Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèle de moniteur FAQs
Reportez-vous à ce qui suit FAQs pour plus d'informations sur Amazon SageMaker Model Monitor.
Q : Comment Model Monitor et SageMaker Clarify aident-ils les clients à surveiller le comportement des modèles ?
Les clients peuvent surveiller le comportement du modèle selon quatre dimensions : qualité des données, qualité du modèle, dérive du biais et dérive de l'attribution des fonctionnalités via Amazon SageMaker Model Monitor et SageMaker Clarify. Model Monitor
Q : Que se passe-t-il en arrière-plan quand Sagemaker Model Monitor est activé ?
Amazon SageMaker Model Monitor automatise la surveillance des modèles, ce qui évite de devoir surveiller les modèles manuellement ou de créer des outils supplémentaires. Afin d'automatiser le processus, Model Monitor vous permet de créer un ensemble de statistiques et de contraintes de référence en utilisant les données avec lesquelles votre modèle a été entraîné, puis de définir une planification pour surveiller les prédictions effectuées sur votre point de terminaison. Model Monitor utilise des règles pour détecter les écarts dans vos modèles et vous en avertit le cas échéant. Les étapes suivantes décrivent ce qui se passe lorsque vous activez la surveillance des modèles :
-
Activer la surveillance des modèles : pour un point de terminaison en temps réel, vous devez permettre au point de terminaison de capturer les données issues des demandes entrantes dans un modèle ML déployé et les prédictions de modèle résultantes. Pour une tâche de transformation par lots, activez la capture des données des entrées et des sorties de transformation par lots.
-
Tâche de traitement de référence : vous créez ensuite une référence à partir du jeu de données qui a été utilisé pour entraîner le modèle. La référence calcule les métriques et suggère des contraintes pour les métriques. Par exemple, le score de rappel du modèle ne doit pas régresser et descendre en dessous de 0,571, ou le score de précision ne doit pas descendre en dessous de 1,0. Les prédictions en temps réel ou par lots réalisées à partir de votre modèle sont comparées aux contraintes et sont signalées comme des violations si elles se situent hors des valeurs contraintes.
-
Tâche de surveillance : vous créez ensuite une planification de surveillance spécifiant les données à collecter, la fréquence de collecte, la manière de les analyser et les rapports à produire.
-
Job de fusion : cela ne s'applique que si vous utilisez Amazon SageMaker Ground Truth. Model Monitor compare les prédictions réalisées par votre modèle aux étiquettes Ground Truth afin de mesurer la qualité du modèle. Pour que cela fonctionne, vous étiquetez périodiquement les données capturées par votre point de terminaison ou votre tâche de transformation par lots et les téléchargez dans Amazon S3.
Une fois les étiquettes Ground Truth créées et téléchargées, incluez leur emplacement comme paramètre dans la tâche de surveillance que vous créez.
Lorsque vous utilisez Model Monitor pour surveiller une tâche de transformation par lots à la place d'un point de terminaison en temps réel, au lieu de recevoir des demandes à un point de terminaison et de suivre les prédictions, Model Monitor surveille les entrées et les sorties d'inférence. Dans une planification de Model Monitor, le client fournit le nombre et le type d'instances à utiliser dans le cadre de la tâche de traitement. Ces ressources restent réservées jusqu'à ce que la planification soit supprimée, quel que soit le statut de l'exécution en cours.
Q : Qu'est-ce que la capture de données, pourquoi est-elle requise et comment puis-je l'activer ?
Pour journaliser les entrées au niveau du point de terminaison et les sorties d'inférence à partir du modèle déployé sur Amazon S3, vous pouvez activer une fonctionnalité appelée Capture de données. Pour plus de détails sur la façon de l'activer pour un point de terminaison en temps réel et une tâche de transformation par lots, consultez Capture des données à partir d'un point de terminaison en temps réel et Capture des données à partir d'une tâche de transformation par lots.
Q : L'activation de la capture de données a-t-elle un impact sur les performances d'un point de terminaison en temps réel ?
La capture des données s'effectue de manière asynchrone sans impact sur le trafic de production. Une fois que vous avez activé la capture des données, la charge utile de demande et de réponse, ainsi que certaines métadonnées supplémentaires sont enregistrées à l'emplacement Amazon S3 que vous avez spécifié dans DataCaptureConfig. Notez qu'il peut y avoir un retard dans la propagation des données capturées vers Amazon S3.
Vous pouvez également afficher les données capturées en répertoriant les fichiers de capture de données stockés dans Amazon S3. Le format du chemin d'accès Amazon S3 est : s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl. La capture de données Amazon S3 doit avoir lieu dans la même région que la planification Model Monitor. Vous devez également vous assurer que les noms des colonnes du jeu de données de référence comportent uniquement des lettres minuscules et un trait de soulignement (_) comme seul séparateur.
Q : Pourquoi Ground Truth est-il requis pour la surveillance des modèles ?
Les étiquettes Ground Truth sont requises par les fonctionnalités suivantes de Model Monitor :
-
La surveillance de la qualité du modèle compare les prédictions réalisées par votre modèle aux étiquettes Ground Truth afin de mesurer la qualité du modèle.
-
La surveillance des biais du modèle surveille les prédictions pour détecter les biais. Un biais peut être introduit dans des modèles ML déployés lorsque les données utilisées pour l'entraînement diffèrent des données utilisées pour générer des prédictions. Cela est particulièrement vrai si les données utilisées pour l'entraînement changent au fil du temps (par exemple, des taux hypothécaires variables). Dans ce cas, la prédiction du modèle n'est pas très précise, sauf si le modèle est réentraîné avec des données mises à jour. Par exemple, un modèle de prédiction des prix de l'immobilier peut être biaisé si les taux hypothécaires utilisés pour entraîner le modèle diffèrent du taux hypothécaire réel le plus récent.
Q : Pour les clients qui utilisent Ground Truth pour l'étiquetage, quelles sont les mesures que je peux prendre pour surveiller la qualité du modèle ?
La surveillance de la qualité du modèle compare les prédictions réalisées par votre modèle aux étiquettes Ground Truth afin de mesurer la qualité du modèle. Pour que cela fonctionne, vous étiquetez périodiquement les données capturées par votre point de terminaison ou votre tâche de transformation par lots et les téléchargez dans Amazon S3. Outre les captures, l'exécution de la surveillance des biais du modèle nécessite également des données Ground Truth. Dans des cas d'utilisation réels, les données Ground Truth doivent être régulièrement collectées et chargées dans l'emplacement Amazon S3 désigné. Pour que les étiquettes Ground Truth correspondent aux données de prédiction capturées, chaque enregistrement du jeu de données doit avoir un identifiant unique. Pour la structure de chaque enregistrement des données Ground Truth, consultez Ingestion d'étiquettes Ground Truth et fusion avec des prédictions.
L'exemple de code suivant peut être utilisé pour générer des données Ground Truth artificielles pour un jeu de données tabulaire.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
L'exemple de code suivant montre comment générer du trafic artificiel à envoyer au point de terminaison de modèle. Notez l'attribut inferenceId utilisé ci-dessus pour invoquer. S'il est présent, il est utilisé pour joindre avec les données Ground Truth (dans le cas contraire, eventId est utilisé).
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
Vous devez charger les données Ground Truth dans un compartiment Amazon S3 ayant le même format de chemin que les données capturées, qui ont le format suivant : s3://<bucket>/<prefix>/yyyy/mm/dd/hh
Note
La date de ce chemin est la date à laquelle l'étiquette Ground Truth est collectée. Il n'est pas nécessaire qu'elle corresponde à la date où l'inférence a été générée.
Q : Comment les clients peuvent-ils personnaliser les planifications de surveillance ?
En plus d'utiliser les mécanismes de surveillance intégrés, vous pouvez créer vos propres planifications et procédures de surveillance personnalisées à l'aide de scripts de prétraitement et de post-traitement, ou en utilisant ou créant votre propre conteneur. Il est important de noter que les scripts de prétraitement et de post-traitement ne fonctionnent qu'avec des tâches de qualité de modèle et de données.
Amazon SageMaker AI vous permet de surveiller et d'évaluer les données observées par les points de terminaison du modèle. Pour cela, vous devez créer une base de référence vous permettant de comparer le trafic en temps réel. Une fois qu'une base de référence est prête, configurez une planification à évaluer et à comparer en permanence à la base de référence. Lors de la création d'une planification, vous pouvez fournir le script de prétraitement et de post-traitement.
L'exemple suivant montre comment personnaliser des planifications de surveillance à l'aide de scripts de prétraitement et de post-traitement.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
Q : Quels sont les scénarios ou les cas d'utilisation dans lesquels je peux tirer parti d'un script de prétraitement ?
Vous pouvez utiliser des scripts de prétraitement lorsque vous devez transformer les entrées de votre moniteur de modèles. Prenons les exemples de scénarios suivants :
-
Script de prétraitement pour la transformation des données
Supposons que la sortie de votre modèle soit un tableau :
[1.0, 2.1]. Le conteneur Model Monitor fonctionne uniquement avec des structures JSON tabulaires ou mises à plat, telles que{“prediction0”: 1.0, “prediction1” : 2.1}. Vous pouvez utiliser un script de prétraitement comme l'exemple suivant pour transformer le tableau en structure JSON correcte.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Exclusion de certains enregistrements des calculs de métriques de Model Monitor
Supposons que votre modèle comporte des fonctionnalités facultatives et que vous utilisiez
-1pour indiquer que la fonctionnalité facultative présente une valeur manquante. Si vous disposez d'une surveillance de qualité des données, vous pouvez le supprimer-1du tableau des valeurs d'entrée afin qu'il ne soit pas inclus dans les calculs métriques de la surveillance. Vous pouvez utiliser un script comme celui-ci pour supprimer ces valeurs.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Application d'une stratégie d'échantillonnage personnalisée
Vous pouvez également appliquer une stratégie d'échantillonnage personnalisée dans votre script de prétraitement. Pour ce faire, configurez le conteneur prédéfini de Model Monitor de manière à ignorer un pourcentage des enregistrements en fonction de la fréquence d'échantillonnage que vous avez spécifiée. Dans l'exemple suivant, le gestionnaire échantillonne 10 % des enregistrements en renvoyant l'enregistrement dans 10 % des appels du gestionnaire et en renvoyant une liste vide autrement.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Utilisation d'une journalisation personnalisée
Vous pouvez enregistrer toutes les informations dont vous avez besoin depuis votre script sur Amazon CloudWatch. Cela peut être utile lors du débogage de votre script de prétraitement en cas d'erreur. L'exemple suivant montre comment vous pouvez utiliser l'
preprocess_handlerinterface pour vous connecter à CloudWatch.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
Note
Lorsque le script de prétraitement est exécuté sur des données de transformation par lots, le type d'entrée n'est pas toujours l'objet CapturedData. Pour des données CSV, le type est une chaîne. Pour des données JSON, le type est un dictionnaire Python.
Q : Quand puis-je utiliser un script de post-traitement ?
Vous pouvez utiliser un script de post-traitement en tant qu'extension après une exécution de surveillance réussie. L'exemple suivant est simple, mais vous pouvez exécuter ou appeler n'importe quelle fonction métier dont vous avez besoin après une exécution de surveillance réussie.
def postprocess_handler(): print("Hello from the post-processing script!")
Q : Quand dois-je envisager d'apporter mon propre conteneur pour la surveillance des modèles ?
SageMaker L'IA fournit un conteneur prédéfini pour analyser les données capturées à partir de points de terminaison ou pour les tâches de transformation par lots pour les ensembles de données tabulaires. Toutefois, dans certains scénarios, vous souhaiterez peut-être créer votre propre conteneur. Réfléchissez aux scénarios suivants :
-
Des exigences réglementaires et de conformité vous obligent à n'utiliser que les conteneurs créés et gérés en interne dans votre organisation.
-
Si vous souhaitez inclure quelques bibliothèques tierces, vous pouvez placer un
requirements.txtfichier dans un répertoire local et le référencer à l'aide dusource_dirparamètre de l'estimateur SageMaker AI, qui permet l'installation de bibliothèques au moment de l'exécution. Toutefois, si vous avez de nombreuses bibliothèques ou dépendances qui augmentent le temps d'installation lors de l'exécution de la tâche d'entraînement, vous souhaiterez peut-être tirer parti du BYOC. -
Votre environnement n'impose aucune connexion Internet (ni Silo), ce qui empêche le téléchargement de packages.
-
Vous souhaitez surveiller des données dans des formats autres que tabulaires, tels que les cas d'utilisation de modèles NLP ou CV.
-
Vous avez besoin de métriques de surveillance supplémentaires par rapport à celles prises en charge par Model Monitor.
Q : J'ai des modèles NLP et CV. Comment puis-je les surveiller pour détecter la dérive des données ?
Le conteneur SageMaker prédéfini d'Amazon AI prend en charge les ensembles de données tabulaires. Si vous souhaitez surveiller les modèles NLP et CV, vous pouvez apporter votre propre conteneur en tirant parti des points d'extension fournis par Model Monitor. Pour plus de détails sur les exigences, consultez Apport de vos propres conteneurs. Voici quelques exemples supplémentaires :
-
Pour une explication détaillée de l'utilisation de Model Monitor pour un cas d'utilisation de la vision par ordinateur, consultez Détection et analyse de prédictions incorrectes
(langue française non garantie). -
Pour un scénario dans lequel Model Monitor peut être utilisé pour un cas d'utilisation du NLP, voir Détecter la dérive des données NLP à l'aide d'Amazon SageMaker Model Monitor personnalisé
.
Q : Je souhaite supprimer le point de terminaison du modèle pour lequel Model Monitor a été activé, mais je ne peux pas le faire car la planification de surveillance est toujours active. Que dois-je faire ?
Si vous souhaitez supprimer un point de terminaison d'inférence hébergé dans SageMaker AI sur lequel Model Monitor est activé, vous devez d'abord supprimer le calendrier de surveillance du modèle (à l'aide de la DeleteMonitoringSchedule CLI ou de l'API). Ensuite, supprimez le point de terminaison.
Q : Est-ce que SageMaker Model Monitor calcule les mesures et les statistiques à saisir ?
Model Monitor calcule des métriques et des statistiques pour la sortie, et non pour l'entrée.
Q : SageMaker Model Monitor prend-il en charge les terminaux multimodèles ?
Non, Model Monitor prend en charge uniquement les points de terminaison qui hébergent un seul modèle, et non pas la surveillance des points de terminaison multimodèles.
Q : SageMaker Model Monitor fournit-il des données de surveillance sur les conteneurs individuels d'un pipeline d'inférence ?
Model Monitor prend en charge la surveillance des pipelines d'inférence, mais la capture et l'analyse des données sont effectuées pour l'ensemble du pipeline, pas pour ses conteneurs individuels.
Q : Que puis-je faire pour éviter tout impact sur les demandes d'inférence lorsque la capture de données est configurée ?
Pour éviter tout impact sur les requêtes d'inférence, Data Capture cesse de capturer les requêtes à des niveaux élevés d'utilisation du disque. Nous vous recommandons de maintenir l'utilisation du disque en dessous de 75 % pour que la capture des données continue de capturer les requêtes.
Q : La capture de données Amazon S3 peut-elle se faire dans une AWS région différente de celle dans laquelle le calendrier de surveillance a été configuré ?
Non, la capture de données Amazon S3 doit avoir lieu dans la même région que la planification de surveillance.
Q : Qu'est-ce qu'une base de référence et comment en créer une ? Puis-je créer une base de référence personnalisée ?
Une base de référence sert de référence pour comparer les prédictions en temps réel ou par lots issues du modèle. Elle calcule des statistiques et des métriques ainsi que des contraintes sur ces éléments. Au cours de la surveillance, tous ces éléments sont utilisés conjointement pour identifier les violations.
Pour utiliser la solution par défaut d'Amazon SageMaker Model Monitor, vous pouvez utiliser le SDK Amazon SageMaker Python
Le résultat d'une tâche de référence est constitué de deux fichiers : statistics.json et constraints.json. Le schéma des statistiques et le schéma des contraintes contiennent les schémas des fichiers respectifs. Vous pouvez passer en revue les contraintes générées et les modifier si nécessaire avant de les utiliser pour la surveillance. Sur la base de votre compréhension du domaine et du problème métier, vous pouvez rendre une contrainte plus agressive ou l'assouplir pour contrôler le nombre et la nature des violations.
Q : Quelles sont les directives pour créer un jeu de données de référence ?
La principale exigence pour tout type de surveillance est de disposer d'un jeu de données de référence utilisé pour calculer les métriques et les contraintes. Il s'agit généralement du jeu de données d'entraînement utilisé par le modèle, mais dans certains cas, vous pouvez choisir d'utiliser un autre jeu de données de référence.
Les noms des colonnes du jeu de données de référence doivent être compatibles avec Spark. Afin de maintenir une compatibilité maximale entre Spark, CSV, JSON et parquet, il est conseillé de n'utiliser que des lettres minuscules et d'utiliser uniquement _ comme séparateur. Les caractères spéciaux, y compris “ ”, peuvent poser des problèmes.
Q : Quels sont les paramètres StartTimeOffset et EndTimeOffset, et quand sont-ils utilisés ?
Lorsque Amazon SageMaker Ground Truth est requis pour surveiller des tâches telles que la qualité des modèles, vous devez vous assurer qu'une tâche de surveillance utilise uniquement des données pour lesquelles Ground Truth est disponible. Les end_time_offset paramètres start_time_offset et de EndpointInputstart_time_offset et end_time_offset. Ces paramètres doivent être spécifiés dans le format de durée ISO 8601
-
Si vos résultats Ground Truth arrivent 3 jours après la réalisation des prédictions, définissez
start_time_offset="-P3D"etend_time_offset="-P1D", soit 3 jours et 1 jour respectivement. -
Si les résultats Ground Truth arrivent 6 heures après les prédictions et que vous avez une planification horaire, définissez
start_time_offset="-PT6H"etend_time_offset="-PT1H"sur 6 heures et 1 heure.
Q : Puis-je exécuter des tâches de surveillance « à la demande » ?
Oui, vous pouvez exécuter des tâches de surveillance « à la demande » en exécutant une tâche de SageMaker traitement. Pour Batch Transform, Pipelines propose un pipeline MonitorBatchTransformStep
Q : Comment configurer Model Monitor ?
Vous pouvez configurer Model Monitor de la manière suivante :
-
SDK Amazon SageMaker AI Python
— Il existe un module Model Monitor qui contient des classes et des fonctions qui aident à suggérer des bases de référence, à créer des calendriers de surveillance, etc. Consultez les exemples de blocs-notes Amazon SageMaker Model Monitor pour obtenir des blocs-notes détaillés qui exploitent le SDK SageMaker AI Python pour configurer Model Monitor. -
Pipelines : les pipelines sont intégrés à Model Monitor via les QualityCheck étapes et ClarifyCheckStep APIs. Vous pouvez créer un pipeline d' SageMaker IA qui contient ces étapes et qui peut être utilisé pour exécuter des tâches de surveillance à la demande chaque fois que le pipeline est exécuté.
-
Amazon SageMaker Studio Classic : vous pouvez créer un calendrier de surveillance de la qualité des données ou des modèles ainsi que des programmes d'explicabilité et de partialité du modèle directement depuis l'interface utilisateur en sélectionnant un point de terminaison dans la liste des points de terminaison des modèles déployés. Des planifications pour d'autres types de surveillance peuvent être créées en sélectionnant l'onglet correspondant dans l'interface utilisateur.
-
SageMaker Tableau de bord du modèle : vous pouvez activer la surveillance sur les terminaux en sélectionnant un modèle qui a été déployé sur un point de terminaison. Dans la capture d'écran suivante de la console SageMaker AI, un modèle nommé
group1a été sélectionné dans la section Modèles du tableau de bord des modèles. Sur cette page, vous pouvez créer une planification de surveillance, et vous pouvez modifier, activer ou désactiver les planifications et les alertes de surveillance existantes. Pour obtenir un guide pas à pas sur la façon d'afficher les alertes et les planifications du moniteur de modèles, consultez Affichage des planifications et des alertes de Model Monitor.
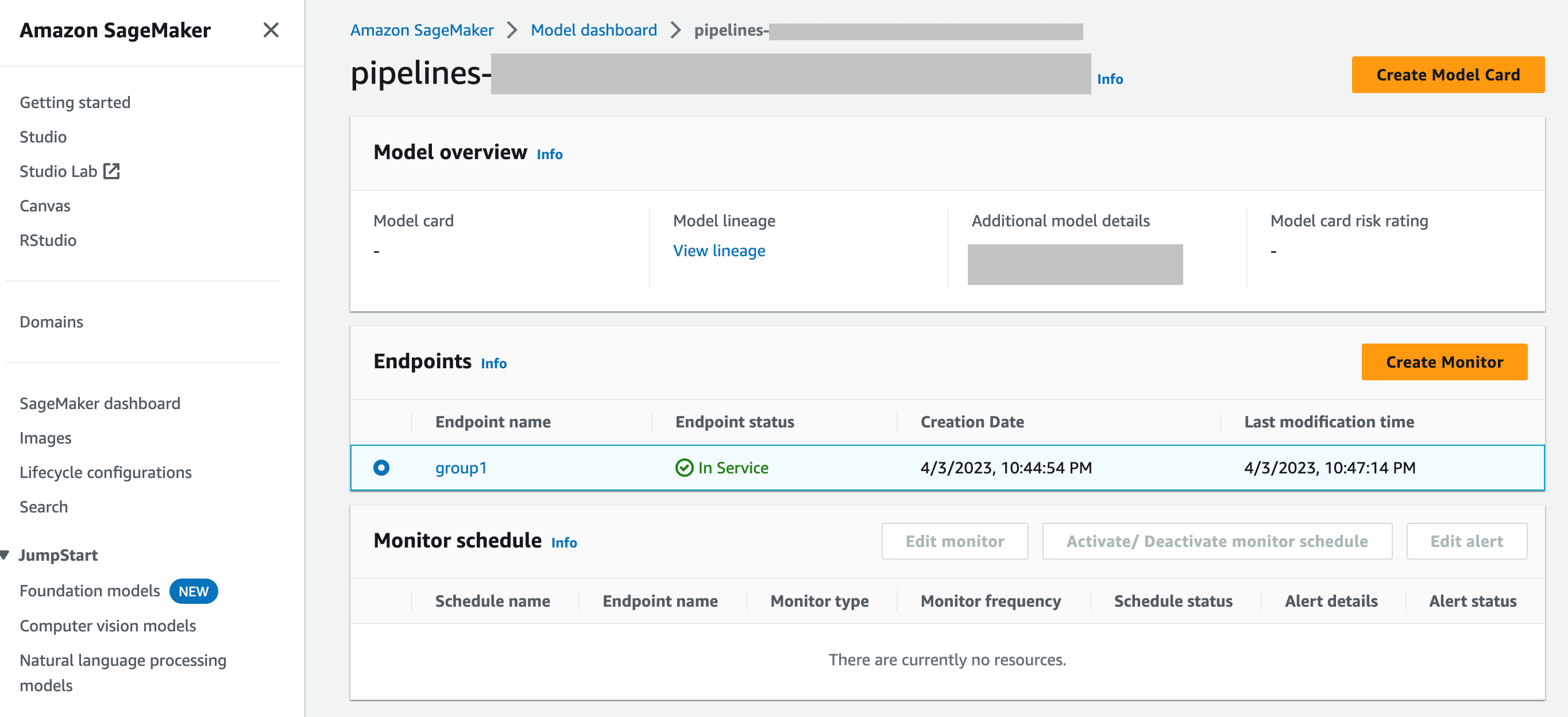
Q : Comment s'intègre Model Monitor au SageMaker Model Dashboard ?
SageMaker Model Dashboard vous offre une surveillance unifiée de tous vos modèles en fournissant des alertes automatisées concernant les écarts par rapport au comportement attendu et en résolvant les problèmes afin d'inspecter les modèles et d'analyser les facteurs influant sur les performances des modèles au fil du temps.
