Amazon Redshift tidak akan lagi mendukung pembuatan UDF Python baru mulai Patch 198. UDF Python yang ada akan terus berfungsi hingga 30 Juni 2026. Untuk informasi lebih lanjut, lihat posting blog
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Memulai dengan gudang data Amazon Redshift Tanpa Server
Jika Anda adalah pengguna pertama kali Amazon Redshift Serverless, kami sarankan Anda membaca bagian berikut untuk membantu Anda mulai menggunakan Amazon Redshift Serverless. Alur dasar Amazon Redshift Serverless adalah membuat sumber daya tanpa server, terhubung ke Amazon Redshift Tanpa Server, memuat data sampel, dan kemudian menjalankan kueri pada data. Dalam panduan ini, Anda dapat memilih untuk memuat data sampel dari Amazon Redshift Tanpa Server atau dari bucket Amazon S3. Data sampel digunakan di seluruh dokumentasi Amazon Redshift untuk mendemonstrasikan fitur. Untuk mulai menggunakan gudang data yang disediakan Amazon Redshift, lihat. Memulai gudang data yang disediakan Amazon Redshift
Mendaftar untuk Akun AWS
Untuk memulai AWS, Anda membutuhkan Akun AWS. Untuk informasi tentang membuat Akun AWS, lihat Memulai dengan Akun AWS di Panduan AWS Account Management Referensi.
Membuat gudang data dengan Amazon Redshift Serverless
Saat pertama kali masuk ke konsol Amazon Redshift Tanpa Server, Anda diminta untuk mengakses pengalaman memulai, yang dapat Anda gunakan untuk membuat dan mengelola sumber daya tanpa server. Dalam panduan ini, Anda akan membuat sumber daya tanpa server menggunakan pengaturan default Amazon Redshift Serverless.
Untuk kontrol pengaturan yang lebih terperinci, pilih Sesuaikan pengaturan.
catatan
Redshift Tanpa Server memerlukan VPC Amazon dengan tiga subnet di tiga zona ketersediaan yang berbeda. Redshift Serverless juga membutuhkan setidaknya 3 alamat IP yang tersedia. Pastikan VPC Amazon yang Anda gunakan untuk Redshift Serverless memiliki tiga subnet di tiga zona ketersediaan berbeda, dan setidaknya 3 alamat IP yang tersedia, sebelum melanjutkan. Untuk informasi selengkapnya tentang membuat subnet di VPC Amazon, lihat Membuat subnet di Panduan Pengguna Amazon Virtual Private Cloud. Untuk informasi selengkapnya tentang alamat IP di VPC Amazon, lihat alamat IP untuk VPC dan subnet Anda.
Untuk mengkonfigurasi dengan pengaturan default:
Masuk ke AWS Management Console dan buka konsol Amazon Redshift di. https://console.aws.amazon.com/redshiftv2/
Pilih Coba Uji Coba Gratis Redshift Tanpa Server.
-
Di bawah Konfigurasi, pilih Gunakan pengaturan default. Amazon Redshift Serverless membuat namespace default dengan workgroup default yang terkait dengan namespace ini. Pilih Simpan konfigurasi.
catatan
Namespace adalah kumpulan objek database dan pengguna. Namespaces mengelompokkan semua resource yang Anda gunakan di Redshift Serverless, seperti skema, tabel, pengguna, datashares, dan snapshot.
Workgroup adalah kumpulan sumber daya komputasi. Workgroup menyimpan sumber daya komputasi yang Redshift Serverless gunakan untuk menjalankan tugas komputasi.
Tangkapan layar berikut menunjukkan pengaturan default untuk Amazon Redshift Serverless.
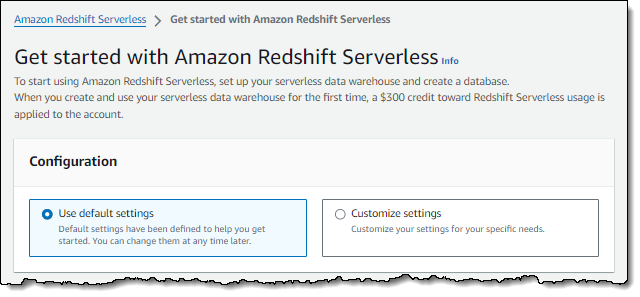
-
Setelah penyiapan selesai, pilih Lanjutkan untuk pergi ke dasbor Tanpa Server Anda. Anda dapat melihat bahwa workgroup tanpa server dan namespace tersedia.
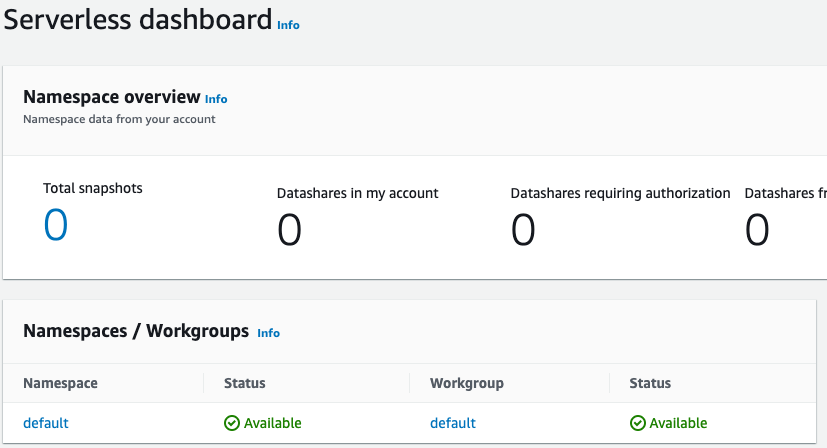
catatan
Jika Redshift Serverless tidak berhasil membuat workgroup, Anda dapat melakukan hal berikut:
Atasi kesalahan apa pun yang dilaporkan Redshift Tanpa Server, seperti memiliki terlalu sedikit subnet di VPC Amazon Anda.
Hapus namespace dengan memilih default-namespace di dasbor Redshift Serverless, lalu pilih Actions, Delete namespace. Menghapus namespace membutuhkan waktu beberapa menit.
Saat Anda membuka konsol Redshift Serverless lagi, layar selamat datang muncul.
Memuat data sampel
Setelah menyiapkan gudang data dengan Amazon Redshift Serverless, Anda dapat menggunakan editor kueri Amazon Redshift v2 untuk memuat data sampel.
-
Untuk meluncurkan editor kueri v2 dari konsol Amazon Redshift Tanpa Server, pilih Kueri data. Saat Anda memanggil editor kueri v2 dari konsol Amazon Redshift Tanpa Server, tab browser baru terbuka dengan editor kueri. Editor kueri v2 terhubung dari mesin klien Anda ke lingkungan Amazon Redshift Tanpa Server.
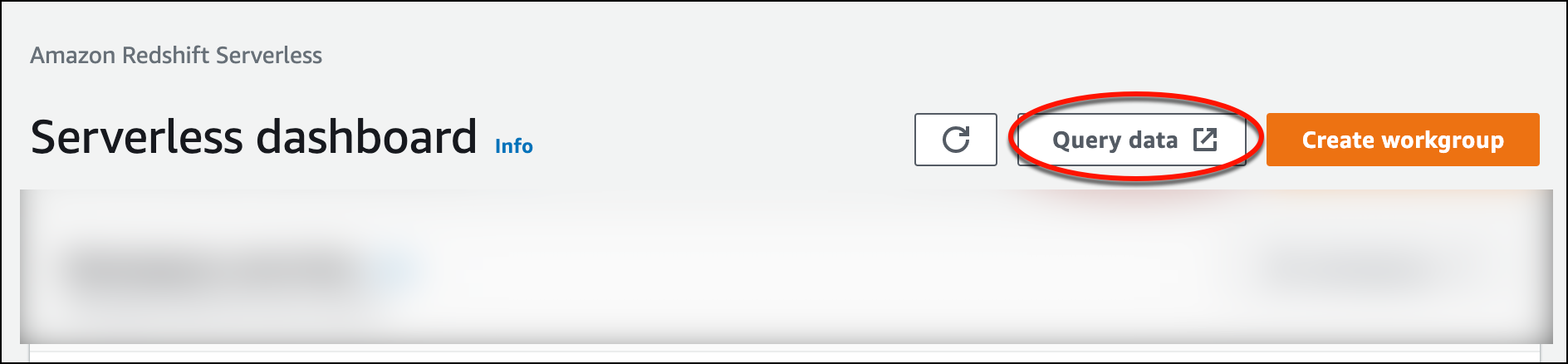
-
Untuk panduan ini, Anda akan menggunakan akun AWS administrator dan default AWS KMS key. Untuk informasi tentang mengonfigurasi editor kueri v2, termasuk izin mana yang diperlukan, lihat Mengonfigurasi Anda Akun AWS di Panduan Manajemen Pergeseran Merah Amazon. Untuk informasi tentang mengonfigurasi Amazon Redshift untuk menggunakan kunci yang dikelola pelanggan, atau untuk mengubah kunci KMS yang digunakan Amazon Redshift, lihat Mengubah AWS KMS kunci untuk namespace.
-
Untuk menyambung ke workgroup, pilih nama workgroup di panel tampilan pohon.
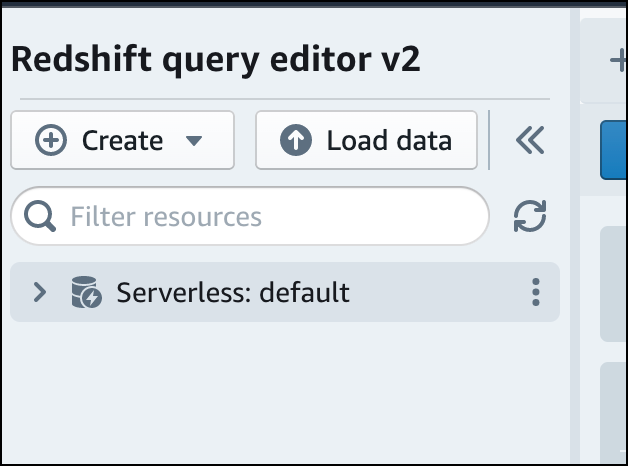
-
Saat menghubungkan ke workgroup baru untuk pertama kalinya dalam query editor v2, Anda harus memilih jenis otentikasi yang akan digunakan untuk terhubung ke workgroup. Untuk panduan ini, biarkan pengguna Federasi dipilih, dan pilih Buat koneksi.
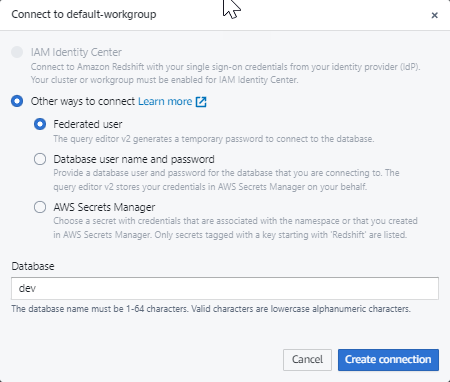
Setelah terhubung, Anda dapat memilih untuk memuat data sampel dari Amazon Redshift Tanpa Server atau dari bucket Amazon S3.
-
Di bawah workgroup default Amazon Redshift Serverless, perluas database sample_data_dev. Ada tiga skema sampel yang sesuai dengan tiga kumpulan data sampel yang dapat Anda muat ke dalam database Amazon Redshift Tanpa Server. Pilih kumpulan data sampel yang ingin dimuat, dan pilih Buka buku catatan sampel.
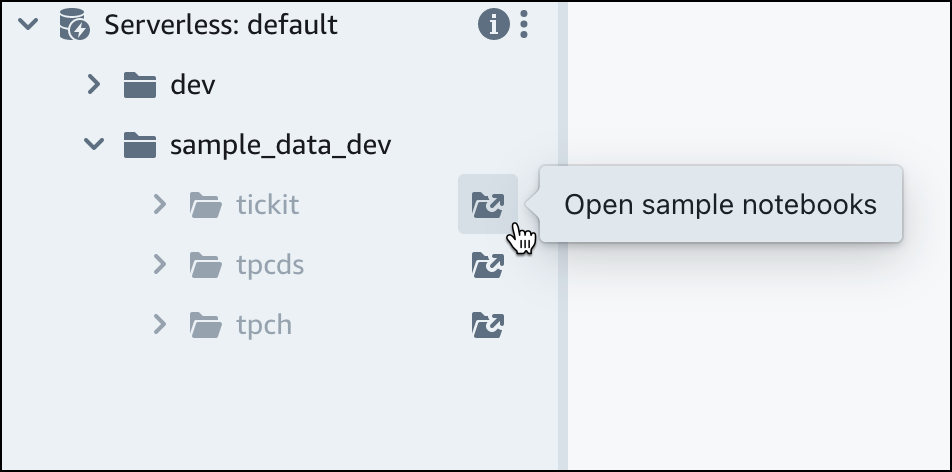
catatan
Notebook SQL adalah wadah untuk sel SQL dan Markdown. Anda dapat menggunakan buku catatan untuk mengatur, membubuhi keterangan, dan berbagi beberapa perintah SQL dalam satu dokumen.
-
Saat memuat data untuk pertama kalinya, editor kueri v2 akan meminta Anda untuk membuat database sampel. Pilih Buat.
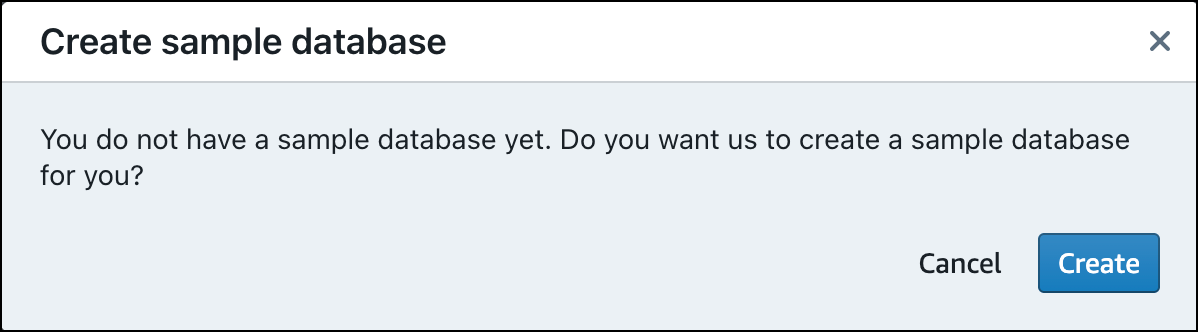
Menjalankan kueri sampel
Setelah menyiapkan Amazon Redshift Tanpa Server, Anda dapat mulai menggunakan kumpulan data sampel di Amazon Redshift Tanpa Server. Amazon Redshift Serverless secara otomatis memuat kumpulan data sampel, seperti kumpulan data tickit, dan Anda dapat segera melakukan kueri data.
-
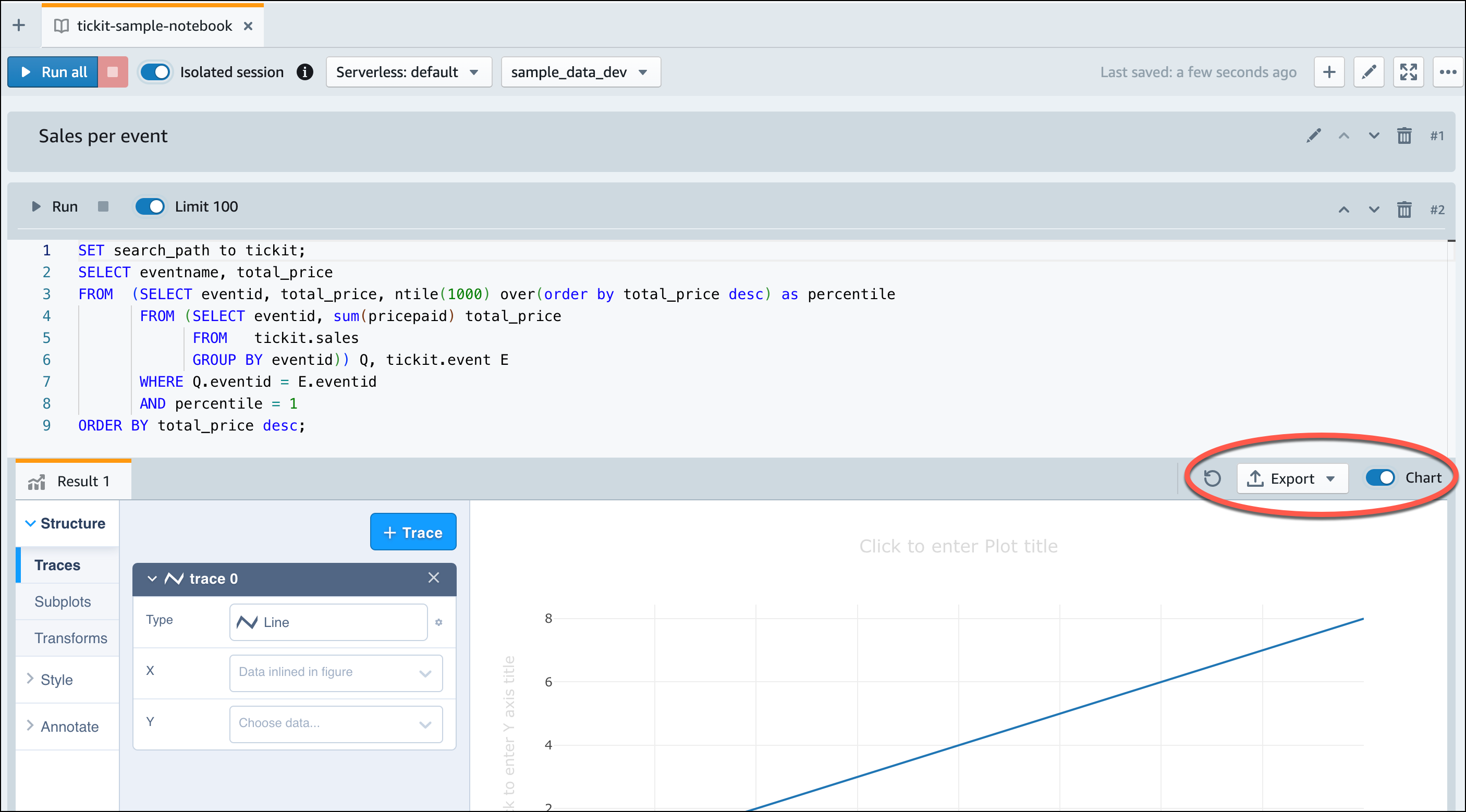
Setelah Amazon Redshift Serverless selesai memuat data sampel, semua kueri sampel dimuat di editor. Anda dapat memilih Jalankan semua untuk menjalankan semua kueri dari contoh buku catatan.
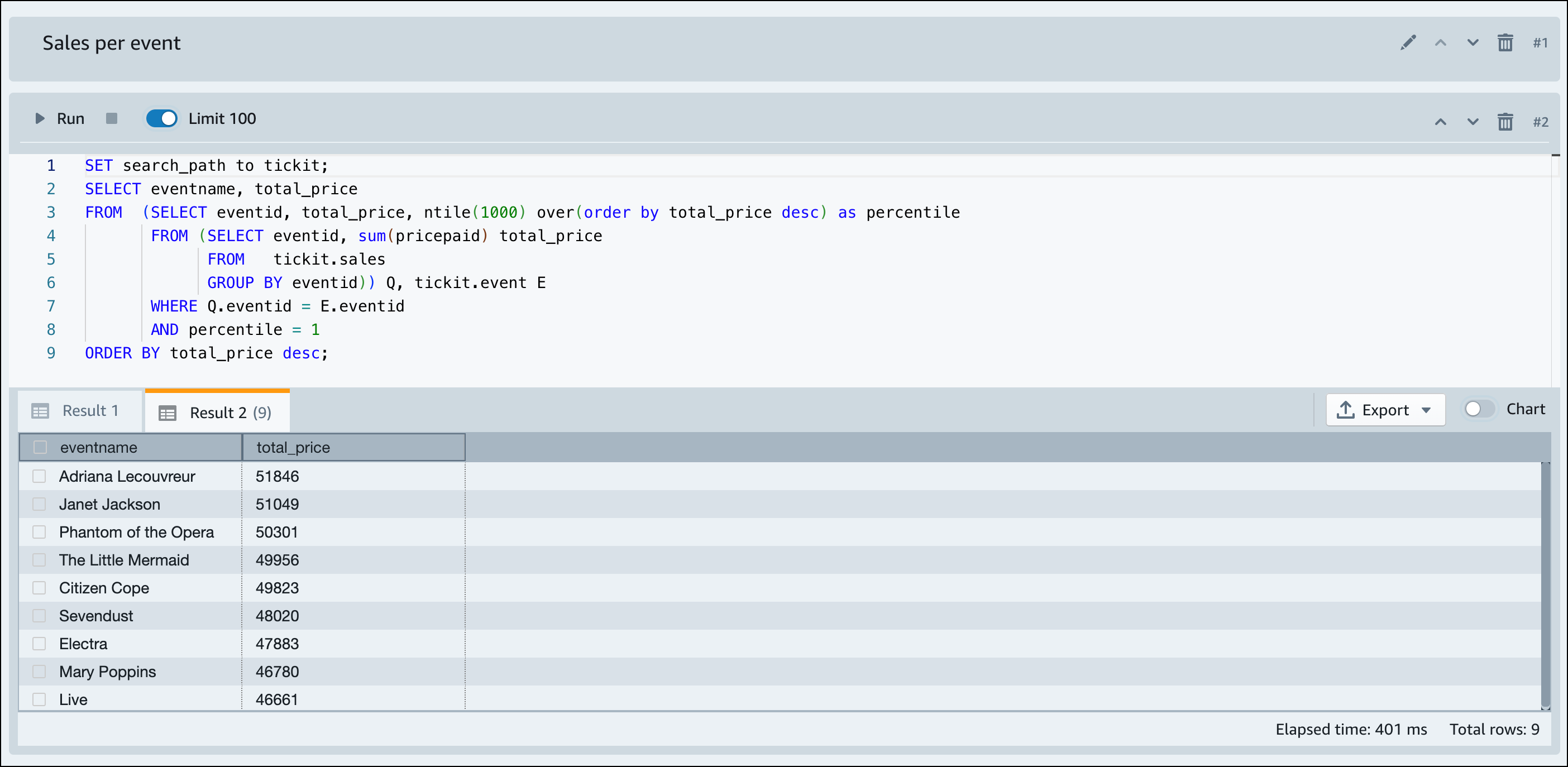
Anda juga dapat mengekspor hasil sebagai file JSON atau CSV atau melihat hasilnya dalam bagan.
Anda juga dapat memuat data dari bucket Amazon S3. Lihat Memuat data dari Amazon S3 untuk mempelajari selengkapnya.
Memuat data dari Amazon S3
Setelah membuat gudang data, Anda dapat memuat data dari Amazon S3.
Pada titik ini, Anda memiliki database bernamadev. Selanjutnya, Anda akan membuat beberapa tabel dalam database, mengunggah data ke tabel, dan mencoba kueri. Demi kenyamanan Anda, data sampel yang Anda muat tersedia di bucket Amazon S3.
-
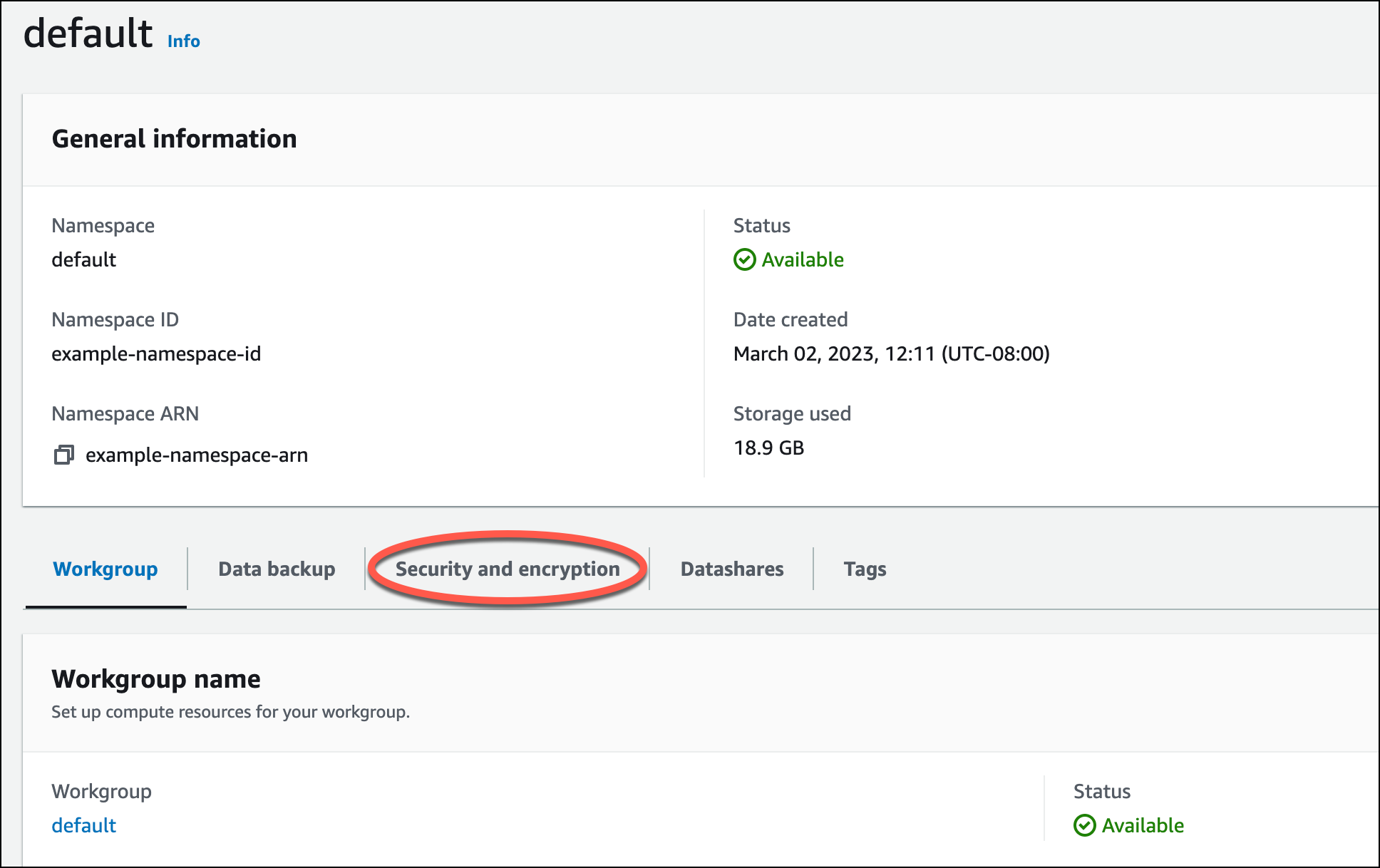
Sebelum Anda dapat memuat data dari Amazon S3, Anda harus terlebih dahulu membuat peran IAM dengan izin yang diperlukan dan melampirkannya ke namespace tanpa server Anda. Untuk melakukannya, kembali ke konsol Redshift Serverless dan pilih konfigurasi Namespace. Dari menu navigasi, pilih namespace Anda, lalu pilih Keamanan dan enkripsi. Kemudian, pilih Kelola peran IAM.
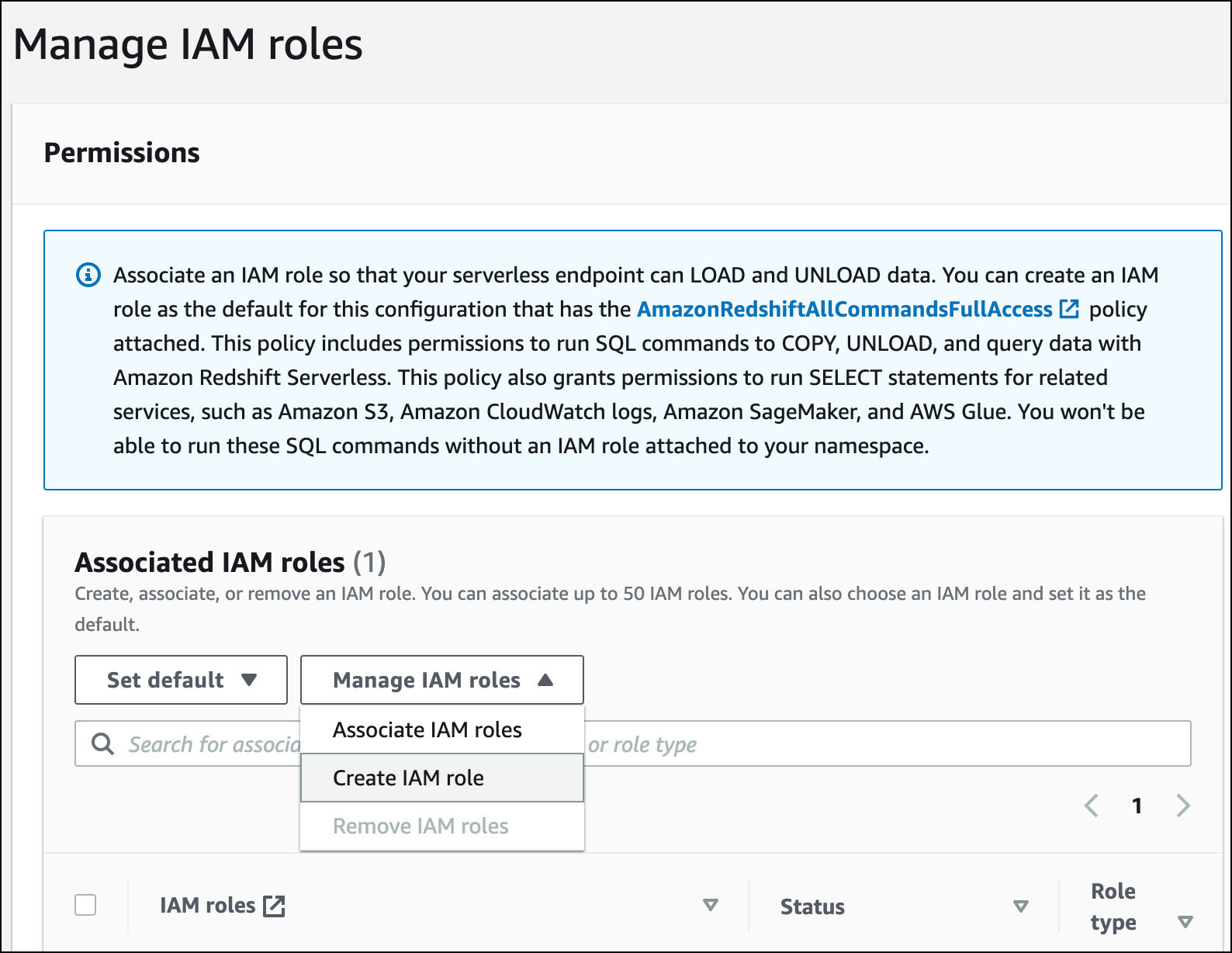
Perluas menu Kelola peran IAM, dan pilih Buat peran IAM.
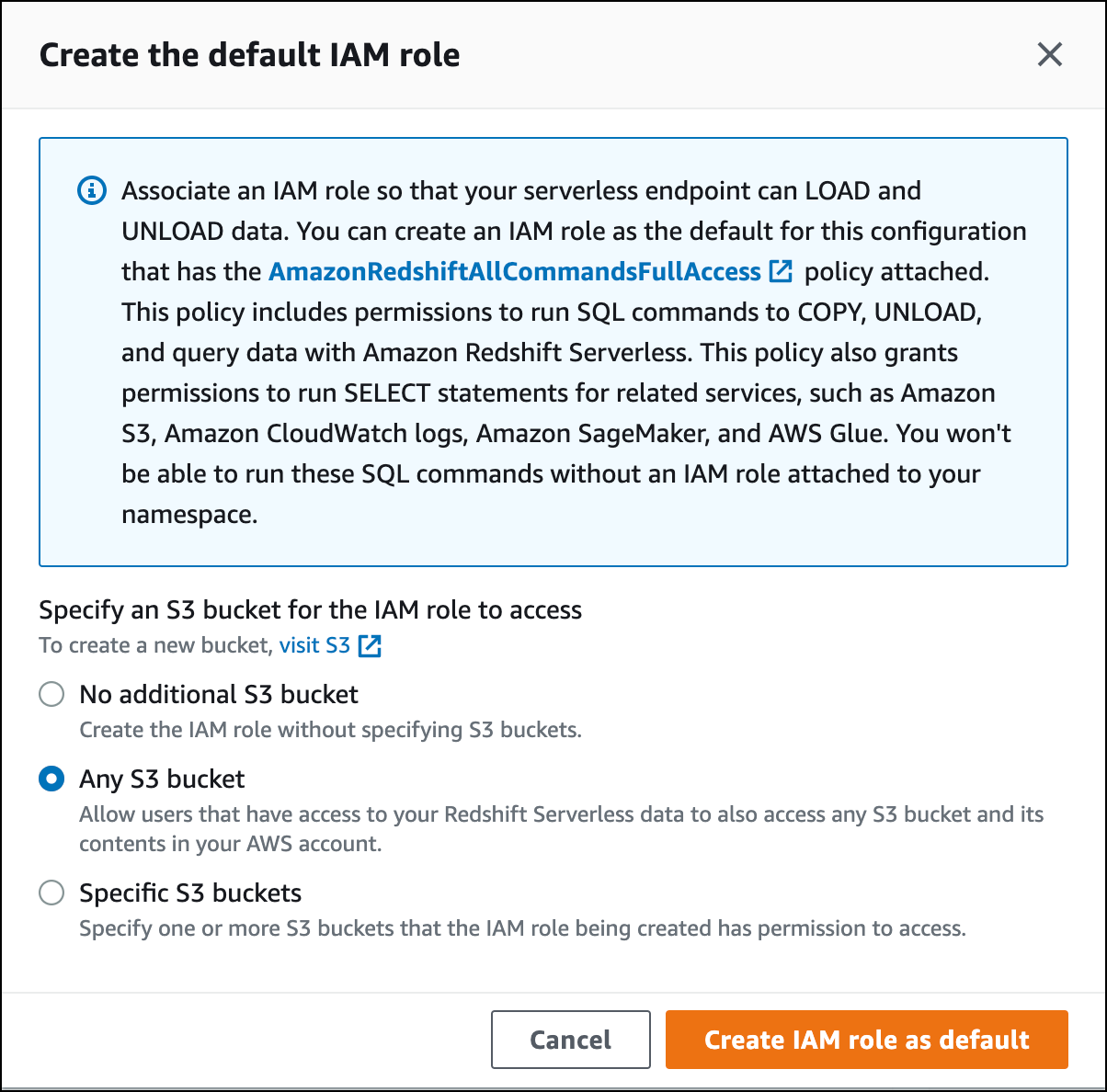
Pilih level akses bucket S3 yang ingin Anda berikan ke peran ini, dan pilih Buat peran IAM sebagai default.
-
Pilih Simpan perubahan. Anda sekarang dapat memuat data sampel dari Amazon S3.
Langkah-langkah berikut menggunakan data dalam bucket Amazon Redshift S3 publik, tetapi Anda dapat mereplikasi langkah yang sama menggunakan bucket S3 dan perintah SQL Anda sendiri.
Muat data sampel dari Amazon S3
-
Di editor kueri v2, pilih
 Tambah, lalu pilih Notebook untuk membuat buku catatan SQL baru.
Tambah, lalu pilih Notebook untuk membuat buku catatan SQL baru.
-
Beralih ke
devdatabase.
-
Buat tabel.
Jika Anda menggunakan query editor v2, copy dan jalankan berikut membuat pernyataan tabel untuk membuat tabel dalam
devdatabase. Untuk informasi selengkapnya tentang sintaks, lihat MEMBUAT TABEL di Panduan Pengembang Database Amazon Redshift.create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp); -
Di editor kueri v2, buat sel SQL baru di buku catatan Anda.
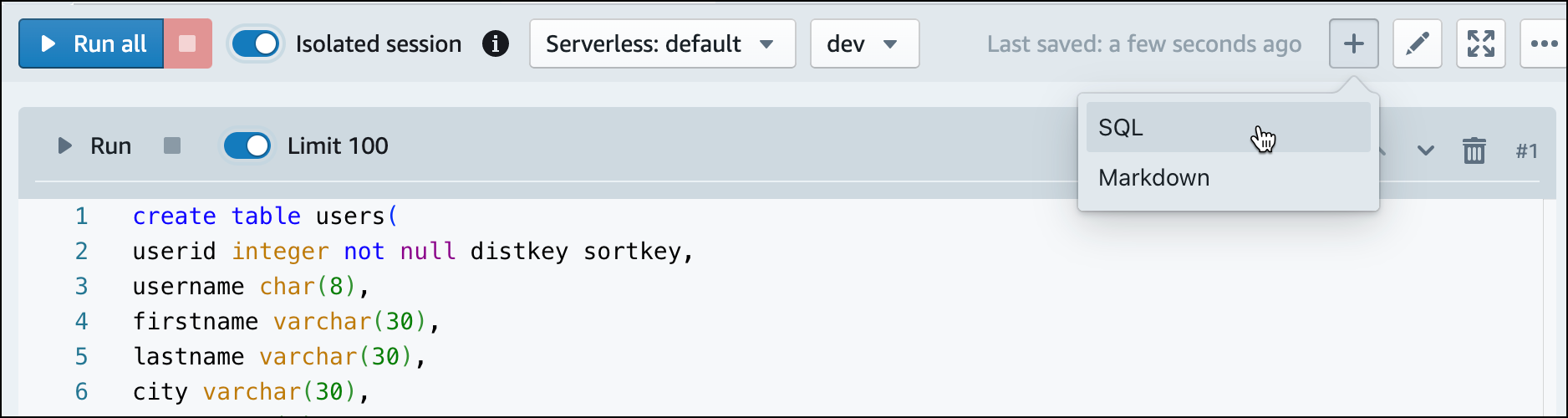
-
Sekarang gunakan perintah COPY di editor kueri v2 untuk memuat kumpulan data besar dari Amazon S3 atau Amazon DynamoDB ke Amazon Redshift. Untuk informasi selengkapnya tentang sintaks COPY, lihat COPY di Panduan Pengembang Database Amazon Redshift.
Anda dapat menjalankan perintah COPY dengan beberapa data sampel yang tersedia di bucket S3 publik. Jalankan perintah SQL berikut di editor query v2.
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE default; -
Setelah memuat data, buat sel SQL lain di buku catatan Anda dan coba beberapa contoh kueri. Untuk informasi selengkapnya tentang bekerja dengan perintah SELECT, lihat SELECT di Panduan Pengembang Amazon Redshift. Untuk memahami struktur dan skema data sampel, jelajahi menggunakan editor kueri v2.
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;
Sekarang setelah Anda memuat data dan menjalankan beberapa kueri sampel, Anda dapat menjelajahi area lain di Amazon Redshift Tanpa Server. Lihat daftar berikut untuk mempelajari selengkapnya tentang cara menggunakan Amazon Redshift Tanpa Server.
-
Anda dapat memuat data dari bucket Amazon S3. Lihat Memuat data dari Amazon S3 untuk informasi selengkapnya.
-
Anda dapat menggunakan editor kueri v2 untuk memuat data dari file terpisah karakter lokal yang lebih kecil dari 5 MB. Untuk informasi selengkapnya, lihat Memuat data dari file lokal.
-
Anda dapat terhubung ke Amazon Redshift Serverless dengan alat SQL pihak ketiga dengan driver JDBC dan ODBC. Lihat Menghubungkan ke Amazon Redshift Tanpa Server untuk informasi selengkapnya.
-
Anda juga dapat menggunakan Amazon Redshift Data API untuk terhubung ke Amazon Redshift Tanpa Server. Lihat Menggunakan Amazon Redshift Data API
untuk informasi selengkapnya. -
Anda dapat menggunakan data Anda di Amazon Redshift Serverless dengan Redshift MLuntuk membuat model pembelajaran mesin dengan perintah CREATE MODEL. Lihat Tutorial: Membangun model churn pelanggan untuk mempelajari cara membuat model Redshift ML.
-
Anda dapat menanyakan data dari data lake Amazon S3 tanpa memuat data apa pun ke Amazon Redshift Tanpa Server. Lihat Menanyakan data lake untuk informasi selengkapnya.
