Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Obiettivi del livello di servizio (SLO)
È possibile utilizzare Application Signals per creare obiettivi del livello di servizio per i servizi destinati alle operazioni o alle dipendenze aziendali critiche. Creando SLO su questi servizi, avrai la possibilità di tracciarli nel pannello di controllo SLO e di avere una visione d'insieme delle tue operazioni più importanti.
Oltre a creare una panoramica che gli operatori possono utilizzare per visualizzare lo stato attuale delle operazioni critiche, puoi utilizzare gli SLO per monitorare le prestazioni a lungo termine dei tuoi servizi, per assicurarti che soddisfino le tue aspettative. Se hai stipulato contratti sul livello di servizio con i clienti, gli SLO sono un ottimo strumento per accertarti che vengano rispettati.
La valutazione dello stato dei servizi con gli SLO inizia con la definizione di obiettivi chiari e misurabili basati su parametri delle prestazioni chiave: gli indicatori del livello di servizio (SLI). Uno SLO tiene traccia delle prestazioni SLI rispetto alla soglia e all'obiettivo prefissati e riporta in che misura le prestazioni delle applicazioni si avvicinano alla soglia.
Application Signals ti aiuta a impostare gli SLO sui parametri delle prestazioni chiave. Application Signals raccoglie automaticamente parametri di Latency e Availability per ogni servizio e operazione che individua e questi parametri sono spesso ideali da utilizzare come SLI. Con la procedura guidata di creazione degli SLO, puoi utilizzare questi parametri per i tuoi SLO. Puoi quindi monitorare lo stato di tutti i tuoi SLO tramite i pannelli di controllo di Application Signals.
Puoi impostare gli SLO su operazioni o dipendenze specifiche che il tuo servizio chiama o utilizza. È possibile utilizzare qualsiasi CloudWatch metrica o espressione metrica come SLI, oltre a utilizzare le metriche and. Latency Availability
La creazione di SLO è molto importante per ottenere il massimo vantaggio da Application Signals. CloudWatch Dopo aver creato gli SLO, puoi visualizzarne lo stato nella console Application Signals per vedere rapidamente quali di questi servizi e operazioni critici stanno funzionando bene e quali no. La possibilità di monitorare gli SLO offre i seguenti principali vantaggi:
Gli operatori di servizi vedere più facilmente l'integrità operativa attuale dei servizi critici confrontandoli con lo SLI. In questo modo possono controllare e identificare rapidamente servizi e operazioni non funzionanti.
È possibile monitorare le prestazioni dei servizi rispetto a obiettivi aziendali misurabili per periodi di tempo più lunghi.
Scegliendo su cosa impostare gli SLO, dai la priorità a ciò che è importante per te. I pannelli di controllo di Application Signals mostrano automaticamente informazioni su ciò a cui hai dato priorità.
Quando crei uno SLO, puoi anche scegliere di creare CloudWatch allarmi contemporaneamente per monitorare gli SLO. Puoi impostare allarmi per monitorare le violazioni della soglia e anche i livelli di avviso. Questi allarmi possono avvisarti automaticamente se i parametri SLO superano la soglia che hai impostato o se si avvicinano a una soglia di avviso. Ad esempio, uno SLO che si avvicina alla soglia di avviso può avvisarti che il tuo team dovrebbe rallentare la frequenza di abbandono dell'applicazione per assicurarsi che gli obiettivi di prestazione a lungo termine vengano raggiunti.
Argomenti
Concetti di SLO
Uno SLO include i componenti seguenti:
Un indicatore del livello di servizio (SLI), che è un parametro chiave delle prestazioni specificato dall'utente. Rappresenta il livello di prestazione desiderato per l'applicazione. Application Signals raccoglie automaticamente parametri chiave di
LatencyeAvailabilityper i servizi e le operazioni che individua e questi parametri sono spesso ideali da utilizzare come SLI.Sei tu a scegliere la soglia da utilizzare per il tuo SLI. Ad esempio, 200 ms per la latenza.
Un obiettivo o un obiettivo di raggiungimento, ossia la percentuale di tempo o richieste in cui si prevede che lo SLI raggiunga la soglia in ogni intervallo di tempo. Gli intervalli di tempo possono essere brevi, come ore, o lunghi, come un anno.
Gli intervalli possono essere intervalli di calendario o intervalli ricorrenti.
Gli intervalli del calendario sono allineati al calendario, ad esempio un SLO registrato mensilmente. CloudWatch regola automaticamente i dati relativi a salute, budget e risultati scolastici in base al numero di giorni in un mese. Gli intervalli di calendario sono più adatti agli obiettivi aziendali che sono misurati in base al calendario.
Gli intervalli ricorrenti sono calcolati su base sequenziale. Gli intervalli ricorrenti sono più adatti per monitorare l'esperienza utente recente della tua applicazione.
Il periodo è un periodo di tempo più breve e più periodi costituiscono un intervallo. Le prestazioni dell'applicazione vengono confrontate allo SLI durante ogni periodo compreso nell'intervallo. Per ogni periodo, si stabilisce che l'applicazione ha raggiunto o non ha raggiunto le prestazioni previste.
Ad esempio, un obiettivo del 99% con un intervallo di calendario di un giorno e un periodo di 1 minuto significa che l'applicazione deve soddisfare o raggiungere la soglia di successo nel 99% dei periodi di 1 minuto durante il giorno. In caso affermativo, lo SLO è stato raggiunto per quel giorno. Il giorno successivo è previsto un nuovo intervallo di valutazione e l'applicazione deve soddisfare o raggiungere la soglia di successo nel 99% dei periodi di 1 minuto durante il secondo giorno per soddisfare lo SLO per il secondo giorno.
Uno SLI può essere basato su uno dei nuovi parametri dell'applicazione standard raccolte da Application Signals. In alternativa, può essere qualsiasi espressione metrica o CloudWatch metrica. I parametri dell'applicazione standard che è possibile utilizzare per una SLI sono Latency e Availability. Availability rappresenta le risposte andate a buon fine divise per il totale delle richieste. Viene calcolata come (1 - frequenza di errore)*100, dove le risposte di errore sono 5xx errori. Le risposte andate a buon fine sono risposte prive di errori 5XX. Le risposte 4XX vengono considerate come andate a buon fine.
Oltre a creare SLO su una singola operazione o su tutte le operazioni di un servizio, è possibile creare SLO compositi che monitorano un sottoinsieme di operazioni per un servizio. Gli SLO compositi aggregano la Availability metrica su più operazioni, offrendo una visione unificata dell'affidabilità per un gruppo di operazioni correlate. È possibile selezionare tra 2 e 20 operazioni da includere in uno SLO composito. Per ulteriori informazioni, consulta Crea uno SLO composito su più operazioni.
Calcolo del budget di errore e del livello di raggiungimento per gli SLO basati su periodi
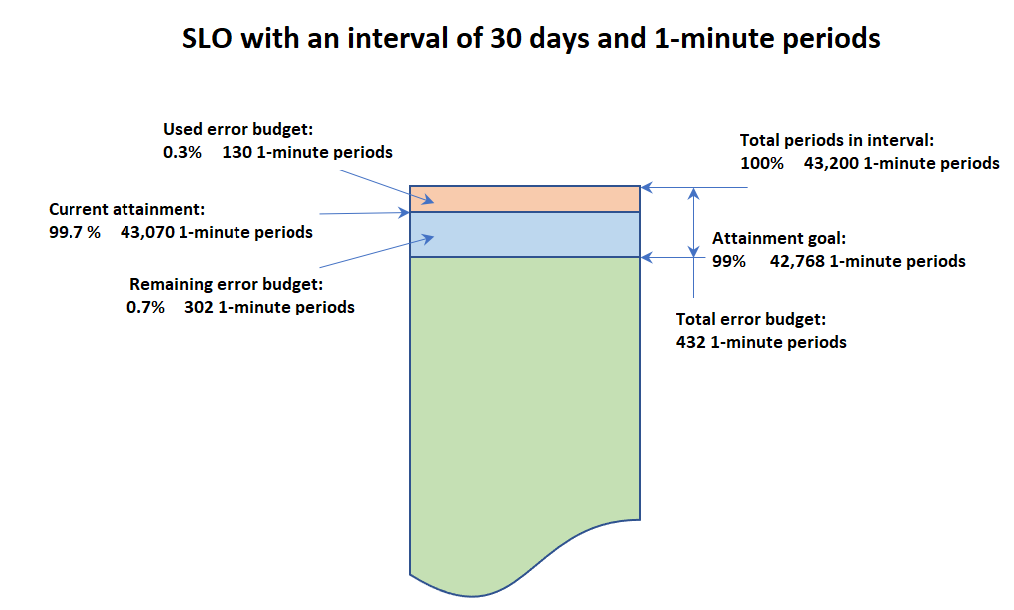
Quando si visualizzano le informazioni su uno SLO, vengono visualizzati lo stato di integrità corrente e il relativo budget di errore. Il budget di errore è la quantità di tempo all'interno dell'intervallo che può superare la soglia ma consentire comunque di rispettare lo SLO. Il budget di errore totale è la quantità totale di tempo di superamento della soglia che può essere tollerato durante l'intero intervallo. Il budget di errore residuo è la quantità di tempo residuo di superamento della soglia che può essere tollerato durante l'intervallo corrente. Questo si calcola sottraendo dal budget di errore totale la quantità di tempo in cui la soglia è già stata superata.
L'immagine seguente illustra i concetti di budget di raggiungimento e di errore per un obiettivo con un intervallo di 30 giorni, periodi di 1 minuto e un obiettivo di raggiungimento del 99%. 30 giorni contengono 43.200 periodi da 1 minuto. Il 99% di 43.200 è 42.768, quindi per raggiungere lo SLO è necessario che 42.768 raggiungano l'obiettivo. Finora, nell'intervallo attuale, 130 periodi di 1 minuto non hanno raggiunto l'obiettivo.
Determinazione del successo in ogni periodo
All'interno di ogni periodo, i dati SLI vengono aggregati in un unico punto dati basato sulla statistica utilizzata per lo SLI. Questo punto dati rappresenta l'intera durata del periodo. Quel singolo punto dati viene confrontato con la soglia SLI per determinare se il periodo ha raggiunto l'obiettivo. La visualizzazione nel pannello di controllo dei periodi che non hanno raggiunto l'obiettivo durante l'intervallo di tempo corrente può avvisare gli operatori del servizio che è necessario controllarlo.
Se si ritiene che il periodo non abbia raggiunto l'obiettivo, l'intera durata del periodo viene conteggiata come non riuscito ai fini del calcolo del budget di errore. Il monitoraggio del budget di errore consente di sapere se il servizio sta ottenendo le prestazioni desiderate per un periodo di tempo più lungo.
Esclusioni delle finestre temporali
Le esclusioni delle finestre temporali sono un blocco di tempo con una data di inizio e di fine definita. Questo periodo di tempo è escluso dalle metriche delle prestazioni dello SLO ed è possibile pianificare finestre di esclusione una tantum o ricorrenti. Prendiamo come esempio la manutenzione programmata.
Nota
Per gli SLO basati su periodi, i dati SLI nella finestra di esclusione sono considerati non in violazione.
Per gli SLO basati su richiesta, sono escluse tutte le richieste valide e non valide nella finestra di esclusione.
Quando un intervallo per uno SLO basato su richiesta viene completamente escluso, viene pubblicata una metrica predefinita del tasso di raggiungimento pari al 100%.
È possibile specificare solo finestre temporali con una data di inizio futura.
Calcolo del budget di errore e del raggiungimento per gli SLO basati su richieste
Dopo aver creato uno SLO, puoi recuperare i report relativi al budget di errore. Un budget di errore rappresenta quante richieste possono non rispettare l'obiettivo dello SLO senza che l'applicazione smetta di soddisfarlo. Per uno SLO basato su richiesta, il budget di errore residuo è dinamico e può aumentare o diminuire, a seconda del rapporto tra richieste valide e richieste totali
La tabella seguente illustra il calcolo per uno SLO basato su richiesta con un intervallo di 5 giorni e un obiettivo di raggiungimento dell'85%. In questo esempio, supponiamo che non ci sia stato traffico prima del Giorno 1. Lo SLO non ha raggiunto l'obiettivo il Giorno 10.
Nota
Per gli SLO basati su richiesta, TotalRequestCountPerMinute e BadRequestCountPerMinute vengono emessi come metriche aggiuntive rispetto alle metriche SLO basate sul periodo. Queste metriche sono fornite per scopi di osservabilità e non vengono utilizzate come input per il calcolo del tasso di raggiungimento.
Poiché queste metriche sono generate da dati metrici valutati periodicamente, i loro valori potrebbero occasionalmente differire dal conteggio delle richieste previsto a causa dei tempi o dei ritardi di pubblicazione delle metriche. Tali discrepanze non influiscono sui calcoli del raggiungimento degli SLO, che vengono calcolati indipendentemente da queste metriche emesse al minuto.
| Orario | Total Requests (Richieste totali) | Richieste non valide | Totale cumulativo delle richieste totali negli ultimi 5 giorni | Totale cumulativo delle richieste valide negli ultimi 5 giorni | Request-based conseguimento | Richieste totali del budget | Richieste rimanenti del budget |
|---|---|---|---|---|---|---|---|
|
Giorno 1 |
10 | 1 |
10 |
9 |
9/10 = 90% |
1.5 |
0,5 |
|
Giorno 2 |
5 |
1 |
15 |
13 |
13/15= 86% |
2.3 |
0.3 |
|
Giorno 3 |
1 |
1 |
16 |
13 |
13/16= 81% |
2.4 |
-0,6 |
|
Giorno 4 |
24 |
0 |
40 |
37 |
37/40= 92% |
6.0 |
3.0 |
|
Giorno 5 |
20 |
5 |
60 |
52 |
52/60= 87% |
9,0 |
1.0 |
|
Giorno 6 |
6 |
2 |
56 |
47 |
47/56= 84% |
8,4 |
-0,6 |
|
Giorno 7 |
10 |
3 |
61 |
50 |
50/61= 82% |
9.2 |
-1,8 |
|
Giorno 8 |
15 |
6 |
75 |
59 |
59/75= 79% |
11,3 |
-4,7 |
| Giorno 9 |
12 |
1 |
63 |
46 |
46/63= 73% |
9,5 |
-7,5 |
|
Giorno 10 |
5 |
57 |
40 |
40/57= 70% |
8,5 |
-8,5 | |
|
Raggiungimento finale degli ultimi 5 giorni |
|
70% |
Calcola l'indice di consumo e, facoltativamente, imposta gli allarmi relativi all'indice di consumo
È possibile utilizzare Application Signals per calcolare gli indici di consumo per gli obiettivi del livello di servizio. L'indice di consumo è una metrica che indica la velocità con cui il servizio consuma il budget di errore in rapporto all'obiettivo di raggiungimento dello SLO. È espressa come fattore multiplo del tasso di errore di base.
L'indice di consumo viene calcolato in base al tasso di errore di base, che dipende dall'obiettivo di raggiungimento. L'obiettivo di raggiungimento consiste nella percentuale di periodi di tempo soddisfacenti o di richieste riuscite che deve essere ottenuta per raggiungere l'obiettivo SLO. Il tasso di errore di base è (100% - percentuale dell'obiettivo di raggiungimento), e questo numero esaurirebbe esattamente il budget di errore completo alla fine dell'intervallo di tempo dello SLO. Quindi uno SLO con un obiettivo di raggiungimento del 99% avrebbe un tasso di errore di base dell'1%.
Il monitoraggio dell'indice di consumo illustra quanto siamo lontani dal tasso di errore di base. Ancora una volta, prendendo l'esempio di un obiettivo di raggiungimento del 99%, è vero quanto segue:
Indice di consumo = 1: se l'indice di consumo rimane sempre esattamente pari al tasso di errore di base, raggiungiamo perfettamente l'obiettivo SLO.
Indice di consumo < 1: se l'indice di consumo è inferiore al tasso di errore di base, siamo sulla buona strada per superare l'obiettivo SLO.
Indice di consumo > 1: se l'indice di consumo è superiore al tasso di errore di base, probabilmente non riusciremo a raggiungere l'obiettivo SLO.
Quando crei le frequenze di masterizzazione per i tuoi SLO, puoi anche scegliere di creare CloudWatch allarmi contemporaneamente per monitorare le frequenze di masterizzazione. Puoi impostare una soglia per gli indici di consumo e gli allarmi possono avvisarti automaticamente se le metriche relative a tali indici superano la soglia che hai impostato. Ad esempio, un indice di consumo vicino alla soglia può indicare che lo SLO sta consumando il budget di errore più rapidamente di quanto il tuo team possa tollerare e che potrebbe essere necessario rallentare il ritmo dei cambiamenti nell'applicazione per garantire il raggiungimento degli obiettivi prestazionali a lungo termine.
La creazione di allarmi comporta addebiti. Per ulteriori informazioni sui CloudWatch prezzi, consulta la pagina CloudWatch dei prezzi di Amazon
Calcolo dell'indice di consumo
Per calcolare l'indice di consumo è necessario specificare una finestra di visualizzazione retrospettiva. La finestra di visualizzazione retrospettiva è il periodo di tempo durante il quale misurare il tasso di errore.
burn rate = error rate over the look-back window / (100% - attainment goal)
Nota
Se non sono disponibili dati relativi al periodo dell'indice di consumo, Application Signals calcola tale indice in base al raggiungimento.
Il tasso di errore viene calcolato come rapporto tra il numero di eventi non validi e il numero totale di eventi durante la finestra dell'indice di consumo:
Per gli SLO basati su periodi, il tasso di errore viene calcolato dividendo i periodi negativi per i periodi totali. Il totale dei periodi rappresenta la totalità dei periodi presenti nella finestra di visualizzazione retrospettiva.
Per gli SLO basati su richieste, si tratta di una misura delle richieste non valide divisa per le richieste totali. Il numero totale di richieste è il numero di richieste durante la finestra di visualizzazione retrospettiva.
La finestra di visualizzazione retrospettiva deve essere un multiplo del periodo SLO e deve essere inferiore all'intervallo SLO.
Determina la soglia appropriata per un allarme relativo all'indice di consumo
Quando si configura un allarme relativo all'indice di consumo, è necessario scegliere un valore per l'indice di consumo come soglia di allarme. Il valore di questa soglia dipende dalla lunghezza dell'intervallo SLO e dalla finestra di visualizzazione retrospettiva, e dipende dal metodo o dal modello mentale che il team desidera adottare. Sono disponibili due metodi principali per determinare la soglia.
Metodo 1: determina la percentuale del budget totale stimato per gli errori che il team è disposto a consumare nella finestra di visualizzazione retrospettiva.
Se vuoi ricevere un allarme quando l'X% del budget di errore stimato viene speso nelle ultime ore di visualizzazione retrospettiva dell'indice di consumo, la soglia dell'indice di consumo è la seguente:
burn rate threshold = X% * SLO interval length / look-back window size
Ad esempio, il 5% di un budget di errore di 30 giorni (720 ore) impiegato per più di un'ora richiede un indice di consumo pari a 5% * 720 / 1 = 36. Pertanto, se la finestra di visualizzazione retrospettiva sull'indice di consumo è di 1 ora, impostiamo la soglia dell'indice di consumo su 36.
Puoi utilizzare la CloudWatch console per creare allarmi sulla frequenza di combustione utilizzando questo metodo. È possibile specificare il numero X e la soglia viene determinata utilizzando la formula precedente.
La lunghezza dell'intervallo SLO viene determinata in base al tipo di intervallo SLO:
Per gli SLO con un intervallo variabile, si tratta della durata dell'intervallo in ore.
Per gli SLO con un intervallo basato sul calendario:
Se l'unità è di giorni o settimane, è la lunghezza dell'intervallo in ore.
Se l'unità è un mese, prendiamo 30 giorni come lunghezza stimata e la convertiamo in ore.
Metodo 2: determina il tempo che manca all'esaurimento del budget per l'intervallo successivo
Per far sì che l'allarme ti avvisi quando il tasso di errore corrente nella finestra di visualizzazione retrospettiva più recente indica che mancano meno di X ore all'esaurimento del budget (supponendo che il budget residuo sia attualmente del 100%), puoi utilizzare la seguente formula per determinare la soglia dell'indice di consumo.
burn rate threshold = SLO interval length / X
Sottolineiamo che il tempo che manca all'esaurimento del budget (X) nella formula precedente presuppone che il budget totale rimanente sia attualmente del 100% e pertanto non tiene conto dell'importo del budget che è già stato consumato in questo intervallo. Possiamo anche considerarlo come il tempo che manca all'esaurimento del budget per l'intervallo successivo.
Procedure dettagliate per gli allarmi relativi all'indice di consumo
Ad esempio, prendiamo uno SLO con un intervallo di rotazione di 28 giorni. L'impostazione di un allarme relativo all'indice di consumo per questo SLO prevede due passaggi:
Impostazione dell'indice di consumo e della finestra di visualizzazione retrospettiva.
Crea un CloudWatch allarme che monitora la frequenza di combustione.
Per iniziare, stabilisci la quota del budget totale per gli errori che il servizio è disposto a consumare entro un periodo di tempo specifico. In altre parole, stabilisci il tuo obiettivo usando questa frase: “Voglio essere avvisato quando l'X% del mio budget totale destinato agli errori viene consumato entro M minuti”.
Ad esempio, potresti impostare l'obiettivo in modo da ricevere un avviso quando il 2% del budget totale per gli errori viene consumato entro 60 minuti.
Per impostare l'indice di consumo, è necessario innanzitutto definire la finestra di visualizzazione retrospettiva. La finestra di visualizzazione retrospettiva è M, che in questo esempio è di 60 minuti.
Successivamente, crei l'allarme. CloudWatch In questa fase, è necessario specificare una soglia per l'indice di consumo. Se l'indice di consumo supera tale soglia, l'allarme genererà un avviso. Per trovare la soglia, usa la formula seguente:
burn rate threshold = X% * SLO interval length/ look-back window size
In questo esempio, X è 2 perché vogliamo essere avvisati se il 2% del budget di errore viene consumato entro 60 minuti. La durata dell'intervallo è di 40.320 minuti (28 giorni) e 60 minuti è la finestra di visualizzazione retrospettiva, quindi la risposta è:
burn rate threshold = 2% * 40,320 / 60 = 13.44.
In questo esempio, dovresti impostare 13,44 come soglia di allarme.
Allarmi multipli con finestre diverse
Impostando gli allarmi su più finestre di visualizzazione retrospettiva, è possibile rilevare rapidamente picchi del tasso di errore con una finestra breve e al contempo rilevare aumenti minori del tasso di errore che, se ignorati, finirebbero col ridurre il budget di errore.
Inoltre, è possibile impostare un allarme composito su una frequenza di combustione con finestra lunga e su una frequenza di combustione con finestra corta (1/12th della finestra lunga) ed essere informati solo quando entrambe le frequenze di combustione superano una soglia. In questo modo, è possibile ricevere un avviso solo per le situazioni ancora in corso. Per ulteriori informazioni sugli allarmi compositi in CloudWatch, vedere. Create a composite alarm
Nota
Quando crei l'indice di consumo, puoi impostare un allarme di metrica su tale indice. Per impostare un allarme composito su più allarmi di indice di consumo, è necessario utilizzare le istruzioni in Create a composite alarm.
Una strategia di allarme composito consigliata nella cartella di lavoro di Google Site Reliability Engineering
Un allarme composito che rileva un paio di allarmi, uno con una finestra di un'ora e uno con una finestra di cinque minuti.
Un secondo allarme composito che rileva un paio di allarmi, uno con una finestra di sei ore e uno con una finestra di 30 minuti.
Un terzo allarme composito che rileva un paio di allarmi, uno con una finestra di tre giorni e l'altro con una finestra di sei ore.
I passaggi per effettuare questa configurazione sono i seguenti:
-
Crea cinque indici di consumo, con finestre di cinque minuti, 30 minuti, un'ora, sei ore e tre giorni.
Crea le seguenti tre coppie di CloudWatch allarmi. Ogni coppia include una finestra lunga e una finestra corta che 1/12th appartiene alla finestra lunga e le soglie vengono determinate utilizzando i passaggi in. Determina la soglia appropriata per un allarme relativo all'indice di consumo Quando calcoli la soglia per ogni allarme della coppia, utilizza la finestra di visualizzazione retrospettiva più lunga della coppia nel calcolo.
Allarmi sugli indici di consumo a 1 ora e 5 minuti (la soglia è determinata dal 2% del budget totale)
Allarmi sugli indici di consumo a 6 ore e 30 minuti (la soglia è determinata dal 5% del budget totale)
Allarmi sugli indici di consumo a 3 giorni e 6 ore (la soglia è determinata dal 10% del budget totale)
Per ognuna di queste coppie, crea un allarme composito per essere avvisato quando entrambi i singoli allarmi entrano nello stato ALARM. Per ulteriori informazioni sulla creazione di allarmi compositi, consulta Create a composite alarm.
Ad esempio, se gli allarmi per la prima coppia (finestra di un'ora e finestra di cinque minuti) hanno un nome
OneHourBurnRateeFiveMinuteBurnRate, la CloudWatch regola degli allarmi compositi sarebbeALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)
La strategia precedente è possibile solo per SLO con intervalli di almeno tre ore. Per gli SLO con intervalli più brevi, ti consigliamo di iniziare con una coppia di allarmi con frequenza di combustione in cui un allarme ha una finestra di riepilogo che corrisponde alla finestra di riepilogo dell'altro allarme. 1/12th Quindi, procedi impostando un allarme composito su questa coppia.
Creazione di uno SLO.
Ti consigliamo di impostare SLO sia di latenza che di disponibilità sulle tue applicazioni critiche. Questi parametri raccolti da Application Signals sono in linea con gli obiettivi aziendali comuni.
Puoi anche impostare gli SLO su qualsiasi espressione matematica CloudWatch metrica o metrica che dia come risultato una singola serie temporale.
La prima volta che crei uno SLO nel tuo account, crea CloudWatch automaticamente il ruolo AWSServiceRoleForCloudWatchApplicationSignalscollegato al servizio nel tuo account, se non esiste già. Questo ruolo collegato ai servizi consente di CloudWatch raccogliere dati di CloudWatch log, dati di X-Ray traccia, dati di CloudWatch metrica e dati di tagging dalle applicazioni del tuo account. Per ulteriori informazioni sui ruoli collegati ai servizi, consulta CloudWatch . Utilizzo di ruoli collegati ai servizi per CloudWatch
Quando crei uno SLO, specifica se si tratta di uno SLO basato sul periodo o uno SLO basato su richiesta. Ogni tipo di SLO ha un modo diverso di valutare le prestazioni dell'applicazione rispetto all'obiettivo di raggiungimento.
Uno SLO basato sul periodo utilizza periodi di tempo definiti all'interno di un intervallo di tempo totale specificato. Per ogni periodo di tempo, Application Signals determina se l'applicazione ha raggiunto il suo obiettivo. Il tasso di raggiungimento viene calcolato come
number of good periods/number of total periods.Ad esempio, per uno SLO basato sul periodo, soddisfare un obiettivo di raggiungimento del 99,9% significa che, nell'intervallo stabilito, l'applicazione deve raggiungere il proprio obiettivo di prestazioni per almeno il 99,9% dei periodi di tempo.
Uno SLO basato su richiesta non utilizza periodi di tempo predefiniti. Invece, lo SLO misura
number of good requests/number of total requestsdurante l'intervallo. In qualsiasi momento, puoi trovare il rapporto tra le richieste valide e le richieste totali per l'intervallo fino al timestamp specificato e misurare tale rapporto rispetto all'obiettivo impostato nel tuo SLO.
Argomenti
Creazione di uno SLO basato sul periodo
Per creare uno SLO basato sul periodo, utilizza la procedura seguente.
Per creare uno SLO basato sul periodo
Apri la CloudWatch console all'indirizzo. https://console.aws.amazon.com/cloudwatch/
Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli Crea SLO.
In Imposta l'indicatore del livello di servizio (SLI), effettua una delle seguenti operazioni:
Per impostare lo SLO su un'operazione di servizio, su tutte le operazioni o sulla dipendenza di un servizio, utilizzando una delle metriche
Latencyapplicative standard oppure:AvailabilityPer Tipo, scegli Servizio.
Seleziona un account che lo SLO monitorerà.
Seleziona il servizio che lo SLO monitorerà.
Per Tipo, scegli una delle seguenti opzioni:
Operazioni di servizio: per creare uno SLO su un'operazione di servizio, su tutte le operazioni o su un sottoinsieme di operazioni.
Dipendenza dal servizio: per creare un SLO su una dipendenza del servizio.
Se hai scelto Service Operations, seleziona l'operazione che questo SLO monitorerà. Per creare uno SLO a livello di servizio che monitori lo stato generale del servizio in tutte le operazioni, seleziona Tutte le operazioni. Altrimenti, seleziona un'operazione specifica da monitorare.
Per creare uno SLO che monitori un sottoinsieme di operazioni, vedi. Crea uno SLO composito su più operazioni
Se hai scelto Service Dependency, procedi come segue:
In Seleziona un'operazione, seleziona un'operazione specifica o seleziona Tutte le operazioni per utilizzare le metriche di tutte le operazioni di questo servizio che richiama una dipendenza.
In Seleziona una dipendenza, cerca e seleziona la dipendenza richiesta per la quale desideri misurare l'affidabilità.
Dopo aver selezionato la dipendenza, puoi visualizzare il grafico aggiornato e i dati storici in base alla dipendenza.
Per Seleziona un metodo di calcolo, scegli Periodi.
I menu a discesa Seleziona servizio e Seleziona operazione sono popolati da servizi e operazioni che sono stati attivi nelle ultime 24 ore.
Seleziona Disponibilità o Latenza, quindi imposta la soglia.
Per impostare lo SLO su qualsiasi CloudWatch metrica o espressione matematica metrica: CloudWatch
Per Tipo, scegliete Metrica. CloudWatch
Scegliete Seleziona CloudWatch metrica.
Viene visualizzata la schermata Seleziona parametro. Utilizza le schede Sfoglia o Query per trovare il parametro desiderato oppure crea un'espressione matematica del parametro.
Dopo aver selezionato il parametro desiderato, scegli la scheda Parametri nel grafico e seleziona le statistiche e il periodo da utilizzare per lo SLO. Quindi, scegli Seleziona parametro.
Per informazioni su queste schermate, consulta Rappresentazione grafica di un parametro e Aggiungi un'espressione matematica a un grafico CloudWatch.
Per Seleziona un metodo di calcolo, scegli Periodi.
Per Imposta condizione, seleziona un operatore di confronto e una soglia per lo SLO da utilizzare come indicatore di successo.
Se hai selezionato Assistenza nel passaggio 4, imposta la durata del periodo per questo SLO.
Inserisci un nome per lo SLO. L'inclusione del nome di un servizio o di un'operazione, insieme a parole chiave appropriate come latenza o disponibilità, ti aiuterà a identificare rapidamente cosa indica lo stato SLO durante la valutazione.
Imposta l'intervallo e l'obiettivo di raggiungimento per lo SLO. Per ulteriori informazioni sugli intervalli e sugli obiettivi di raggiungimento e su come interagiscono tra loro, consulta Concetti di SLO.
(Facoltativo) Per Imposta gli indici di consumo SLO, effettua le seguenti operazioni:
Imposta la durata (in minuti) della finestra di visualizzazione retrospettiva per l'indice di consumo. Per informazioni su come scegliere questa durata, consulta Procedure dettagliate per gli allarmi relativi all'indice di consumo.
Per creare più indici di consumo per questo SLO, scegli Aggiungi altri indici di consumo e imposta la finestra di visualizzazione retrospettiva per gli indici di consumo aggiuntivi.
(Facoltativo) Crea allarmi relativi all'indice di consumo eseguendo queste operazioni:
In Imposta allarmi dell'indice di consumo seleziona la casella di controllo per ogni indice di consumo per il quale vuoi creare un allarme. Per ciascuno di questi allarmi, procedi come segue:
Specifica l'argomento Amazon SNS da utilizzare per le notifiche quando l'allarme entra in stato ALARM.
Imposta una soglia di indice di consumo oppure specifica la percentuale del budget totale stimato consumata nell'ultima finestra di visualizzazione retrospettiva che desideri non superare. Se imposti la percentuale del budget totale stimato consumata, la soglia dell'indice di consumo viene calcolata automaticamente e utilizzata nell'allarme. Per decidere quale soglia impostare o per capire come utilizzare questa opzione per calcolare la soglia dell'indice di consumo, consulta Determina la soglia appropriata per un allarme relativo all'indice di consumo.
(Facoltativo) Imposta uno o più CloudWatch allarmi o una soglia di avviso per lo SLO.
CloudWatch gli allarmi possono utilizzare Amazon SNS per avvisarti in modo proattivo se un'applicazione non è integra in base alle sue prestazioni SLI.
Per creare un allarme, seleziona una delle caselle di controllo relative agli allarmi e inserisci o crea l'argomento Amazon SNS da utilizzare per le notifiche quando l'allarme entra nello stato
ALARM. Per ulteriori informazioni sugli allarmi, consulta. CloudWatch Utilizzo degli CloudWatch allarmi Amazon La creazione di allarmi comporta addebiti. Per ulteriori informazioni sui CloudWatch prezzi, consulta la pagina CloudWatch dei prezzi di Amazon. Se imposti una soglia di avviso, questa viene visualizzata nelle schermate di Application Signals per aiutarti a identificare gli SLO che rischiano di non essere raggiunti, anche se al momento sono integri.
Per impostare una soglia di avviso, inserisci il valore della soglia in Soglia di avviso. Quando il budget di errore dello SLO è inferiore alla soglia di avviso, lo SLO viene contrassegnato con un avviso in diverse schermate di Application Signals. Le soglie di avviso vengono visualizzate anche nei grafici del budget di errore. Puoi anche creare un allarme di avviso per lo SLO basato sulla soglia di avviso.
(Facoltativo) Per Imposta l'esclusione della finestra temporale SLO, procedi come segue:
In Escludi finestra temporale, imposta la finestra temporale da escludere dalle metriche delle prestazioni SLO.
Puoi scegliere Imposta finestra temporale e accedere alla Finestra di inizio per ogni ora o mese, oppure puoi scegliere Imposta la finestra temporale con l'espressione CRON e inserire l'espressione CRON.
In Ripeti, imposta se l'esclusione di questa finestra temporale è ricorrente o meno.
(Facoltativo) In Aggiungi motivo, puoi scegliere di inserire un motivo per l'esclusione della finestra temporale. Prendiamo come esempio la manutenzione programmata.
Seleziona Aggiungi finestra temporale per aggiungere fino a 10 finestre di esclusione temporale.
Per aggiungere tag a questo SLO, scegli la scheda Tag, quindi scegli Aggiungi nuovo tag. Con i tag è possibile a gestire, identificare, organizzare, cercare e filtrare le risorse. Per ulteriori informazioni sui tag, consulta Tagging delle risorse AWS.
Nota
Se l'applicazione a cui è correlato questo SLO è registrata AWS Service Catalog AppRegistry, puoi utilizzare il
awsApplicationtag per associare questo SLO a quell'applicazione in cui si riferisce. AppRegistry Per ulteriori informazioni, consulta Cos'è? AppRegistryScegli Crea SLO. Se hai scelto anche di creare uno o più allarmi, il nome del pulsante cambia di conseguenza.
Creazione di uno SLO basato su richiesta
Per creare un SLO basato su richiesta, utilizza la procedura seguente.
Creazione di un SLO basato su richiesta
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli Crea SLO.
In Imposta l'indicatore del livello di servizio (SLI), effettua una delle seguenti operazioni:
Per impostare lo SLO su un'operazione di servizio, su tutte le operazioni o sulla dipendenza di un servizio, utilizzando una delle metriche
Latencyapplicative standard oppure:AvailabilityPer Tipo, scegli Servizio.
Seleziona il servizio che lo SLO monitorerà.
Per Tipo, scegli una delle seguenti opzioni:
Operazioni di servizio: per creare uno SLO su un'operazione di servizio, su tutte le operazioni o su un sottoinsieme di operazioni.
Dipendenza dal servizio: per creare un SLO su una dipendenza del servizio.
Se hai scelto Service Operations, seleziona l'operazione che questo SLO monitorerà. Per creare uno SLO a livello di servizio che monitori lo stato generale del servizio in tutte le operazioni, seleziona Tutte le operazioni. Altrimenti, seleziona un'operazione specifica da monitorare.
Per creare uno SLO che monitori un sottoinsieme di operazioni, vedi. Crea uno SLO composito su più operazioni
Se hai scelto Service Dependency, procedi come segue:
In Seleziona un'operazione, seleziona un'operazione specifica o seleziona Tutte le operazioni per utilizzare le metriche di tutte le operazioni di questo servizio che richiama una dipendenza.
In Seleziona una dipendenza, cerca e seleziona la dipendenza richiesta per la quale desideri misurare l'affidabilità.
Dopo aver selezionato la dipendenza, puoi visualizzare il grafico aggiornato e i dati storici in base alla dipendenza.
Per Seleziona un metodo di calcolo, scegli Richieste.
-
I menu a discesa Seleziona servizio e Seleziona operazione sono popolati da servizi e operazioni che sono stati attivi nelle ultime 24 ore.
Scegli Disponibilità o Latenza. Se scegli Latenza, imposta la soglia.
Per impostare lo SLO su qualsiasi CloudWatch metrica o espressione matematica metrica: CloudWatch
Per Tipo, scegliete Metrica. CloudWatch
-
Per Definisci le richieste obiettivo, procedi come segue:
Scegli se misurare le Richieste valide o le Richieste non valide.
-
Scegliete Seleziona CloudWatch metrica. Questa metrica sarà il numeratore del rapporto tra le richieste target e le richieste totali. Se utilizzi una metrica di latenza, utilizza le statistiche Trimmed count (TC). Se la soglia è 9 ms e stai utilizzando l'operatore di confronto inferiore a (<), utilizza la soglia TC (:threshold - 1). Per ulteriori informazioni su TC, consulta Sintassi.
Viene visualizzata la schermata Seleziona parametro. Utilizza le schede Sfoglia o Query per trovare il parametro desiderato oppure crea un'espressione matematica del parametro.
-
Per Definisci le richieste totali, scegli la CloudWatch metrica che desideri utilizzare per l'origine. Questa metrica sarà il denominatore del rapporto tra le richieste target e le richieste totali.
Viene visualizzata la schermata Seleziona parametro. Utilizza le schede Sfoglia o Query per trovare il parametro desiderato oppure crea un'espressione matematica del parametro.
Dopo aver selezionato il parametro desiderato, scegli la scheda Parametri nel grafico e seleziona le statistiche e il periodo da utilizzare per lo SLO. Quindi, scegli Seleziona parametro.
Se utilizzi una metrica di latenza che emette un punto dati per richiesta, utilizza le Statistiche del conteggio dei campioni per contare il numero di richieste totali.
Per informazioni su queste schermate, consulta Rappresentazione grafica di un parametro e Aggiungi un'espressione matematica a un grafico CloudWatch.
Inserisci un nome per lo SLO. L'inclusione del nome di un servizio o di un'operazione, insieme a parole chiave appropriate come latenza o disponibilità, ti aiuterà a identificare rapidamente cosa indica lo stato SLO durante la valutazione.
Imposta l'intervallo e l'obiettivo di raggiungimento per lo SLO. Per ulteriori informazioni sugli intervalli e sugli obiettivi di raggiungimento e su come interagiscono tra loro, consulta Concetti di SLO.
(Facoltativo) Per Imposta gli indici di consumo SLO, effettua le seguenti operazioni:
Imposta la durata (in minuti) della finestra di visualizzazione retrospettiva per l'indice di consumo. Per informazioni su come scegliere questa durata, consulta Procedure dettagliate per gli allarmi relativi all'indice di consumo.
Per creare più indici di consumo per questo SLO, scegli Aggiungi altri indici di consumo e imposta la finestra di visualizzazione retrospettiva per gli indici di consumo aggiuntivi.
(Facoltativo) Crea allarmi relativi all'indice di consumo eseguendo queste operazioni:
In Imposta allarmi dell'indice di consumo seleziona la casella di controllo per ogni indice di consumo per il quale vuoi creare un allarme. Per ciascuno di questi allarmi, procedi come segue:
Specifica l'argomento Amazon SNS da utilizzare per le notifiche quando l'allarme entra in stato ALARM.
Imposta una soglia di indice di consumo oppure specifica la percentuale del budget totale stimato consumata nell'ultima finestra di visualizzazione retrospettiva che desideri non superare. Se imposti la percentuale del budget totale stimato consumata, la soglia dell'indice di consumo viene calcolata automaticamente e utilizzata nell'allarme. Per decidere quale soglia impostare o per capire come utilizzare questa opzione per calcolare la soglia dell'indice di consumo, consulta Determina la soglia appropriata per un allarme relativo all'indice di consumo.
(Facoltativo) Imposta uno o più CloudWatch allarmi o una soglia di avviso per lo SLO.
CloudWatch gli allarmi possono utilizzare Amazon SNS per avvisarti in modo proattivo se un'applicazione non è integra in base alle sue prestazioni SLI.
Per creare un allarme, seleziona una delle caselle di controllo relative agli allarmi e inserisci o crea l'argomento Amazon SNS da utilizzare per le notifiche quando l'allarme entra nello stato
ALARM. Per ulteriori informazioni sugli allarmi, consulta. CloudWatch Utilizzo degli CloudWatch allarmi Amazon La creazione di allarmi comporta addebiti. Per ulteriori informazioni sui CloudWatch prezzi, consulta la pagina CloudWatch dei prezzi di Amazon. Se imposti una soglia di avviso, questa viene visualizzata nelle schermate di Application Signals per aiutarti a identificare gli SLO che rischiano di non essere raggiunti, anche se al momento sono integri.
Per impostare una soglia di avviso, inserisci il valore della soglia in Soglia di avviso. Quando il budget di errore dello SLO è inferiore alla soglia di avviso, lo SLO viene contrassegnato con un avviso in diverse schermate di Application Signals. Le soglie di avviso vengono visualizzate anche nei grafici del budget di errore. Puoi anche creare un allarme di avviso per lo SLO basato sulla soglia di avviso.
(Facoltativo) Per Imposta l'esclusione della finestra temporale SLO, procedi come segue:
In Escludi finestra temporale, imposta la finestra temporale da escludere dalle metriche delle prestazioni SLO.
Puoi scegliere Imposta finestra temporale e accedere alla Finestra di inizio per ogni ora o mese, oppure puoi scegliere Imposta la finestra temporale con l'espressione CRON e inserire l'espressione CRON.
In Ripeti, imposta se l'esclusione di questa finestra temporale è ricorrente o meno.
(Facoltativo) In Aggiungi motivo, puoi scegliere di inserire un motivo per l'esclusione della finestra temporale. Prendiamo come esempio la manutenzione programmata.
Seleziona Aggiungi finestra temporale per aggiungere fino a 10 finestre di esclusione temporale.
Per aggiungere tag a questo SLO, scegli la scheda Tag, quindi scegli Aggiungi nuovo tag. Con i tag è possibile a gestire, identificare, organizzare, cercare e filtrare le risorse. Per ulteriori informazioni sui tag, consulta Tagging delle risorse AWS.
Nota
Se l'applicazione a cui è correlato questo SLO è registrata AWS Service Catalog AppRegistry, puoi utilizzare il
awsApplicationtag per associare questo SLO a quell'applicazione in cui si riferisce. AppRegistry Per ulteriori informazioni, consulta Cos'è? AppRegistryScegli Crea SLO. Se hai scelto anche di creare uno o più allarmi, il nome del pulsante cambia di conseguenza.
Crea un SLO sul monitor di un'app
Puoi creare SLO per monitorare le prestazioni dei monitor delle tue app CloudWatch RUM. Ciò consente di tenere traccia delle metriche reali dell'esperienza utente e di garantire che le applicazioni Web e mobili soddisfino gli obiettivi di prestazioni. Gli SLO sui monitor delle app utilizzano la valutazione basata sulle richieste, che misura il rapporto tra le richieste soddisfacenti e le richieste totali.
Per creare uno SLO sul monitor di un'app
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli Crea SLO.
Per Set Service Level Indicator (SLI), scegli RUM AppMonitor.
Seleziona il monitor dell'app che questo SLO monitorerà dall'elenco a discesa. L'elenco mostra il nome del monitor dell'app insieme alla piattaforma supportata (Web, iOS o Android).
(Facoltativo) Seleziona una pagina o una schermata specifica da monitorare. Se non selezioni una pagina, lo SLO monitorerà tutte le pagine per il monitoraggio dell'app.
Per Select metric, scegli la metrica da utilizzare per lo SLI. Le metriche disponibili dipendono dalla piattaforma:
Per le applicazioni web:
PerformanceNavigationDuration,JSErrorCountHttp4xxCount, eHttp5xxCountPer applicazioni mobili (iOS e Android):
ScreenLoadTimeCrashCount,Http4xxCount, eHttp5xxCount
Per Imposta condizione, seleziona un operatore di confronto e una soglia per lo SLO da utilizzare come indicatore di successo.
Inserisci un nome per lo SLO. L'inclusione del nome del monitor dell'app e delle parole chiave appropriate ti aiuterà a identificare rapidamente ciò che indica lo stato SLO durante il triage.
Imposta l'intervallo e l'obiettivo di raggiungimento per lo SLO. Per ulteriori informazioni, consulta Concetti di SLO.
(Facoltativo) Configura le frequenze di combustione e gli allarmi in base alle esigenze. Per ulteriori informazioni, consulta Calcola l'indice di consumo e, facoltativamente, imposta gli allarmi relativi all'indice di consumo.
(Facoltativo) Se necessario, imposta le esclusioni relative alla finestra temporale.
(Facoltativo) Aggiungi tag per organizzare e identificare questo SLO.
Scegli Crea SLO.
Crea uno SLO su un canarino
Puoi creare degli SLO per monitorare le prestazioni dei tuoi canarini CloudWatch Synthetics. Ciò consente di tenere traccia dei risultati sintetici del monitoraggio e di garantire che gli endpoint e le API soddisfino gli obiettivi di disponibilità e prestazioni. Gli SLO sui canarini utilizzano la valutazione basata sul periodo, in cui ogni canary run viene considerata come un periodo di valutazione distinto.
Per creare un SLO su un canarino
Apri la CloudWatch console all'indirizzo. https://console.aws.amazon.com/cloudwatch/
Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli Crea SLO.
Per Set Service Level Indicator (SLI), scegli Synthetics Canary.
Seleziona il canarino che questo SLO monitorerà dall'elenco a discesa.
Per Seleziona metrica, scegli una delle seguenti opzioni:
SuccessPercentDurationSuccessPercentmisura la percentuale di canarini andati a buon fineDurationmisura il tempo necessario per completare ogni corsa dei canarini
Per Imposta condizione, seleziona un operatore di confronto e una soglia per lo SLO da utilizzare come indicatore di successo.
Inserisci un nome per lo SLO. L'inclusione del nome del canarino e delle parole chiave appropriate ti aiuterà a identificare rapidamente ciò che indica lo status SLO durante il triage.
Imposta l'intervallo e l'obiettivo di raggiungimento per lo SLO. Per ulteriori informazioni, consulta Concetti di SLO.
(Facoltativo) Configura le frequenze di combustione e gli allarmi in base alle esigenze. Per ulteriori informazioni, consulta Calcola l'indice di consumo e, facoltativamente, imposta gli allarmi relativi all'indice di consumo.
(Facoltativo) Se necessario, imposta le esclusioni relative alla finestra temporale.
(Facoltativo) Aggiungi tag per organizzare e identificare questo SLO.
Scegli Crea SLO.
Crea uno SLO composito su più operazioni
È possibile creare uno SLO composito che monitora la Availability metrica in un sottoinsieme di operazioni per un servizio. Ciò è utile quando si desidera monitorare insieme l'affidabilità di un gruppo di operazioni correlate, anziché monitorare una singola operazione o tutte le operazioni.
Gli SLO compositi supportano sia la valutazione basata sul periodo che quella basata sulla richiesta. È possibile selezionare tra 2 e 20 operazioni da includere. Esistono due modi per selezionare le operazioni:
Selezione esplicita: seleziona manualmente le singole operazioni dal menu a discesa.
Pattern matching: utilizza un prefisso o un'espressione regolare per abbinare automaticamente le operazioni per nome.
Nota
Gli SLO compositi supportano solo la Availability metrica. La Latency metrica non è disponibile per gli SLO compositi.
Per creare uno SLO composito
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli Crea SLO.
Per Set Service Level Indicator (SLI), per Tipo, scegli Service.
Seleziona il servizio che lo SLO monitorerà.
Per Tipo, scegli Service Operations.
Seleziona le operazioni da includere in questo SLO composito. Esegui una delle seguenti operazioni:
Per selezionare manualmente le operazioni, scegliete più operazioni dal menu a discesa Operazione. È possibile selezionare tra 2 e 20 operazioni.
Le operazioni selezionate vengono visualizzate come token sotto il menu a discesa. Puoi rimuovere un'operazione scegliendo l'icona di annullamento sul relativo token.
Per selezionare le operazioni per modello, seleziona la casella di controllo Usa pattern matching. Quindi, esegui queste operazioni:
Per Tipo di pattern, scegliete Prefisso o Espressione regolare.
Il prefisso corrisponde a tutte le operazioni i cui nomi iniziano con il testo immesso. Ad esempio, l'immissione
Invokecorrisponde alle operazioniInvokeAsyncdenominateInvokeFunctione così via.L'espressione regolare corrisponde a tutte le operazioni i cui nomi corrispondono al modello regex immesso. Ad esempio, l'immissione
^Invoke.*corrisponde alle stesse operazioni dell'esempio del prefisso.
Immettete lo schema nel campo Motivo. La console visualizza le operazioni corrispondenti sotto forma di token sotto il campo in modo da poter verificare i risultati.
Dopo aver selezionato le operazioni, la metrica viene automaticamente impostata su Disponibilità.
Per Seleziona un metodo di calcolo, scegli Periodi o Richieste.
Se hai selezionato Periodi, imposta la durata del periodo e la soglia di disponibilità per questo SLO.
Immettete un nome per lo SLO o utilizzate il nome generato automaticamente. Il nome generato automaticamente include il nome del servizio e la parola «composito» per aiutarti a identificarlo.
Imposta l'intervallo e l'obiettivo di raggiungimento per lo SLO. Per ulteriori informazioni sugli intervalli e sugli obiettivi di raggiungimento e su come interagiscono tra loro, consulta Concetti di SLO.
(Facoltativo) Configura le frequenze di combustione e gli allarmi in base alle esigenze. Per ulteriori informazioni, consulta Calcola l'indice di consumo e, facoltativamente, imposta gli allarmi relativi all'indice di consumo.
(Facoltativo) Imposta uno o più CloudWatch allarmi o una soglia di avviso per lo SLO.
(Facoltativo) Se necessario, imposta le esclusioni della finestra temporale.
(Facoltativo) Aggiungi tag per organizzare e identificare questo SLO.
Scegli Crea SLO.
Utilizza i consigli SLO
Application Signals può fornire consigli per la configurazione SLO sulla base di dati metrici storici degli ultimi 30 giorni. Quando fornisci informazioni di base sul tuo servizio e sul tipo di SLO che desideri creare, Application Signals analizza i dati metrici e suggerisce valori ottimali per la soglia metrica, l'obiettivo SLO e le finestre di burnrate.
Per ricevere consigli SLO, devi fornire le seguenti informazioni:
Scegliete Service Operation o Service Dependency:
Per Service Operation, specificare il servizio e l'operazione
Per Service Dependency, specificare il servizio, l'operazione (o tutte le operazioni) e la dipendenza
Il tipo di valutazione SLO: basata sul periodo o sulla richiesta
Il tipo di metrica applicativa standard: o
LatencyAvailability
Sulla base di queste informazioni e dei dati storici sulle prestazioni del servizio, Application Signals consiglia i seguenti parametri di configurazione SLO:
Soglia metrica: la soglia di prestazioni per lo SLI, calcolata in base alle prestazioni effettive del servizio negli ultimi 30 giorni.
Obiettivo SLO: la percentuale dell'obiettivo di raggiungimento suggerito che si allinea all'affidabilità storica del servizio.
Finestre di burnrate: durate consigliate per monitorare la velocità con cui il servizio consuma il budget di errore.
È possibile accettare i valori consigliati o modificarli in base a requisiti aziendali specifici. I consigli forniscono un punto di partenza basato sui dati per configurare SLO che riflettano le effettive caratteristiche prestazionali del servizio.
Visualizza e valuta lo stato SLO
Puoi visualizzare rapidamente lo stato dei tuoi SLO utilizzando gli obiettivi del livello di servizio o le opzioni Services nella console. CloudWatch La visualizzazione Servizi offre una panoramica immediata della percentuale di servizi non integri, calcolata in base agli SLO che hai impostato. Per ulteriori informazioni sull'uso dell'opzione Servizi, consulta Monitoraggio dell'integrità operativa delle applicazioni con Application Signals.
La visualizzazione Obiettivi del livello di servizio offre una panoramica macro dell'organizzazione. È possibile visualizzare gli SLO soddisfatti e non soddisfatti nel loro complesso. In questo modo puoi avere un'idea di quanti dei tuoi servizi e delle tue operazioni rispondono alle tue aspettative per periodi di tempo più lunghi, in base agli SLI che hai scelto.
Per visualizzare tutti gli SLO utilizzando la visualizzazione Obiettivi del livello di servizio
-
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Viene visualizzato l'elenco Obiettivi del livello di servizio (SLO).
Puoi visualizzare rapidamente lo stato attuale degli SLO nella colonna Stato SLI. Per ordinare gli SLO in modo che tutti gli SLO non integri siano in cima all'elenco, scegli la colonna dello stato SLI finché gli SLO non integri non saranno tutti in cima alla lista.
La tabella dello SLO contiene le colonne predefinite riportate di seguito. Puoi modificare le colonne da visualizzare selezionando l'icona a forma di ingranaggio sopra l'elenco. Per ulteriori informazioni su obiettivi, SLI, raggiungimento e intervalli, consulta Concetti di SLO.
Il nome dello SLO.
La colonna Obiettivo mostra la percentuale di periodi di ogni intervallo che devono soddisfare correttamente la soglia SLI affinché venga raggiunto l'obiettivo SLO. Mostra anche la durata dell'intervallo per lo SLO.
Lo stato SLI indica l'integrità dello stato operativo corrente dell'applicazione. Se un periodo dell'intervallo di tempo attualmente selezionato non era integro per lo SLO, lo stato SLI mostra Non integro.
Se questo SLO è configurato per monitorare una dipendenza, le colonne Dipendenza e Operazione remota mostreranno i dettagli su quella relazione di dipendenza.
Il raggiungimento finale è il livello di successo raggiunto alla fine dell'intervallo di tempo selezionato. Ordina in base a questa colonna per vedere gli SLO che rischiano maggiormente di non essere rispettati.
Il delta di raggiungimento è la differenza nel livello di raggiungimento tra l'inizio e la fine dell'intervallo di tempo selezionato. Un delta negativo indica che il parametro tende verso il basso. Ordina in base a questa colonna per vedere le tendenze più recenti degli SLO.
Il budget di errore finale (%) è la percentuale di tempo totale all'interno del periodo in cui è possibile che si verifichino periodi non integri senza impedire che lo SLO sia raggiunto con successo. Se lo si imposta al 5% e lo SLI non è integro nel 5% o meno dei periodi rimanenti dell'intervallo, lo SLO viene comunque raggiunto con successo.
Il delta del budget di errore è la differenza nel budget di errore tra l'inizio e la fine dell'intervallo di tempo selezionato. Un delta negativo indica che il parametro tende verso la non riuscita.
Il budget di errore finale (tempo) è la quantità di tempo effettivo nell'intervallo che può essere non integro senza impedire che lo SLO sia raggiunto con successo. Ad esempio, se si tratta di 14 minuti, se lo SLI non è integro per meno di 14 minuti durante l'intervallo rimanente, lo SLO verrà comunque raggiunto con successo.
-
Il budget di errore finale (richieste) è la quantità di richieste nell'intervallo che può essere non integro senza impedire che lo SLO sia raggiunto correttamente. Per gli SLO basati su richieste, questo valore è dinamico e può cambiare al variare del numero totale cumulativo di richieste nel tempo.
Le colonne Servizio, Operazione e Tipo mostrano informazioni sul servizio e sull'operazione per cui è impostato questo SLO.
Per visualizzare i grafici del raggiungimento e del budget di errore per uno SLO, seleziona il pulsante di opzione accanto al nome dello SLO.
I grafici nella parte superiore della pagina mostrano il raggiungimento dello SLO e lo stato del budget di errore. Viene inoltre visualizzato un grafico sul parametro SLI associato a questo SLO.
Per valutare ulteriormente uno SLO che non soddisfa il suo obiettivo, scegli il nome del servizio, dell'operazione o della dipendenza associato a tale SLO. Verrà visualizzata la pagina dei dettagli dove puoi effettuare ulteriori operazioni di valutazione. Per ulteriori informazioni, consulta Visualizzazione dell'attività dettagliata del servizio e dell'integrità operativa tramite la pagina dei dettagli del servizio.
Per modificare l'intervallo di tempo dei grafici e delle tabelle sulla pagina, scegli un nuovo intervallo di tempo nella parte superiore dello schermo.
Modifica di uno SLO esistente
Segui questa procedura per modificare uno SLO esistente. Quando modifichi uno SLO, puoi cambiare solo la soglia, l'intervallo, l'obiettivo di raggiungimento e i tag. Per modificare altri aspetti come il servizio, l'operazione o il parametro, crea un nuovo SLO invece di modificarne uno esistente.
La modifica di parte di una configurazione principale dello SLO, come il periodo o la soglia, invalida tutti i dati e le valutazioni precedenti relativi al raggiungimento e all'integrità. Questa operazione elimina e ricrea efficacemente lo SLO.
Nota
Quando modifichi uno SLO, gli allarmi associati non vengono aggiornati automaticamente. Potrebbe essere necessario aggiornare gli allarmi per mantenerli sincronizzati con lo SLO.
Per modificare uno SLO esistente
-
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli il pulsante di opzione accanto allo SLO che desideri modificare, quindi scegli Operazioni, Modifica SLO.
Apporta le modifiche desiderate e seleziona Salva modifiche.
Eliminazione di uno SLO
Segui questa procedura per eliminare uno SLO esistente.
Nota
Quando elimini uno SLO, gli allarmi associati non vengono eliminati automaticamente. Sarà necessario eliminarli manualmente. Per ulteriori informazioni, consulta Gestione degli allarmi.
Per eliminare uno SLO
-
Apri la CloudWatch console all'indirizzo https://console.aws.amazon.com/cloudwatch/
. Nel riquadro di navigazione scegli Obiettivi del livello di servizio (SLO).
Scegli il pulsante di opzione accanto allo SLO che desideri modificare, quindi scegli Operazioni, Elimina SLO.
Scegli Conferma.
