Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisez l'apprentissage par renforcement avec Amazon SageMaker AI
L’apprentissage par renforcement (RL) combine des domaines tels que l’informatique, les neurosciences et la psychologie pour déterminer comment associer des situations à des actions afin d’optimiser un signal numérique de récompense. Cette notion de signal de récompense en RL découle de la recherche en neurosciences sur la façon dont le cerveau humain prend des décisions sur les actions qui optimisent la récompense et réduisent la punition. Dans la plupart des situations, les humains ne reçoivent pas d’instructions explicites sur les mesures à prendre, mais ils doivent apprendre à la fois quelles actions produisent les récompenses les plus immédiates et comment ces actions influencent les situations et les conséquences futures.
Le problème du RL est formalisé à l’aide des processus décisionnels de Markov (MDP) qui proviennent de la théorie des systèmes dynamiques. Les PDM visent à recueillir des détails de haut niveau sur un problème réel qu’un agent d’apprentissage rencontre sur une certaine période lorsqu’il tente d’atteindre un objectif ultime. L’agent d’apprentissage doit être en mesure de déterminer l’état actuel de son environnement et d’identifier les actions possibles qui affectent l’état actuel de l’agent d’apprentissage. De plus, les objectifs de l’agent d’apprentissage devraient être étroitement liés à l’état de l’environnement. Une solution à un problème formulé de cette manière est connue sous le nom de méthode d’apprentissage par renforcement.
Quelles sont les différences entre les paradigmes d’apprentissage supervisé et non supervisé ?
Le machine learning peut être divisé en trois paradigmes d’apprentissage distincts : supervisé, non supervisé et par renforcement.
Dans le cadre de l’apprentissage supervisé, un superviseur externe fournit un ensemble d’entraînement d’exemples étiquetés. Chaque exemple contient des informations sur une situation, appartient à une catégorie et comporte une étiquette identifiant la catégorie à laquelle il appartient. L’objectif de l’apprentissage supervisé est de généraliser afin de prédire correctement dans des situations qui ne figurent pas dans les données d’entraînement.
En revanche, le RL traite des problèmes interactifs, ce qui rend impossible la collecte de tous les exemples possibles de situations avec des étiquettes correctes qu’un agent pourrait rencontrer. Ce type d’apprentissage est plus prometteur lorsqu’un agent est en mesure de tirer des leçons précises de sa propre expérience et de s’adapter en conséquence.
Dans l’apprentissage non supervisé, un agent apprend en découvrant la structure dans des données non étiquetées. Bien qu’un agent de RL puisse tirer profit de la découverte d’une structure fondée sur ses expériences, le seul but du RL est d’optimiser un signal de récompense.
Pourquoi l’apprentissage à renforcement est-il important ?
Le RL est adapté à la résolution de problèmes d’envergure et complexes tels que la gestion de la chaîne d’approvisionnement, les systèmes de chauffage, ventilation et climatisation, la robotique industrielle, l’intelligence artificielle ludique, les systèmes de dialogue et les véhicules autonomes. Il est possible d’entraîner des systèmes pour prendre des décisions en cas d’incertitude et dans les environnements dynamiques, car les modèles d’apprentissage à renforcement apprennent grâce à un processus continu de récompenses et de punitions pour chaque action effectuée par l’agent.
Processus de décision markovien
L’apprentissage à renforcement est basé sur des modèles appelés processus de décision markoviens. Un processus de décision markovien se compose d’une série d’intervalles de temps. Chaque intervalle de temps se compose des éléments suivants :
- Environnement
-
Définit l’espace dans lequel fonctionne le modèle d’apprentissage à renforcement. Il peut s’agir d’un environnement concret ou d’un simulateur. Par exemple, si vous entraînez un véhicule autonomes physique sur une route physique, il s’agit d’un environnement concret. Si vous entraînez un programme informatique qui modélise un véhicule autonome roulant sur une route, il s’agit d’un simulateur.
- State
-
Spécifie toutes les informations sur l’environnement et les étapes antérieures pertinentes pour l’avenir. Par exemple, dans un modèle de RL dans lequel un robot peut se déplacer dans n’importe quelle direction à n’importe quel intervalle de temps, la position du robot à l’intervalle de temps actuel est l’état, car si nous savons où se trouve le robot est, il n’est pas nécessaire de connaître les étapes pour arriver à ce résultat.
- Action
-
Que fait l’agent. Par exemple, le robot fait un pas en avant.
- Récompense
-
Un nombre qui représente la valeur de l’état résultant de la dernière action effectuée par l’agent. Par exemple, si l’objectif est qu’un robot trouve un trésor, la récompense pour l’avoir trouvé peut être de 5 et celle pour ne pas l’avoir trouvé de 0. Le modèle d’apprentissage à renforcement tente de trouver une stratégie capable d’optimiser la récompense cumulative sur le long terme. On appelle cela une stratégie.
- Observation
-
Informations sur l’état de l’environnement mises à disposition de l’agent à chaque étape. Il peut d’agir de l’état entier ou simplement d’une partie. Par exemple, l’agent dans un modèle de jeu d’échecs peut observer l’état entier du plateau à chaque étape, mais un robot dans un labyrinthe peut uniquement observer une petite partie du labyrinthe dans lequel il se trouve.
En général, l’entraînement dans l’apprentissage à renforcement comporte de nombreux épisodes. Un épisode se compose de toutes les intervalles de temps dans un processus de décision markovien depuis l’état initial jusqu’à ce que l’environnement atteigne l’état terminal.
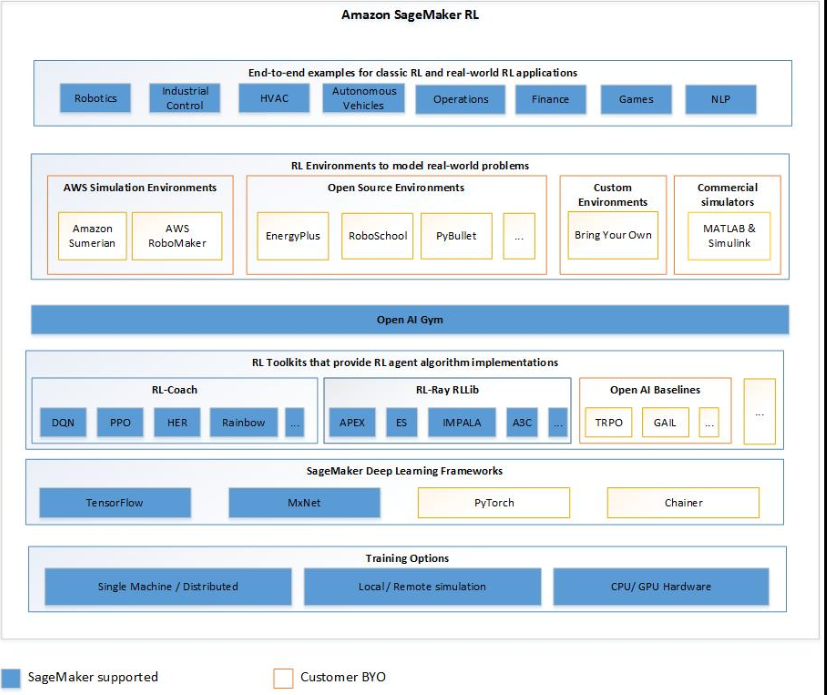
Principales fonctionnalités d'Amazon SageMaker AI RL
Pour entraîner des modèles RL dans SageMaker AI RL, utilisez les composants suivants :
-
Une infrastructure de deep learning. Actuellement, l' SageMaker IA prend en charge RL in TensorFlow et Apache MXNet.
-
Une boîte à outils d’apprentissage à renforcement. Une boîte à outils d’apprentissage par renforcement gère l’interaction entre l’agent et l’environnement, et fournit une large sélection des algorithmes d’apprentissage par renforcement dernier cri. SageMaker L'IA prend en charge les boîtes à outils Intel Coach et Ray RLLib. Pour plus d'informations sur Intel Coach, consultez https://nervanasystems.github.io/coach/
. Pour plus d'informations sur Ray RLLib, consultez https://ray.readthedocs.io/en/latest/rllib.html . -
Un environnement d’apprentissage à renforcement. Vous pouvez utiliser des environnements personnalisés, open-source ou commerciaux. Pour plus d'informations, consultez Environnements RL dans Amazon SageMaker AI.
Le schéma suivant montre les composants RL pris en charge dans SageMaker AI RL.
Exemples de blocs-notes d’apprentissage par renforcement
Pour des exemples de code complets, consultez les carnets d'exemples d'apprentissage par renforcement
