Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration des rôles et des utilisateurs dans Amazon OpenSearch Ingestion
Amazon OpenSearch Ingestion utilise différents modèles et IAM rôles d'autorisations pour permettre aux applications source d'écrire dans des pipelines et pour permettre aux pipelines d'écrire dans des récepteurs. Avant de commencer à ingérer des données, vous devez créer un ou plusieurs IAM rôles dotés d'autorisations spécifiques en fonction de votre cas d'utilisation.
Au minimum, vous avez besoin des rôles suivants pour configurer un pipeline réussi.
| Name (Nom) | Description |
|---|---|
| Rôle de gestion |
Tout directeur chargé de gérer des pipelines (généralement un « administrateur de pipeline ») a besoin d'un accès de gestion, qui inclut des autorisations telles que |
| Rôle du pipeline |
Le rôle de pipeline, que vous spécifiez dans la YAML configuration du pipeline, fournit les autorisations requises pour qu'un pipeline puisse écrire dans le domaine ou le récepteur de collection et lire à partir de sources basées sur le pull. Pour plus d’informations, consultez les rubriques suivantes : |
| Rôle d'ingestion |
Le rôle d'ingestion contient l' |
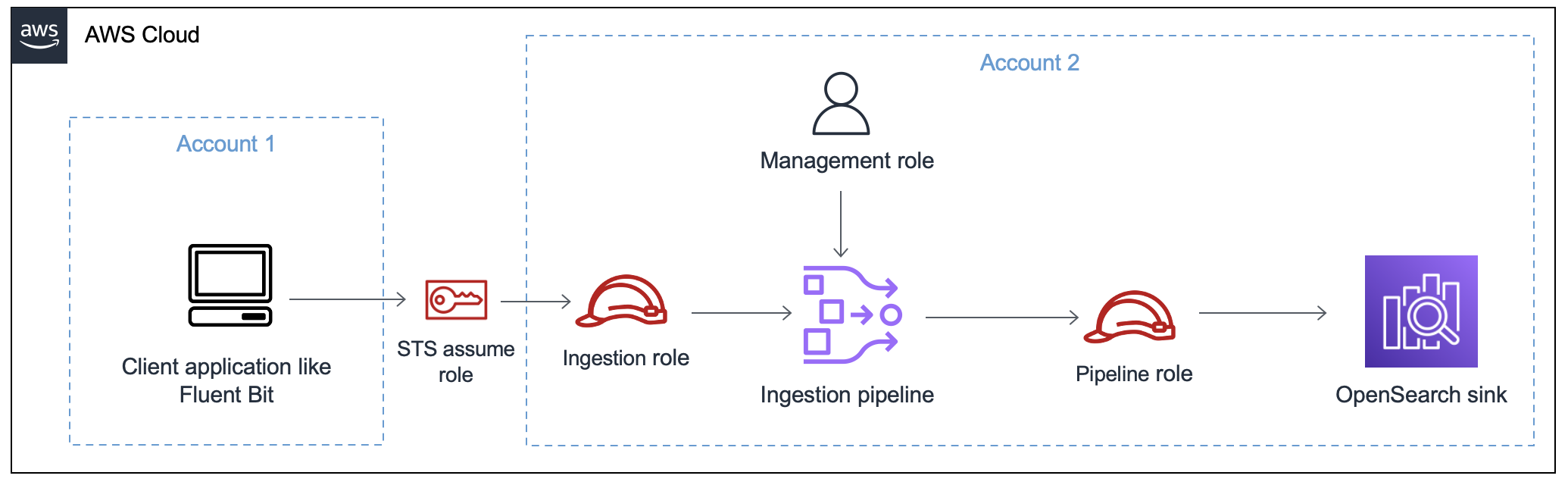
L'image suivante illustre une configuration de pipeline typique, dans laquelle une source de données telle qu'Amazon S3 ou Fluent Bit écrit dans un pipeline d'un autre compte. Dans ce cas, le client doit assumer le rôle d'ingestion pour accéder au pipeline. Pour de plus amples informations, veuillez consulter Ingestion entre comptes.
Pour un guide de configuration simple, voirTutoriel : Ingestion de données dans un domaine à l'aide d'Amazon OpenSearch Ingestion.
Rôle de gestion
Outre les osis:* autorisations de base nécessaires pour créer et modifier un pipeline, vous devez également disposer de l'iam:PassRoleautorisation pour la ressource de rôle du pipeline. Toute Service AWS personne qui accepte un rôle doit utiliser cette autorisation. OpenSearch L'ingestion joue le rôle chaque fois qu'elle doit écrire des données dans un récepteur. Cela permet aux administrateurs de s'assurer que seuls les utilisateurs approuvés peuvent configurer OpenSearch Ingestion avec un rôle octroyant des autorisations. Pour plus d'informations, voir Accorder à un utilisateur l'autorisation de transmettre un rôle à un Service AWS.
Si vous utilisez le AWS Management Console (en utilisant des plans et en vérifiant ultérieurement votre pipeline), vous devez disposer des autorisations suivantes pour créer et mettre à jour un pipeline :
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Resource":"*", "Action":[ "osis:CreatePipeline", "osis:GetPipelineBlueprint", "osis:ListPipelineBlueprints", "osis:GetPipeline", "osis:ListPipelines", "osis:GetPipelineChangeProgress", "osis:ValidatePipeline", "osis:UpdatePipeline" ] }, { "Resource":[ "arn:aws:iam::your-account-id:role/pipeline-role" ], "Effect":"Allow", "Action":[ "iam:PassRole" ] } ] }
Si vous utilisez le AWS CLI (sans prévalider votre pipeline ni utiliser des plans), vous devez disposer des autorisations suivantes pour créer et mettre à jour un pipeline :
{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Resource":"*", "Action":[ "osis:CreatePipeline", "osis:UpdatePipeline" ] }, { "Resource":[ "arn:aws:iam::your-account-id:role/pipeline-role" ], "Effect":"Allow", "Action":[ "iam:PassRole" ] } ] }
Rôle du pipeline
Un pipeline a besoin de certaines autorisations pour écrire dans son récepteur. Ces autorisations varient selon que le récepteur est un domaine OpenSearch de service ou une collection OpenSearch sans serveur.
En outre, un pipeline peut avoir besoin d'autorisations pour extraire de l'application source (si la source est un plugin basé sur le pull) et d'autorisations pour écrire dans une file d'attente de lettres mortes S3, si elle est configurée.
Rubriques
Écrire dans un récepteur de domaine
Un pipeline d' OpenSearch ingestion a besoin d'une autorisation pour écrire dans un domaine de OpenSearch service configuré comme récepteur. Ces autorisations incluent la possibilité de décrire le domaine et de HTTP lui envoyer des demandes.
Pour fournir à votre pipeline les autorisations requises pour écrire dans un récepteur, créez d'abord un rôle AWS Identity and Access Management (IAM) avec les autorisations requises. Ces autorisations sont les mêmes pour le public et les VPC pipelines. Spécifiez ensuite le rôle du pipeline dans la politique d'accès au domaine afin que le domaine puisse accepter les demandes d'écriture provenant du pipeline.
Enfin, spécifiez le rôle ARN comme valeur de l'option sts_role_arn dans la configuration du pipeline :
version: "2" source: http: ... processor: ... sink: - opensearch: ... aws: sts_role_arn: arn:aws:iam::your-account-id:role/pipeline-role
Pour obtenir des instructions pour effectuer chacune de ces étapes, voir Autoriser les pipelines à accéder aux domaines.
Écrire dans un évier de collection
Un pipeline d' OpenSearch ingestion a besoin d'une autorisation pour écrire dans une collection OpenSearch sans serveur configurée comme récepteur. Ces autorisations incluent la possibilité de décrire la collection et de HTTP lui envoyer des demandes.
Créez d'abord un IAM rôle aoss:BatchGetCollection autorisé à accéder à toutes les ressources (*). Incluez ensuite ce rôle dans une politique d'accès aux données et accordez-lui les autorisations nécessaires pour créer des index, mettre à jour des index, décrire des index et rédiger des documents au sein de la collection. Enfin, spécifiez le rôle ARN comme valeur de l'option sts_role_arn dans la configuration du pipeline.
Pour obtenir des instructions pour effectuer chacune de ces étapes, voir Autoriser les pipelines à accéder aux collections.
Écrire dans une file d'attente de lettres mortes
Si vous configurez votre pipeline pour écrire dans une file d'attente contenant des lettres mortessts_role_arnoption dans la DLQ configuration. Les autorisations incluses dans ce rôle permettent au pipeline d'accéder au compartiment S3 que vous spécifiez comme destination pour les DLQ événements.
Vous devez utiliser le même principe sts_role_arn dans tous les composants du pipeline. Par conséquent, vous devez associer une politique d'autorisation distincte à votre rôle de pipeline qui fournit DLQ l'accès. Au minimum, le rôle doit être autorisé à S3:PutObject agir sur la ressource du bucket :
{ "Version": "2012-10-17", "Statement": [ { "Sid": "WriteToS3DLQ", "Effect": "Allow", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::my-dlq-bucket/*" } ] }
Vous pouvez ensuite spécifier le rôle dans la DLQ configuration du pipeline :
... sink: opensearch: dlq: s3: bucket: "my-dlq-bucket" key_path_prefix: "dlq-files" region: "us-west-2" sts_role_arn: "arn:aws:iam::your-account-id:role/pipeline-role"
Rôle d'ingestion
Tous les plugins source actuellement pris en charge OpenSearch par Ingestion, à l'exception de S3, utilisent une architecture basée sur le push. Cela signifie que l'application source envoie les données vers le pipeline, plutôt que le pipeline extrait les données de la source.
Par conséquent, vous devez accorder à vos applications source les autorisations requises pour ingérer des données dans un pipeline d' OpenSearch ingestion. Au minimum, le rôle qui signe la demande doit être autorisé à effectuer l'osis:Ingestaction, ce qui lui permet d'envoyer des données à un pipeline. Les mêmes autorisations sont requises pour les points de terminaison publics et de VPC pipeline.
L'exemple de politique suivant permet au principal associé d'ingérer des données dans un pipeline unique appelé my-pipeline :
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PermitsWriteAccessToPipeline", "Effect": "Allow", "Action": "osis:Ingest", "Resource": "arn:aws:osis:region:your-account-id:pipeline/pipeline-name" } ] }
Pour de plus amples informations, veuillez consulter Intégration des pipelines OpenSearch Amazon Ingestion à d'autres services et applications.
Ingestion entre comptes
Il se peut que vous deviez ingérer des données dans un pipeline à partir d'un autre Compte AWS système, tel qu'un compte d'application. Pour configurer l'ingestion entre comptes, définissez un rôle d'ingestion au sein du même compte que le pipeline et établissez une relation de confiance entre le rôle d'ingestion et le compte d'application :
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::external-account-id:root" }, "Action": "sts:AssumeRole" }] }
Configurez ensuite votre application pour qu'elle assume le rôle d'ingestion. Le compte d'application doit accorder au rôle d'application AssumeRoledes autorisations pour le rôle d'ingestion dans le compte de pipeline.
Pour obtenir des étapes détaillées et des exemples IAM de politiques, voirFournir un accès à l'ingestion entre comptes.
