Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Multi-AZ Penerapan instans DB untuk Amazon RDS
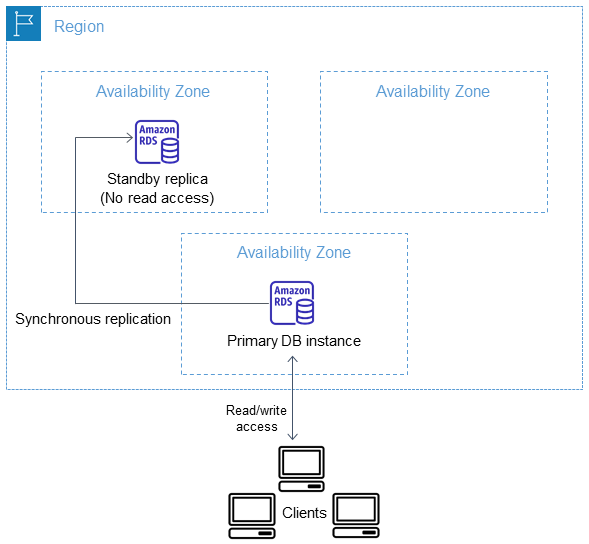
Amazon RDS menyediakan ketersediaan tinggi dan dukungan failover untuk instans DB menggunakan Multi-AZ penerapan dengan satu instans DB siaga. Jenis penyebaran ini disebut penyebaran instans Multi-AZ DB. Amazon RDS menggunakan beberapa teknologi berbeda untuk memberikan dukungan failover ini. Multi-AZ penerapan untuk instance MariaDB, MySQL, Oracle, PostgreSQL, dan RDS Custom untuk SQL Server DB menggunakan teknologi failover Amazon. Instans DB Microsoft SQL Server menggunakan SQL Server Database Mirroring (DBM) atau Always On Availability Groups (AG). Untuk informasi tentang dukungan versi SQL Server Multi-AZ, lihatMulti-AZ penerapan untuk Amazon RDS untuk Microsoft SQL Server. Untuk informasi tentang bekerja dengan RDS Custom for SQL Server Multi-AZ, lihat. Mengelola Multi-AZ penyebaran untuk RDS Custom untuk SQL Server
Dalam penerapan instans Multi-AZ DB, Amazon RDS secara otomatis menyediakan dan memelihara replika siaga sinkron di Availability Zone yang berbeda. Instans DB primer direplikasi secara sinkron di seluruh Zona Ketersediaan ke replika siaga untuk memberikan redundansi data dan meminimalkan lonjakan latensi selama pencadangan sistem. Menjalankan instans DB dengan ketersediaan tinggi dapat meningkatkan ketersediaan selama pemeliharaan sistem terencana. Hal ini juga dapat membantu melindungi basis data Anda terhadap kegagalan instans DB dan gangguan Zona Ketersediaan. Untuk informasi selengkapnya tentang Zona Ketersediaan, lihat Wilayah, Zona Ketersediaan, dan Zona Lokal.
catatan
Opsi ketersediaan tinggi bukanlah solusi penskalaan untuk skenario hanya baca. Anda tidak dapat menggunakan replika siaga untuk menyajikan lalu lintas baca. Untuk melayani lalu lintas hanya-baca, gunakan cluster Multi-AZ DB atau replika baca sebagai gantinya. Untuk informasi selengkapnya tentang cluster Multi-AZ DB, lihatMulti-AZ Penerapan cluster DB untuk Amazon RDS. Untuk informasi selengkapnya tentang replika baca, lihat Menggunakan replika baca instans DB.
Menggunakan konsol RDS, Anda dapat membuat penyebaran instans Multi-AZ DB hanya dengan menentukan Multi-AZ saat membuat instance DB. Anda dapat menggunakan konsol untuk mengonversi instans DB yang ada menjadi penerapan instans Multi-AZ DB dengan memodifikasi instans DB dan menentukan opsi. Multi-AZ Anda juga dapat menentukan penerapan instans Multi-AZ DB dengan AWS CLI atau Amazon RDS API. Gunakan perintah CLI create-db-instance atau modify-db-instance, atau operasi API CreateDBInstance atau ModifyDBInstance.
Konsol RDS menunjukkan Zona Ketersediaan replika siaga (disebut AZ sekunder). Anda juga dapat menggunakan perintah CLI describe-db-instances atau operasi API DescribeDBInstances untuk menemukan AZ sekunder.
Instans Multi-AZ DB yang menggunakan penerapan instans DB dapat meningkatkan latensi tulis dan komit dibandingkan dengan penerapan. Single-AZ Hal ini karena replikasi data sinkron yang terjadi. Anda mungkin mengalami perubahan latensi jika penerapan Anda gagal ke replika siaga, meskipun direkayasa dengan konektivitas jaringan latensi rendah AWS antara Availability Zones. Untuk beban kerja produksi, kami menyarankan Anda menggunakan IOPS Terketentuan (input/output operasi per detik) untuk kinerja yang cepat dan konsisten. Untuk informasi selengkapnya tentang kelas instans DB, lihat Kelas instans DB.
