Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per la modellazione dei dati relazionali in DynamoDB
Questa sezione fornisce best practice per la modellazione dei dati relazionali in Amazon DynamoDB. Innanzitutto, presentiamo i concetti tradizionali di modellazione dei dati. Quindi, descriviamo i vantaggi dell'utilizzo di DynamoDB rispetto ai tradizionali sistemi di gestione di database relazionali e in che modo elimina la necessità di operazioni JOIN e riduce il sovraccarico.
Illustriamo quindi come progettare una tabella DynamoDB dimensionabile in modo efficiente. Infine, forniamo un esempio di come modellare i dati relazionali in DynamoDB.
Argomenti
Modelli di database relazionali tradizionali
I sistemi di gestione dei database relazionali (RDBMS) tradizionali archiviano i dati in una struttura relazionale normalizzata. L'obiettivo del modello di dati relazionali è ridurre la duplicazione dei dati (attraverso la normalizzazione) per supportare l'integrità referenziale e ridurre le anomalie dei dati.
Lo schema seguente è un esempio di modello di dati relazionale per un'applicazione generica di immissione degli ordini. L'applicazione supporta uno schema delle risorse umane che supporta i sistemi di supporto operativi e aziendali di un produttore ipotetico.
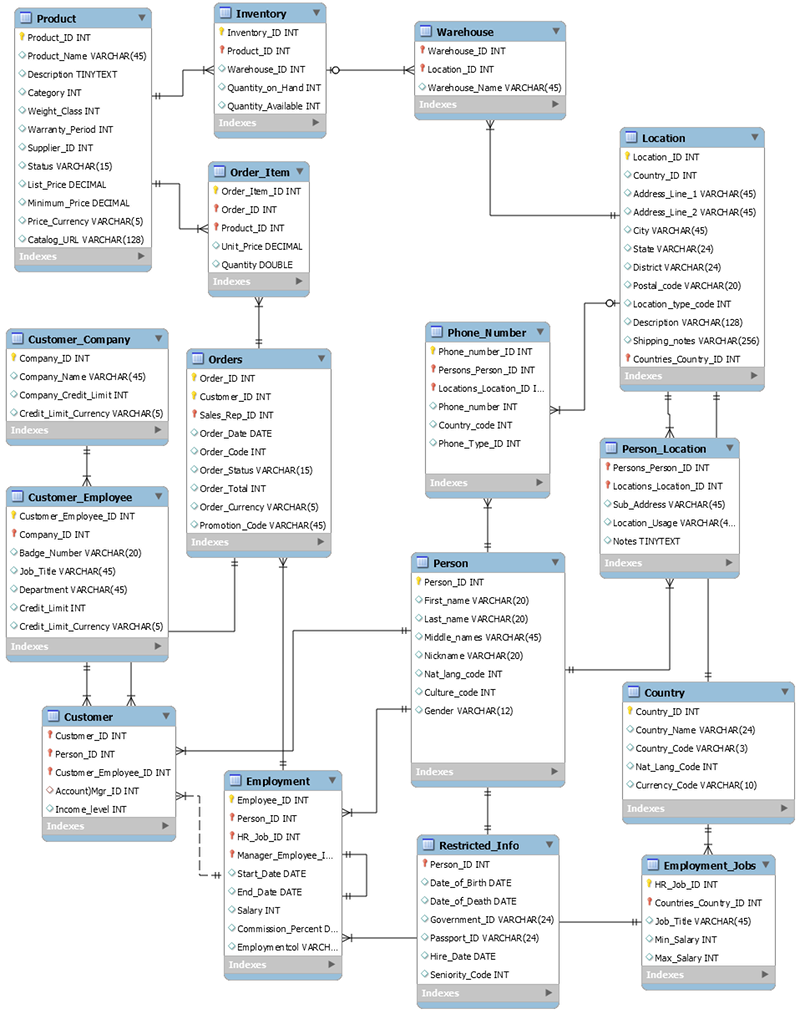
In quanto servizio di database non relazionale, DynamoDB offre molti vantaggi rispetto ai tradizionali sistemi di gestione di database relazionali.
In che modo DynamoDB elimina la necessità di operazioni JOIN
Un RDBMS utilizza un linguaggio SQL (Structure Query Language) per restituire i dati all'applicazione. A causa della normalizzazione del modello di dati, tali query richiedono in genere l'uso dell'operatore JOIN per combinare i dati di una o più tabelle.
Ad esempio, per generare un elenco di articoli dell'ordine d'acquisto ordinati in base alla quantità disponibile in tutti i magazzini che possono spedire tale articolo, puoi eseguire la query SQL seguente nello schema precedente.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCLe query SQL di questo tipo possono fornire un'API flessibile per accedere ai dati, ma richiedono un alto livello di elaborazione. Ogni join nella query aumenta la complessità del runtime della query perché i dati di ogni tabella devono essere suddivisi in fasi e quindi assemblati per restituire il set di risultati.
Altri fattori che possono influire sul tempo impiegato per l'esecuzione delle query sono la dimensione delle tabelle e la presenza di indici nelle colonne da unire. La query precedente avvia query complesse in diverse tabelle e poi ordina il set di risultati.
L'eliminazione della necessità di JOINs è la base della modellazione dei dati NoSQL. Questo è il motivo per cui abbiamo creato DynamoDB per Amazon.com supportare e perché DynamoDB è in grado di offrire prestazioni costanti su qualsiasi scala. Data la complessità di runtime delle query SQL e RDBMSJOINs, le prestazioni non sono costanti su larga scala. Ciò causa problemi di prestazioni man mano che le applicazioni dei clienti aumentano.
Sebbene la normalizzazione dei dati riduca la quantità di dati archiviati su disco, spesso le risorse più limitate che influiscono sulle prestazioni sono il tempo della CPU e la latenza della rete.
DynamoDB è progettato per ridurre al minimo entrambi i vincoli eliminando JOINs (e incoraggiando la denormalizzazione dei dati) e ottimizzando l'architettura del database per rispondere completamente a una query dell'applicazione con una singola richiesta a un elemento. Queste qualità consentono a DynamoDB di fornire prestazioni a una cifra in millisecondi su qualsiasi scala. Questo perché la complessità del runtime delle operazioni DynamoDB è costante, indipendentemente dalla dimensione dei dati, per i modelli di accesso comuni.
In che modo le transazioni DynamoDB eliminano il sovraccarico del processo di scrittura
Un altro fattore che può rallentare un RDBMS è l'uso di transazioni per scrivere in uno schema normalizzato. Come indicato nell'esempio, le strutture dei dati relazionali utilizzate dalla maggior parte delle applicazioni (OLTP) devono essere suddivise e distribuite in più tabelle logiche quando sono archiviate in un sistema RDBMS.
Pertanto, è necessario un framework di ACID-compliant transazioni per evitare condizioni di gara e problemi di integrità dei dati che potrebbero verificarsi se un'applicazione tenta di leggere un oggetto in fase di scrittura. Un tale framework di transazioni, se abbinato a uno schema relazionale, può aggiungere un sovraccarico significativo al processo di scrittura.
L'implementazione delle transazioni in DynamoDB impedisce i problemi di scalabilità comuni riscontrati con un RDBMS. DynamoDB esegue questa operazione emettendo una transazione come singola chiamata API e limitando il numero di elementi a cui è possibile accedere in quella singola transazione. Long-running le transazioni possono causare problemi operativi poiché mantengono i dati bloccati per un lungo periodo di tempo o in modo perpetuo, poiché la transazione non viene mai chiusa.
Per prevenire tali problemi in DynamoDB, le transazioni sono state implementate con due operazioni API distinte: TransactWriteItems e TransactGetItems. Queste operazioni API non hanno una semantica di inizio e fine comune in un RDBMS. Inoltre, DynamoDB ha un limite di accesso di 100 elementi in una transazione per prevenire allo stesso modo transazioni di lunga durata. Per ulteriori informazioni sulle transazioni DynamoDB, consulta Utilizzo delle transazioni.
Per questi motivi, se la tua azienda ha bisogno di una risposta a bassa latenza alle query a traffico elevato, lo sfruttamento di un sistema NoSQL ha senso dal punto di vista tecnico ed economico. Amazon DynamoDB aiuta a risolvere i problemi che limitano la scalabilità del sistema relazionale evitandoli.
Le prestazioni di un RDBMS in genere non sono sufficientemente scalabili per i seguenti motivi:
-
Utilizza join costosi per riassemblare le visualizzazioni richieste dei risultati delle query.
-
Normalizza i dati e li archivia in tabelle multiple che richiedono query multiple da scrivere nel disco.
-
In genere comporta i costi prestazionali di un sistema di transazioni. ACID-compliant
DynamoDB si ridimensiona bene per questi motivi:
-
La flessibilità dello schema permette a DynamoDB di archiviare i dati gerarchici complessi in un singolo elemento.
-
La progettazione della chiave composita gli permette di archiviare voci assieme nella stessa tabella.
-
Le transazioni vengono eseguite in un'unica operazione. Il numero massimo di elementi a cui è possibile accedere è 100, per evitare operazioni di lunga durata.
Le query sull'archivio dei dati diventano molto più semplici, spesso come segue:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB lavora molto meno per fornire i dati richiesti rispetto a RDBMS dell'esempio precedente.
