Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pelajari konsep Amazon Redshift
Amazon Redshift Tanpa Server memungkinkan Anda mengakses dan menganalisis data tanpa semua konfigurasi gudang data yang disediakan. Sumber daya secara otomatis disediakan dan kapasitas gudang data ditingkatkan secara cerdas untuk memberikan kinerja yang cepat bahkan untuk beban kerja yang paling menuntut dan tidak dapat diprediksi. Anda tidak dikenakan biaya saat gudang data menganggur, jadi Anda hanya membayar untuk apa yang Anda gunakan. Anda dapat memuat data dan mulai melakukan kueri segera di editor kueri Amazon Redshift v2 atau di alat intelijen bisnis (BI) favorit Anda. Nikmati kinerja harga terbaik dan fitur SQL yang akrab di lingkungan administrasi nol yang mudah digunakan.
Jika Anda adalah pengguna pertama kali Amazon Redshift, kami sarankan Anda mulai dengan membaca bagian berikut:
-
Ikhtisar fitur Amazon Redshift Tanpa Server - Dalam topik ini, Anda dapat menemukan ikhtisar Amazon Redshift Tanpa Server dan kemampuan utamanya.
-
Sorotan dan harga layanan
— Di halaman detail produk ini, Anda dapat menemukan detail tentang sorotan dan harga Amazon Redshift Tanpa Server. -
Memulai dengan gudang data Amazon Redshift Tanpa Server. — Dalam topik ini, Anda dapat mempelajari lebih lanjut tentang cara membuat gudang data Amazon Redshift Tanpa Server, dan mulai menanyakan data menggunakan editor kueri v2.
Jika Anda lebih suka mengelola sumber daya Amazon Redshift secara manual, Anda dapat membuat klaster yang disediakan untuk kebutuhan kueri data Anda. Untuk informasi selengkapnya, lihat klaster Amazon Redshift.
Jika organisasi Anda memenuhi syarat dan klaster Anda sedang dibuat di Wilayah AWS tempat Amazon Redshift Tanpa Server tidak tersedia, Anda mungkin dapat membuat klaster di bawah program uji coba gratis Amazon Redshift. Pilih salah satu Produksi atau Uji coba gratis untuk menjawab pertanyaan Untuk apa Anda berencana menggunakan cluster ini? Saat Anda memilih Uji coba gratis, Anda membuat konfigurasi dengan tipe node dc2.large. Untuk informasi selengkapnya tentang memilih uji coba gratis, lihat uji coba gratis Amazon Redshift
Berikut ini adalah beberapa konsep utama Amazon Redshift Serverless.
-
Namespace — Kumpulan objek database dan pengguna. Ruang nama mengelompokkan semua sumber daya yang Anda gunakan di Amazon Redshift Tanpa Server, seperti skema, tabel, pengguna, rangkaian data, dan snapshot.
-
Workgroup - Kumpulan sumber daya komputasi. Workgroup menampung sumber daya komputasi yang digunakan Amazon Redshift Serverless untuk menjalankan tugas komputasi. Beberapa contoh sumber daya tersebut termasuk Redshift Processing Units (RPU), grup keamanan, batas penggunaan. Workgroup memiliki pengaturan jaringan dan keamanan yang dapat Anda konfigurasikan menggunakan konsol Amazon Redshift Serverless, AWS Command Line Interface atau Amazon Redshift Serverless API.
Untuk informasi selengkapnya tentang mengonfigurasi namespace dan sumber daya workgroup, lihat Bekerja dengan ruang nama dan Bekerja dengan grup kerja.
Berikut adalah beberapa konsep cluster utama Amazon Redshift yang disediakan:
-
Cluster — Komponen infrastruktur inti dari gudang data Amazon Redshift adalah cluster.
Sebuah cluster terdiri dari satu atau lebih node komputasi. Node komputasi menjalankan kode yang dikompilasi.
Jika sebuah cluster disediakan dengan dua atau lebih node komputasi, node pemimpin tambahan mengoordinasikan node komputasi. Node pemimpin menangani komunikasi eksternal dengan aplikasi, seperti alat intelijen bisnis dan editor kueri. Aplikasi klien Anda berinteraksi langsung hanya dengan node pemimpin. Node komputasi transparan untuk aplikasi eksternal.
-
Database — Sebuah cluster berisi satu atau lebih database.
Data pengguna disimpan dalam satu atau lebih database pada node komputasi. Klien SQL Anda berkomunikasi dengan node pemimpin, yang pada gilirannya mengkoordinasikan kueri yang sedang berjalan dengan node komputasi. Untuk detail tentang node komputasi dan node pemimpin, lihat Arsitektur sistem gudang data. Dalam database, data pengguna diatur ke dalam satu atau lebih skema.
Amazon Redshift adalah sistem manajemen basis data relasional (RDBMS) dan kompatibel dengan aplikasi RDBMS lainnya. Ini menyediakan fungsi yang sama dengan RDBMS biasa, termasuk fungsi pemrosesan transaksi online (OLTP) seperti memasukkan dan menghapus data. Amazon Redshift juga dioptimalkan untuk analisis batch berkinerja tinggi dan pelaporan kumpulan data.
Berikut ini, Anda dapat menemukan deskripsi aliran pemrosesan data tipikal di Amazon Redshift, bersama dengan deskripsi berbagai bagian aliran. Untuk informasi lebih lanjut tentang arsitektur sistem Amazon Redshift, lihat Arsitektur sistem gudang data.
Diagram berikut menggambarkan aliran pemrosesan data khas di Amazon Redshift.
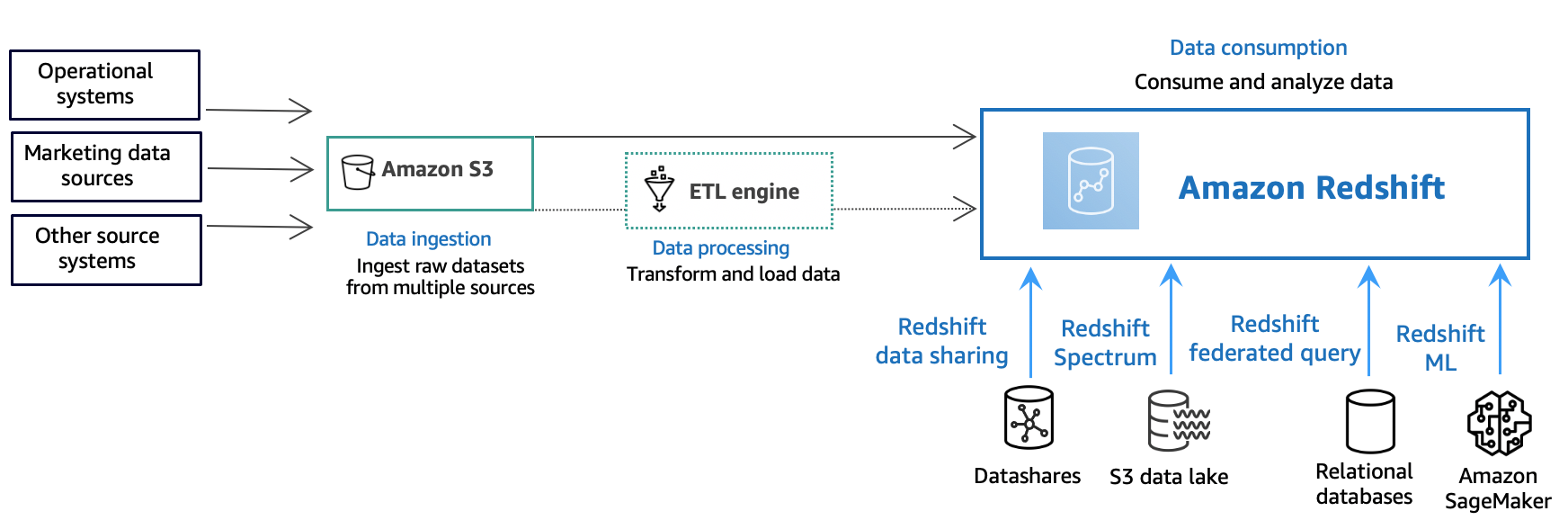
Gudang data Amazon Redshift adalah kueri database relasional kelas perusahaan dan sistem manajemen. Amazon Redshift mendukung koneksi klien dengan berbagai jenis aplikasi, termasuk intelijen bisnis (BI), pelaporan, data, dan alat analitik. Ketika Anda menjalankan kueri analitik, Anda mengambil, membandingkan, dan mengevaluasi sejumlah besar data dalam operasi multi-tahap untuk menghasilkan hasil akhir.
Pada lapisan konsumsi data, berbagai jenis sumber data terus mengunggah data terstruktur, semi-terstruktur, atau tidak terstruktur ke lapisan penyimpanan data. Area penyimpanan data ini berfungsi sebagai area pementasan yang menyimpan data dalam berbagai keadaan kesiapan konsumsi. Contoh penyimpanan mungkin berupa bucket Amazon Simple Storage Service (Amazon S3).
Pada lapisan pemrosesan data opsional, data sumber melewati pra-pemrosesan, validasi, dan transformasi menggunakan pipa ekstrak, transformasi, beban (ETL) atau ekstrak, muat, transformasi (ELT). Kumpulan data mentah ini kemudian disempurnakan dengan menggunakan operasi ETL. Contoh mesin ETL adalah AWS Glue.
Pada lapisan konsumsi data, data dimuat ke dalam klaster Amazon Redshift, tempat Anda dapat menjalankan beban kerja analitis.
Untuk beberapa contoh beban kerja analitis, lihat Menanyakan sumber data luar.
