de maintenir une haute disponibilité pour vos applications qui s’exécutent dans les autres AZ. Lorsque vous commencez un changement de zone par rapport à la zone de zone affectée, le réseau intégré au cluster de votre environnement EKS se met automatiquement à jour pour n'utiliser que des zones de zone de zone saines, afin de maintenir la haute disponibilité de votre cluster.
Le fait de disposer d’une configuration multi-AZ pour votre environnement EKS améliore la fiabilité globale de votre système. Cependant, les environnements multi-AZ influencent la manière dont les données des applications sont transférées et traitées, ce qui a un impact sur les frais de réseau de votre environnement. Plus précisément, un trafic sortant inter-zones fréquent (trafic réparti entre les zones de disponibilité) peut avoir un impact important sur vos coûts liés au réseau. Vous pouvez appliquer différentes stratégies pour contrôler le volume de trafic inter-zones entre les pods de votre cluster EKS et réduire les coûts associés. Pour plus d’informations sur la manière d’optimiser les coûts réseau lors de l’exécution d’environnements EKS hautement disponibles, consultez ces bonnes pratiques
Le diagramme suivant illustre un environnement EKS hautement disponible avec trois zones de disponibilité en bon état.
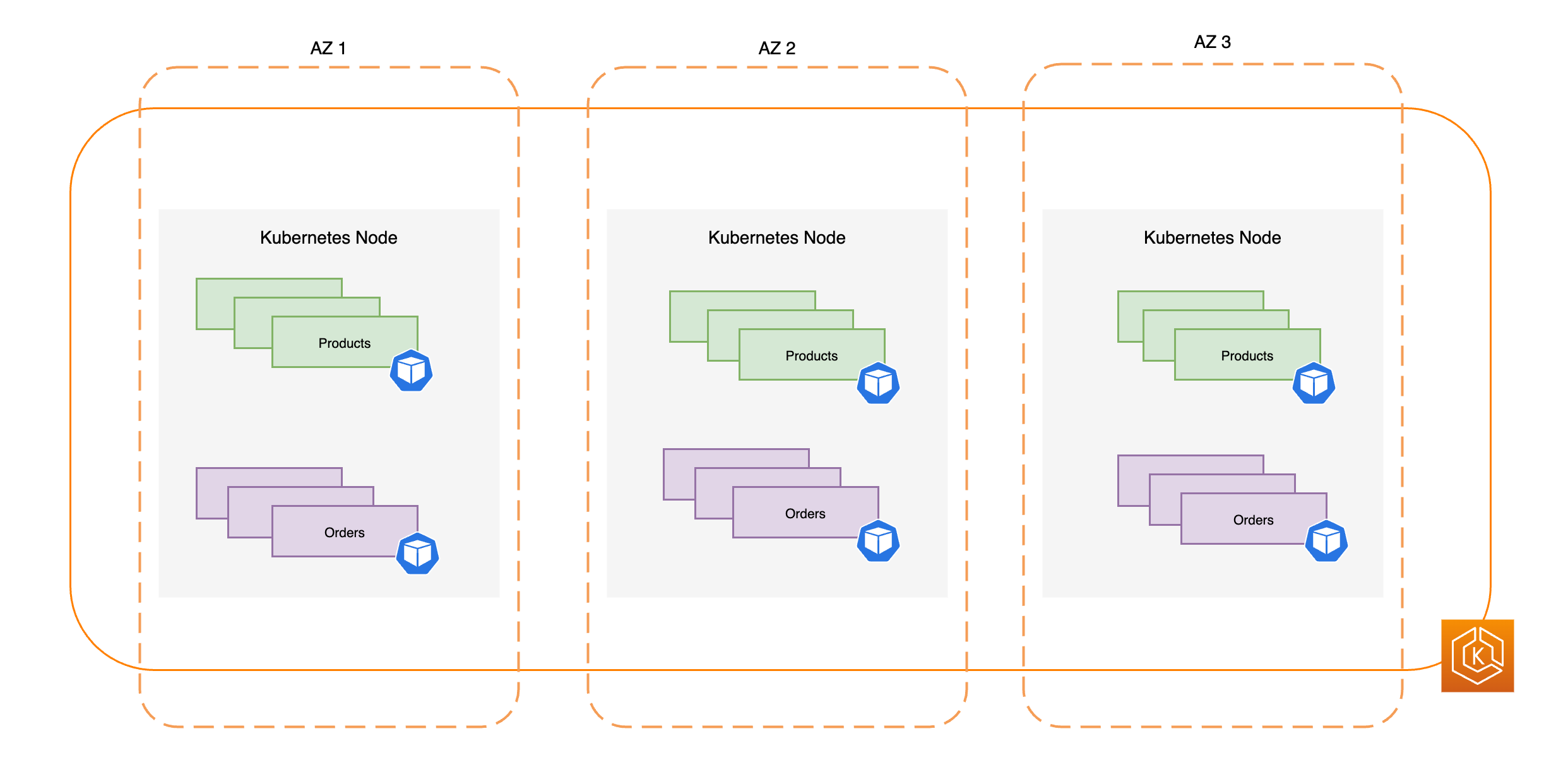
Le diagramme suivant illustre comment un environnement EKS avec trois zones de disponibilité résiste à une défaillance d’une zone de disponibilité et reste hautement disponible grâce aux deux autres zones de disponibilité en bon état.
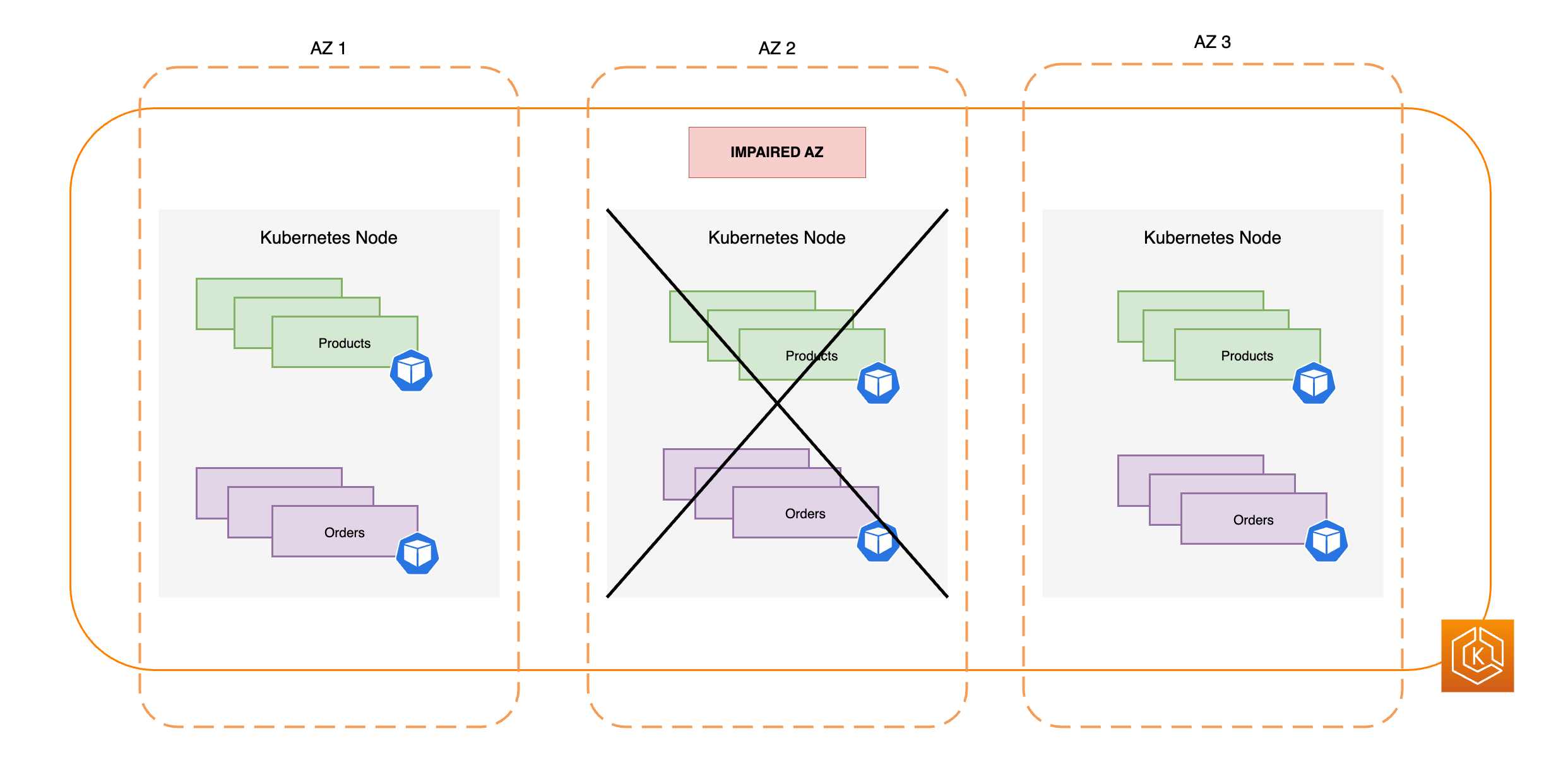
Provisionner une capacité de calcul suffisante pour faire face à la suppression d’une seule zone de disponibilité
Afin d’optimiser l’utilisation des ressources et les coûts de votre infrastructure de calcul dans le plan de données EKS, il est une bonne pratique d’aligner la capacité de calcul sur les exigences de votre charge de travail. Cependant, si tous vos composants master sont à pleine capacité, vous devez ajouter de nouveaux composants master au plan de données EKS avant de pouvoir planifier de nouveaux pods. Lorsque vous exécutez des charges de travail critiques, il est généralement recommandé de disposer d’une capacité redondante en ligne pour faire face à des scénarios tels que des augmentations soudaines de la charge et des problèmes d’état des nœuds. Si vous prévoyez d’utiliser le changement de zone, vous envisagez de supprimer toute la capacité d’une zone de disponibilité en cas de défaillance. Cela signifie que vous devez ajuster votre capacité de calcul redondante afin qu’elle soit suffisante pour gérer la charge même si l’une des zones de disponibilité est hors ligne.
Lorsque vous mettez à l’échelle vos ressources de calcul, le processus d’ajout de nouveaux nœuds au plan de données EKS prend un certain temps. Cela peut avoir des implications sur les performances en temps réel et la disponibilité de vos applications, en particulier en cas de défaillance de zone. Votre environnement EKS doit être capable d’absorber la charge liée à la perte d’une zone de disponibilité sans entraîner de dégradation de l’expérience pour vos utilisateurs finaux ou vos clients. Cela implique de réduire au minimum ou d’éliminer le décalage entre le moment où un nouveau pod est nécessaire et celui où il est effectivement planifié sur un composants master.
De plus, en cas de défaillance de zone, vous devez vous efforcer d’atténuer le risque de rencontrer une contrainte de capacité de calcul qui empêcherait l’ajout de nouveaux nœuds nécessaires à votre plan de données EKS dans les zones de disponibilité saines.
Pour réduire le risque de ces impacts négatifs potentiels, nous vous recommandons de surallouer la capacité de calcul de certains nœuds de travail de chacune des AZ. De cette manière, le planificateur Kubernetes dispose d’une capacité préexistante pour le placement de nouveaux pod, ce qui est particulièrement important lorsque vous perdez l’une des zones de disponibilité de votre environnement.
Exécuter et répartir plusieurs réplicas de pod entre les zones de disponibilité
Kubernetes vous permet de mettre à l’échelle vos charges de travail à l’avance en exécutant plusieurs instances (réplicas de pod) d’une même application. L’exécution de plusieurs réplicas de pods pour une application élimine les points de défaillance uniques et augmente les performances globales en réduisant la pression sur les ressources d’un seul réplica. Toutefois, pour bénéficier à la fois d’une haute disponibilité et d’une meilleure tolérance aux pannes pour vos applications, nous vous recommandons d’exécuter plusieurs réplicas de votre application et de répartir les réplicas sur différents domaines de défaillance, également appelés domaines topologiques. Dans ce scénario, les domaines de défaillance sont les zones de disponibilité. En utilisant des contraintes de répartition topologique
Le diagramme suivant illustre un environnement EKS avec un flux de trafic est-ouest lorsque toutes les zones de disponibilité sont saines.
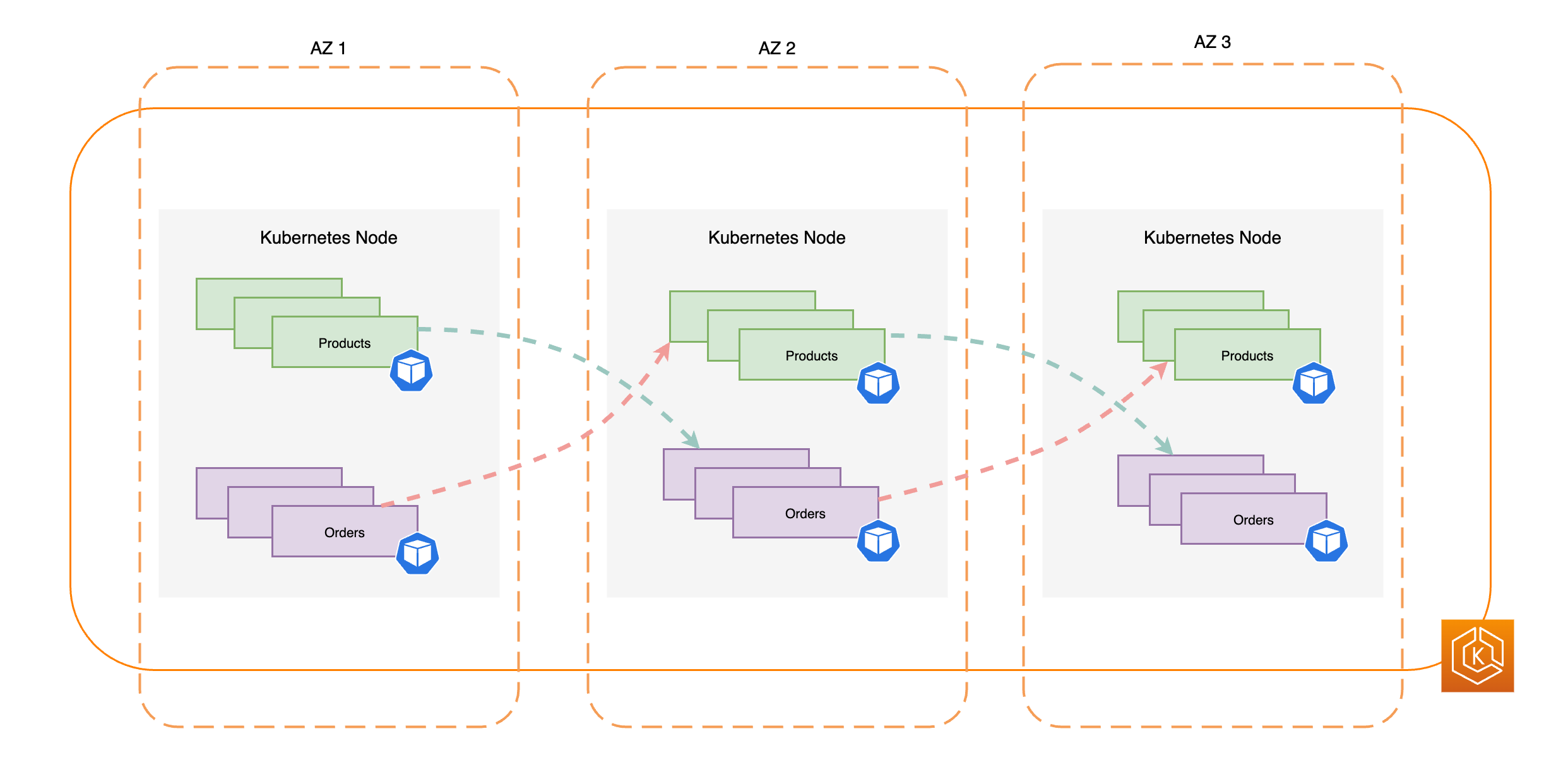
Le diagramme suivant illustre un environnement EKS avec un flux de trafic est-ouest où une seule AZ est défaillante et où vous avez lancé un changement de zone.
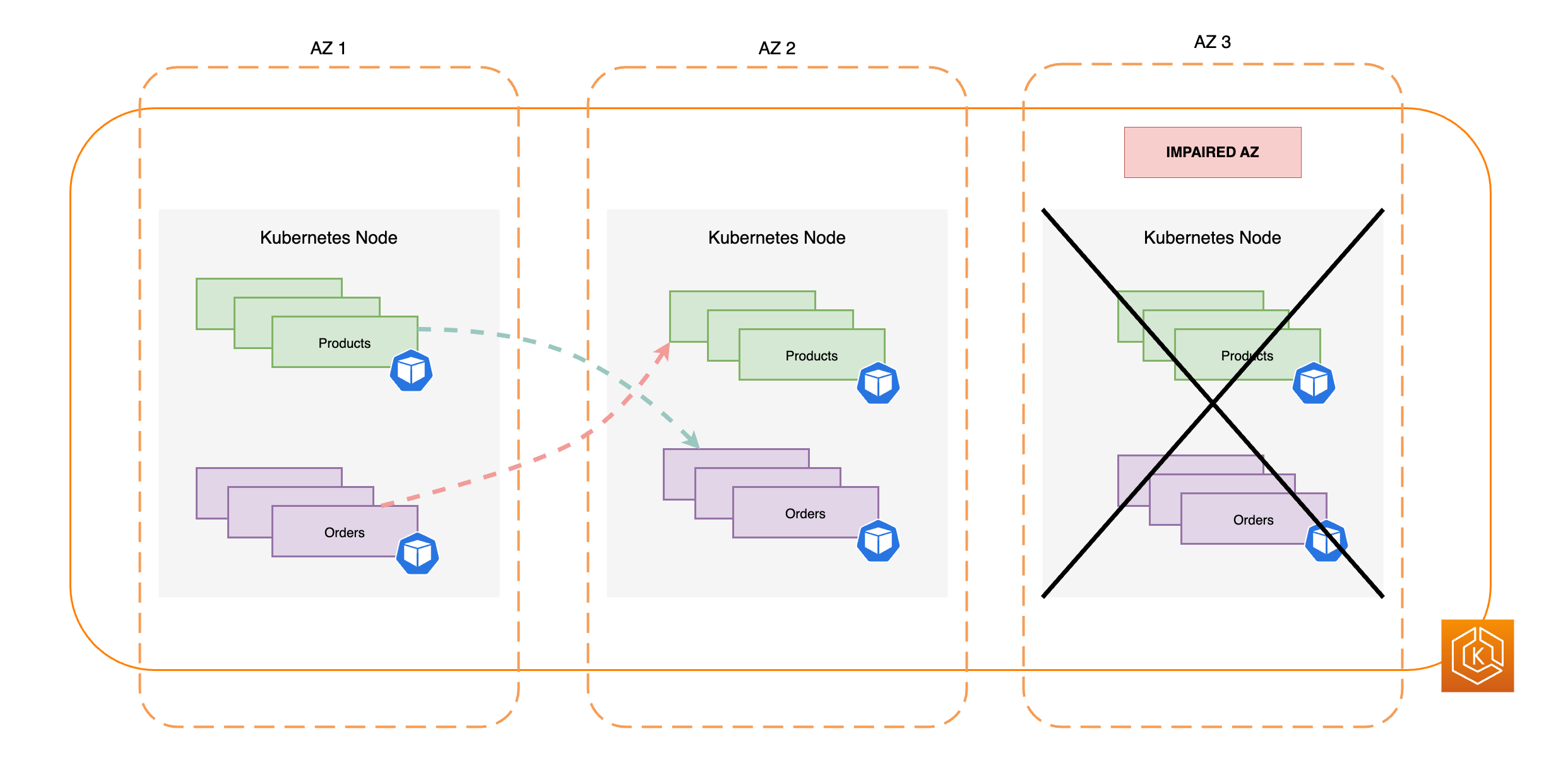
L’extrait de code suivant est un exemple de configuration de votre charge de travail avec plusieurs réplicas dans Kubernetes.
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
Plus important encore, vous devez exécuter plusieurs répliques de votre logiciel de serveur DNS (CoreDNS/kube-dns) et appliquer des contraintes de propagation topologique similaires, si elles ne sont pas configurées par défaut. Cela permet de garantir que, en cas de défaillance d’une seule zone de disponibilité, vous disposez d’un nombre suffisant de pods DNS dans des zones de disponibilité saines pour continuer à traiter les demandes de découverte de services pour les autres pods en communication dans le cluster. Le module complémentaire CoreDNS EKS dispose de paramètres par défaut pour les pods CoreDNS qui garantissent que, si des nœuds sont disponibles dans plusieurs zones de disponibilité, ils sont répartis dans les zones de disponibilité de votre cluster. Si vous le souhaitez, vous pouvez remplacer ces paramètres par défaut par vos propres configurations personnalisées.
Lorsque vous installez CoreDNS avec HelmreplicaCount dans le fichier values.yamltopologySpreadConstraints dans le même fichier values.yaml. L’extrait de code suivant illustre comment vous pouvez configurer CoreDNS pour cela.
CoreDNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
En cas de défaillance d’une zone de disponibilité, vous pouvez absorber la charge accrue sur les pods CoreDNS en utilisant un système autoscaling pour CoreDNS. Le nombre d’instances DNS dont vous aurez besoin dépend du nombre de charges de travail exécutées dans votre cluster. CoreDNS est lié au CPU, ce qui lui permet de s’adapter en fonction du CPU à l’aide du Horizontal Pod Autoscaler (HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
EKS peut également gérer l’autoscaling du déploiement CoreDNS dans la version du module complémentaire EKS de CoreDNS. Cet autoscaler CoreDNS surveille en continu l’état du cluster, y compris le nombre de nœuds et le nombre de cœurs de processeur. Sur la base de ces informations, le contrôleur ajuste dynamiquement le nombre de réplicas du déploiement CoreDNS dans un cluster EKS.
Pour activer la configuration de l’autoscaling dans le module complémentaire CoreDNS EKS, utilisez le paramètre de configuration suivant :
{ "autoScaling": { "enabled": true } }
Vous pouvez également utiliser le NodeLocal DNS
Colocaliser les pod interdépendants dans la même zone de disponibilité
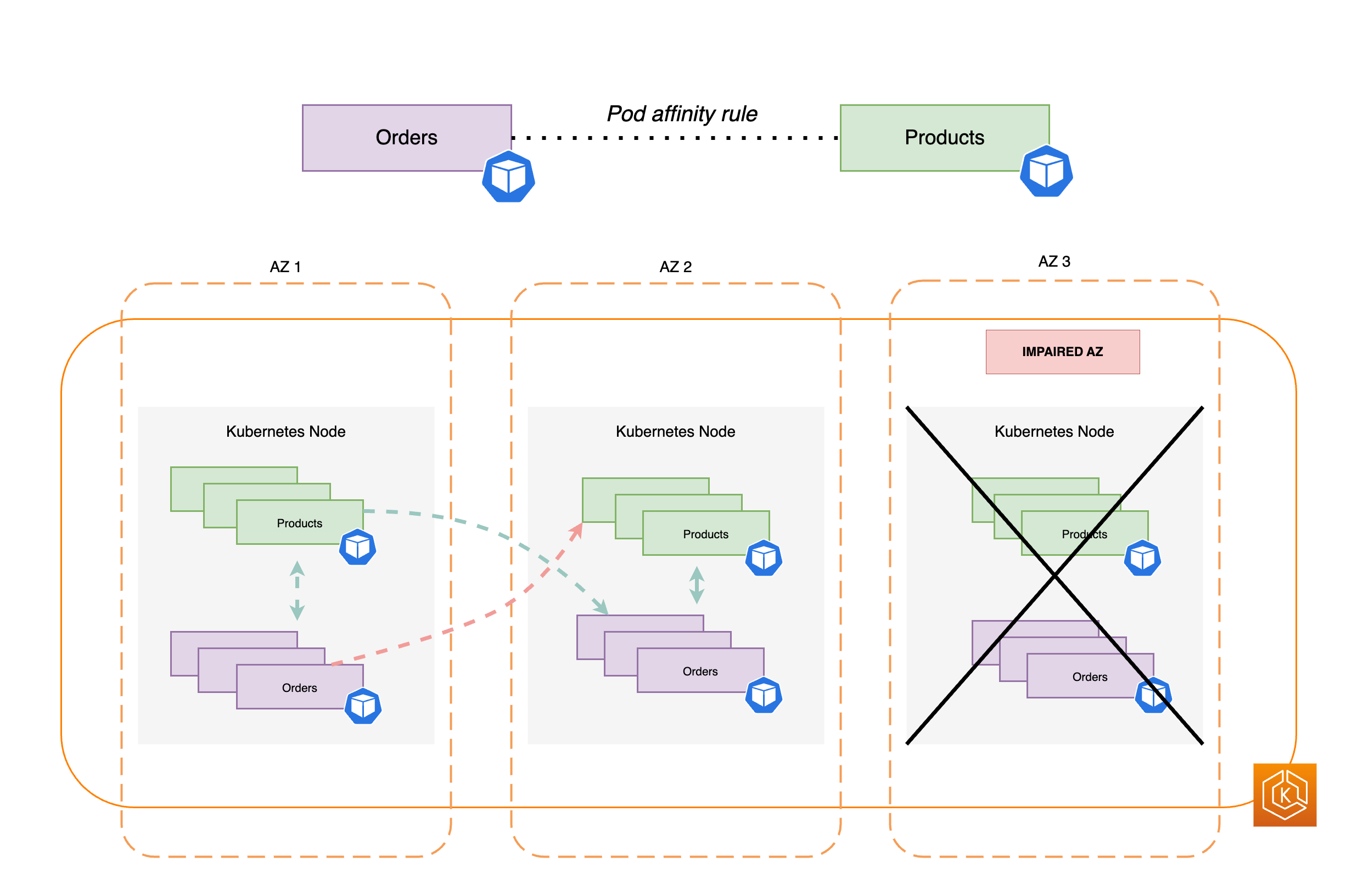
En règle générale, les applications ont des charges de travail distinctes qui doivent communiquer entre elles pour mener à bien un processus de bout en bout. Si ces applications distinctes sont réparties sur différentes zones de disponibilité et ne sont pas colocalisées dans la même zone, une seule défaillance de zone peut avoir un impact sur le processus de bout en bout. Par exemple, si Application A dispose de plusieurs réplicas dans les zones de disponibilité 1 et 2, mais que Application B dispose de toutes ses réplicas dans la zone de disponibilité 3, la perte de la zone de disponibilité 3 affectera les processus de bout en bout entre les deux charges de travail, Application A et Application B. En combinant les contraintes de propagation de topologie pour les pods, vous pouvez améliorer la résilience de votre application en répartissant les pods sur toutes les zones de disponibilité. De plus, cela permet de configurer une relation entre certains pods afin de garantir leur colocalisation.
Grâce aux règles d’affinité des pods
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Le diagramme suivant montre plusieurs pods que le planificateur a colocalisés sur le même nœud à l’aide des règles d’affinité des pods.
Vérifier que votre environnement de cluster peut gérer la perte d’une zone de disponibilité
Une fois que vous avez rempli les conditions décrites dans les sections précédentes, l’étape suivante consiste à vérifier que vous disposez d’une capacité de calcul et de charge de travail suffisante pour gérer la perte d’une zone de disponibilité. Pour ce faire, vous pouvez lancer manuellement un changement de zone dans EKS. Vous pouvez également activer le transfert automatique de zone et configurer des essais, qui permettent également de vérifier que vos applications fonctionnent comme prévu avec une zone de disponibilité en moins dans votre environnement de cluster.
Questions fréquentes (FAQ)
Pourquoi utiliser cette fonctionnalité ?
En utilisant le changement de zone ARC ou le transfert automatique de zone dans votre cluster EKS, vous pouvez mieux maintenir la disponibilité des applications Kubernetes en automatisant le processus de récupération rapide consistant à transférer le trafic réseau du cluster hors d’une zone de disponibilité défaillante. Avec ARC, vous pouvez éviter les étapes longues et compliquées qui peuvent entraîner une période de récupération prolongée lors d’événements de défaillance d’une zone de disponibilité.
Comment fonctionne cette fonctionnalité avec les autres AWS services ?
EKS s'intègre à ARC, qui fournit l'interface principale dans laquelle vous pouvez effectuer des opérations de restauration AWS. Afin de garantir que le routage du trafic au sein du cluster soit correctement acheminé hors d’une zone de disponibilité défaillante, EKS modifie la liste des points de terminaison réseau pour les pods s’exécutant dans le plan de données Kubernetes. Si vous utilisez Elastic Load Balancing pour le routage du trafic externe vers le cluster, vous pouvez enregistrer vos équilibreurs de charge auprès d’ARC et lancer un changement de zone sur ceux-ci afin d’empêcher le trafic d’affluer vers la zone de disponibilité dégradée. Si vous utilisez le mode automatique EKS, le mode automatique EKS limite automatiquement le provisionnement des nœuds aux zones de disponibilité saines. Le changement de zone fonctionne également avec les groupes Amazon EC2 Auto Scaling créés par les groupes de nœuds gérés par EKS. Afin d’empêcher qu’une zone de disponibilité défaillante ne soit utilisée pour de nouveaux pods Kubernetes ou le lancement de nouveaux nœuds, EKS supprime la zone de disponibilité défaillante des groupes Auto Scaling.
En quoi cette fonctionnalité diffère-t-elle des protections Kubernetes par défaut ?
Cette fonctionnalité fonctionne en tandem avec plusieurs protections intégrées à Kubernetes qui contribuent à la résilience des applications des clients. Vous pouvez configurer des sondes de disponibilité et de vitalité des pods qui déterminent quand un pod doit prendre en charge le trafic. Lorsque ces sondes échouent, Kubernetes supprime ces pods en tant que cibles pour un service, et le trafic n’est plus envoyé au pod. Bien que cela soit utile, il n’est pas simple pour les clients de configurer ces surveillances de l’état de manière à garantir leur échec lorsqu’une AZ est dégradée. La fonctionnalité de changement de zone ARC fournit un filet de sécurité supplémentaire qui vous aide à isoler entièrement une AZ dégradée lorsque les protections natives de Kubernetes ne sont pas suffisantes. Le changement de zone vous offre également un moyen simple de tester la disponibilité opérationnelle et la résilience de votre architecture.
Puis-je AWS commencer un changement de zone en mon nom ?
Oui, si vous voulez utiliser le changement de zone ARC de manière entièrement automatisée, vous pouvez activer le changement automatique de zone ARC. Avec l'autoshift zonal, vous pouvez compter sur vous AWS pour surveiller l'état des AZ de votre cluster EKS et pour démarrer automatiquement un changement de zone lorsqu'une altération de l'AZ est détectée.
Que se passe-t-il si j’utilise cette fonctionnalité et que mes composants master et mes charges de travail ne sont pas mis à l’échelle au préalable ?
Si vous n’avez pas effectué de mise à l’échelle préalable et que vous comptez sur le provisionnement de nœuds ou de pod supplémentaires pendant un changement de zone, vous risquez un retard dans la récupération. Le processus d’ajout de nouveaux nœuds au plan de données Kubernetes prend un certain temps, ce qui peut avoir un impact sur les performances en temps réel et la disponibilité de vos applications, en particulier en cas de défaillance de zone. De plus, en cas de défaillance de zone, vous pouvez rencontrer une contrainte potentielle de capacité de calcul qui pourrait empêcher l’ajout de nouveaux nœuds nécessaires aux zones de disponibilité saines.
Si vous utilisez le mode automatique d'EKS, le mode automatique d'EKS provisionne automatiquement les nouveaux nœuds dans des zones de disponibilité saines afin de répondre à la demande non planifiée de pods. Cependant, les nouveaux nœuds mettent encore du temps à être lancés et prêts. Pour une restauration rapide, nous vous recommandons de prédimensionner vos charges de travail sur plusieurs zones de disponibilité.
Si vos charges de travail ne sont pas mises à l’échelle au préalable et réparties sur toutes les zones de disponibilité de votre cluster, une défaillance zonale peut avoir un impact sur la disponibilité d’une application qui ne s’exécute que sur les composants master d’une zone de disponibilité affectée. Afin d’atténuer le risque d’une interruption complète de la disponibilité de votre application, EKS dispose d’un dispositif de sécurité qui permet d’envoyer le trafic vers les points de terminaison des pods dans une zone défaillante si cette charge de travail a tous ses points de terminaison dans la zone de disponibilité défaillante. Cependant, nous vous recommandons vivement de mettre à l’échelle au préalable et de répartir vos applications sur toutes les zones de disponibilité afin de maintenir la disponibilité en cas de problème de zone.
Comment cela fonctionne-t-il si j’exécute une application avec état ?
Si vous exécutez une application avec état, vous devez évaluer sa tolérance aux pannes en fonction de votre cas d’utilisation et de votre architecture. Si vous avez une active/standby architecture ou un modèle, il se peut que l'actif se trouve dans un AZ altéré. Au niveau de l’application, si l’instance de secours n’est pas activée, vous risquez de rencontrer des problèmes avec votre application. Vous pouvez également rencontrer des problèmes lorsque de nouveaux pods Kubernetes sont lancés dans des zones de disponibilité saines, car ils ne pourront pas se connecter aux volumes persistants liés à la zone de disponibilité défaillante.
Cette fonctionnalité fonctionne-t-elle avec le mode automatique EKS ?
Oui. Lorsque vous activez le changement de zone sur un cluster en mode automatique EKS, le mode automatique EKS répond automatiquement aux événements de changement de zone. Lors d'un changement de zone, le mode automatique d'EKS arrête le provisionnement de nouveaux nœuds dans la zone de zone affectée, suspend les actions d'interruption volontaires (telles que la consolidation et la dérive) susceptibles d'affecter la zone de zone altérée et évite de lancer des pods soumis à des exigences de planification strictes ciblant la zone de zone endommagée. Vous n'avez besoin d'aucune configuration supplémentaire au-delà de l'activation du décalage de zone sur le cluster.
Cette fonctionnalité fonctionne-t-elle avec Karpenter autogéré ?
Self-managed Le support Karpenter est disponible avec le changement de zone ARC et le changement automatique de zone dans EKS avec la version 1.12 ou supérieure de Karpenter
Cette fonctionnalité est-elle compatible avec EKS Fargate ?
Cette fonctionnalité n’est pas compatible avec EKS Fargate. Par défaut, lorsque EKS Fargate détecte un événement de l’état, les pod seront exécutés de préférence dans les autres zones de disponibilité.
Le plan de contrôle Kubernetes géré par Amazon EKS sera-t-il affecté ?
Non, par défaut, Amazon EKS exécute et adapte le plan de contrôle Kubernetes sur plusieurs zones de disponibilité afin de garantir une haute disponibilité. Le changement de zone ARC et le déplacement automatique de zone n’agissent que sur le plan de données Kubernetes.
Cette nouvelle fonctionnalité entraîne-t-elle des coûts supplémentaires ?
Vous pouvez utiliser le changement de zone ARC et le changement automatique de zone dans votre cluster EKS sans frais supplémentaires. Cependant, vous continuerez à payer les instances provisionnées et nous vous recommandons vivement de mettre à l’échelle au préalable votre plan de données Kubernetes avant d’utiliser cette fonctionnalité. Il est important de trouver un équilibre entre le coût et la disponibilité des applications.
Ressources supplémentaires
