Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Elementi costitutivi della modellazione dei dati in DynamoDB
In questa sezione verranno descritti i modelli di progettazione (o elementi costitutivi) che puoi utilizzare per l'applicazione.
Argomenti
Blocco costitutivo di chiave di ordinamento composita
Si potrebbe pensare a NoSQL come a un database non relazionale. In definitiva, non c'è un motivo per cui le relazioni non possono essere inserite in uno schema DynamoDB; hanno semplicemente un aspetto diverso rispetto ai database relazionali e alle relative chiavi esterne. Uno dei modelli più critici che possiamo utilizzare per sviluppare una gerarchia logica dei dati in DynamoDB è una chiave di ordinamento composita. Lo stile di progettazione più comune è quello in cui ogni livello della gerarchia (livello padre > livello figlio > livello nipote) è separato da un hashtag. Ad esempio, PARENT#CHILD#GRANDCHILD#ETC.
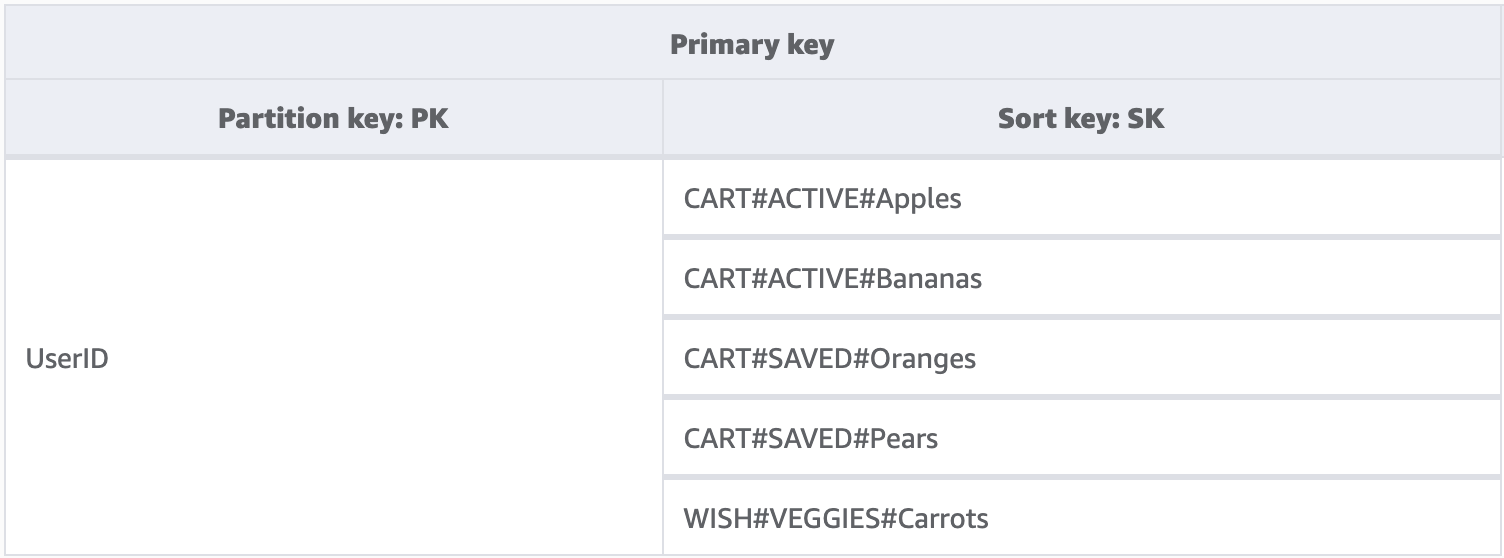
Sebbene una chiave di partizione in DynamoDB richieda sempre il valore esatto per eseguire query sui dati, possiamo applicare alla chiave di ordinamento una condizione parziale da sinistra a destra, simile all'attraversamento di un albero binario.
Nell'esempio precedente, è disponibile un negozio di e-commerce con un carrello acquisti che deve essere mantenuto tra le sessioni utente. Ogni volta che l'utente esegue l'accesso, può scegliere di visualizzare l'intero carrello acquisti, inclusi gli elementi salvati per uso futuro. Tuttavia, al momento del pagamento, solo gli elementi nel carrello attivo devono essere caricati per l'acquisto. Poiché entrambe le KeyConditions richiedono esplicitamente le chiavi di ordinamento CART, i dati della lista dei desideri aggiuntivi vengono semplicemente ignorati da DynamoDB in fase di lettura. Sebbene gli elementi salvati e attivi facciano entrambi parte dello stesso carrello, devono essere gestiti in modo diverso nelle diverse parti dell'applicazione. Pertanto, l'applicazione di una KeyCondition al prefisso della chiave di ordinamento è il modo più ottimizzato per recuperare solo i dati necessari per ciascuna parte dell'applicazione.
Funzionalità principali di questo elemento costitutivo
-
Gli elementi correlati vengono archiviati localmente tra loro per un accesso ai dati conveniente.
-
Utilizzando
KeyConditionle espressioni, i sottoinsiemi della gerarchia possono essere recuperati selettivamente, il che significa che non vengono sprecati RCUs -
Parti differenti dell'applicazione possono archiviare i relativi elementi sotto un prefisso specifico, evitando elementi sovrascritti o scritture in conflitto.
Elemento costitutivo di multilocazione
Molti clienti utilizzano DynamoDB per ospitare dati per applicazioni multi-tenant. Per questi scenari, desideriamo progettare lo schema in modo da mantenere tutti i dati di un singolo tenant nella propria partizione logica della tabella. Questo sfrutta il concetto di raccolta di elementi, che è un termine per tutti gli elementi in una tabella DynamoDB con la stessa chiave di partizione. Per ulteriori informazioni su come DynamoDB approccia la multilocazione, consulta Multitenancy on DynamoDB.
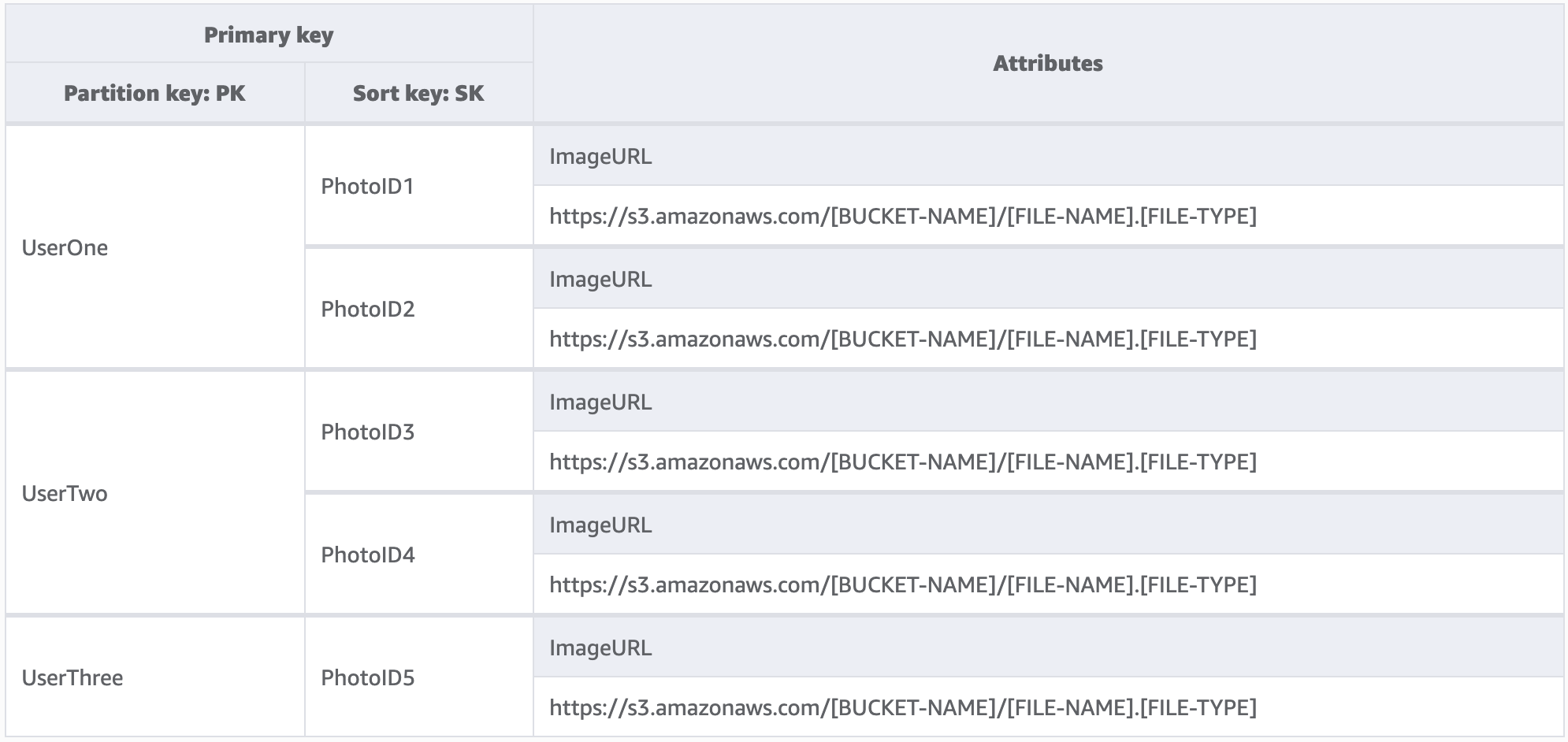
In questo esempio, gestiamo un sito di hosting di foto con potenzialmente migliaia di utenti. Inizialmente ogni utente caricherà foto solo sul proprio profilo, ma per impostazione predefinita un utente non può visualizzare le foto di qualsiasi altro utente. L'aggiunta di un ulteriore livello di isolamento all'autorizzazione della chiamata di ciascun utente all'API sarebbe ideale per garantire che i dati vengano richiesti solo dalla propria partizione, ma a livello di schema, le chiavi di partizione univoche sono sufficienti.
Funzionalità principali di questo elemento costitutivo
-
La quantità di dati letta da qualsiasi utente o tenant può essere solo pari alla quantità totale di elementi nella relativa partizione
-
La rimozione dei dati di un tenant a causa della chiusura di un account o di una richiesta di conformità può essere effettuata in modo discreto ed economico. Esegui semplicemente una query in cui la chiave di partizione è uguale al relativo ID tenant, quindi esegui un'operazione
DeleteItemper ciascuna chiave primaria restituita
Nota
Progettato pensando alla multi-tenancy, è possibile utilizzare diversi provider di chiavi di crittografia su un'unica tabella per isolare i dati in modo sicuro. L'AWS SDK di crittografia del database per Amazon DynamoDB consente di includere la crittografia lato client nei carichi di lavoro DynamoDB. Puoi eseguire la crittografia a livello di attributo, che ti consente di crittografare valori di attributo specifici prima di archiviarli nella tabella DynamoDB e di cercare attributi crittografati senza prima decrittografare l'intero database.
Elemento costitutivo di indice Sparse
A volte un modello di accesso richiede la ricerca di elementi che corrispondono a un elemento raro o a un elemento che riceve uno stato (che richiede una risposta riassegnata). Anziché eseguire regolarmente query sull'intero set di dati per questi elementi, possiamo sfruttare il fatto che gli indici secondari globali (GSI) sono scarsamente caricati con dati. Ciò significa che solo gli elementi della tabella di base che dispongono degli attributi definiti nell'indice verranno replicati nell'indice.
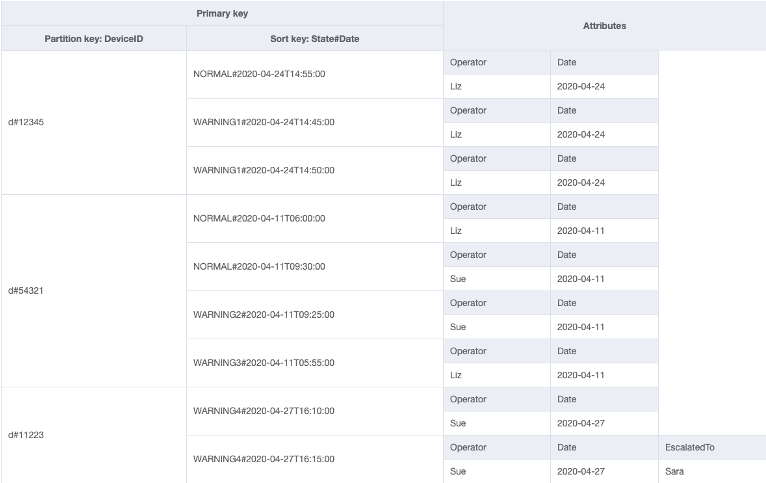

In questo esempio, possiamo vedere un caso d'uso IOT in cui ciascun dispositivo sul campo segnala periodicamente uno stato. Per la maggior parte dei report, ci aspettiamo che il dispositivo segnali tutto, ma a volte può essere presente un guasto che deve essere riassegnato a un tecnico di riparazione. Per i report con un'escalation, l'attributo EscalatedTo viene aggiunto all'elemento, ma non è altrimenti presente. Il GSI in questo esempio è partizionato da EscalatedTo e, poiché il GSI porta con sé chiavi della tabella di base, possiamo ancora vedere quale DeviceID ha segnalato il guasto e a che ora.
Sebbene le letture siano più economiche delle scritture in DynamoDB, gli indici Sparse sono uno strumento molto potente per casi d'uso in cui le istanze di un tipo di elemento specifico sono rare, ma le letture per trovarle sono comuni.
Funzionalità principali di questo elemento costitutivo
-
I costi di scrittura e archiviazione per il GSI sparso si applicano solo agli elementi che corrispondono allo schema di chiave, quindi il costo del GSI può essere sostanzialmente inferiore rispetto ad altri in cui sono replicati tutti gli elementi GSIs
-
Una chiave di ordinamento composita può ancora essere utilizzata per restringere ulteriormente gli elementi che corrispondono alla query desiderata. Ad esempio, è possibile utilizzare un timestamp per la chiave di ordinamento per visualizzare solo i guasti segnalati negli ultimi X minuti (
SK > 5 minutes ago, ScanIndexForward: False)
Elemento costitutivo di Time to Live
La maggior parte dei dati ha una certa durata per cui può essere considerato utile mantenerli in un datastore primario. Per facilitare l'uscita dei dati da DynamoDB, è disponibile una funzionalità chiamata Time to Live (TTL). La funzionalità TTL consente di definire un attributo specifico a livello di tabella che deve essere monitorato per gli elementi con un timestamp epoch (che appartiene al passato). Ciò consente di eliminare gratuitamente i record scaduti dalla tabella.
Nota
Se si utilizzano le Tabelle globali versione 2019.11.21 (Corrente) e si utilizza anche la funzionalità Time to Live, DynamoDB replica le eliminazioni TTL in tutte le tabelle di replica. L'eliminazione TTL iniziale non consuma capacità di scrittura nella regione in cui si verifica la scadenza del TTL. Tuttavia, l'eliminazione TTL replicata nelle tabelle di replica consuma capacità di scrittura replicata in ciascuna regione di replica e verranno addebitati i costi applicabili.
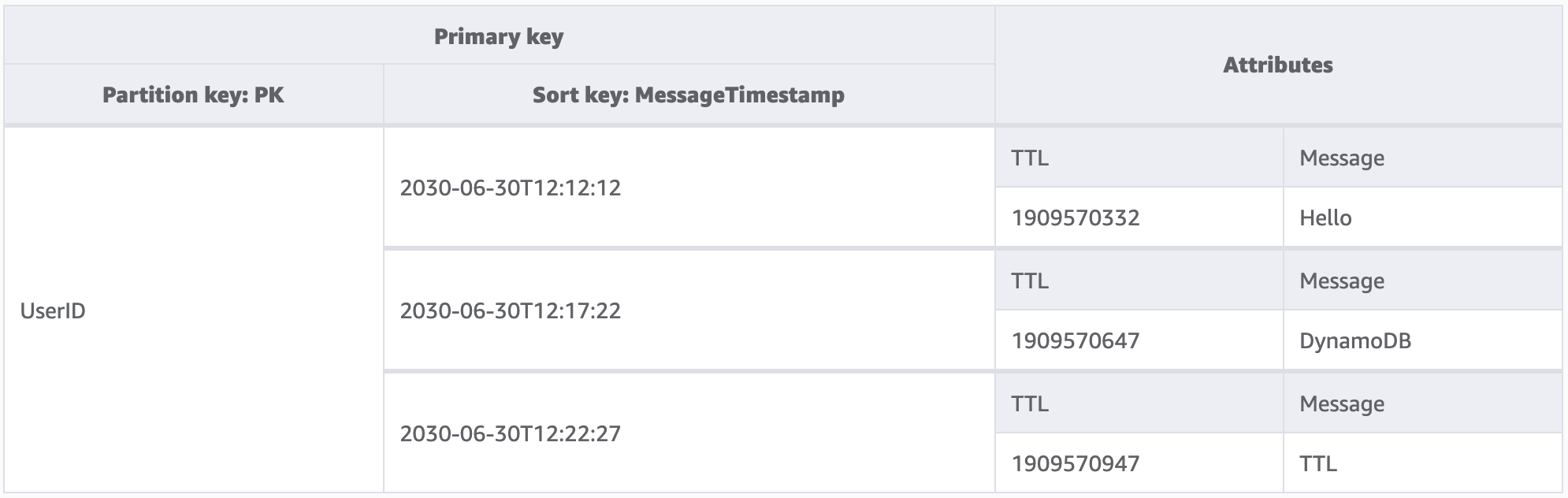
In questo esempio, è disponibile un'applicazione progettata per consentire a un utente di creare messaggi di breve durata. Quando un messaggio viene creato in DynamoDB, l'attributo TTL viene impostato su una data sette giorni nel futuro dal codice dell'applicazione. In circa sette giorni, DynamoDB rileverà che il timestamp di epoca di questi elementi appartiene al passato e li eliminerà.
Poiché le eliminazioni effettuate dal TTL sono gratuite, si consiglia di utilizzare questa funzionalità per rimuovere i dati storici dalla tabella. Ciò ridurrà le spese mensili di archiviazione complessive e i costi delle letture utente poiché le query devono recuperare una quantità minore di dati. Sebbene TTL sia abilitato a livello di tabella, l'utente deve decidere per quali elementi o entità creare un attributo TTL e fino a quando nel futuro impostare il timestamp di epoca.
Funzionalità principali di questo elemento costitutivo
-
Eliminazioni TTL vengono eseguite dietro le quinte senza ripercussioni sulle prestazioni della tabella
-
TTL è un processo asincrono che viene eseguito all'incirca ogni sei ore, ma l'eliminazione di un record scaduto può richiedere oltre 48 ore
-
Non fare affidamento sulle eliminazioni TTL per casi d'uso come record di blocco o gestione dello stato, se i dati obsoleti devono essere eliminati in meno di 48 ore
-
-
Puoi assegnare all'attributo TTL un nome attributo valido, ma il valore deve essere un tipo numero
Time to Live per elemento costitutivo di archiviazione
Sebbene TTL sia uno strumento efficace per eliminare dati meno recenti da DynamoDB, molti casi d'uso richiedono che un archivio dei dati venga mantenuto per un periodo di tempo più lungo rispetto al datastore principale. In questo caso, è possibile sfruttare l'eliminazione temporizzata dei record di TTL per inviare i record scaduti in un datastore a lungo termine.
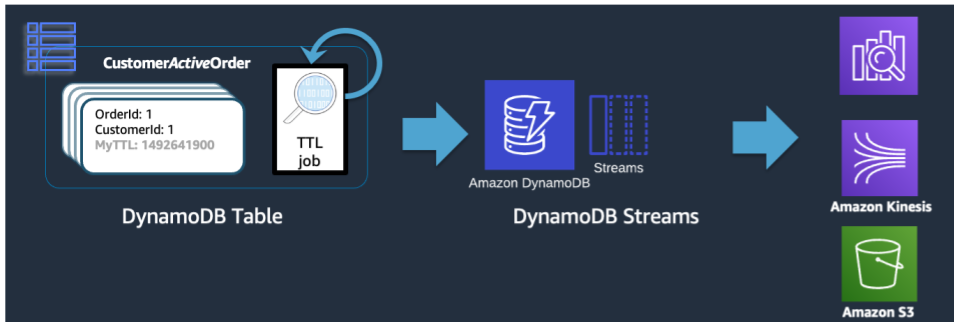
Quando un'eliminazione TTL viene eseguita da DynamoDB, viene ancora inviata nel flusso DynamoDB come un evento Delete. Tuttavia, quando TTL DynamoDB è quello che esegue l'eliminazione, nel record di flusso è presente un attributo di principal:dynamodb. Utilizzando un abbonato Lambda a DynamoDB Stream, possiamo applicare un filtro eventi solo per l'attributo principale di DynamoDB e sapere che tutti i record che corrispondono a quel filtro devono essere inviati a un archivio come Amazon Glacier.
Funzionalità principali di questo elemento costitutivo
-
Una volta che le letture a bassa latenza di DynamoDB non sono più necessarie per gli elementi storici, la loro migrazione a un servizio di storage più freddo come Amazon Glacier può ridurre significativamente i costi di storage, soddisfacendo al contempo le esigenze di conformità dei dati del tuo caso d'uso
-
Se i dati vengono mantenuti in Amazon S3, è possibile utilizzare strumenti di analisi economici come Amazon Athena o Redshift Spectrum per eseguire l'analisi storica dei dati
Elemento costitutivo di partizionamento verticale
Gli utenti che hanno familiarità con un database di modelli di documenti sono a conoscenza dell'idea di archiviare tutti i dati correlati all'interno di un singolo documento JSON. Sebbene DynamoDB supporti i tipi di dati JSON, non supporta l’esecuzione di KeyConditions su JSON annidati. Poiché KeyConditions sono i fattori che determinano la quantità di dati letti dal disco e il numero effettivo di dati consumati da RCUs una query, ciò può comportare inefficienze su larga scala. Per ottimizzare meglio le scritture e le letture di DynamoDB, si consiglia di suddividere le singole entità del documento in singoli elementi DynamoDB, operazione nota anche come partizionamento verticale.

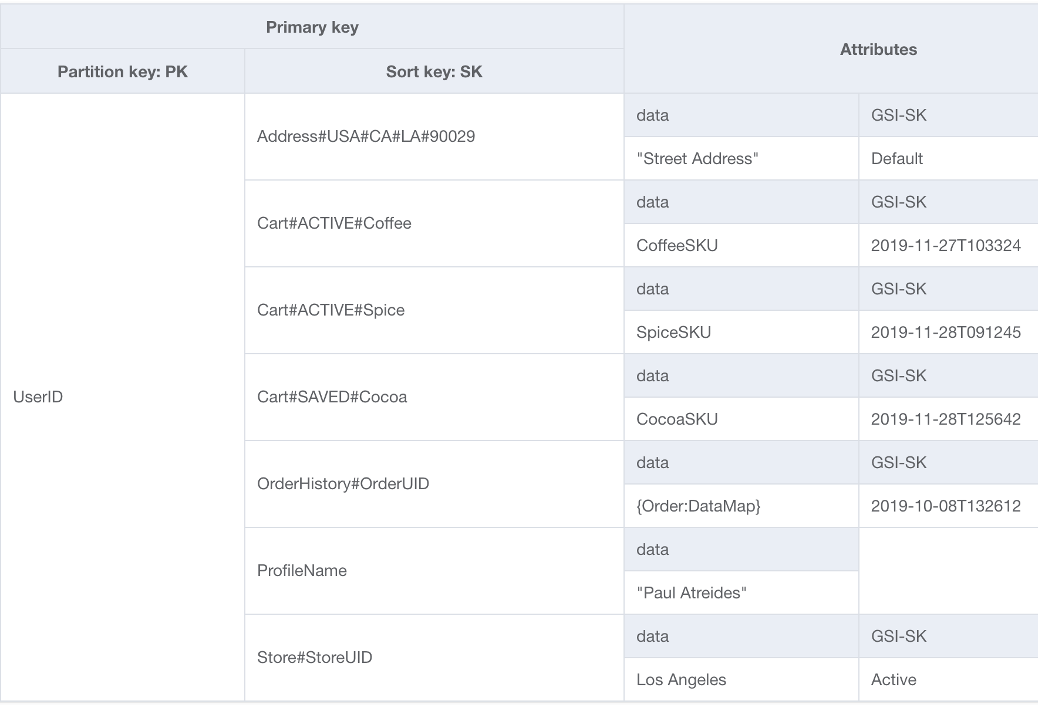
Il partizionamento verticale, come mostrato in precedenza, è un esempio chiave di progettazione tabella singola, ma può anche essere implementato su più tabelle, se lo si desidera. Poiché DynamoDB addebita le scritture in incrementi di 1 KB, devi partizionare idealmente il documento in un modo che generi inferiori a 1 KB.
Funzionalità principali di questo elemento costitutivo
-
Una gerarchia di relazioni dei dati viene mantenuta tramite prefissi delle chiavi di ordinamento, in modo che la singola struttura del documento possa essere ricostruita lato client, se necessario
-
I singoli componenti della struttura di dati possono essere aggiornati in maniera indipendente, determinando piccoli aggiornamenti elemento di solo 1 WCU
-
Utilizzando la chiave di ordinamento
BeginsWith, l'applicazione può recuperare dati simili in una singola query, aggregando i costi di lettura per ridurre il costo/la latenza totale -
I documenti di grandi dimensioni possono facilmente superare il limite di dimensioni del singolo elemento di 400 KB in DynamoDB e il partizionamento verticale consente di aggirare questo limite
Elemento costitutivo di partizionamento di scrittura
Uno dei pochi limiti fissi implementati da DynamoDB è la limitazione della velocità di trasmissione effettiva che una singola partizione fisica può mantenere al secondo (non necessariamente una singola chiave di partizione). Questi limiti sono attualmente:
-
1.000 WCU (o 1.000 <=1 KB elementi scritti al secondo) e 3.000 RCU (o 3.000 <=4 KB letture al secondo) fortemente coerenti o
-
6000 <=4 KB letture al secondo a consistenza finale
Nel caso in cui le richieste rispetto alla tabella superino uno di questi limiti, un errore di ThroughputExceededException, più comunemente noto come limitazione (della larghezza di banda della rete), viene restituito all'SDK client. I casi d'uso che richiedono operazioni di lettura oltre tale limite saranno per lo più gestiti al meglio posizionando una cache di lettura davanti a DynamoDB, ma le operazioni di scrittura richiedono una progettazione a livello di schema nota come partizionamento di scrittura.
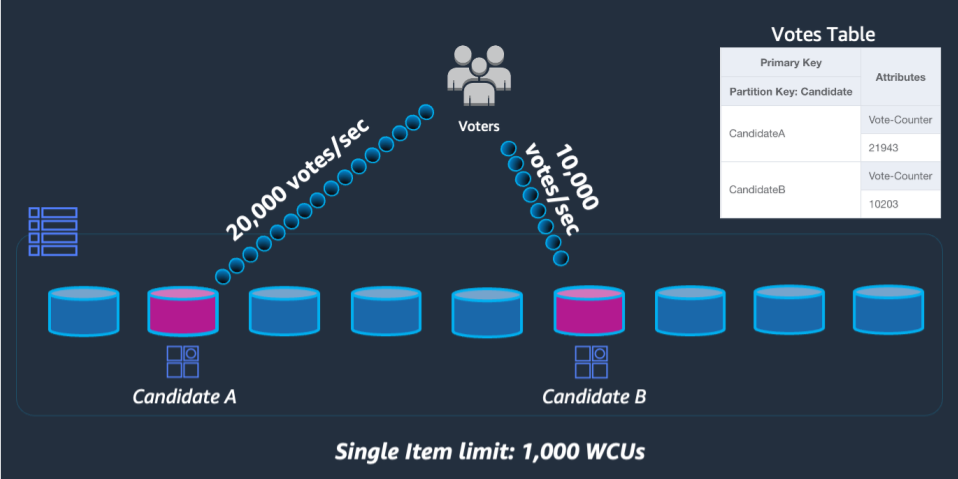
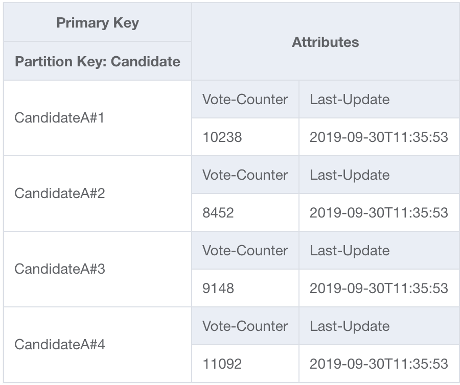
Per risolvere questo problema, un numero intero casuale verrà aggiunto alla fine della chiave di partizione per ogni partecipante nel codice UpdateItem dell'applicazione. L'intervallo del generatore di numeri interi casuali dovrà avere un limite superiore che corrisponde o supera la quantità prevista di scritture al secondo per un determinato partecipante diviso 1000. Per supportare 20.000 voti al secondo, l'aspetto è simile a rand (0,19). Ora che i dati sono archiviati in partizioni logiche separate, devono essere ricombinati in fase di lettura. Poiché i totali dei voti non devono essere in tempo reale, una funzione Lambda pianificata per leggere tutte le partizioni di voto ogni X minuti può eseguire un'aggregazione occasionale per ogni partecipante e riscriverla in un singolo record totale di voti per le letture dal vivo.
Funzionalità principali di questo elemento costitutivo
-
Per casi d'uso con una velocità di trasmissione effettiva di scrittura estremamente elevata per una determinata chiave di partizione che non può essere evitata, le operazioni di scrittura possono essere distribuite artificialmente su più partizioni DynamoDB
-
GSIs anche con una chiave di partizione a bassa cardinalità dovrebbe utilizzare questo schema, poiché la limitazione su un GSI applicherà una contropressione alle operazioni di scrittura sulla tabella di base
