Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Progettazione dello schema del sistema di gestione dei reclami in DynamoDB
Caso d'uso aziendale del sistema di gestione dei reclami
DynamoDB è un database ideale per un sistema di gestione dei reclami (o contact center) in quanto la maggior parte dei modelli di accesso ad essi associati sarebbero ricerche transazionali basate su valori chiave. I modelli di accesso tipici in questo scenario sarebbero i seguenti:
-
Crea e aggiorna i reclami
-
Inoltra un reclamo
-
Crea e leggi commenti su un reclamo
-
Ricevi tutti i reclami di un cliente
-
Ottieni tutti i commenti di un agente e ottieni tutte le escalation
Alcuni commenti possono contenere allegati che descrivono il reclamo o la soluzione. Sebbene questi siano tutti modelli di accesso fondamentali, possono esserci requisiti aggiuntivi, come l'invio di notifiche quando viene aggiunto un nuovo commento a un reclamo o l'esecuzione di interrogazioni analitiche per determinare la distribuzione dei reclami in base alla gravità (o alle prestazioni degli agenti) a settimana. Un ulteriore requisito relativo alla gestione del ciclo di vita o alla conformità sarebbe quello di archiviare i dati dei reclami dopo tre anni dalla registrazione del reclamo.
Diagramma dell'architettura del sistema di gestione dei reclami
Nel contenuto seguente viene illustrato il diagramma dell’architettura del sistema di gestione dei reclami. Questo diagramma mostra le diverse Servizio AWS integrazioni utilizzate dal sistema di gestione dei reclami.
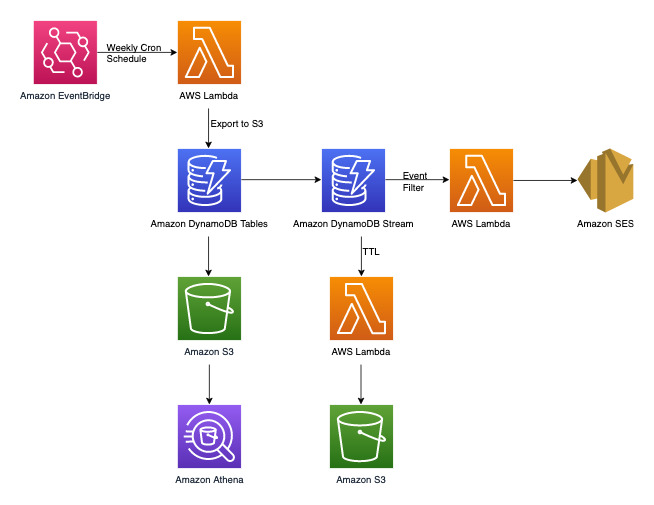
Oltre ai modelli di accesso transazionale chiave-valore che tratteremo più avanti nella sezione sulla modellazione dei dati di DynamoDB, abbiamo tre requisiti non transazionali. Il diagramma dell'architettura riportato sopra può essere suddiviso nei seguenti tre flussi di lavoro:
-
Invia una notifica quando un nuovo commento viene aggiunto a un reclamo
-
Esegui interrogazioni analitiche sui dati settimanali
-
Archivia dati più vecchi di tre anni
Diamo un'occhiata più approfondita a ciascuno di essi.
Invia una notifica quando un nuovo commento viene aggiunto a un reclamo
Possiamo utilizzare il flusso di lavoro seguente per soddisfare questo requisito:
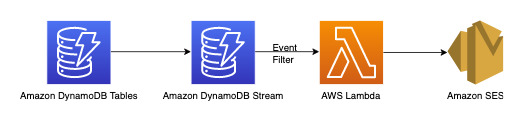
DynamoDB Streams è un meccanismo di acquisizione dei dati di modifica per registrare tutte le attività di scrittura sulle tabelle DynamoDB. È possibile configurare le funzioni Lambda in modo che si attivino su alcune o tutte queste modifiche. Un filtro eventi può essere configurato sui trigger Lambda per filtrare gli eventi non pertinenti al caso d'uso. In questo caso, possiamo utilizzare un filtro per attivare Lambda solo quando viene aggiunto un nuovo commento e inviare una notifica agli ID e-mail pertinenti che possono essere recuperati da AWS Secrets Manager o qualsiasi altro archivio di credenziali.
Esegui interrogazioni analitiche sui dati settimanali
DynamoDB è adatto per carichi di lavoro incentrati principalmente sull'elaborazione transazionale online (OLTP). Per gli altri modelli di accesso del 10-20% con requisiti analitici, i dati possono essere esportati in S3 con la funzionalità gestita Esporta su Amazon S3 senza alcun impatto sul traffico in tempo reale sulla tabella DynamoDB. Dai un'occhiata a questo flusso di lavoro qui sotto:
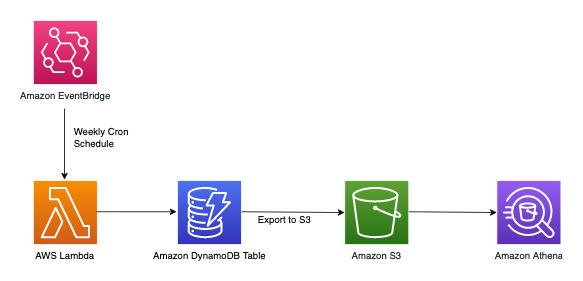
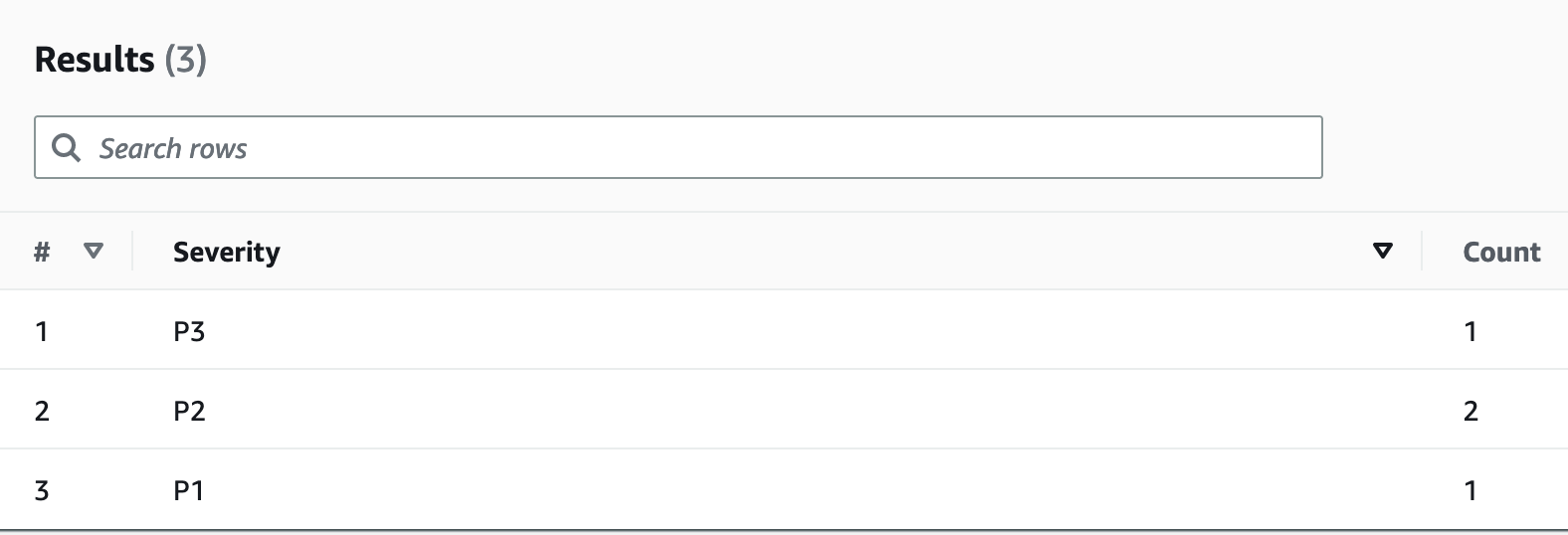
Amazon EventBridge può essere utilizzato per l'attivazione AWS Lambda nei tempi previsti: consente di configurare un'espressione cron per l'invocazione Lambda in modo che avvenga periodicamente. Lambda può richiamare l’API ExportToS3 e archiviare i dati di DynamoDB in S3. È quindi possibile accedere a questi dati S3 da un motore SQL come Amazon Athena per eseguire query analitiche sui dati DynamoDB senza influire sul carico di lavoro transazionale in tempo reale sulla tabella. Un esempio di query su Athena per trovare il numero di reclami per livello di gravità sarebbe il seguente:
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
Questa query Athena restituisce il seguente risultato:
Archivia dati più vecchi di tre anni
Puoi sfruttare la funzionalità di DynamoDB Time to Live (TTL) per eliminare i dati obsoleti dalla tabella DynamoDB senza costi aggiuntivi (tranne nel caso delle repliche delle tabelle globali per la versione 2019.11.21 (attuale), in cui le eliminazioni TTL replicate in altre regioni consumano capacità di scrittura). Questi dati vengono visualizzati e possono essere utilizzati da DynamoDB Streams per essere archiviati in Amazon S3. Il flusso di lavoro per questo requisito è il seguente:
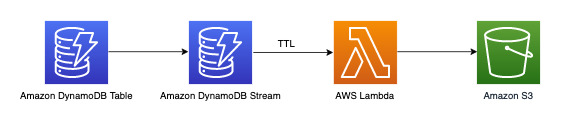
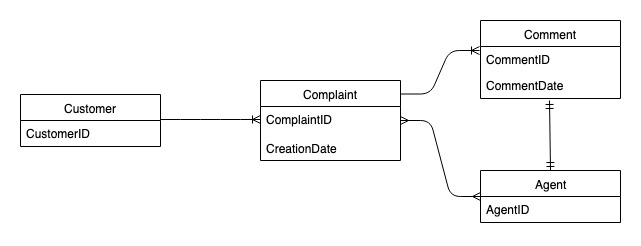
Diagramma delle relazioni tra entità del sistema di gestione dei reclami
Questo è il diagramma delle relazioni tra entità (ERD) che useremo per la progettazione dello schema di gestione dei reclami.
Modelli di accesso al sistema di gestione dei reclami
Questi sono i modelli di accesso che creeremo per la progettazione dello schema di gestione dei reclami.
-
createComplaint
-
updateComplaint
-
aggiorna ID SeveritybyComplaint
-
ottenere ComplaintByComplaintID
-
aggiungere CommentByComplaintID
-
ottenere AllCommentsByComplaintID
-
ottenere LatestCommentByComplaintID
-
ottenere AComplaintbyCustomerIDAndComplaintID
-
ottenere AllComplaintsByCustomerID
-
intensificare ComplaintByComplaintID
-
ottenere AllEscalatedComplaints
-
get EscalatedComplaintsByAgentID (ordina dal più recente al più vecchio)
-
get CommentsByAgentID (tra due date)
Evoluzione della progettazione dello schema del sistema di gestione dei reclami
Poiché si tratta di un sistema di gestione dei reclami, la maggior parte dei modelli di accesso ruota attorno a un reclamo come entità principale. Essendo ComplaintID altamente importante garantirà una distribuzione uniforme dei dati nelle partizioni sottostanti ed è anche il criterio di ricerca più comune per i nostri modelli di accesso identificati. Pertanto, ComplaintID è un buon candidato per la chiave di partizione in questo set di dati.
Fase 1: gestire i modelli di accesso 1 (createComplaint), 2 (updateComplaint), 3 (updateSeveritybyComplaintID) e 4 (getComplaintByComplaintID)
Possiamo utilizzare una chiave di ordinamento generica denominata “metadati” (o “AA”) per archiviare informazioni specifiche sul reclamo, ad esempio CustomerID, State ,Severity eCreationDate. Utilizziamo operazioni singleton con PK=ComplaintID e SK=“metadata” per effettuare le seguenti operazioni:
-
PutItemper creare un nuovo reclamo -
UpdateItemper aggiornare la gravità o altri campi nei metadati del reclamo -
GetItemper recuperare i metadati per il reclamo

Fase 2: Gestire il modello di accesso 5 (addCommentByComplaintID)
Questo modello di accesso richiede un modello di relazione uno-a-molti tra un reclamo e i commenti sul reclamo. Useremo qui la tecnica di partizionamento verticale per utilizzare una chiave di ordinamento e creare una raccolta di elementi con diversi tipi di dati. Se esaminiamo i modelli di accesso 6 (getAllCommentsByComplaintID) e 7 (getLatestCommentByComplaintID), sappiamo che i commenti dovranno essere ordinati per tempo. Possiamo anche ricevere più commenti contemporaneamente in modo da poter utilizzare la tecnica della chiave di ordinamento composita per aggiungere tempo e CommentID nell'attributo sort key.
Altre opzioni per gestire tali possibili collisioni di commenti sarebbero aumentare la granularità del timestamp o aggiungere un numero incrementale come suffisso invece di utilizzare Comment_ID. In questo caso, prefisseremo il valore della chiave di ordinamento per gli elementi corrispondenti ai commenti con “comm#” per abilitare le operazioni basate sull'intervallo.
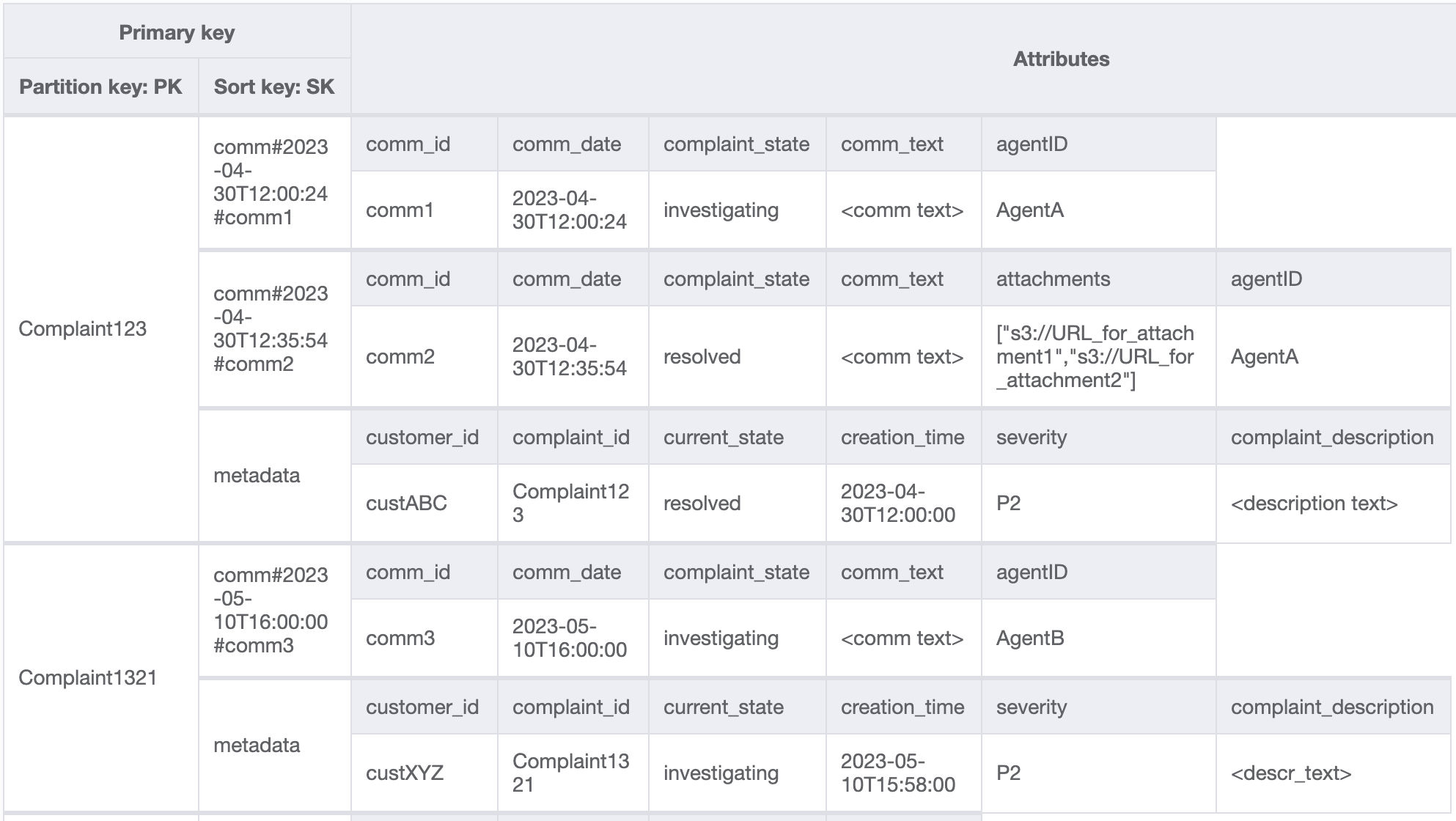
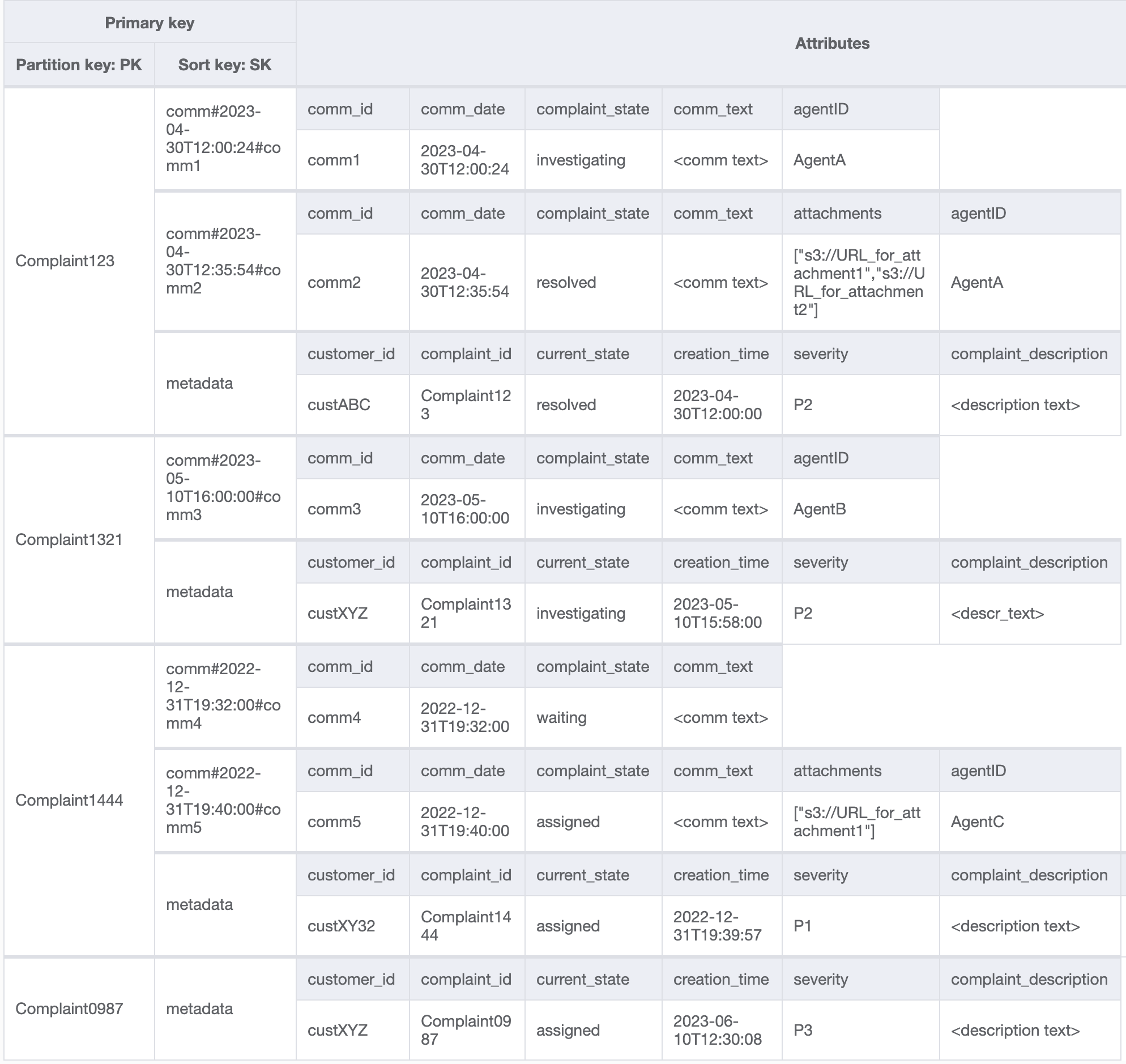
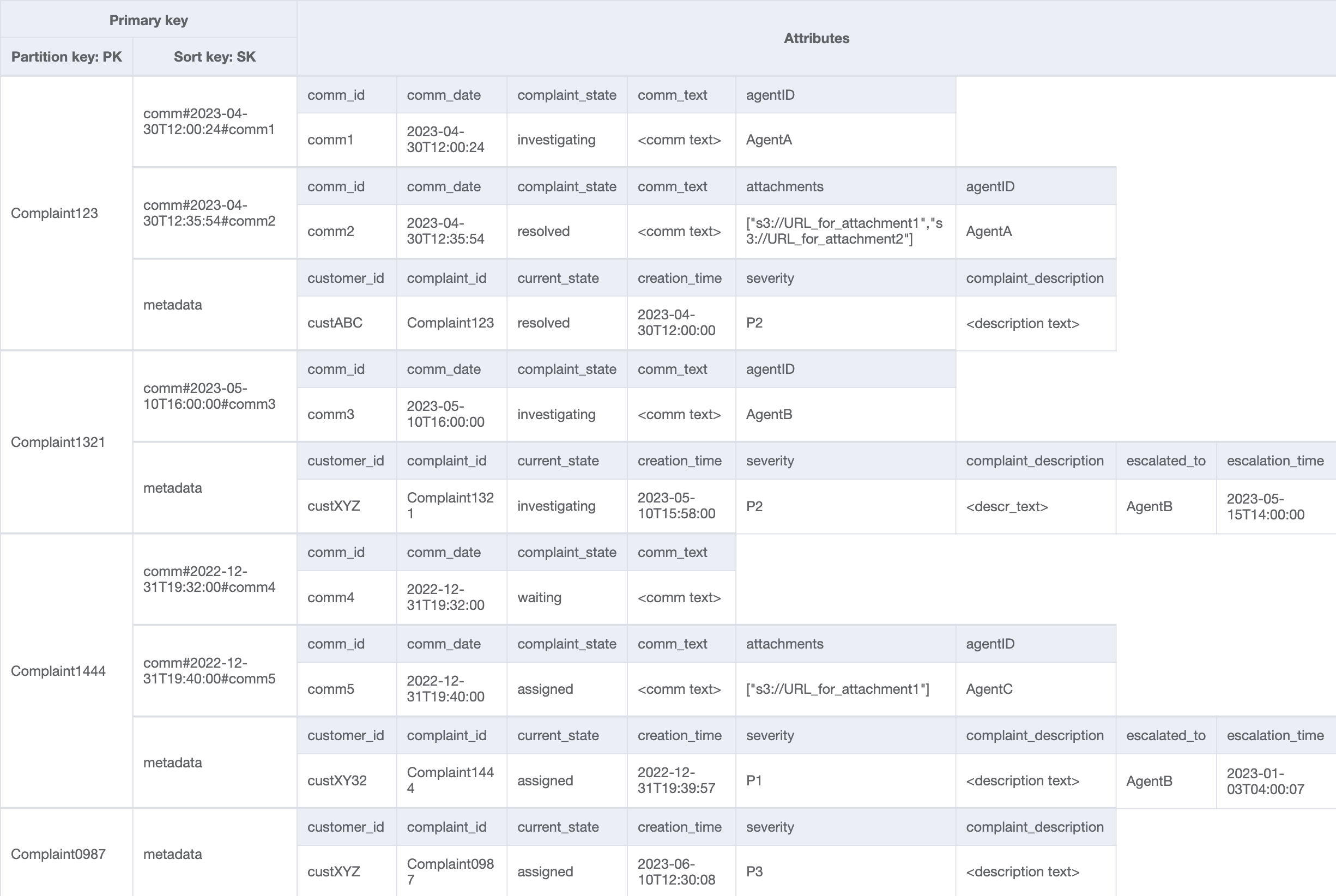
Dobbiamo inoltre garantire che currentState nei metadati del reclamo rifletta lo stato in cui viene aggiunto un nuovo commento. L'aggiunta di un commento potrebbe indicare che il reclamo è stato assegnato a un agente o è stato risolto e così via. Per integrare l'aggiunta di commenti e l'aggiornamento dello stato corrente nei metadati dei reclami, in modo «tutto o niente», utilizzeremo l'API. TransactWriteItems Lo stato della tabella risultante ora è simile al seguente:

Aggiungiamo altri dati nella tabella e aggiungiamo anche ComplaintID come campo separato dal nostro PK per rendere il modello a prova di futuro nel caso in cui avessimo bisogno di indici aggiuntivi su ComplaintID. Tieni inoltre presente che alcuni commenti potrebbero contenere allegati che verranno archiviati in Amazon Simple Storage Service e ne manterremo i riferimenti o gli URL solo in DynamoDB. È consigliabile mantenere il database transazionale il più snello possibile per ottimizzare costi e prestazioni. L'aspetto dei dati è ora il seguente:
Fase 3: Gestire i modelli di accesso 6 (getAllCommentsByComplaintID) e 7 (getLatestCommentByComplaintID)
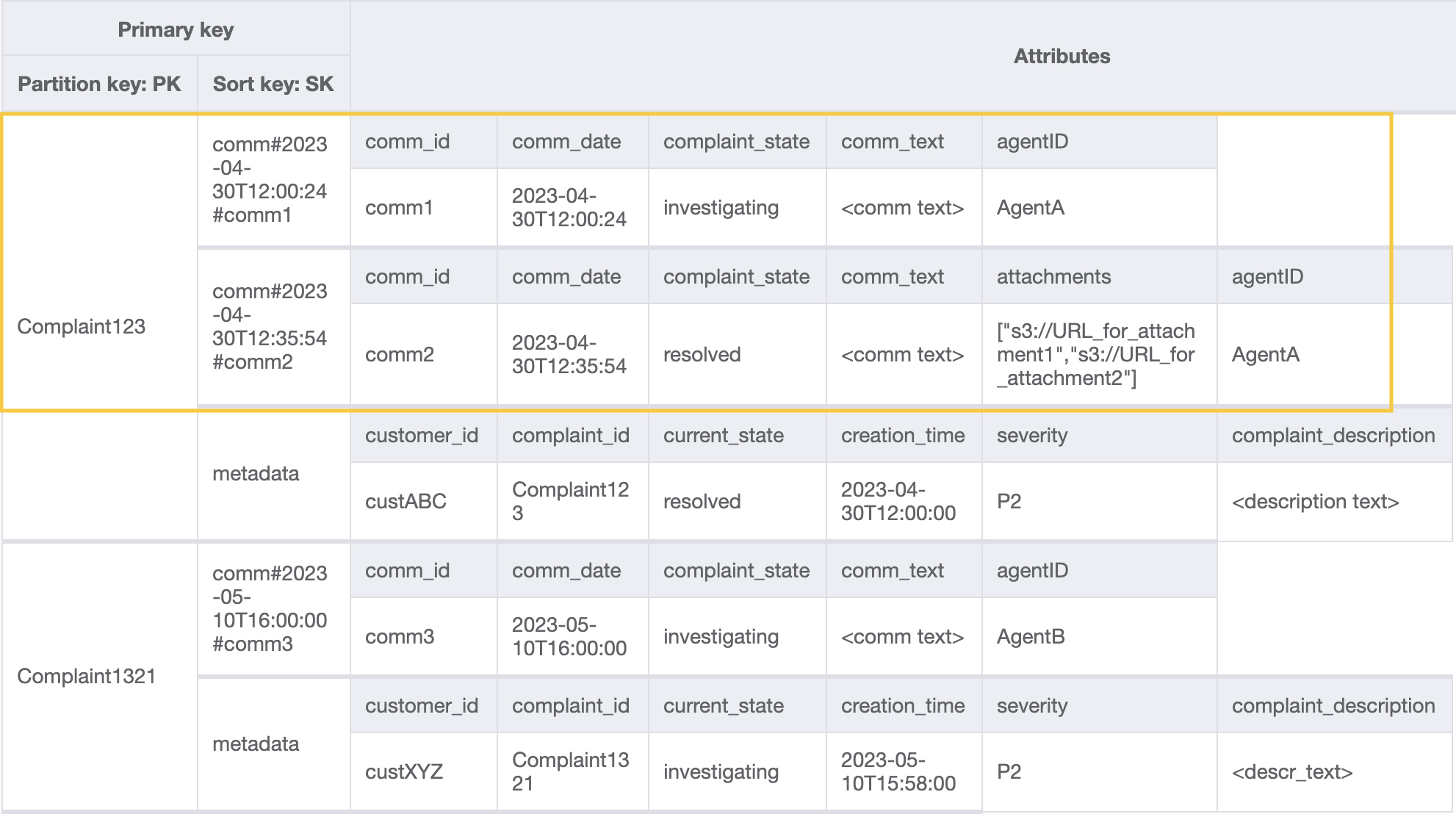
Per ottenere tutti i commenti relativi a un reclamo, possiamo utilizzare l’operazione query con la condizione begins_with sulla chiave di ordinamento. Invece di consumare capacità di lettura aggiuntiva per leggere i metadati e quindi avere il sovraccarico di filtrare i risultati pertinenti, una condizione chiave di ordinamento come questa ci aiuta a leggere solo ciò di cui abbiamo bisogno. Ad esempio, un’operazione di query con PK=Complaint123 e SK begins_with comm# restituirebbe quanto segue saltando la voce dei metadati:
Poiché abbiamo bisogno dell'ultimo commento per un reclamo nel modello 7 (getLatestCommentByComplaintID), utilizziamo due parametri di interrogazione aggiuntivi:
-
ScanIndexForwarddeve essere impostato su False per ottenere risultati ordinati in ordine decrescente -
Limitdeve essere impostato su 1 per ottenere l'ultimo commento (solo uno)
Simile allo schema di accesso 6 (getAllCommentsByComplaintID), saltiamo l'immissione dei metadati utilizzando begins_with comm# come condizione chiave di ordinamento. Ora, puoi eseguire il modello di accesso 7 su questa progettazione usando l'operazione query con PK=Complaint123 e SK=begins_with comm#, ScanIndexForward=False e Limit 1. Verrà restituito come risultato l’elemento mirato seguente:
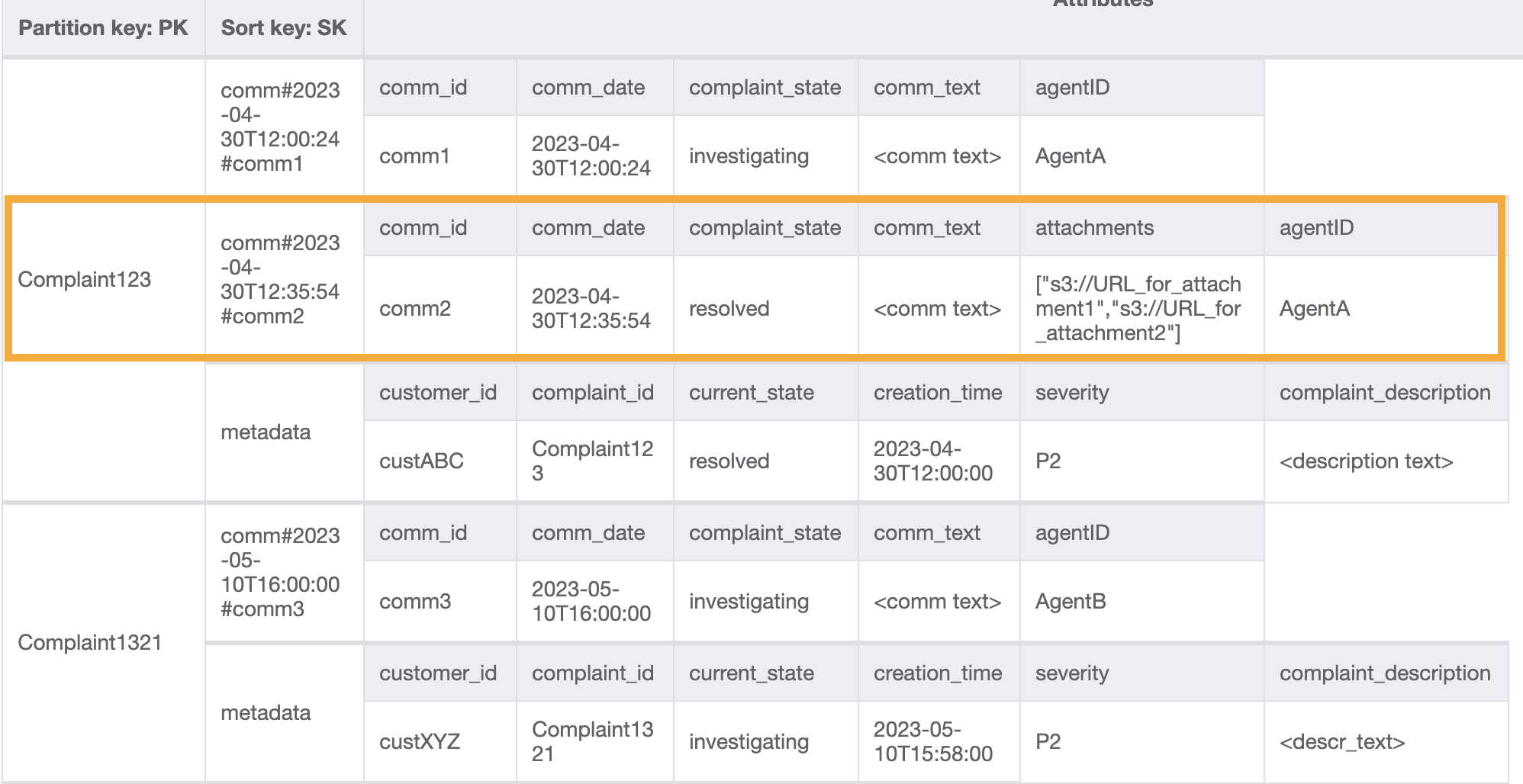
Aggiungiamo altri dati fittizi alla tabella.
Fase 4: Gestire i modelli di accesso 8 (getAComplaintbyCustomerIDAndComplaintID) e 9 (getAllComplaintsByCustomerID)
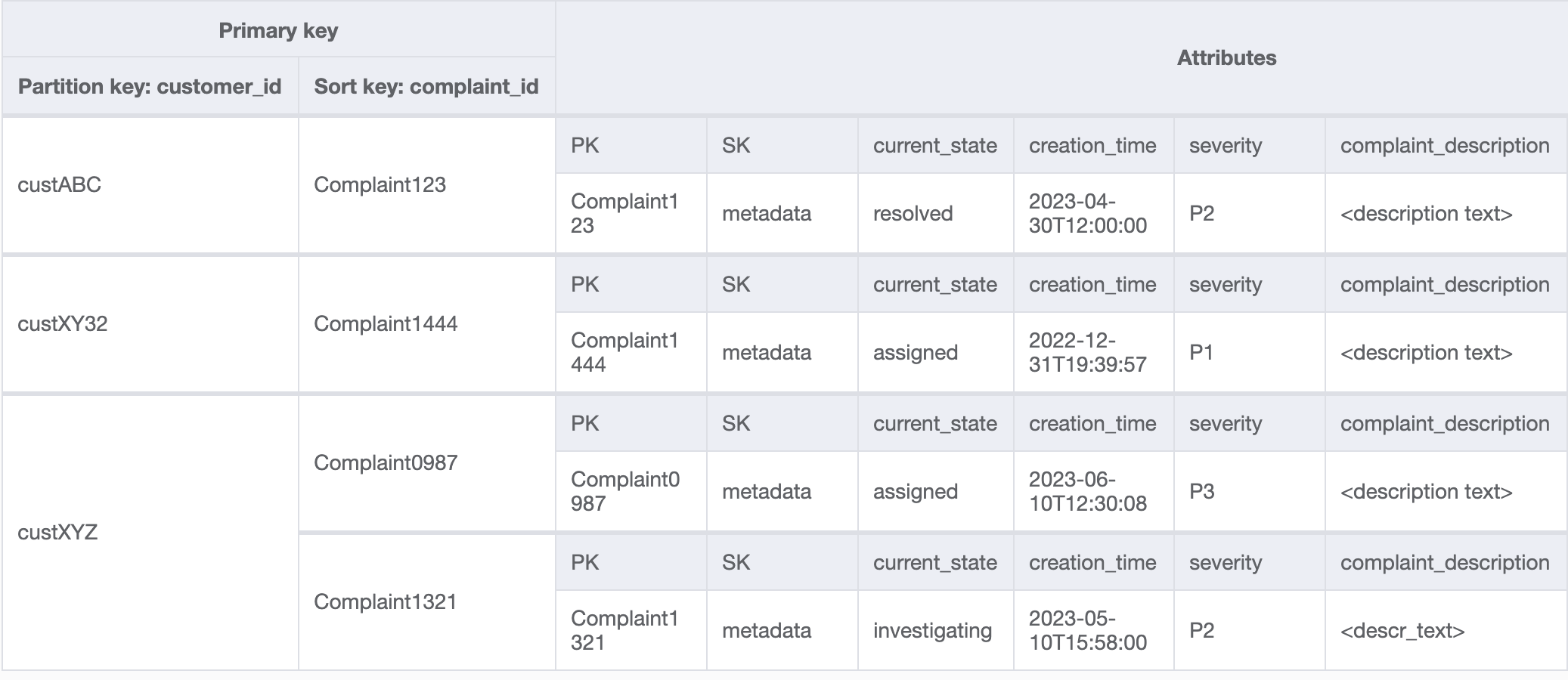
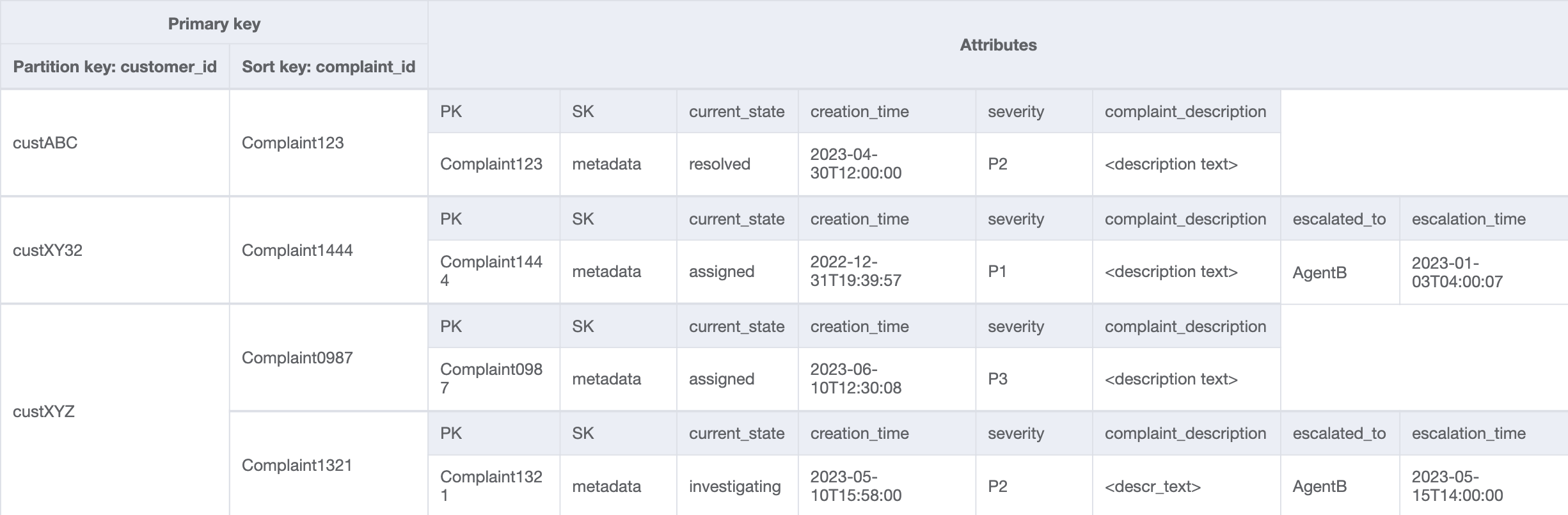
I modelli di accesso 8 (getAComplaintbyCustomerIDAndComplaintID) e 9 (getAllComplaintsByCustomerID) introducono nuovi criteri di ricerca: CustomerID. Recuperarlo dalla tabella esistente richiede una costosa Scan per leggere tutti i dati e quindi filtrare gli elementi pertinenti per il CustomerID in questione. Possiamo rendere questa ricerca più efficiente creando un indice secondario globale (GSI) con CustomerID come chiave di partizione. Tenendo presente la relazione uno-a-molti tra cliente e reclami, nonché il modello di accesso 9 (getAllComplaintsByCustomerID),ComplaintID sarebbe il candidato giusto per la chiave di ordinamento.
I dati del GSI sarebbero i seguenti:
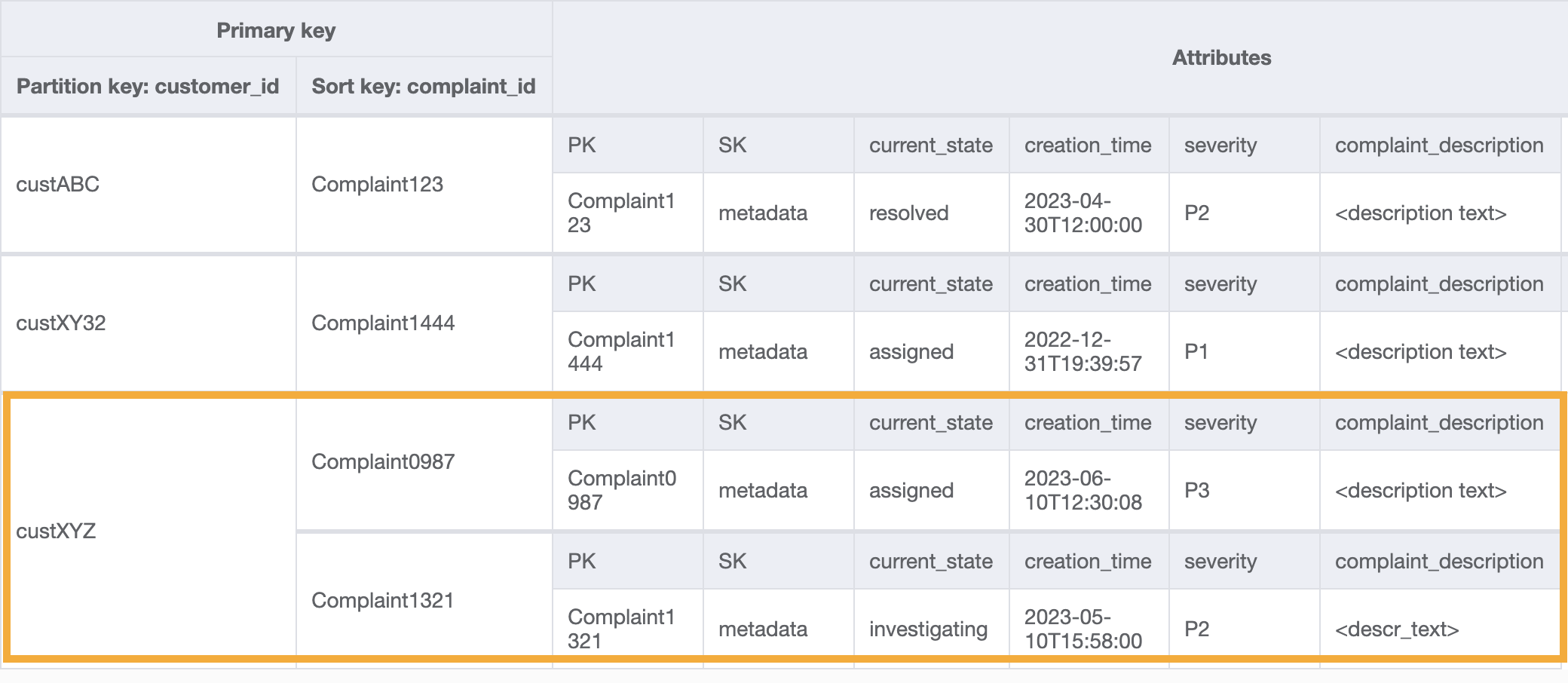
Una query di esempio su questo GSI per il modello di accesso 8 (getAComplaintbyCustomerIDAndComplaintID) sarebbe: customer_id=custXYZ, sort key=Complaint1321. Il risultato sarebbe:
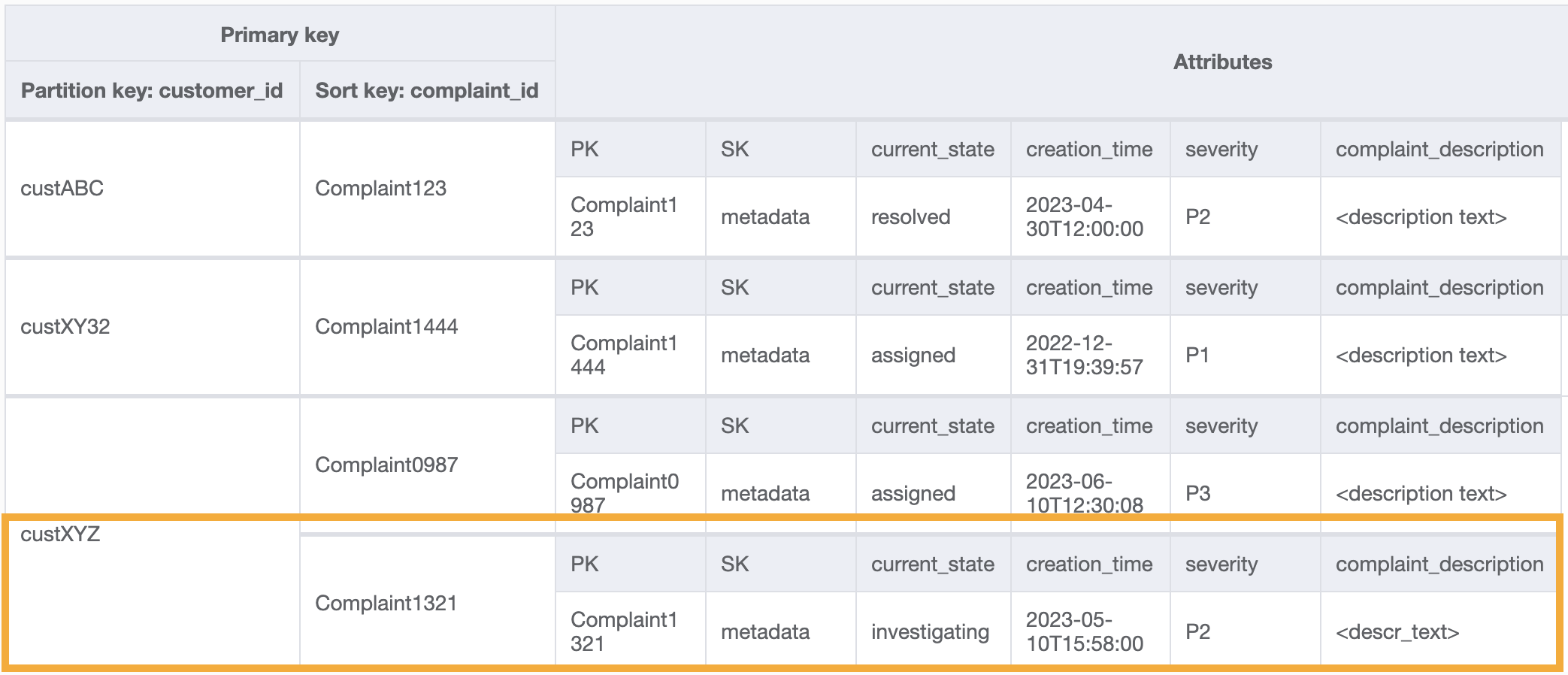
Per ricevere tutti i reclami di un cliente in merito al modello di accesso 9 (getAllComplaintsByCustomerID), la domanda sul GSI sarebbe: customer_id=custXYZ come condizione della chiave di partizione. Il risultato sarebbe:
Fase 5: Gestire il modello di accesso 10 (escalateComplaintByComplaintID)
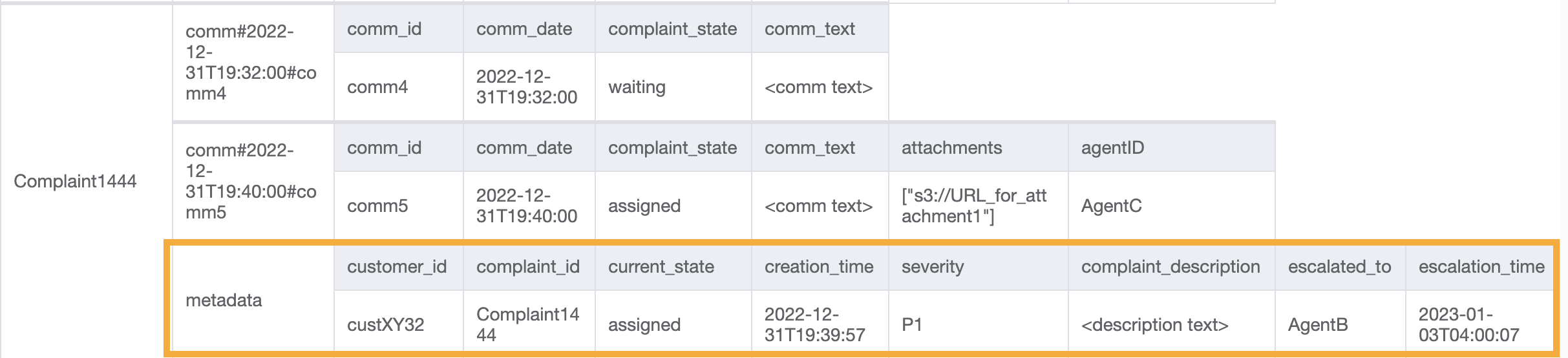
Questo accesso introduce l'aspetto dell'escalation. Per inoltrare un reclamo, possiamo usare UpdateItem per aggiungere attributi come escalated_to e escalation_time all'elemento dei metadati del reclamo esistente. DynamoDB offre una progettazione flessibile dello schema, il che significa che un insieme di attributi non chiave può essere uniforme o discreto tra diversi elementi. Un esempio è fornito di seguito.
UpdateItem with PK=Complaint1444, SK=metadata
Fase 6: Gestire i modelli di accesso 11 (getAllEscalatedComplaints) e 12 (getEscalatedComplaintsByAgentID)
Si prevede che solo alcuni reclami vengano estrapolati dall'intero set di dati. Pertanto, la creazione di un indice degli attributi relativi all'escalation porterebbe a ricerche efficienti e a uno storage GSI conveniente. Possiamo farlo sfruttando la tecnica dell’indice sparso. Il GSI con chiave di partizione come escalated_to e chiave di ordinamento come escalation_time sarebbe simile a questo:

Per ricevere tutti i reclami più elevati relativi allo schema di accesso 11 (getAllEscalatedComplaints), eseguiamo semplicemente la scansione di questo GSI. Tieni presente che questa scansione sarà efficiente ed economica a causa delle dimensioni del GSI. Per ricevere reclami più elevati per un agente specifico (shema di accesso 12 (getEscalatedComplaintsByAgentID)), la chiave di partizione sarebbe escalated_to=agentID e abbiamo impostato ScanIndexForward su False per ordinare dal più recente al meno recente.
Fase 7: Gestire il modello di accesso 13 (getCommentsByAgentID)
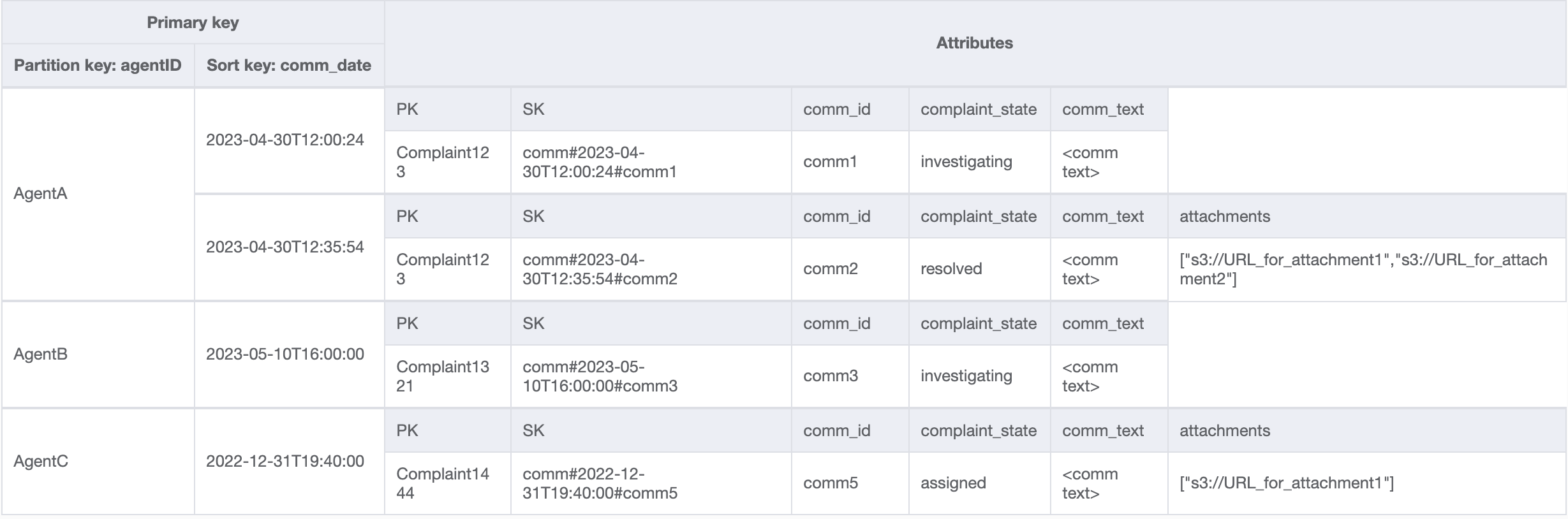
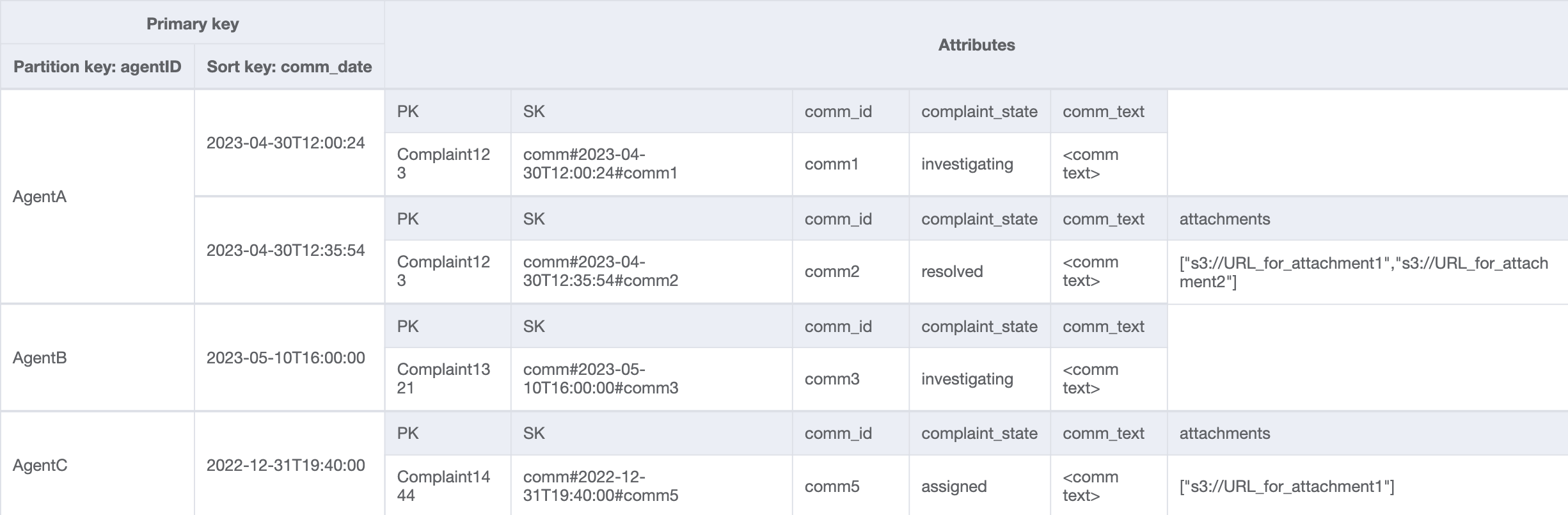
Per l'ultimo schema di accesso, dobbiamo eseguire una ricerca in base a una nuova dimensione: AgentID. Abbiamo anche bisogno di un ordine temporale per leggere i commenti tra due date, quindi creiamo un GSI con agent_id come chiave di partizione e comm_date come chiave di ordinamento. I dati di questo GSI saranno simili ai seguenti:
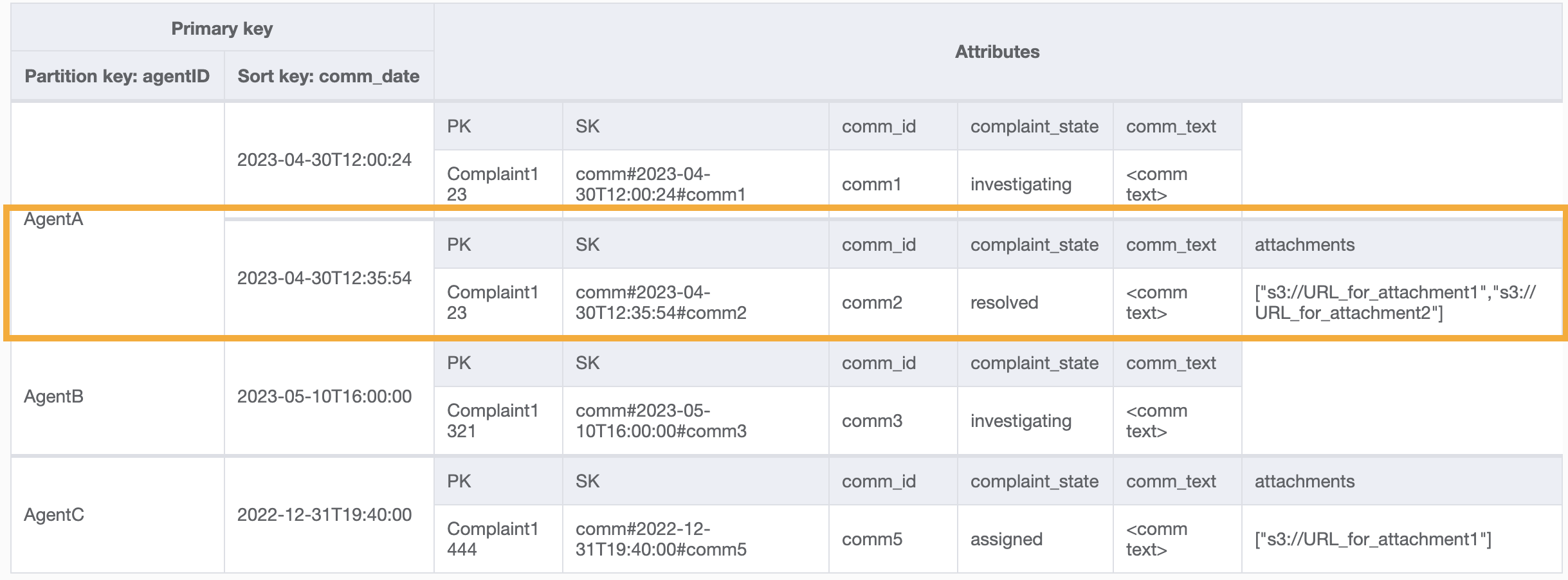
Una domanda di esempio su questo GSI potrebbe essere partition key agentID=AgentA e sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00), il cui risultato è:
Tutti i modelli di accesso e il modo in cui la progettazione dello schema li affronta sono riassunti nella tabella seguente:
| Modello di accesso | Base table/GSI /LSI | Operation | Valore della chiave di partizione | Valore della chiave di ordinamento | Altro conditions/filters |
|---|---|---|---|---|---|
| createComplaint | Tabella di base | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | Tabella di base | UpdateItem | PK=complaint_id | SK=metadata | |
| aggiorna SeveritybyComplaint ID | Tabella di base | UpdateItem | PK=complaint_id | SK=metadata | |
| ottenere ComplaintByComplaintID | Tabella di base | GetItem | PK=complaint_id | SK=metadata | |
| aggiungere CommentByComplaintID | Tabella di base | TransactWriteItems | PK=complaint_id | SK=metadata, SK=comm#comm_date#comm_id | |
| ottenere AllCommentsByComplaintID | Tabella di base | Query | PK=complaint_id | SK begins_with "comm#" | |
| ottenere LatestCommentByComplaintID | Tabella di base | Query | PK=complaint_id | SK begins_with "comm#" | scan_index_forward=False, Limit 1 |
| ottenere AComplaintbyCustomerIDAndComplaintID | Customer_complaint_GSI | Query | customer_id=customer_id | complaint_id = complaint_id | |
| ottenere AllComplaintsByCustomerID | Customer_complaint_GSI | Query | customer_id=customer_id | N/A | |
| intensificare ComplaintByComplaintID | Tabella di base | UpdateItem | PK=complaint_id | SK=metadata | |
| ottenere AllEscalatedComplaints | Escalations_GSI | Scan | N/A | N/A | |
| get EscalatedComplaintsByAgentID (ordina dal più recente al più vecchio) | Escalations_GSI | Query | escalated_to=agent_id | N/A | scan_index_forward=False |
| get CommentsByAgentID (tra due date) | Agents_Comments_GSI | Query | agent_id=agent_id | SK between (date1, date2) |
Schema finale del sistema di gestione dei reclami
Di seguito sono riportate le progettazioni dello schema finale. Per scaricare questo schema come file JSON, consulta Esempi di DynamoDB
Tabella di base
Customer_Complaint_GSI
Escalations_GSI

Agents_Comments_GSI
Utilizzo di NoSQL Workbench con questa progettazione dello schema
Puoi importare questo schema finale in NoSQL Workbench, uno strumento visivo che fornisce funzionalità di modellazione dei dati, visualizzazione dei dati e sviluppo di query per DynamoDB, per esplorare e modificare ulteriormente il tuo nuovo progetto. Per iniziare, segui queste fasi:
-
Scarica NoSQL Workbench. Per ulteriori informazioni, consulta Download di NoSQL Workbench per DynamoDB.
-
Scarica il file dello schema JSON elencato in precedenza, che si trova già nel formato del modello NoSQL Workbench.
-
Importa il file dello schema JSON in NoSQL Workbench. Per ulteriori informazioni, consulta Importazione di un modello di dati esistente.
-
Dopo che è stato importato in NOSQL Workbench, puoi modificare il modello di dati. Per ulteriori informazioni, consulta Modifica di un modello di dati esistente.
