Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Réaliser une preuve de concept (POC) pour Amazon Redshift
Amazon Redshift est un entrepôt de données cloud populaire, qui propose un service cloud entièrement géré qui s'intègre au lac de données Amazon Simple Storage Service, aux flux en temps réel, aux flux de travail d'apprentissage automatique (ML), aux flux de travail transactionnels d'une entreprise, etc. Les sections suivantes vous guident tout au long du processus de validation de principe (POC) sur Amazon Redshift. Les informations présentées ici vous aident à définir des objectifs pour votre POC et à tirer parti des outils qui peuvent automatiser le provisionnement et la configuration des services pour votre POC.
Note
Pour obtenir une copie de ces informations au format PDF, cliquez sur le lien Run your own Redshift POC sur la page des ressources Amazon
Lorsque vous effectuez un POC d'Amazon Redshift, vous testez, prouvez et adoptez des fonctionnalités telles que des fonctionnalités best-in-class de sécurité, une mise à l'échelle élastique, une intégration et une ingestion faciles, ainsi que des options d'architecture de données décentralisées flexibles.

Suivez les étapes ci-dessous pour réussir un POC.
Étape 1 : Déterminez le périmètre de votre POC

Lorsque vous effectuez un POC, vous pouvez choisir d'utiliser vos propres données ou d'utiliser des ensembles de données d'analyse comparative. Lorsque vous choisissez vos propres données, vous exécutez vos propres requêtes sur ces données. Avec les données d'analyse comparative, des exemples de requêtes sont fournis avec le point de référence. Consultez Utiliser des exemples de jeux de données pour plus de détails si vous n'êtes pas encore prêt à effectuer un POC avec vos propres données.
En général, nous recommandons d'utiliser deux semaines de données pour un POC Amazon Redshift.
Commencez par effectuer les opérations suivantes :
Identifiez vos exigences opérationnelles et fonctionnelles, puis revenez en arrière. Les exemples les plus courants sont les suivants : amélioration des performances, réduction des coûts, test d'une nouvelle charge de travail ou d'une nouvelle fonctionnalité, ou comparaison entre Amazon Redshift et un autre entrepôt de données.
Fixez des objectifs spécifiques qui deviennent les critères de réussite du POC. Par exemple, pour des performances plus rapides, dressez une liste des cinq principaux processus que vous souhaitez accélérer et incluez les durées d'exécution actuelles ainsi que la durée d'exécution requise. Il peut s'agir de rapports, de requêtes, de processus ETL, d'ingestion de données ou de tout autre problème actuel.
Identifiez la portée et les artefacts spécifiques nécessaires pour exécuter les tests. Quels ensembles de données devez-vous migrer ou ingérer en permanence dans Amazon Redshift, et quels sont les requêtes et les processus nécessaires pour exécuter les tests en fonction des critères de réussite ? Il existe deux façons de procéder :
Apportez vos propres données
Pour tester vos propres données, établissez la liste minimale viable d'artefacts de données nécessaires pour tester vos critères de réussite. Par exemple, si votre entrepôt de données actuel compte 200 tables, mais que les rapports que vous souhaitez tester n'en ont besoin que de 20, votre POC peut être exécuté plus rapidement en utilisant uniquement le plus petit sous-ensemble de tables.
Utiliser des exemples de jeux de données
Si vos propres ensembles de données ne sont pas prêts, vous pouvez toujours commencer à effectuer un POC sur Amazon Redshift en utilisant les ensembles de données de référence tels que
TPC-DS ou TPC-H et en exécutant des exemples de requêtes d'analyse comparative pour exploiter la puissance d'Amazon Redshift. Ces ensembles de données sont accessibles depuis votre entrepôt de données Amazon Redshift une fois celui-ci créé. Pour obtenir des instructions détaillées sur la façon d'accéder à ces ensembles de données et des exemples de requêtes, consultezÉtape 2 : Lancez Amazon Redshift.
Étape 2 : Lancez Amazon Redshift

Amazon Redshift vous permet d'obtenir plus rapidement des informations grâce à un entrepôt de données cloud rapide, simple et sécurisé à grande échelle. Vous pouvez démarrer rapidement en lançant votre entrepôt sur la console Redshift Serverless
Configurer Amazon Redshift sans serveur
La première fois que vous utilisez Redshift Serverless, la console vous guide à travers les étapes nécessaires au lancement de votre entrepôt. Vous pourriez également être éligible à un crédit correspondant à votre utilisation de Redshift Serverless sur votre compte. Pour plus d'informations sur le choix d'un essai gratuit, consultez la rubrique Essai gratuit d'Amazon Redshift
Si vous avez déjà lancé Redshift Serverless dans votre compte, suivez les étapes décrites dans la section Création d'un groupe de travail avec un espace de noms dans le guide de gestion Amazon Redshift. Une fois votre entrepôt disponible, vous pouvez choisir de charger les exemples de données disponibles dans Amazon Redshift. Pour plus d'informations sur l'utilisation de l'éditeur de requêtes Amazon Redshift v2 pour charger des données, consultez la section Chargement d'exemples de données dans le guide de gestion Amazon Redshift.
Si vous apportez vos propres données au lieu de charger l'exemple d'ensemble de données, consultezÉtape 3 : Chargez vos données.
Étape 3 : Chargez vos données

Après avoir lancé Redshift Serverless, l'étape suivante consiste à charger vos données pour le POC. Que vous téléchargiez un simple fichier CSV, que vous ingériez des données semi-structurées depuis S3 ou que vous diffusiez directement des données, Amazon Redshift offre la flexibilité nécessaire pour déplacer rapidement et facilement les données depuis la source vers les tables Amazon Redshift.
Choisissez l'une des méthodes suivantes pour charger vos données.
Téléchargez un fichier local
Pour une ingestion et une analyse rapides, vous pouvez utiliser l'éditeur de requêtes Amazon Redshift v2 pour charger facilement des fichiers de données depuis votre bureau local. Il a la capacité de traiter des fichiers dans différents formats tels que CSV, JSON, AVRO, PARQUET, ORC, etc. Pour permettre à vos utilisateurs, en tant qu'administrateur, de charger des données depuis un poste de travail local à l'aide de l'éditeur de requêtes v2, vous devez spécifier un compartiment Amazon S3 commun, et le compte utilisateur doit être configuré avec les autorisations appropriées. Vous pouvez suivre le chargement des données en toute simplicité et en toute sécurité dans Amazon Redshift à l'aide de Query Editor V2
Charger un fichier Amazon S3
Pour charger des données depuis un compartiment Amazon S3 dans Amazon Redshift, commencez par utiliser la commande COPY, en spécifiant l'emplacement Amazon S3 source et la table Amazon Redshift cible. Assurez-vous que les rôles et autorisations IAM sont correctement configurés pour autoriser Amazon Redshift à accéder au compartiment Amazon S3 désigné. Suivez le didacticiel : Chargement de données depuis Amazon S3 pour step-by-step obtenir des conseils. Vous pouvez également choisir l'option Charger les données dans l'éditeur de requêtes v2 pour charger directement les données depuis votre compartiment S3.
Ingestion continue des données
Autocopy (en version préliminaire) est une extension de la commande COPY qui automatise le chargement continu des données à partir des compartiments Amazon S3. Lorsque vous créez une tâche de copie, Amazon Redshift détecte la création de nouveaux fichiers Amazon S3 dans un chemin spécifié, puis les charge automatiquement sans votre intervention. Amazon Redshift assure le suivi des fichiers chargés afin de vérifier qu’ils ne sont chargés qu’une seule fois. Pour obtenir des instructions sur la création de tâches de copie, voir TÂCHE DE COPIE
Note
La copie automatique est actuellement en version préliminaire et n'est prise en charge que dans des clusters provisionnés en particulier. Régions AWS Pour créer un cluster de prévisualisation à des fins d'autocopie, voirCréez une intégration d'événements S3 pour copier automatiquement des fichiers depuis des compartiments Amazon S3.
Chargez vos données de streaming
L'ingestion du streaming permet une ingestion rapide et à faible latence des données de flux provenant d'Amazon Kinesis Data
Étape 4 : Analysez vos données

Après avoir créé votre groupe de travail et votre espace de noms Redshift Serverless, et après avoir chargé vos données, vous pouvez immédiatement exécuter des requêtes en ouvrant l'éditeur de requêtes v2 depuis le panneau de navigation de la console Redshift Serverless.
Requête à l'aide de l'éditeur de requêtes Amazon Redshift v2
Vous pouvez accéder à l'éditeur de requêtes v2 depuis la console Amazon Redshift. Consultez Simplifiez votre analyse de données avec l'éditeur de requêtes Amazon Redshift v2
Sinon, si vous souhaitez exécuter un test de charge dans le cadre de votre POC, vous pouvez le faire en suivant les étapes suivantes pour installer et exécuter Apache JMeter.
Exécuter un test de charge à l'aide d'Apache JMeter
Pour effectuer un test de charge afin de simuler « N » utilisateurs soumettant des requêtes simultanément à Amazon Redshift, vous pouvez utiliser Apache
Pour installer et configurer Apache JMeter afin qu'il s'exécute sur votre groupe de travail Redshift Serverless, suivez les instructions de la section Automatiser les tests de charge Amazon Redshift avec l'Analytics Automation Toolkit
Une fois que vous avez terminé de personnaliser vos instructions SQL et de finaliser votre plan de test, enregistrez et exécutez votre plan de test par rapport à votre groupe de travail Redshift Serverless. Pour suivre la progression de votre test, ouvrez la console Redshift Serverless
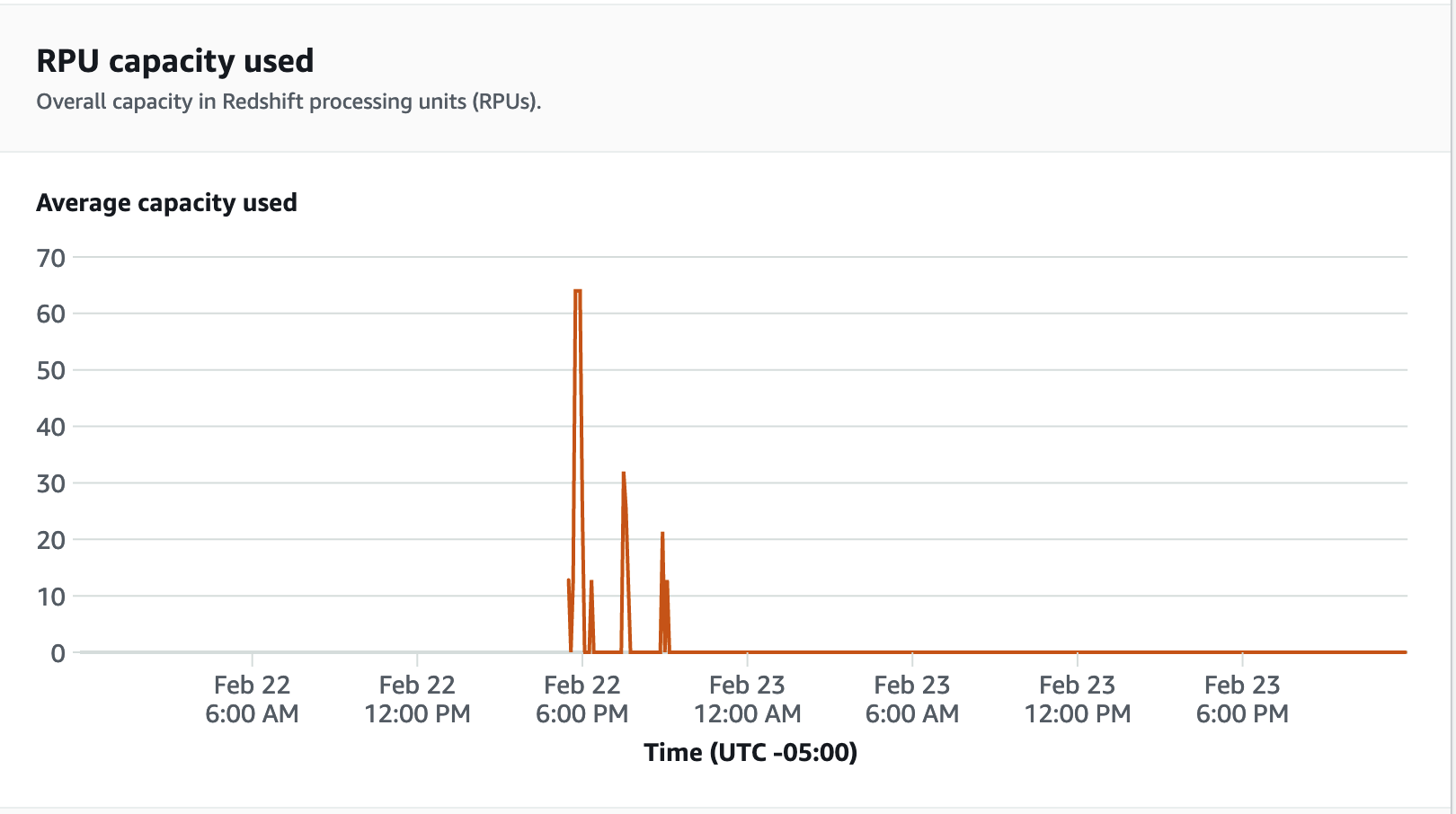
Pour les mesures de performance, choisissez l'onglet Performances de la base de données sur la console Redshift Serverless, pour surveiller les mesures telles que les connexions aux bases de données et l'utilisation du processeur. Vous pouvez consulter ici un graphique pour surveiller la capacité RPU utilisée et observer comment Redshift Serverless évolue automatiquement pour répondre aux demandes de charge de travail simultanées pendant que le test de charge est en cours d'exécution sur votre groupe de travail.
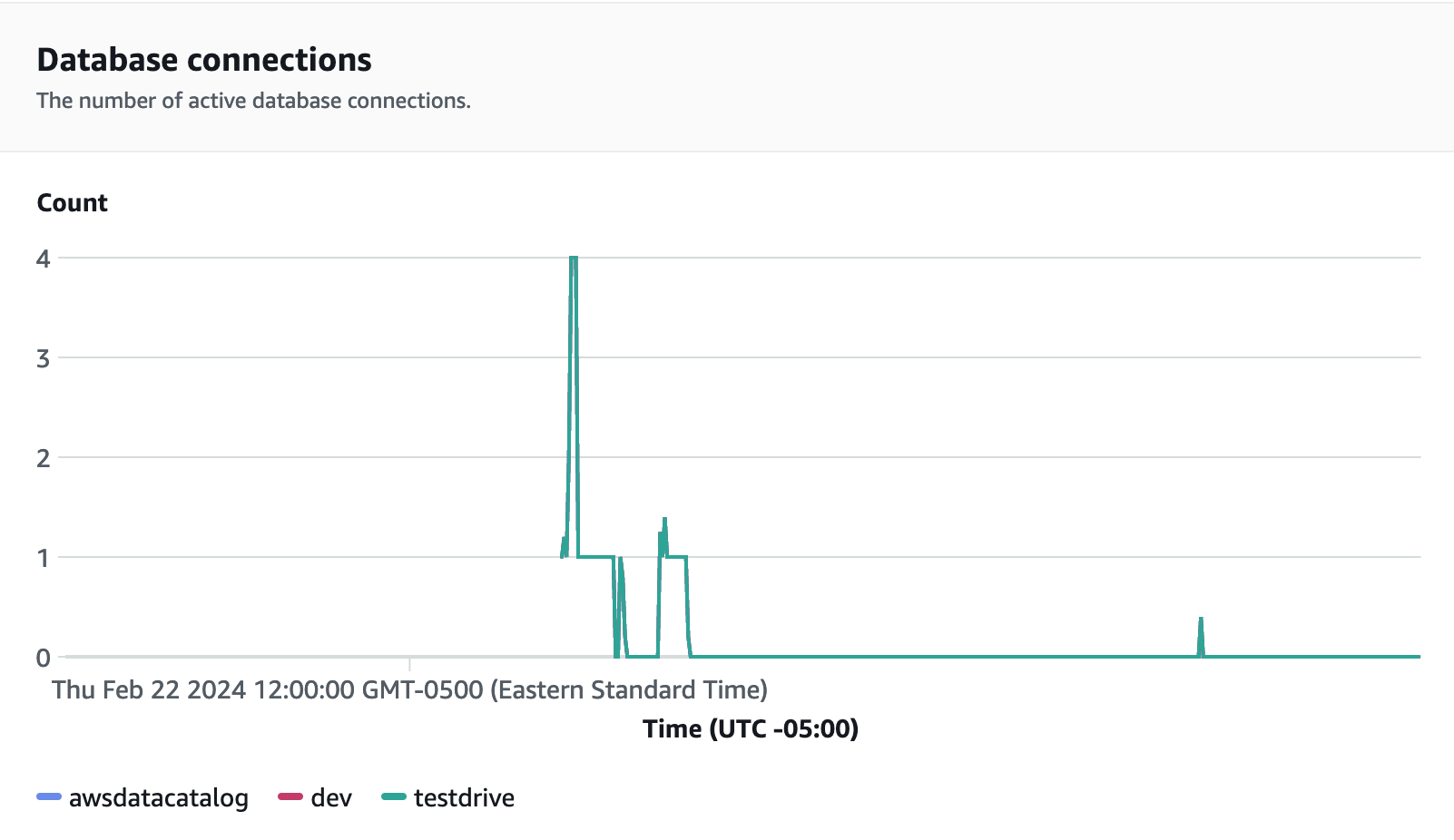
Les connexions aux bases de données constituent un autre indicateur utile à surveiller lors de l'exécution du test de charge pour voir comment votre groupe de travail gère de nombreuses connexions simultanées à un moment donné afin de répondre aux demandes croissantes de charge de travail.
Étape 5 : Optimisation

Amazon Redshift permet à des dizaines de milliers d'utilisateurs de traiter des exaoctets de données chaque jour et d'optimiser leurs charges de travail d'analyse en proposant une variété de configurations et de fonctionnalités adaptées à des cas d'utilisation individuels. Lorsqu'ils choisissent entre ces options, les clients recherchent des outils qui les aident à déterminer la configuration d'entrepôt de données la plus optimale pour prendre en charge leur charge de travail Amazon Redshift.
Essai routier
Vous pouvez utiliser Test Drive
