Nous ne mettons plus à jour le service Amazon Machine Learning et n'acceptons plus de nouveaux utilisateurs pour celui-ci. Cette documentation est disponible pour les utilisateurs existants, mais nous ne la mettons plus à jour. Pour plus d'informations, consultez Qu'est-ce qu'Amazon Machine Learning ?
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cross-Validation
Cross-validation est une technique d'évaluation des modèles de ML en entraînant plusieurs modèles de ML sur des sous-ensembles de données d'entrée disponibles et en les évaluant sur le sous-ensemble complémentaire des données. Utilisez la validation croisée pour détecter un surajustement, par exemple, l'échec de la généralisation d'une tendance.
Dans Amazon ML, vous pouvez utiliser la méthode de validation croisée k-fold pour effectuer une validation croisée. Dans le cadre de la validation croisée à k volets, vous divisez les données d'entrée en k sous-ensembles de données (également appelés plis). Vous entraînez un modèle ML sur tous les sous-ensembles sauf un (k-1), puis vous évaluez le modèle sur le sous-ensemble qui n'a pas été utilisé pour l'entraînement. Ce processus est répété k fois, avec un sous-ensemble différent réservé à l'évaluation (et exclu de la formation) à chaque fois.
Le diagramme suivant illustre un exemple des sous-ensembles de formation et des sous-ensembles d'évaluation complémentaire générés pour chacun des quatre modèles qui sont créés et formés au cours d'une validation croisée à 4 échantillons. Le modèle 1 utilise 25 % des données pour l'évaluation et les 75 % restants pour la formation. Le modèle 2 utilise le deuxième sous-ensemble de 25 % (de 25 % à 50 %) pour l'évaluation et les trois sous-ensembles restants
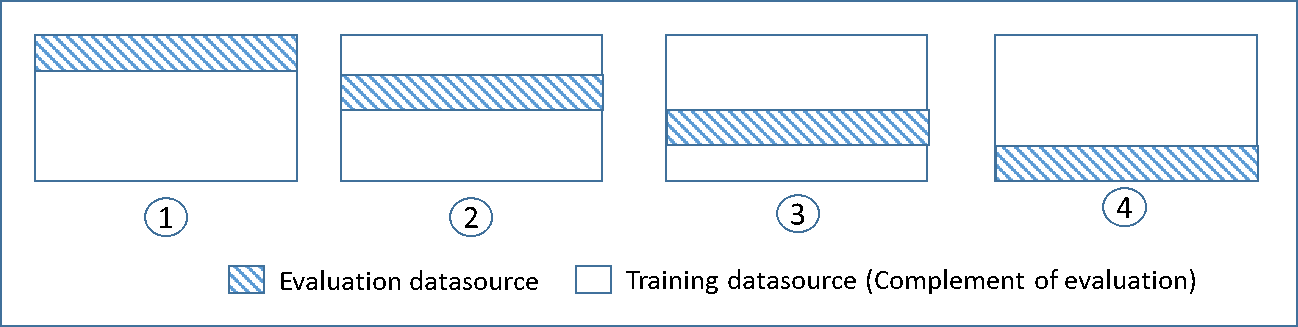
Chaque modèle est formé et évalué à l'aide de sources de données complémentaires - les données figurant dans la source de données d'évaluation incluent toutes les données qui ne se trouvent pas dans la source de données de formation, et sont limitées à cela. Vous créez des sources de données pour chacun de ces sous-ensembles avec le paramètre DataRearrangement dans les API createDatasourceFromS3, createDatasourceFromRedShift et createDatasourceFromRDS. Dans le paramètre DataRearrangement, spécifiez le sous-ensemble de données à inclure dans une source de données en spécifiant où commencer et finir chaque segment. Pour créer les sources de données complémentaires requises pour une validation croisée à 4 000 échantillons, spécifiez le paramètre DataRearrangement comme indiqué dans l'exemple suivant :
Modèle 1 :
Source de données pour l'évaluation :
{"splitting":{"percentBegin":0, "percentEnd":25}}
Source de données pour la formation :
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
Modèle 2 :
Source de données pour l'évaluation :
{"splitting":{"percentBegin":25, "percentEnd":50}}
Source de données pour la formation :
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
Modèle 3 :
Source de données pour l'évaluation :
{"splitting":{"percentBegin":50, "percentEnd":75}}
Source de données pour la formation :
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
Modèle 4 :
Source de données pour l'évaluation :
{"splitting":{"percentBegin":75, "percentEnd":100}}
Source de données pour la formation :
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
L'exécution d'une validation croisée en 4 étapes génère quatre modèles, quatre sources de données pour entraîner les modèles, quatre sources de données pour évaluer les modèles et quatre évaluations, une pour chaque modèle. Amazon ML génère une métrique de performance du modèle pour chaque évaluation. Par exemple, dans une validation croisée à 4 échantillons pour un problème de classification binaire, chacune des évaluations signale une métrique Aire sous une courbe (AUC, Area Under a Curve). Vous pouvez obtenir la mesure des performances globales en calculant la moyenne de ces quatre métriques AUC. Pour obtenir des informations sur la métrique AUC, consultez Mesure de la précision du modèle d'apprentissage-machine.
Pour un exemple de code expliquant comment créer une validation croisée et calculer la moyenne des scores du modèle, consultez l'exemple de code Amazon ML
Ajustement de vos modèles
Après avoir effectué la validation croisée des modèles, vous pouvez ajuster les paramètres pour le modèle suivant si votre modèle ne fonctionne pas selon vos normes. Pour plus d'informations sur le surajustement, consultez Ajustement du modèle : sous-ajustement et surajustement. Pour plus d'informations sur la régularisation, consultez Régularisation. Pour plus d'informations sur la modification des paramètres de régularisation, consultez Création d'un modèle d'apprentissage-machine avec des options personnalisées.
