Amazon Redshift ne prendra plus en charge l'utilisation des UDF Python après le 30 juin 2026. Nous allons commencer à l'appliquer par étapes. Pour plus d'informations sur les options de fin de vie et de migration de Python, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Premiers pas avec les entrepôts de données Amazon Redshift sans serveur
Si vous utilisez Amazon Redshift Serverless pour la première fois, nous vous recommandons de lire les sections suivantes pour vous aider à faire vos premiers pas avec Amazon Redshift Serverless. Le flux de base d'Amazon Redshift sans serveur consiste à créer des ressources sans serveur, à se connecter à Amazon Redshift sans serveur, à charger des exemples de données, puis à exécuter des requêtes sur les données. Dans ce guide, vous pouvez choisir de charger des exemples de données à partir d'Amazon Redshift sans serveur ou d'un compartiment Amazon S3. Les exemples de données sont utilisés dans l’ensemble de la documentation Amazon Redshift pour démontrer les fonctionnalités. Pour commencer à utiliser les entrepôts de données alloués Amazon Redshift, consultez Commencer avec les entrepôts de données alloués Amazon Redshift.
Inscrivez-vous pour un Compte AWS
Pour commencer AWS, vous avez besoin d'un Compte AWS. Pour plus d'informations sur la création d'un Compte AWS, voir Getting started with an Compte AWS dans le Guide de Gestion de compte AWS référence.
Création d'un entrepôt des données avec Amazon Redshift sans serveur
La première fois que vous vous connectez à la console Amazon Redshift sans serveur, vous êtes invité à accéder à l'expérience de démarrage, que vous pouvez utiliser pour créer et gérer des ressources sans serveur. Dans ce guide, vous allez créer des ressources sans serveur en utilisant les paramètres par défaut d'Amazon Redshift sans serveur.
Pour un contrôle plus précis de votre configuration, choisissez Personnaliser les paramètres.
Note
Redshift sans serveur nécessite un VPC Amazon avec trois sous-réseaux dans trois zones de disponibilité différentes. Redshift sans serveur nécessite également au moins 3 adresses IP disponibles. Assurez-vous que le VPC Amazon que vous utilisez pour Redshift sans serveur possède trois sous-réseaux dans trois zones de disponibilité différentes, et au moins 3 adresses IP disponibles, avant de continuer. Pour plus d’informations sur la création de sous-réseaux dans un VPC Amazon, consultez Créer un sous-réseau dans le Guide de l’utilisateur du cloud privé virtuel Amazon. Pour plus d’informations sur les adresses IP dans un VPC Amazon, consultez Adressage IP de vos VPC et sous-réseaux.
Pour configurer avec les paramètres par défaut :
Connectez-vous à la console Amazon Redshift Console de gestion AWS et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
Choisissez Profitez de l’essai gratuit de Redshift sans serveur.
-
Sous Configuration, choisissez Utiliser les paramètres par défaut. Amazon Redshift sans serveur crée un espace de noms par défaut avec un groupe de travail par défaut associé à cet espace de noms. Choisissez Save configuration.
Note
Un espace de noms est une collection d’objets de base de données et d’utilisateurs. Les espaces de noms regroupent toutes les ressources que vous utilisez dans Redshift sans serveur, telles que les schémas, les tables, les utilisateurs, les unités de partage des données et les instantanés.
Un groupe de travail est une collection de ressources informatiques. Les groupes de travail hébergent des ressources de calcul que Redshift sans serveur utilise pour exécuter des tâches de calcul.
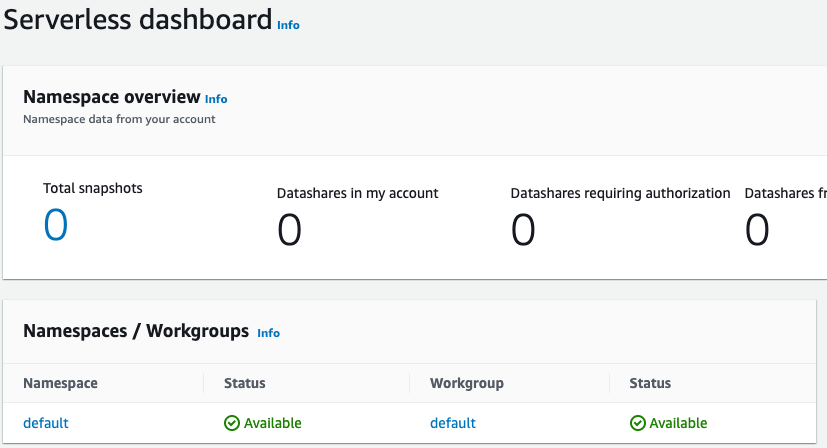
La capture d'écran suivante présente les paramètres par défaut d'Amazon Redshift sans serveur.

-
Une fois la configuration terminée, cliquez sur Continue (Continuer) pour accéder à votre Serverless dashboard (Tableau de bord sans serveur). Vous pouvez constater que le groupe de travail et l'espace de noms sans serveur sont disponibles.
Note
Si Redshift sans serveur ne parvient pas à créer le groupe de travail, vous pouvez effectuer les opérations suivantes :
Corrigez les erreurs signalées par Redshift sans serveur, telles que le nombre insuffisant de sous-réseaux dans votre VPC Amazon.
Supprimez l’espace de noms en choisissant default-namespace dans le tableau de bord Redshift sans serveur, puis en choisissant Actions, Supprimer l’espace de noms. La suppression d’un espace de noms dure plusieurs minutes.
Lorsque vous ouvrez à nouveau la console Redshift sans serveur, l’écran de bienvenue apparaît.
Chargement d’exemples de données
Maintenant que vous avez configuré votre entrepôt des données avec Amazon Redshift sans serveur, vous pouvez utiliser l'éditeur de requête d'Amazon Redshift v2 pour charger des exemples de données.
-
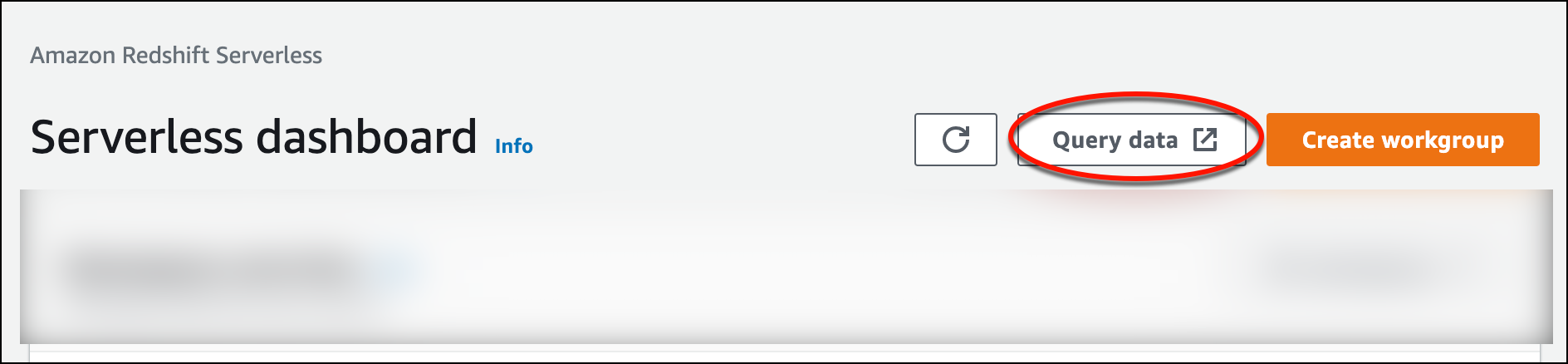
Pour lancer l'éditeur de requête v2 à partir de la console Amazon Redshift sans serveur, choisissez Interroger les données. Lorsque vous appelez l'éditeur de requête v2 à partir de la console Amazon Redshift Serverless, un nouvel onglet du navigateur s'ouvre avec l'éditeur de requête. L'éditeur de requête v2 se connecte depuis votre ordinateur client à l'environnement Amazon Redshift sans serveur.
-
Pour ce guide, vous allez utiliser votre compte AWS administrateur et le compte par défaut AWS KMS key. Pour plus d’informations sur la configuration de l’éditeur de requête v2, notamment sur les autorisations nécessaires, voir Configuration de votre Compte AWS dans le Guide de gestion Amazon Redshift. Pour plus d'informations sur la configuration d'Amazon Redshift pour utiliser une clé gérée par le client ou pour modifier la clé KMS utilisée par Amazon Redshift, consultez Modification de AWS KMS la clé d'un espace de noms.
-
Pour vous connecter à un groupe de travail, sélectionnez le nom du groupe de travail dans le panneau d’arborescence.
-
Lorsque vous vous connectez à un nouveau groupe de travail pour la première fois dans l'éditeur de requête v2, vous devez sélectionner le type d'authentification à utiliser pour vous connecter au groupe de travail. Pour ce guide, laissez l'option Utilisateur fédéré sélectionnée et choisissez Créer une connexion.
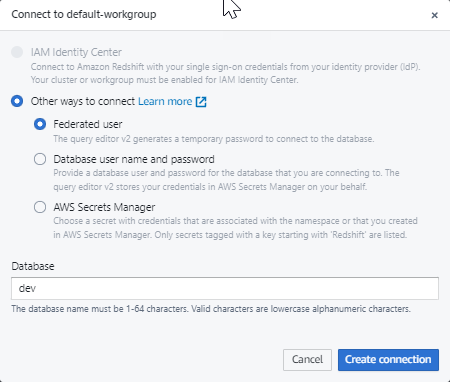
Une fois connecté, vous pouvez choisir de charger des exemples de données à partir d'Amazon Redshift sans serveur ou d'un compartiment Amazon S3.
-
Dans le groupe de travail par défaut Amazon Redshift sans serveur, développez la base de données sample_data_dev. Il existe trois schémas types correspondant à trois jeux de données types que vous pouvez charger dans la base de données Amazon Redshift sans serveur. Choisissez l'exemple de jeu de données que vous souhaitez charger, puis sélectionnez Ouvrir les exemples de blocs-notes.
Note
Un bloc-notes SQL est un conteneur de cellules SQL et Markdown. Vous pouvez utiliser des blocs-notes pour organiser, annoter et partager plusieurs commandes SQL dans un même document.
-
Lorsque vous chargez des données pour la première fois, l'éditeur de requête v2 vous invite à créer une base de données d'exemple. Choisissez Créer.
Exécution d’exemples de requêtes
Après avoir configuré Amazon Redshift sans serveur, vous pouvez commencer à utiliser un exemple de jeu de données dans Amazon Redshift sans serveur. Amazon Redshift sans serveur charge automatiquement le jeu de données d'exemple, tel que le jeu de données tickit, et vous pouvez immédiatement interroger les données.
-
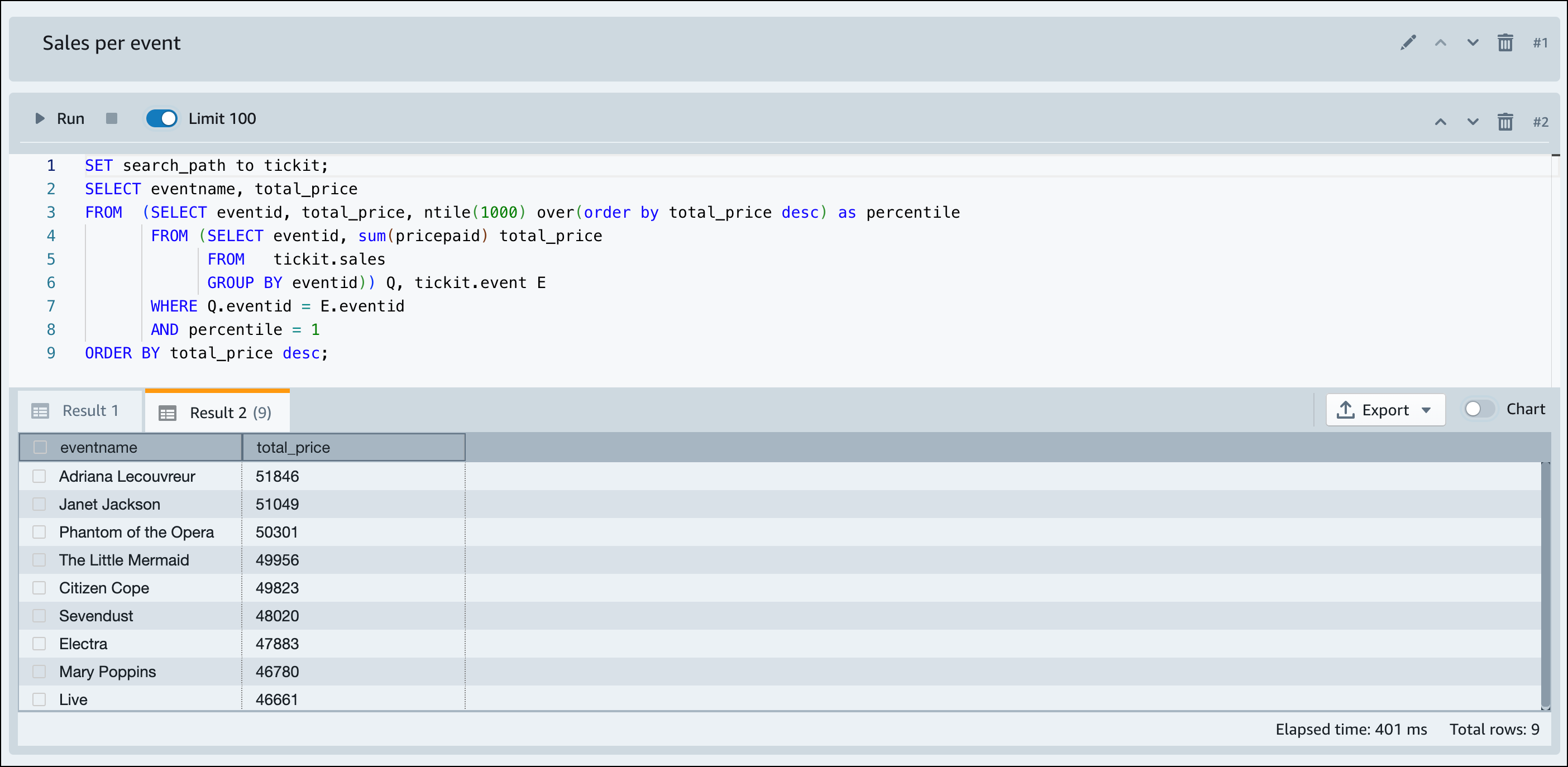
Une fois qu'Amazon Redshift sans serveur a fini de charger les exemples de données, tous les exemples de requêtes sont chargés dans l'éditeur. Vous pouvez choisir Exécuter tout pour exécuter toutes les requêtes des exemples de blocs-notes.
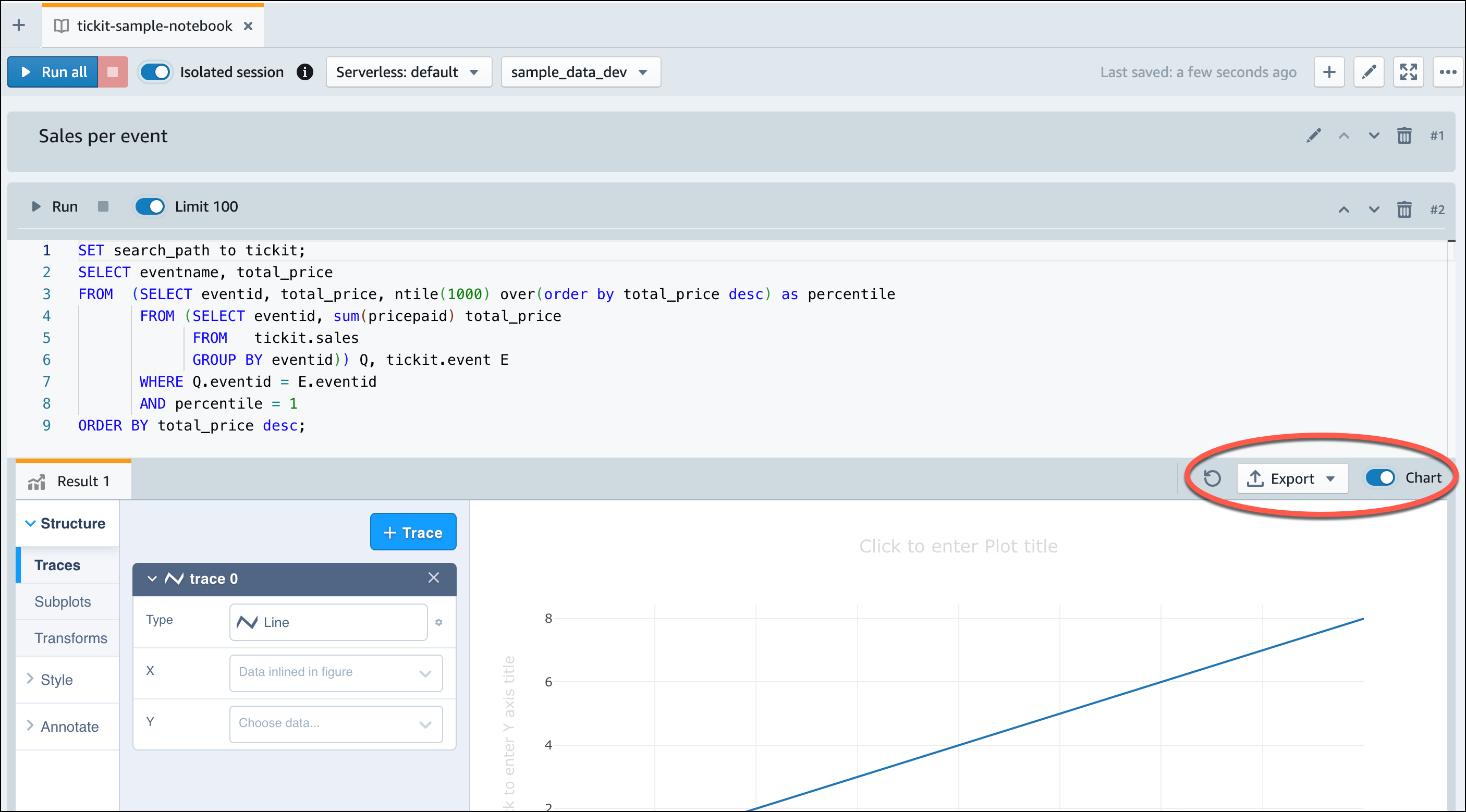
Vous pouvez également exporter les résultats dans un fichier JSON ou CSV ou les afficher dans un graphique.
Vous pouvez également charger des données à partir d'un compartiment Amazon S3. Pour en savoir plus, consultez Chargement de données depuis Amazon S3.
Chargement de données depuis Amazon S3
Après avoir créé votre entrepôt des données, vous pouvez charger des données depuis Amazon S3.
À ce stade, vous disposez d'une base de données nommée dev. Ensuite, créez des tables dans la base de données, chargez des données dans les tables et essayez d'exécuter une requête. Pour plus de commodité, les exemples de données que vous chargez sont disponibles dans un compartiment Amazon S3.
-
Avant de pouvoir charger des données depuis Amazon S3, vous devez d'abord créer un rôle IAM avec les autorisations nécessaires et l'attacher à votre espace de noms sans serveur. Pour ce faire, revenez à la console Redshift sans serveur et choisissez Configuration d’espace de noms. Choisissez votre espace de noms dans le menu de navigation, puis choisissez Sécurité et chiffrement. Choisissez ensuite Gérer les rôles IAM.
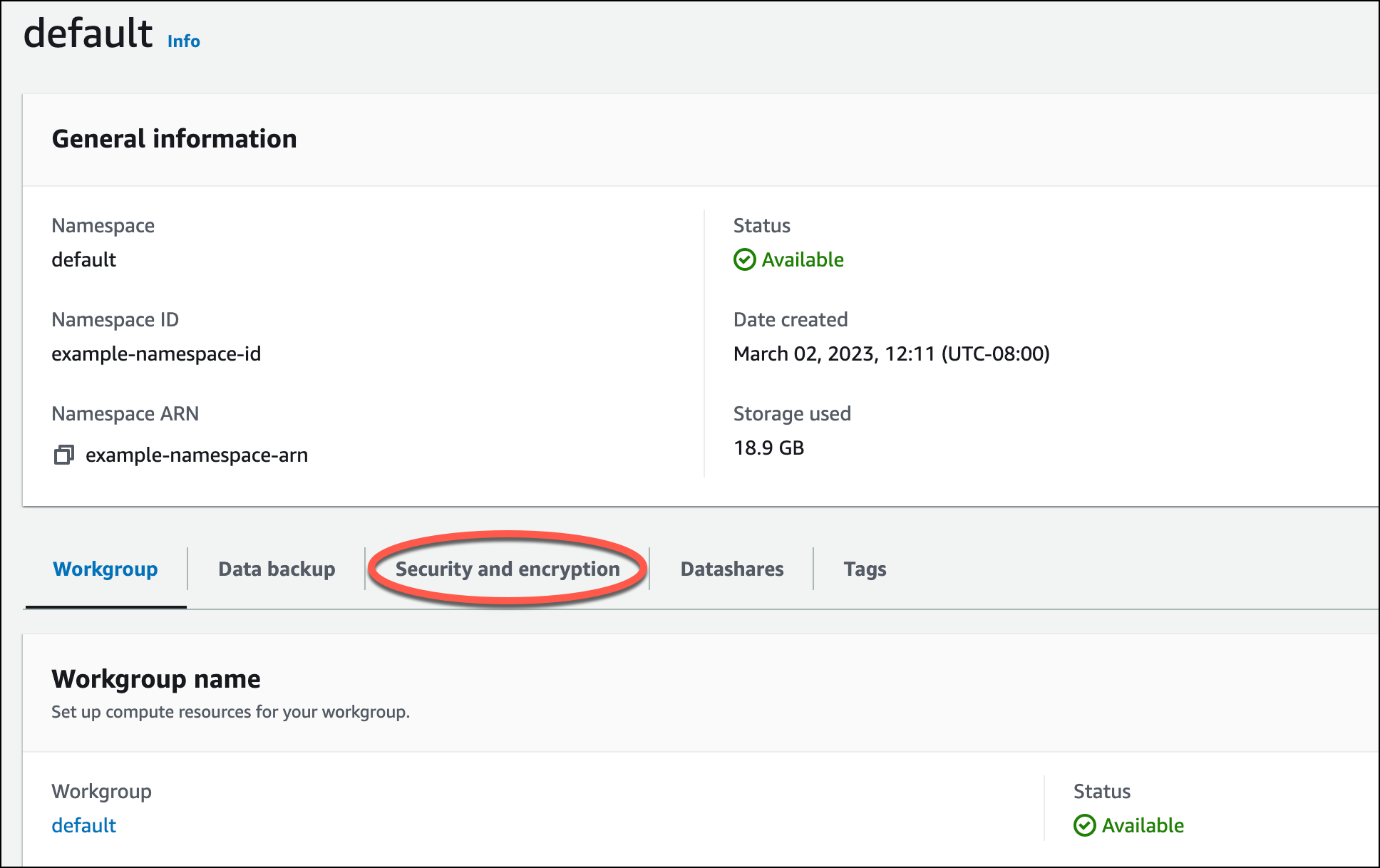
Développez le menu Gérer les rôles IAM et choisissez Créer un rôle IAM.
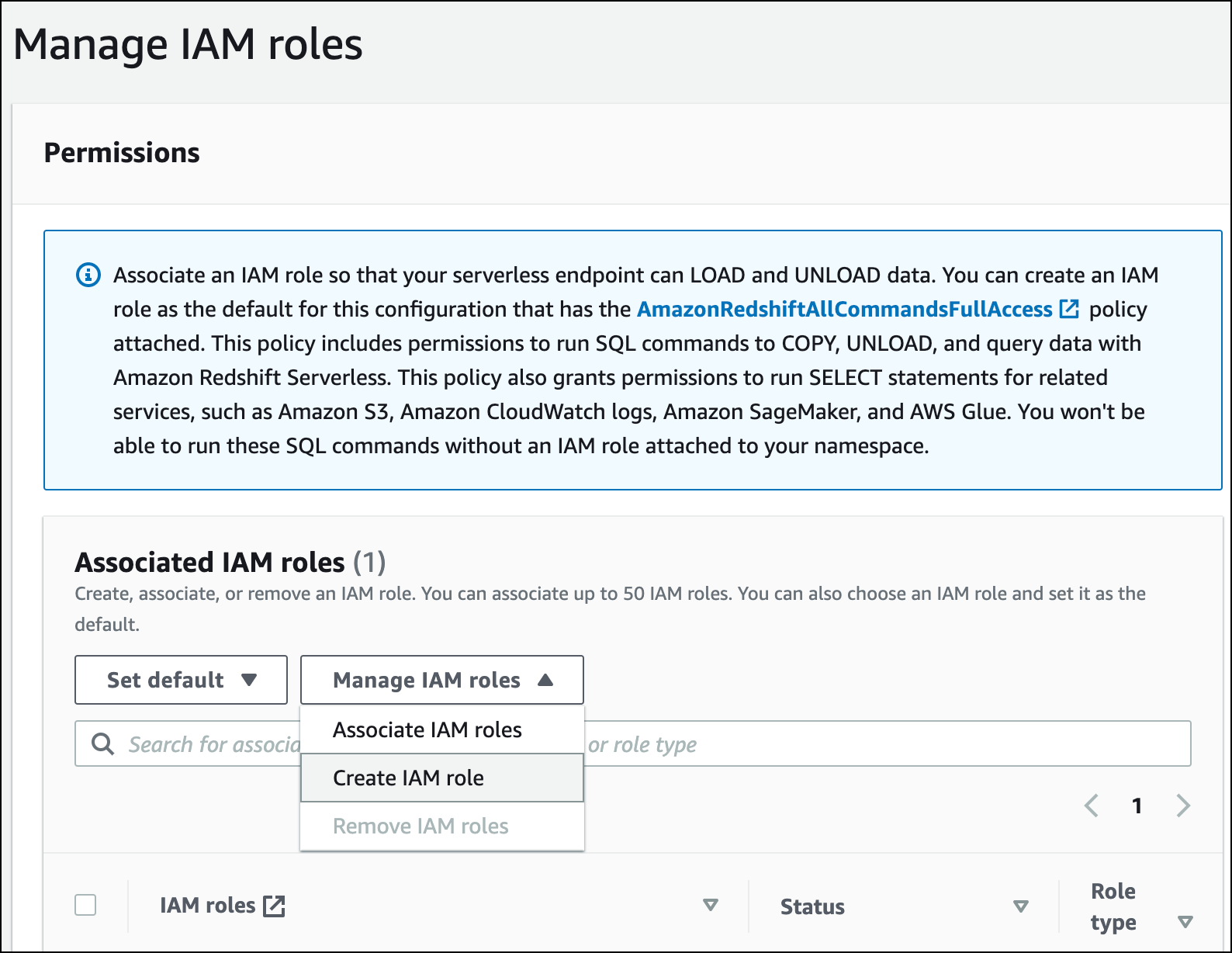
Choisissez le niveau d'accès au compartiment S3 que vous souhaitez accorder à ce rôle, et sélectionnez Créer un rôle IAM par défaut.
-
Sélectionnez Enregistrer les modifications. Vous pouvez désormais charger des exemples de données à partir d'Amazon S3.
Les étapes suivantes utilisent des données au sein d'un compartiment S3 public d'Amazon Redshift, mais vous pouvez reproduire les mêmes étapes en utilisant votre propre compartiment S3 et vos commandes SQL.
Charger un exemple de données à partir d'Amazon S3
-
Dans l'éditeur de requête v2, choisissez
 Ajouter, puis Bloc-notes pour créer un nouveau bloc-notes SQL.
Ajouter, puis Bloc-notes pour créer un nouveau bloc-notes SQL.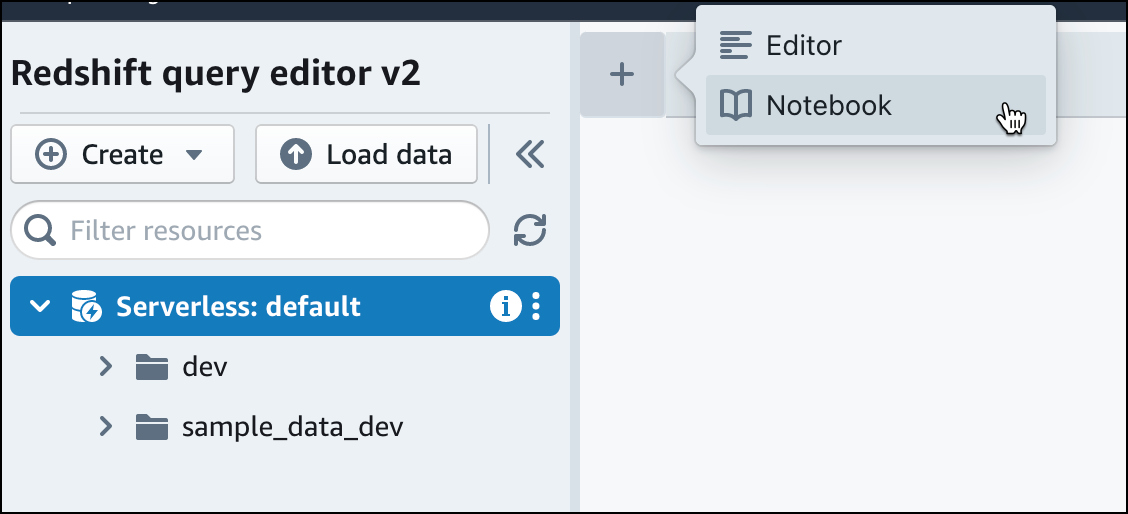
-
Passez à la base de données
dev.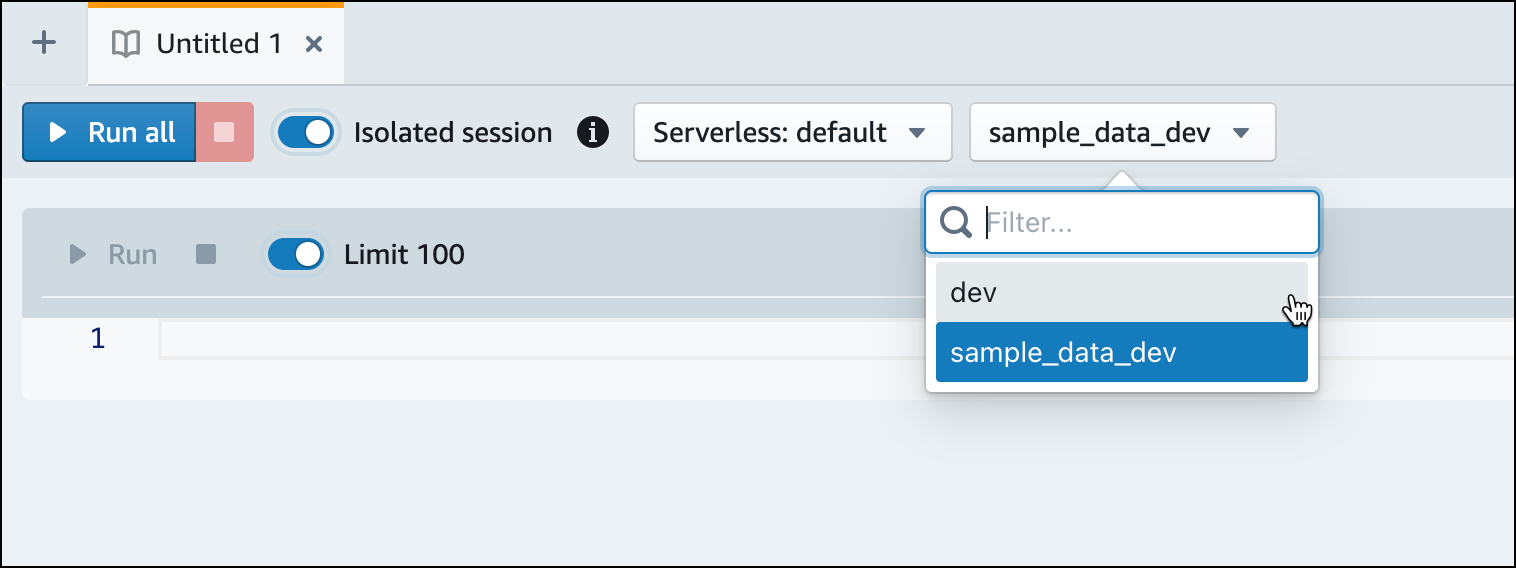
-
Créez des tables.
Si vous utilisez l'éditeur de requête v2, copiez et exécutez les instructions create table suivantes pour créer des tables dans la base de données
dev. Pour plus d’informations sur la syntaxe, consultez CREATE TABLE dans le Guide du développeur de base de données Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
Dans l'éditeur de requête v2, créez une nouvelle cellule SQL dans votre bloc-notes.
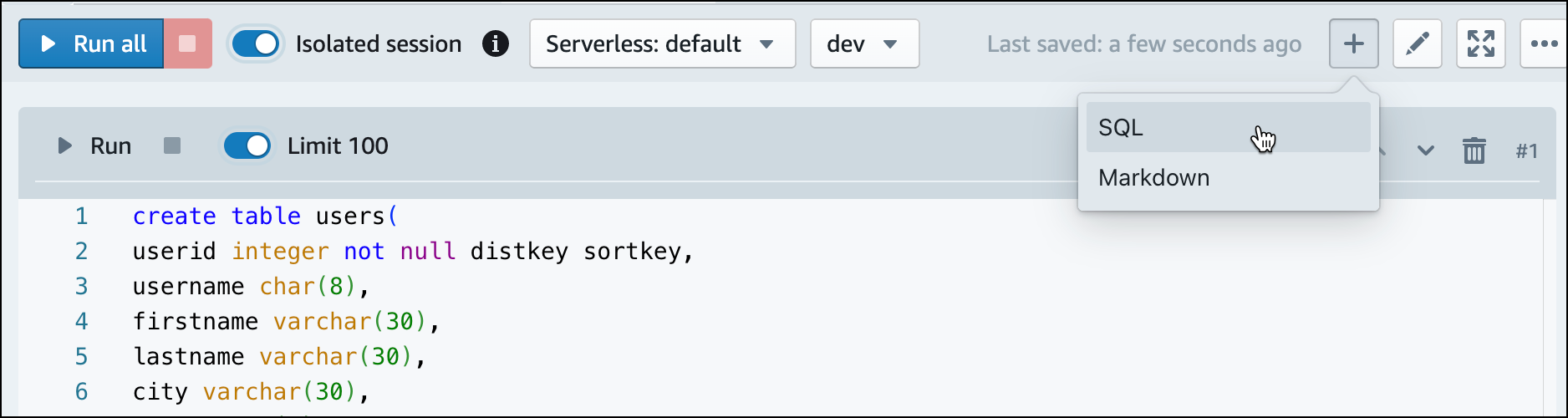
-
Utilisez maintenant la commande COPY dans l'éditeur de requête v2 pour charger de grands jeux de données depuis Amazon S3 ou Amazon DynamoDB dans Amazon Redshift. Pour plus d’informations sur la syntaxe COPY, consultez COPY dans le Guide du développeur de la base de données Amazon Redshift.
Vous pouvez exécuter la commande COPY avec quelques exemples de données disponibles dans un compartiment S3 public. Exécutez les commandes SQL suivantes dans l'éditeur de requête v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Après avoir chargé les données, créez une autre cellule SQL dans votre bloc-notes et essayez quelques exemples de requêtes. Pour plus d’informations sur l’utilisation de l’instruction SELECT, consultez SELECT dans le Guide du développeur Amazon Redshift. Pour comprendre la structure et les schémas des données de l'échantillon, explorez l'éditeur de requête v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Maintenant que vous avez chargé des données et exécuté quelques exemples de requêtes, vous pouvez explorer d'autres domaines d'Amazon Redshift sans serveur. Consultez la liste suivante pour en savoir plus sur la manière dont vous pouvez utiliser Amazon Redshift sans serveur.
-
Vous pouvez charger des données à partir d'un compartiment Amazon S3. Pour plus d'informations, consultez Chargement des données à partir d'Amazon S3.
-
Vous pouvez utiliser l'éditeur de requête v2 pour charger des données à partir d'un fichier local séparé par des caractères et d'une taille inférieure à 5 Mo. Pour plus d'informations, consultez Chargement de données à partir d'un fichier local.
-
Vous pouvez vous connecter à Amazon Redshift sans serveur avec des outils SQL tiers grâce au pilote JDBC et ODBC. Pour plus d'informations, consultez Connexion à Amazon Redshift sans serveur.
-
Vous pouvez également utiliser l’API de données Amazon Redshift pour vous connecter à Amazon Redshift sans serveur. Pour plus d'informations, consultez Utilisation de l'API de données Amazon Redshift
. -
Vous pouvez utiliser vos données dans Amazon Redshift sans serveur avec Redshift ML pour créer des modèles de machine learning avec la commande CREATE MODEL. Consultez Tutoriel : création de modèles de désabonnement des clients pour apprendre à élaborer un modèle ML Redshift.
-
Vous pouvez interroger les données d'un lac de données Amazon S3 sans charger de données dans Amazon Redshift sans serveur. Pour plus d'informations, consultez Interrogation d'un lac de données.
